
컴퓨터 과학에 대한 지식을 습득하고 정리하는 기록용 포스팅입니다.
예외를 판단하는 사고를 기르고, 효율적인 코드를 작성하기 위해
컴퓨터 과학 지식을 활용하는 것을 목표로 합니다.
✅ 입출력 시스템
📌 입출력장치와 채널
-
컴퓨터는 필수장치인 CPU와 메모리, 주변 장치인 입출력장치와 저장장치로 구성되며, 각 장치는 메인보드에 있는
버스로 연결된다.
주변 장치는 데이터 전송 속도에 따라저속 주변장치와고속 주변장치로 구분할 수 있다. -
저속 주변 장치 : 메모리와 주변장치 사이에 오고 가는 데이터의 양이 적어 데이터 전송률이 낮은 장치를 말한다. ex)
키보드,프린터 -
고속 주변 장치 : 메모리와 주변 장치 사이에 대용량 데이터가 오고 가므로 데이터 전송률이 높은 장치를 말한다. ex)
그래픽 카드,하드 디스크 -
여러 주변장치는 메인 보드 내의 버스로 연결된다. 그런데 버스에는 많은 종류의 장치가 연결되기 때문에 버스를 1개만 사용하면
병목 현상이 발생한다.
따라서 여러 개의 버스를 묶어서 사용하는데, 이때 데이터가 지나다니는 하나의 통로를채널이라고 한다.
📌 입출력 버스의 구조
🔍 초기의 구조
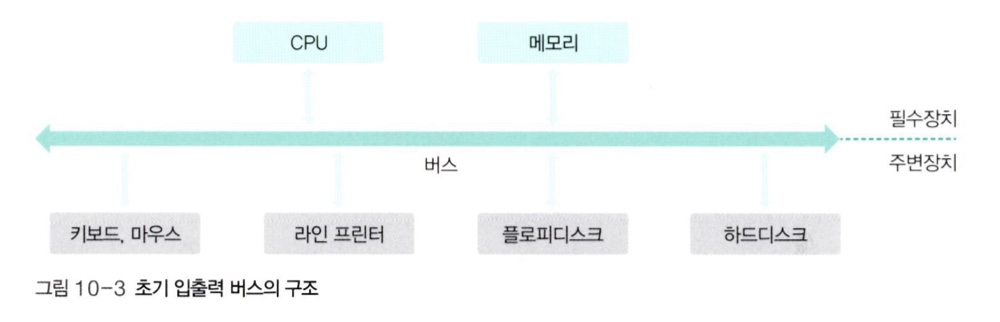
-
CPU가 작업을 진행하다가 입출력 명령을 만나면 직접 입출력 장치에서 데이터를 가져 왔는데, 이를
폴링(Polling) 방식이라고 한다. -
폴링 방식을 적용하면 CPU가 직접 입출력을 하면 입출력이 끝날 때까지 다른 작업을 할 수 없다.
🔍 입출력 제어기를 사용한 구조
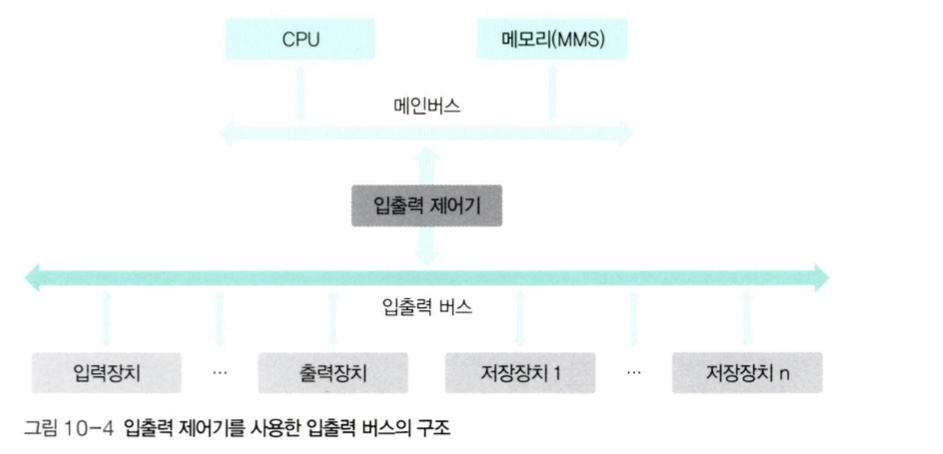
-
CPU가 폴링 방식으로 주변 장치를 관리하기 어려워져서 모든 입출력을
입출력 제어기(I/O Controller)에 맡기는 구조로 바뀌었다. -
메인 버스와 입출력 버스, 2개의 채널로 나뉘며 CPU에서 입출력 요청이 오면 입출력 제어기는 입출력 장치로부터 데이터를 직접 송수신하게 된다.
