11. JSP와 서블릿, Spring에서 발생할 수 있는 여러 문제점
자바 기반의 시스템 중 WAS에서 병목 현상이 발생할 수 있는 부분을 세밀하게 나눈다고 하면, UI 부분과 비즈니스 로직 부분으로 나눌 수 있다. 여기서 UI 부분이란 서버에서 수행되는 UI를 이야기하는 것이다. 자바스크립트로 구성된 UI는 클라이언트 PC에서 수행된다. 자바 기반의 서버단 UI를 구성하는 대부분의 기술은 JSP와 서블릿을 확장하는 기술이다.
1. JSP와 Servlet의 기본적인 동작 원리는 꼭 알아야 한다.
일반적으로 JSP와 같은 웹 화면단을 처리하는 부분에서 소요되는 시간은 많지 않다. JSP의 경우 가장 처음에 호출되는 경우에만 시간이 소요되고, 그 이후의 시간에는 컴파일된 서블릿 클래스가 수행되기 때문이다. 그럼 JSP의 라이프 사이클을 간단하게 리뷰해보자. JSP의 라이프 사이클은 다음의 단계를 거친다.
1) JSP URL 호출
2) 페이지 번역
3) JSP 페이지 컴파일
4) 클래스 로드
5) 인스턴스 생성
6) jspInit 메서드 호출
7) _jspService 메서드 호출
8) jspDestroy 메서드 호출
여기서 해당 JSP 페이지가 이미 컴파일되어 있고, 클래스가 로드되어 있고, JSP 파일이 변경되지 않앗다면, 가장 많은 시간이 소요되는 2~4 프로세스는 생략된다. 서버의 종류에 따라서 서버가 기동될 때 컴파일을 미리 수행하는 Pre-compile 옵션이 있다. 이 옵션을 선택하면 서버에 최신 버전을 반영한 이후에 처음 호출되었을 때 응답 시간이 느린 현상을 방지할 수 있다. 하지만 개발 시에 이 옵션을 켜 놓으면 서버를 기동할 때마다 컴파일을 수행하기 때문에 시간이 오래 걸린다. 따라서 개발 생산성이 떨어지므로 상황에 맞게 옵션을 지정해야 한다.
이번에는 서블릿의 라이프 사이클을 살펴보자. WAS의 JVM이 시작한 후에는,
- Servlet 객체가 자동으로 생성되고 초기화되거나,
- 사용자가 해당 Servlet을 처음으로 호출했을 때 생성되고 초기화 된다.
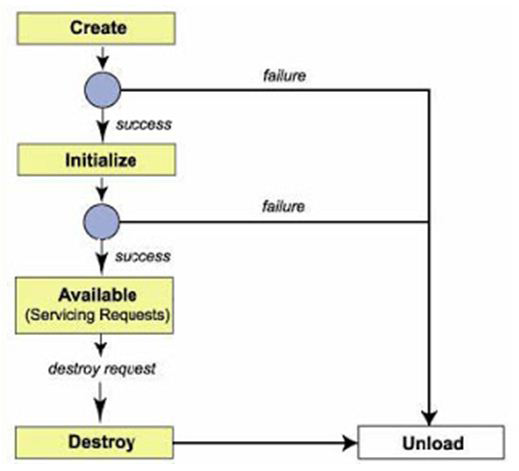
그 다음에는 계속 '사용 가능' 상태로 대기한다. 그리고 중간에 예외가 발생하면 '사용 불가능' 상태로 빠졌다가 다시 '사용 가능' 상태로 변환되기도 한다. 그리고 나서, 해당 서블릿이 더 이상 필요 없을 때는 '파기'상태로 넘어간 후 JVM에서 '제거'된다.
그런데, 여기서 꼭 기억해야 하는 것이 있다. 바로 서블릿은 JVM에 여러 객체로 생성되지 않는다는 점이다. 다시 말해서 WAS가 시작하고, '사용 가능' 상태가 된 이상 대부분의 서블릿은 JVM에 살아 있고, 여러 스레드에서 해당 서블릿의 service() 메서드를 호출하여 공유한다.
