교내 학회에서 하계 컨퍼런스로 DL segmentation 프로젝트를 진행하게 되었는데,
처음 팀원들과 제대로 준비해보는 프로젝트이다보니 진행과정을 어떻게 브리핑하고 관리할지에 대한 고민이 커졌다.
캐글에 들어가서 여러 코드들을 보다보면 Wandb라는 툴을 자주 사용하고 있는 모습을 볼 수 있었는데, 이참에 wandb 사용법을 제대로 익혀두면 앞으로 사용할 일이 많을 것이라 생각했다.
오늘은 그중에서도 파이토치를 어떻게 적용할지 알아보기로했다!
Wandb에서 제공하는 튜토리얼(Pytorch)
(wandb.ai quickstart 를 참고해서 작성하였습니다)
1. Simple Pytorch Integration
!pip install wandb -qUimport wandb
wandb.login()wandb를 설치하고, 로그인 해줍니다.
(1) 시작은 간단하게
import random
total_runs = 5
for run in range(total_runs):
wandb.init(
project="basic-intro",
name=f"experiment_{run}",
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
wandb.log({"acc": acc, "loss": loss})
wandb.finish()wandb.init() 함수는 wandb web 서버와 연결 시켜주는 기능을 합니다. project name과 wandb id를 적어주고. 그리고 config 값을 받아서 저장 시켜둡니다.
-> 다른 코드를 보아하니 config를 따로 빼두고 여러 파라미터를 설정해두는 듯 함
(2) Simple Pytorch Neural Network
Setup Dataloader 과정
import wandb
import math
import random
import torch, torchvision
import torch.nn as nn
import torchvision.transforms as T
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def get_dataloader(is_train, batch_size, slice=5):
"Get a training dataloader"
full_dataset = torchvision.datasets.MNIST(root=".", train=is_train, transform=T.ToTensor(), download=True)
sub_dataset = torch.utils.data.Subset(full_dataset, indices=range(0, len(full_dataset), slice))
loader = torch.utils.data.DataLoader(dataset=sub_dataset,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
def get_model(dropout):
"A simple model"
model = nn.Sequential(nn.Flatten(),
nn.Linear(28*28, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(256,10)).to(device)
return model
def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0):
"Compute performance of the model on the validation dataset and log a wandb.Table"
model.eval()
val_loss = 0.
with torch.inference_mode():
correct = 0
for i, (images, labels) in enumerate(valid_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
val_loss += loss_func(outputs, labels)*labels.size(0)
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
if i==batch_idx and log_images:
log_image_table(images, predicted, labels, outputs.softmax(dim=1))
return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)
def log_image_table(images, predicted, labels, probs):
"Log a wandb.Table with (img, pred, target, scores)"
table = wandb.Table(columns=["image", "pred", "target"]+[f"score_{i}" for i in range(10)])
for img, pred, targ, prob in zip(images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")):
table.add_data(wandb.Image(img[0].numpy()*255), pred, targ, *prob.numpy())
wandb.log({"predictions_table":table}, commit=False)Train 시켜보기
for _ in range(5):
wandb.init(
project="pytorch-intro",
config={
"epochs": 10,
"batch_size": 128,
"lr": 1e-3,
"dropout": random.uniform(0.01, 0.80),
})
config = wandb.config
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2*config.batch_size)
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
model = get_model(config.dropout)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {"train/train_loss": train_loss,
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch)) / n_steps_per_epoch,
"train/example_ct": example_ct}
if step + 1 < n_steps_per_epoch:
wandb.log(metrics)
step_ct += 1
val_loss, accuracy = validate_model(model, valid_dl, loss_func, log_images=(epoch==(config.epochs-1)))
val_metrics = {"val/val_loss": val_loss,
"val/val_accuracy": accuracy}
wandb.log({**metrics, **val_metrics})
print(f"Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}")
wandb.summary['test_accuracy'] = 0.8
wandb.finish()이렇게 코드를 실행해보면
run history, run summary를 코랩에서도 확인할 수 있다는 점이 신기했다.