-
입출력 제어기를 사용하면 느린 입출력장치로 인해 CPU와 메모리의 작업이 느려지는 것을 막을 수 있어 전체 작업 효율이 향상된다.
🔍 입출력 버스의 분리
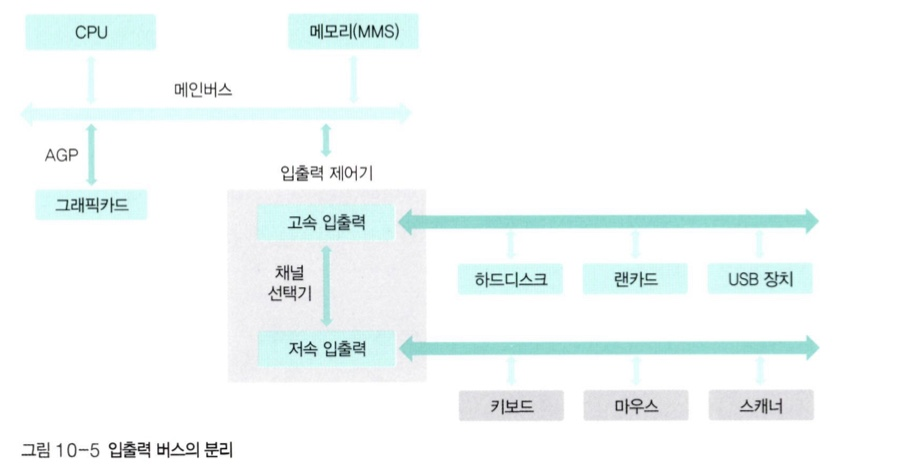
-
입출력 제어기를 사용함으로써 작업 효율을 높일 수 있지만, 한편으로 저속 주변장치 때문에 고속 주변장치의 데이터 전송이 느려지는 문제가 있다.
-
입출력 버스를
고속 입출력 버스와저속 입출력 버스로 분리하여 운영하며, 두 버스 사이의 데이터 전송은채널 선택기가 관리한다. -
그래픽 카드의 경우 AGP(Accelerated Graphics Port)에 카드를 꽂는다. 또한 대용량 데이터 전송하기 위해 메인버스와 직접 연결된 그래픽 버스를 사용한다.
🔍 결론
결론적으로 현대의 컴퓨터는
1. CPU와 메모리를 연결하는 메인버스
2. CPU와 그래픽 카드를 연결하는 그래픽 버스
3. 고속 입출력 버스와 저속 입출력 버스를 사용한다.
📌 직접 메모리 접근
-
DMA(Direcrt Memory Access)는 CPU의 도움 없이도 메모리에 접근 할 수 있도록 입출력 제어기에 부여된 권한으로, 입출력 제어기에는 메모리에 접근하기 위한 DMA 제어기가 있다. -
CPU가 작업하는 공간과 DMA 제어기가 데이터를 옮기는 공간을 분리하여 메인 메모리를 운영하는데, 이를
메모리 맵 입출력(Memory Mapped I/O)이라고 부른다.
이는 메인메모리의 주소 공간 중 일부를 DMA 제어기에 할당하여 작업 공간이 겹치는 것을 막는다.
📌 인터럽트
🔍 인터럽트 개요

-
인터럽트는 주변 장치의 입출력 요구나 하드웨어의 이상 현상을 CPU에 알려주는 역할을 하는 신호이다.
-
입출력 제어기와 DMA 제어기의 협업으로 작업이 완료되면 입출력 제어기는 CPU에 인터럽트를 보낸다.
-
컴퓨터 시스템에는 다양한 종류의 장치가 있기 대문에 CPU가 인터럽트를 받아도 어떤 장치로부터 받은 인터럽트 인지 확인하기 어렵다. 따라서 각 장치에
IRQ(Interrupt Request Lines)이 부여된다.