만약 서블릿 클래스의 메서드 내에 선언한 지역 변수가 아닌 멤버 변수(인스턴스 변수)를 선언하여 service() 메서드에서 사용하면 어떤 일이 벌어질까? 예를 들면 다음과 같다.
package com.perf.servlet;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class DontUserLikeThisServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
String successFlag = "N";
public DontUserLikeThisServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
successFlag = request.getParameter("successFlag");
}
}successFlag 값은 여러 스레드에서 접근하면서 계속 값이 바뀔 것이다. 이처럼 여러 스레드에서 접근하면, 데이터가 꼬여서 원하지 않는 값들이 출력될 수도 있다. 즉, static을 사용하는 것과 거의 동일한 결과를 나타낸다. 그러므로, service() 메서드를 구현할 때는 멤버 변수나 static한 클래스 변수를 선언하여 지속적으로 변경하는 작업은 피하기 바란다.
2. 적절한 include 사용하기
include 기능을 사용하면, 하나의 JSP에서 다른 JSP를 호출하여 여러 JSP 파일을 혼합해서 하나의 JSP로 만들 수 있다. JSP에서 사용할 수 있는 include 방식은 정적인 방식(include directive)과 동적인 방식(include action)이 있다.
정적인 방식은 JSP의 라이프 사이클 중 JSP 페이지 번역 및 컴파일 단계에서 필요한 JSP를 읽어서 메인 JSP의 자바 소스 및 클래스에 포함을 시키는 방식이다.
이와 반대로, 동적인 방식은 페이지가 호출될 때마다 지정된 페이지를 불러들여서 수행하도록 되어 있다. 각 방식은 다음과 같이 사용한다.
- 정적인 방식 : <%@ include file="관련 URL"%>
- 동적인 방식 : <jsp:include page="realtiveURL"/>
이 두 가지 방법 중 어느 방법이 느릴까? 당연한 이야기지만, 동적인 방식이 정적인 방식보다 느릴 수 밖에 없다. 정적인 방식과 동적인 방식의 응답 속도를 비교해 보면 동적인 방식이 약 30배 더 느리게 나타난다.
즉, 성능을 더 빠르게 하려면 정적인 방식을 사용해야 한다는 의미가 된다. 하지만 모든 화면을 정적인 방식으로 구성하면 잘 수행되던 화면에서 오류가 발생할 수 있다. 정적인 방식을 사용하면 메인 JSP에 추가되는 JSP가 생긴다. 이 때 추가된 메인 JSP에 동일한 이름의 변수가 있으며 심각한 오류가 발생할 수 있다. 그러므로 상황에 맞게 알맞은 include 방식을 선택하여 사용해야 한다.
3. 자바 빈즈, 잘 쓰면 약 못쓰면 독
자바 빈즈(Java Beans)는 UI에서 서버 측 데이터를 담아서 처리하기 위한 컴포넌트이다. 간단히 자바 빈즈의 문제점만 알아보자.
자바 빈즈를 통하여 useBeans을 하면 성능에 많은 영향을 미치지는 않지만, 너무 많이 사용하면 JSP에서 소요되는 시간이 증가될 수 있다.
<jsp:useBean id="list" scope="request" class="java.util.ArrayList" type="java.util.List" />
<jsp:useBean id="count" scope="request" class="java.lang.String" />
<jsp:useBean id="pageNo" scope="request" class="java.lang.String" />
<jsp:useBean id="pageSize" scope="request" class="java.lang.String" />
...
//약 20개의 useBean 태그위 소스는 어떤 프로젝트에서 자바 빈즈를 사용한 예이다. 이 화면의 경우 DB까지 전체 처리하는 데 소요된 시간은 97ms이며, 그중 JSP에서 소요된 시간이 57ms이다. 그리고 JSP에서 자바 빈즈를 처리하기 위해서 소요된 시간은 47ms로, 전체 응답 시간의 48%에 해당하는 시간이다.
이 시간을 줄이기 위해서는 TO(Transfer Object) 패턴을 사용해야 한다. 하나의 TO 클래스를 만들고, 위의 예에서 사용된 각 문자열 및 HashMap, List를 그 클래스의 변수로 지정하여 사용하면 화면을 수행하는 데 소요된 시간 중 48%가 절약된다.
한두 개의 자바 빈즈를 사용하는 것은 상관 없지만, 10~20개의 자바 빈즈를 사용하면 성능에 영향을 주게 된다. 그러므로 TO를 만들어 사용하자.
4. 태그 라이브러리도 잘 써야 한다
태그 라이브러리(Tag library)는 JSP에서 공통적으로 반복되는 코드를 클래스로 만들고, 그 클래스를 HTML 태그와 같이 정의된 태그로 사용할 수 있도록 하는 라이브러리다. 요즘은 대부분의 프레임워크에서 많은 종류의 태그 라이브러리를 제공하고 있다. 간단히 태그 라이브러리에 대해서 리뷰하고 태그 라이브러리의 문제점을 알아보자.
