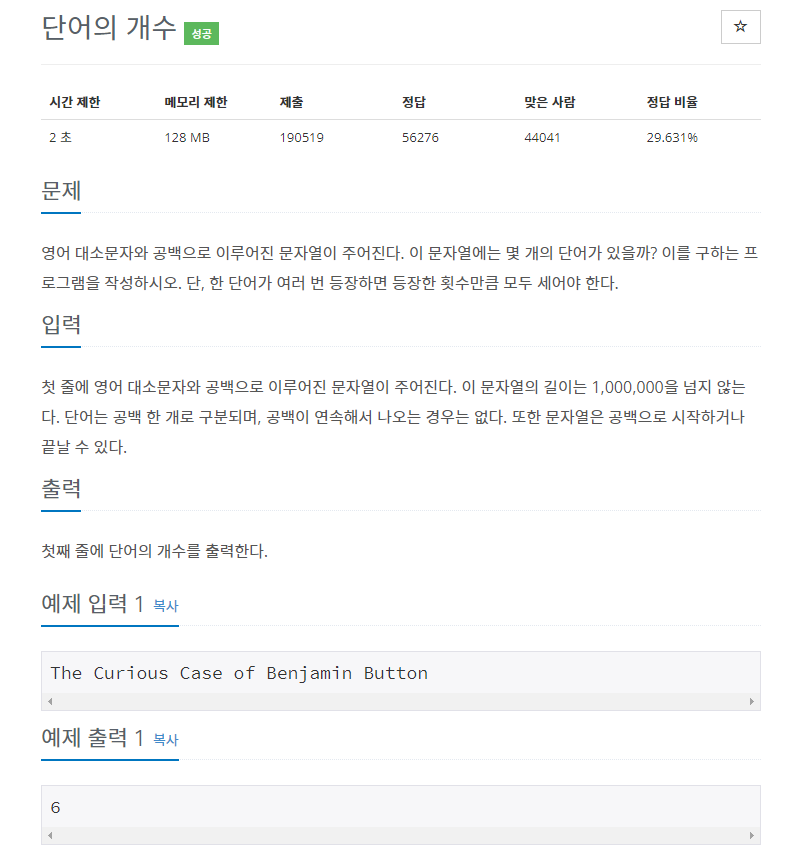
words = input().split(" ")
print(len(words))처음 풀었을 때 틀린 답이 나와서 당황했다.
왜 이게 틀린 답일까?
예제 입력2와 3에는 문자열 앞과 뒤에 공백이 있었다.
디버깅을 해본 결과 words에 [0]이나 [-1] 인덱스에 공백 값이 존재했다.words = input().strip().split(" ")
print(len(words))그래서 이번엔 공백을 제거하는 strip()함수를 써보았다.
앞 공백을 제거하는 것은 lstrip()
뒤 공백을 제거하는 것은 rstrip()
양쪽을 제거하는 것이 strip() 함수이다.
이번엔 예제입력대로 테스트해본 결과 앞 뒤 공백이 제거되어 원하는 출력값을 얻을 수 있었다.
하지만 여전히 틀린 상태였다.
잠깐 고민해본 결과 코드를 수정해보았다.
words = input().split()
print(len(words))split(" ")와 split()의 차이에 있었다.
split() 함수는 괄호에 들어오는 문자를 기준으로 문자열을 쪼개 리스트로 반환하는 함수다.
만약에 괄호에 문자가 들어가지 않는다면, split()은 모든 공백을 한 번에 처리한다.
A = " a ab abc abcd ".split()
B = " a ab abc abcd ".split(" ")
print(len(A)) # 4 출력
print(len(B)) # 13 출력비슷한 코드이지만 공백을 구분하는 기준 때문에 결과값이 달라졌다
split()은 공백이 아무리 많을지라도 공백을 한 번에 처리하는 반면에
split(" ")은 문자열의 공백 하나 하나 처리하기 때문이다.
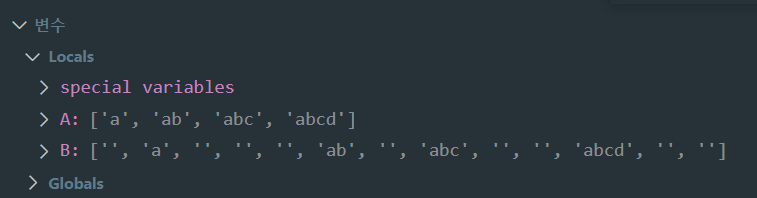
디버깅을 해보니 split(" ")은 공백을 하나하나 리스트에 담고 있었다.
공백에도 공간을 할당한다면 자원낭비가 지나칠 수 있을 것 같다
print("a aa aaa ".split()) >> ['a', 'aa', 'aaa']
print("a aa aaa ".split(' ')) >> ['a\taa\t\taaa\t']tab키를 이용했을 때의 결과의 차이이다
split(" ")에서는 분할점을 스페이스로 명시했기 때문에 해당 입력에서만 분할처리를 한다.
반면 split()에서는 다른 공백에 대해서도 한 번에 처리하기 때문에 \n 등에서도 동일하게 적용한다.
정리하면서
쉬운 문제였지만, split()과 split(" ")의 차이를 모르고 있었다.
자주 쓰는 함수인만큼, 다음 번에는 잊지않고 응용하고자 한다.

개발자가 되고 싶습니다