인터럽트가 발생하면 CPU는 IRQ를 보고 어떤 장치에서 인터럽트가 발생했는지 파악한다.
🔍 인터럽트 벡터와 인터럽트 핸들러
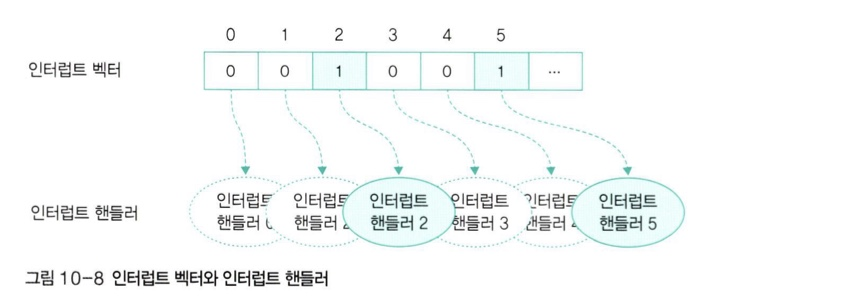
-
인터럽트 벡터는 여러 인터럽트 중 어떤 인터럽트가 발생했는지 파악하기 위해 사용하는 자료구조이다. -
인터럽트 벡터의 값이 1이면 해당 인터럽트가 발생했다는 의미이다.
-
인터럽트 핸들러는 인터럽트의 처리 방법을 함수 형태로 만들어 놓은 것이다. 운영체제는 인터럽트가 발생하면 인터럽트 핸들러를 호출하여 작업을 한다. -
인터럽트 벡터에는 해당 인터럽트 핸들러를 호출할 수 있도록 인터럽트 핸들러가 저장된 메모리의 주소가 포인터 형태로 등록돼 있다.
✅ 디스크 장치
📌 하드 디스크
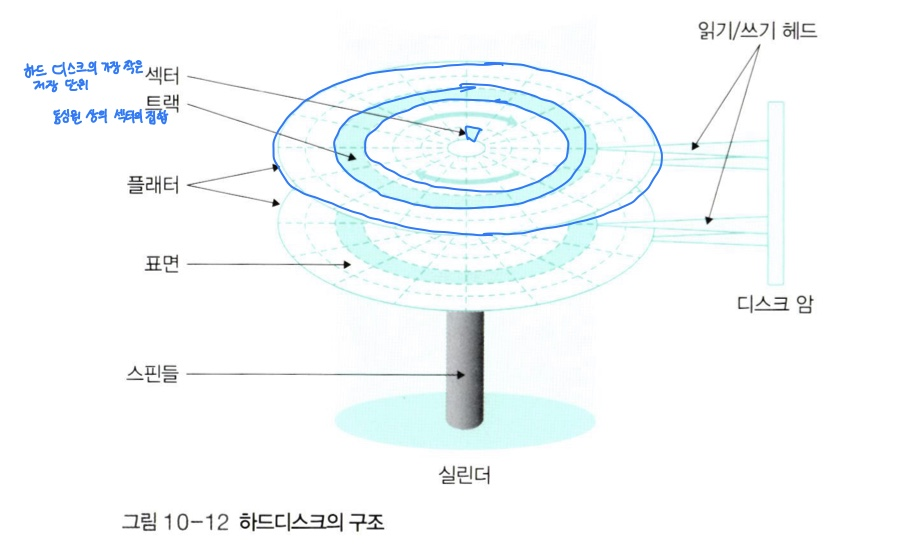
-
플래터: 플래터는 표면에 자성체가 발려 있어 자기를 이용하여 0과 1의 데이터를 저장할 수 있다. 플래터의 표면이 N극을 띠면 0으로, S극을 띠면 1로 인식한다. 또한 항상 일정한 속도로 회전한다. 하드디스크 사양의 7,500rpm = 플래터가 1분에 7,500바퀴를 일정한 속도로 회전한다는 의미이다. -
섹터: 물리적인 개념인 섹터는 하드디스크의 가장 작은 단위이다. 하나의 섹터에는 한 덩어리의 데이터가 저장된다. -
블록: 블록은 하드디스크와 컴퓨터 사이에 데이터를 전송하는 논리적인 저장 단위 중 가장 작은 단위이다. 블록은 여러개의 섹터로 구성된다. -
하드 디스크 입장에서 가장 작은 저장 단위는
섹터이지만,
운영체제 입장에서는블록이 가장 작은 저장 단위이다. -
트랙: 플래터에서 회전축을 중심으로 테이터가 기록되는 동심원, 즉 동일한 동심원상에 있는 섹터의 집합을 말한다. -
실린더: 개념적으로 여러 개의 플래터에 있는 같은 트랙의 집합을 말한다. -
헤드: 하드 디스크에서 데이터를 읽거나 쓸 때에는 읽기/쓰기 헤드를 사용한다. -
파킹: 컴퓨터가 종료될 때 헤드가 플래터의 표면에 흠집을 내지 않도록 하드 디스크는 헤드를 데이터가 저장되지 않는 플래터의 맨 바깥쪽으로 이동 시키는 것을 말한다.