태그 라이브러리는 XML 기반의 tld 파일과 태그 클래스로 구성되어 있다. 태그 라이브러리를 사용하기 위해서는 web.xml 파일을 열어 tld의 URL와 파일 위치를 아래 예제 코드와 같이 정의해야 한다.
<web-app>
<tablib>
<taglib-uri>/tagLibURL/</taglib-uri>
<taglib-location>
/WEB-INF/tlds/tagLib.tld
</taglib-location>
</taglib>
</web-app> web.xml에서 정의하는 tld 파일은 다음과 같은 형식으로 되어 있다.
<?xml version="1.0" encoding="ISO-8859-1"?>
<taglib
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-jsptaglibrary_2_1.xsd"
version="2.1">
<tlibversion>1.0</tlibversion>
<jspversion>1.1</jspversion>
<shortname>tagLibSample</shortname>
<uri/>
<tag>
<name>tagLibSample</name>
<tagclass>com.perf.jsp.TagLibSample</tagclass>
<bodycontent>JSP</bodycontent>
</tag>
</taglib> 이 파일에 중요한 부분은 tag라는 태그의 하위 태그에 있는 내용이다. 여기서 태그 라이브러리의 이름과 클래스를 지정한다. 태그 안에 포함되는 내용의 종류는 bodycontent 태그 안에 지정하여 허용한다.
이제 web.xml 파일과 tld 파일에 태그 라이브러리와 관련된 내용을 지정하였으니 JSP에서 사용하기만 하면 된다. 일반적으로 태그 라이브러리는 JSP의 상단에 지정한다. 방식은 다음과 같다.
<%@ taglib uri="/tagLibURI" prefix="myPreFix" />이렇게 지정된 태그 라이브러리는 여러 가지 방법으로 사용할 수 있지만, 그중 내용에 JSP 태그를 사용하는 방법은 다음과 같다.
<myPreFix:tagLibSample>
<%=contents%>
</myPreFix:tagLibSample>그럼 태그 라이브러리에서 성능상 문제가 발생할 때는 언제인가? 태그 라이브러리 클래스를 잘못 작성하거나 태그 라이브러리 클래스로 전송되는 데이터가 많을 때 성능에 문제가 된다.
실제 프로젝트 사이트 예를 통해서 알아보자. 화면에서 태그 라이브러리를 통해 100~500 건을 처리할 때 소요되는 시간을 놓고 WAS:DB 소요 시간을 비교해 보았다. 그 결과, 1:9로 DB에서 소요되는 시간이 월등히 높았다. 하지만, 이 사이트의 경우 한 번에 검색 가능한 목록에 대한 제한이 없었다. 그리고 일반적으로 조회되는 목록의 건수가 4,000건이 넘었다. 4,000건을 조회할 때의 WAS:DB에서의 응답 시간은 5:5의 비율을 보였다. 물론 4,000건의 데이터를 한 번에 조회하는 것 자체가 문제가 있다. 하지만 기존 CS 시스템의 틀을 벗어나지 못하거나, 벗어나지 않으려는 고객이 있는 사이트는 어쩔 수 없이 그만큼의 데이터를 처리해 주어야 한다.
그리고 태그 라이브러리는 태그 사이에 있는 데이터를 넘겨주어야 하는데, 이때 넘겨 주는 데이터 형태는 대부분 문자열 타입이다. 따라서 데이터가 많으면 많을수록 처리를 해야 하는 내용이 많아지고, 자연히 태그 라이브러리 클래스에서 처리되는 시간이 많아질 수 밖에 없다. 목록을 처리하면서 대용량의 데이터를 처리할 경우에는 태그 라이브러리의 사용을 자제해야 한다.
5. 스프링 프레임워크 간단 정리
우리나라에서는 자바 기반의 프로젝트를 진행할 때 대부분 스프링 프레임워크를 사용한다. 스프링 프레임워크에 대해서 간단히 살펴보자.
먼저, 스프링 프레임워크를 웹 프레임워크로 오해하는 사람들이 많다. 하지만, 스프링 프레임워크는 데스크톱과 웹 애플리케이션, 작고 간단한 애플리케이션부터 여러 서버와 연동하여 동작해야 하는 엔터프라이즈 애플리케이션도 범용적인 애플리케이션 프레임워크다.