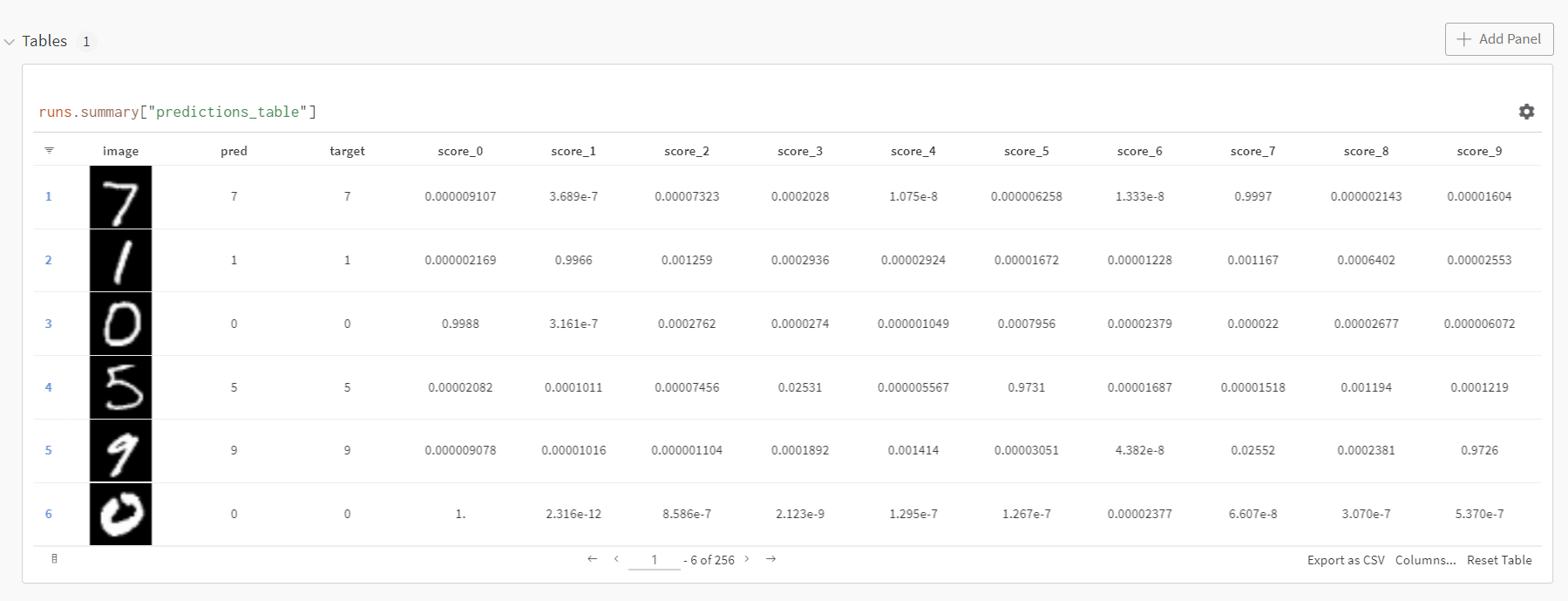
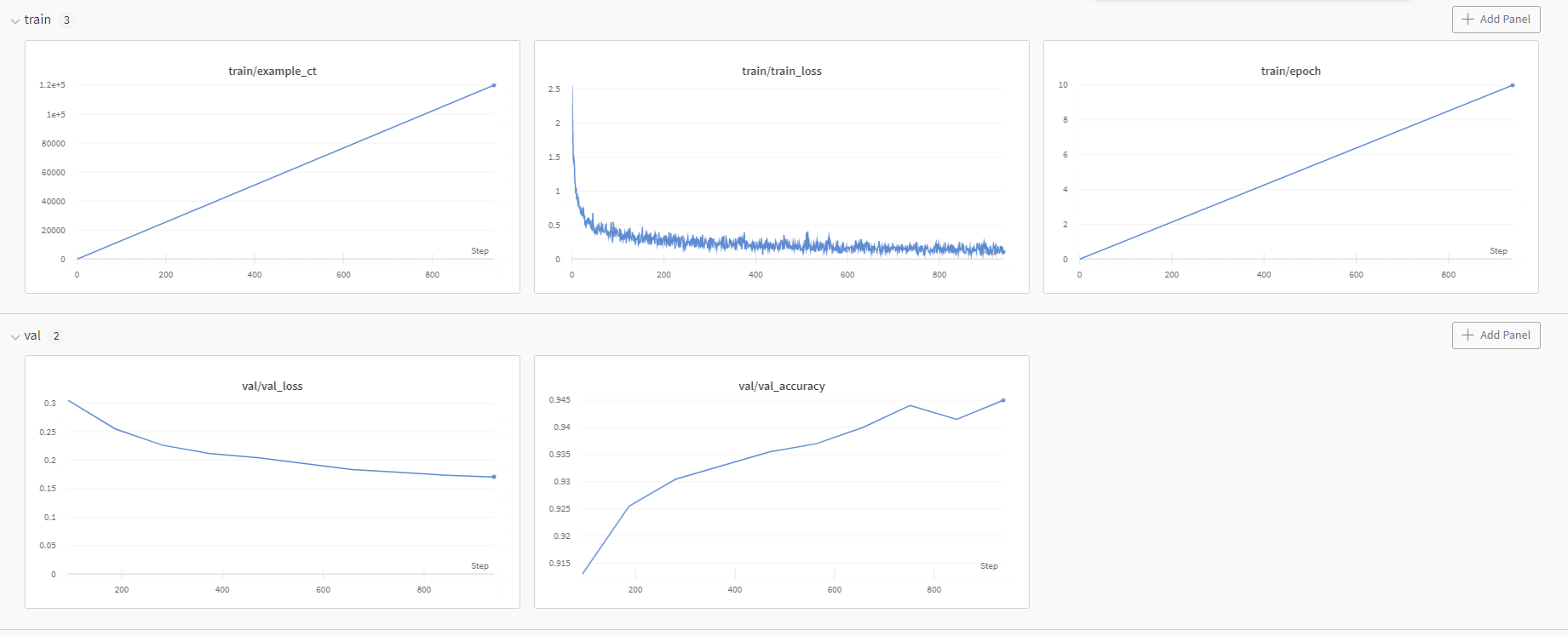
table, train, validation 전 과정을 모두 확인 가능하다.
이 튜토리얼의 마지막에는 pytorch 하이퍼파라미터를 바꿔주는
다음 단계로 넘어가라고 안내하고 있다.
velog 첫 포스팅이라 문법은 타 개발자의 velog 기본 문법 포스팅을 참고했습니다 -> Velog 기본 문법