📌 데이터 전송 시간
-
탐색 시간(Seek Time): 헤드가 현재 위치에서 특정 트랙까지 이동하는데 걸리는 시간. -
회전 지연 시간(Rotational Latency Time): 특정 트랙까지 이동한 헤더가 원하는 섹터를 만날 때까지 회전한 시간. -
전송 시간(Transmission Time): 헤드가 특정 섹터의 데이터를 읽어 전송하는데 걸리는 시간. -
데이터 전송 시간 : 탐색 시간 + 회전 지연 시간 + 전송 시간
데이터 전송 시간에 있어서, 가장 많은 비중을 차지하는 것은 탐색 시간이다. 때문에 탐색 시간을 최소화해야 한다! 이러한 탐색 시간을 최소화하기 위해 디스크 스케줄링 기법을 사용한다.
✅ 디스크 스케줄링
🔍 FCFS(First Come, First Service) 디스크 스케줄링
가장 단순한 방식으로, 요청이 들어온 트랙 순서대로 서비스한다.
🔍 STTF(Shortest Seek Time First) 디스크 스케줄링
-
현재 헤드가 있는 위치에서 가장 가까운 트랙부터 서비스한다.
-
두트랙의 거리가 같다면 먼저 요청받은 트랙을 서비스한다.
-
헤드가 중간에 위치하면 가장 안쪽이나 가장 바깥쪽에 있는 트랙은 서비스 받을 확률이 낮아지기때문에 아사 현상을 일으킬 수 있다.
🔍 블록 STTF(Shortest Seek Time First) 디스크 스케줄링

- STTF의 공평성 위배를 어느 정도 해결한 방법으로, 트랙 요청을 일정한 블록의 형태로 묶어서 블록 내에서 가장 가까운 트랙으로 이동한다.
🔍 SCAN 디스크 스케줄링
-
헤드가 한 방향으로만 움직이면서 서비스한다. 엘리베이터 기법이라고도 부른다.
-
SSTF 기법보다 공평성을 덜 위배하면서도 성능이 좋기 때문에 많이 활용된다.
-
하지만, 동일한 트랙이나 실린더 요청이 연속적으로 발생하면 헤드가 나아가지 못하고 제자리에 머물게 되어 바깥쪽 트랙이 아사 현상을 겪는다.
🔍 C-SCAN 디스크 스케줄링
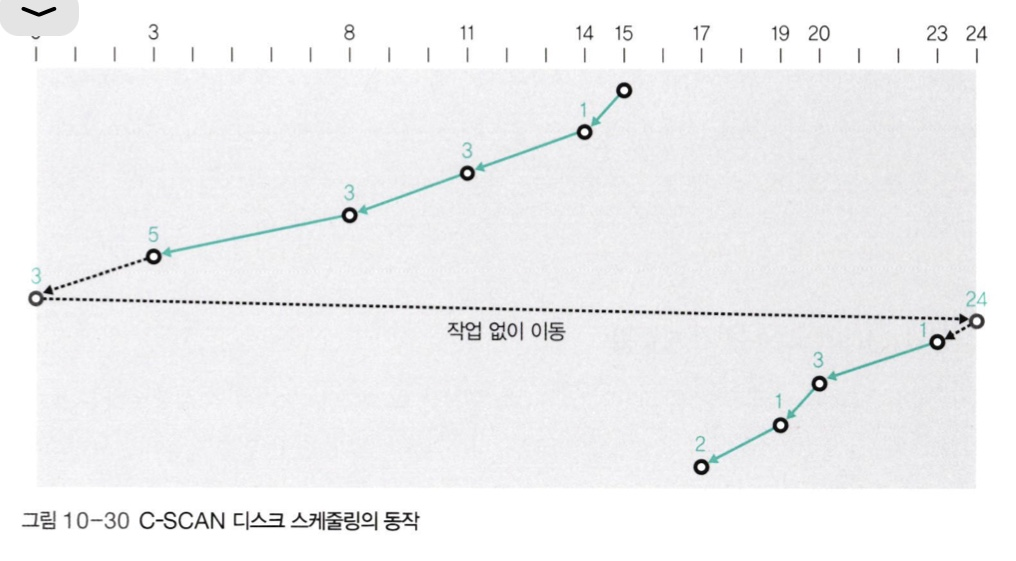
-
헤드가 한쪽 방향으로만 움직인다. 하지만 반대 방향으로 돌아올때는 서비스하지 않고 이동만 한다.
-
작업 없이 이동하는 것은 매우 비효율적이다. 또한 SCAN 기법에서의 아사현상이 해결되지는 않는다. 때문에 잘 사용되지 않는다.
🔍 LOOK 디스크 스케줄링
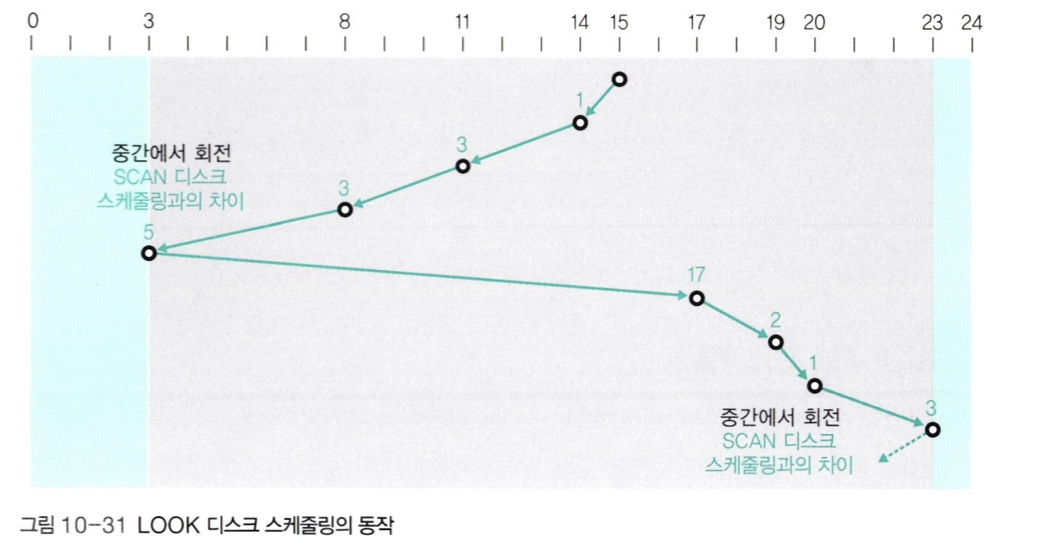
-
SCAN 기법에서 불필요한 부분을 제거하여 효율을 높인 기법이다.
-
SCAN 기법은 트랙 요청이 없어도 헤드가 마지막 트랙에 도착한 후에야 방향을 바꾸지만, LOOK 기법은 서비스할 트랙이 없으면 헤드가 트랙의 끝까지 가지 않는다.
-
SCAN 기법을 개선한 LOOK 기법 또한 많이 사용된다.
🔍 C-LOOK 디스크 스케줄링
- LOOK 기법에 반대 방향으로 돌아올때는 서비스하지 않는 개념을 더한 기법이다.
✅ RAID
📌 RAID 개요
🔍 RAID의 기본 개념
-
RAID(Redundant Array Independent Disks)는 자동으로 백업을 하고 장애가 발생하면 이를 복구하는 시스템을 말한다. -
RAID는 동일한 규격의 디스크를 여러 개 모아 구성하며, 장애가 발생해씅 ㄹ때 데이터를 복구하는데 사용된다.
🔍 RAID의 기본 방식
-
미러링(Mirroring): 똑같은 데이터를 그대로 복사하여 저장하는 방식. -
스트라이핑(Striping): 데이터를 여러 조각으로 나누어 저장하여 입출력 속도를 높이는 방식. (Ex: 하나의 데이터를 디스크 1~4번까지 동시에 나눠서 저장하면 입출력 속도가 빨라진다.) -
오류 검출: 오류 검출 코드(EDC, Error Detecting Code)인패리티 비티(Pariry Bit, 오류 검출만)를 이용하는 오류를 교정하는 방식. -
오류 교정: 오류 교정 코드(ECC, Error Correcting Code)인허밍 코드(Hamming Code, 오류 검출과 교정 둘다)를 이용하여 오류를 검출하는 방식.
📌 RAID 0(Striping)
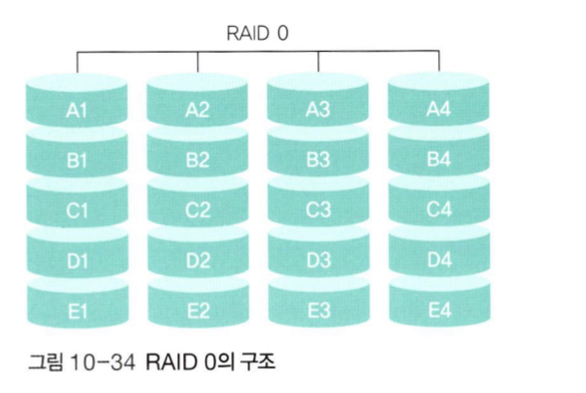
-
RAID 0은 병렬로 연결된 여러 개의 디스크에 데이터를 동시에 입출력할 수 있도록 구성한다. -
같은 규격의 디스크를 병렬로 연결하여 여러 개의 데이터를 여러 디스크에 동시에 저장하거나 가져올 수 있다. 즉, 데이터를 여러 갈래로 찢어서 저장하거나 가져온다.
-
하지만 하나의 디스크라도 문제가 발생 할 경우 전체 RAID 전체에 문제가 발생한다. 즉 안정성이 매우 낮다.
-
장애 발생 시 복구하는 기능이 없기 때문에 장애가 발생하면 데이터를 잃는다. 그럼에도 불구하고 빠른 입출력이 가능하기때문에 개인용 컴퓨터와 고급형 노트북 기종에 사용된다.
📌 RAID 1(Mirroring)
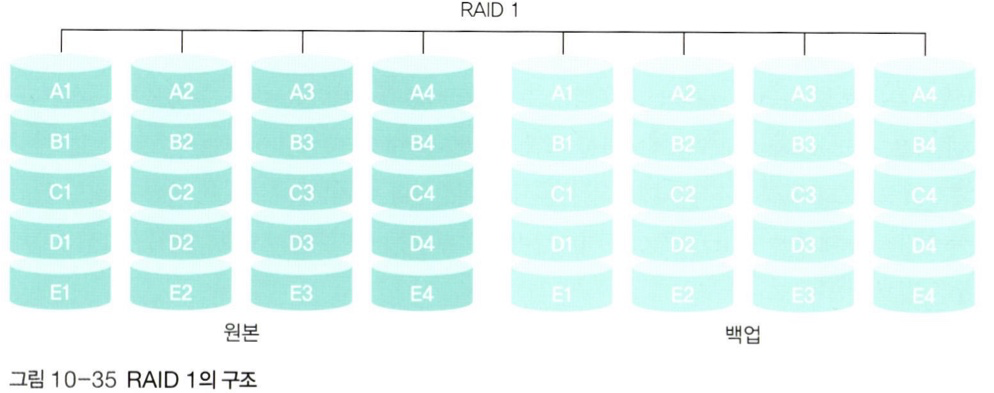
-
RAID 1에서는 순수 백업 시스템을 두어, 똑같은 데이터를 미러링 하여 백업 디스크에 저장한다. 때문에 데이터를 복구할 수 있다. -
같은 크기의 디스크를 최소 2개 이상 필요로 하며 짝수 개의 디스크로 구성된다.
-
최대 강점은 안정성이 높다는 것이다.
📌 RAID 2
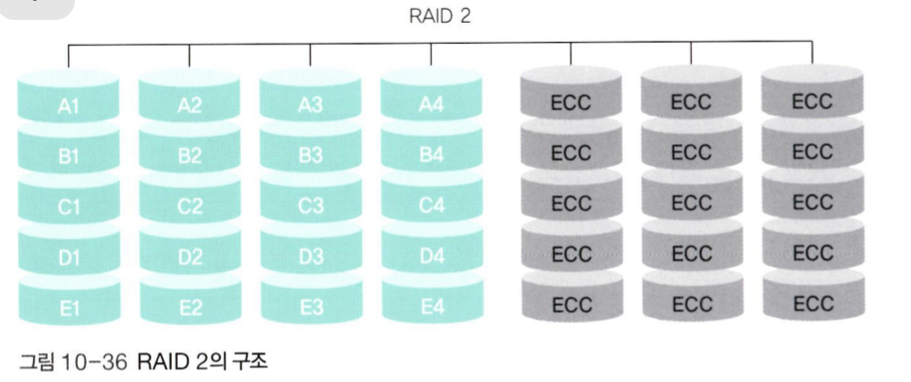
-
RAID 2에서는 허밍 코드와 같은오류 교정 코드(ECC)를 따로 관리하고, 오류가 발생하면 이 코드를 이용하여 디스크를 복구한다. -
각 비트의 오류 교정 코드를 구성하여 나중에 비트 단위로 복구하기 위해서, 데이터가
비트 단위로 스트라이핑 돼서 저장된다. -
n개의 디스크에 대해 오류 교정 코드를 저장하기 위한 n-1개의 디스크를 필요로 하므로, 최소 3개의 디스크가 필요하다.
-
RAID 1보다는 작은 공간을 필요로 하지만, 오류 교정 코드를 계산하는데 많은 시간을 소비한다. 때문에 잘 사용되지 않는다.
📌 RAID 3
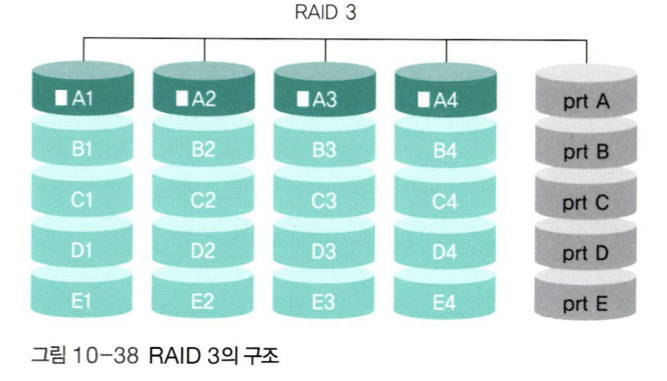
-
패리티 비트를 사용하여 데이터를 복구한다. 앞서서 패리티 비트는 오류를 교정하지 못한다고 했지만, RAID 시스템에서는 패리티 비트를 사용하여 오류를 복구한다.
-
Byte 단위로 스트라이핑을 하고, 오류 검출을 위한 패리티 디스크를 1개 사용한다. Byte 단위로 스트라이핑 하는 것은 너무 작게 쪼개지기 때문에 현재는 사용하지 않는 RAID이다.
📌 RAID 4
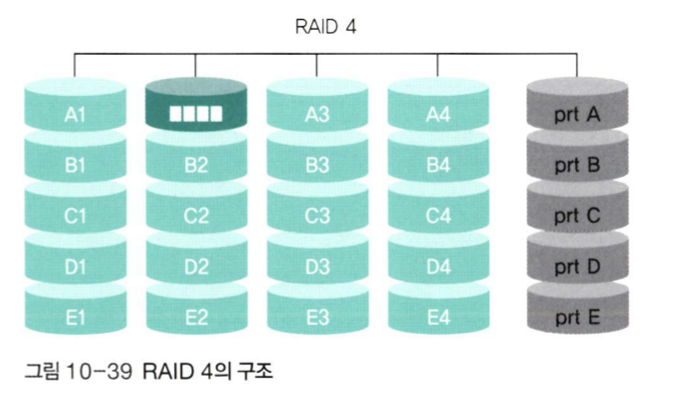
-
RAID 3과 방식은 똑같지만 처리하는 데이터 단위가
Block 단위이다. -
RAID 3방식과 같이 Byte 단위로 쪼개게 되면 패리티 비트를 구성하기 위해 모든 디스크가 동시에 동작해야한다는 단점이 있다(RAID 3 그림의 초록색 부분). 이를 해결하기 위해 RAID 4에서는 Block 단위로 저장한다.
-
모든 패리티 비트가 하나의 디스크에 저장되기 때문에, 병목 현상이 발생하며, 피리티 디스크의 수명이 줄어든다. 이는 RAID 4를 사용하지 않는 이유이다.
📌 RAID 5
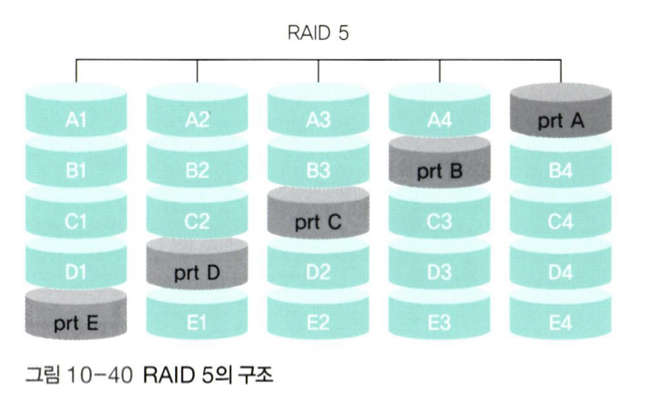
-
RAID 5에서는 패리티 비트를 여러 디스크에 분산하여 구성한다. 이는 병목 현상을 완화 해준다. -
가장 사용빈도가 높은 RAID이다.
📌 RAID 6
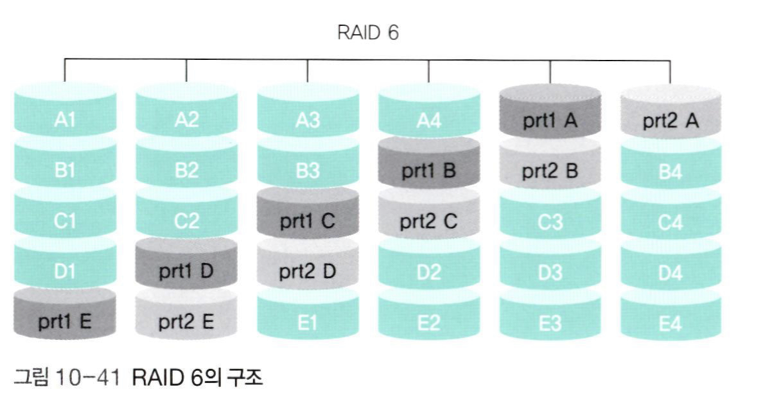
-
RAID 6은 RAID 5와 같은 방식이지만 패리티 비트가 2개이다. -
RAID 5는 두개의 디스크에 동시에 장애가 발생했을 때 복구가 불가능하지만, RAID 6 방식은 가능하다.
📌 RAID 10
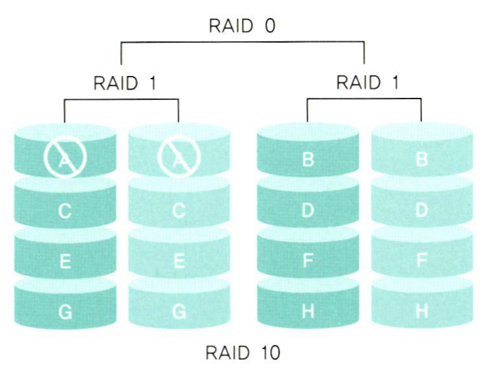
-
그림과 같이, 디스크를 2개 씩 묶어서 RAID 1을 구성하고, 묶인 디스크를 또 RAID 0으로 묶어서 구성한다.
-
병렬로 데이터를 처리하여 입출력 속도를 높일 수 있으며, 장애 발생 시 미러링된 디스크로 복구가 가능하다.
✅ 참고
도서 : 쉽게 배우는 운영체제
https://harryp.tistory.com/806