Spring의 가장 큰 특징은 복잡한 애플리케이션도 POJO(Plain Old Java Object)로 개발할 수 있다는 점이다. (참고로 JSP와 Servlet에서 Servlet은 POJO가 아니다.) Servlet을 개발하면서 반드시 HttpServlet이라는 클래스를 상속해야 한다. 하지만 스프링을 사용하면 HttpServlet을 확장하지 않아도 웹 요청을 처리할 수 있는 클래스를 만들 수 있다. 이밖에도 JMS, JMX, Mail, Web Service 등 여러 가지 기능을 POJO 기반으로 만들 수 있기 때문에, 개발자가 보다 쉽게 자신이 작성한 코드를 테스트할 수 있다. 그래서 더 빠르고 쉽게 문제를 확인할 수 있으며 이는 곧 높은 개발 생산성으로 이어진다.
스프링의 핵심 기술
스프링의 핵심 기술은 바로 Dependency Injection, Aspect Oriented Programming, Portable Service Abstraction으로 함축할 수 있다.

Dependency Injection은 의존성 주입이라고 한다. 이는 객체 간의 의존성 관계를 관리하는 기술 정도로 생각하면 된다. 객체는 보통 혼자서 모든 일을 처리하지 않고, 여러 다른 객체와 협업하여 일을 처리한다. 이때 자신과 협업하는 객체와 자신과의 의존성을 가능한 낮춰야 유리한 경우가 많다. 다시 말해서, 어떤 객체가 필요로 하는 객체를 자신이 직접 생성하여 사용하는 것이 아니라 외부에 있는 다른 무언가로부터 필요로 하는 객체를 주입 받는 기술이다.
public class A {
private B b = new B();
}예제 코드를 보면 A 클래스의 객체는 항상 B 클래스의 객체를 사용하게 된다. 이렇게 구현하면 나중에 B라는 객체를 다른 것으로 교체하기 힘들다. 그런데, 만약 다음과 같이 B 클래스의 객체를 외부에서 넘기는 형태로 코드를 작성하면 보다 손쉽게 A 클래스가 사용하는 객체를 다른 것으로 변경할 수 있다. 즉, 생성자의 매개변수로 넘어온 B 클래스의 객체를 A 클래스에서 사용하는 b로 설정하면 A 클래스의 객체를 사용하기 전에 필요한 B 객체를 외부에서 미리 만들어서 넘겨줄 수 있는 구조가 된다.
public Class A {
private B b;
public A(B b) {
this b = b;
}
}스프링은 이렇게 의존성을 쉽게 주입하는 틀을 제공해 준다. XML이나 어노테이션 등으로 의존성을 주입하는 방법을 제공하며 생성자 주입, 세터 주입, 필드 주입 등 다양한 의존성 주입 방법을 제공하고 있다. 이러한 틀이 없다면 프로젝트마다 각기 다른 방법으로 의존성을 주입하느라 혼란스러웠을 것이다.
스프링에서 제공하는 두번째 핵심 기술은 바로 AOP다. 우리나라 말로는 관점 지향 프로그래밍이라고 부른다. 한때는 이 기술이 마치 객체 지향 프로그래밍(Object Oriented Programming, OOP)을 대체하는 기술로 홍보하기도 했지만 이 기술은 OOP를 보다 더 OOP스럽게 보완해주는 기술이다.
트랜잭션, 로깅, 보안 체크 코드를 생각해보자. 이런 코드들은 여러 모듈, 여러 계층에 스며들기 마련이다. 그런데 필요한 작업이긴 하지만 대부분은 비슷한 코드가 중복되고, 코드를 눈으로 읽는 데 방해가 된다. 이런 코드를 실제 비즈니스 로직과 분리할 수 있도록 도와주는 것이 바로 AOP다. 자바에서 가장 유명한 AOP 프레임워크로는 AspectJ가 있다. 스프링은 AspectJ와 손쉽게 연동하는 방법을 제공할 뿐 아니라, AspectJ 보다 훨씬 더 사용하기 간편한 방법을 사용한 스프링 AOP를 제공해준다. 이 기술을 잘 활용하면 핵심 비즈니스 코드의 가독성을 높여준다.
마지막으로 스프링이 제공하는 핵심 기술로 PSA를 꼽을 수 있다. 오픈소스로 제공되는 자바 라이브러리는 매우 많다. 객체를 XML로 변경하거나 반대로 XML을 다시 객체로 변경하고 싶을 때 사용할 수 있는 라이브러리에는 JAXB, Castor, XMLBeans, JiBX가 있다. 트랜잭션 처리를 하고 싶을 때 사용하는 기술에 따라 JDBC 트랜잭션 API를 사용해야 할 수도 있고, iBatis가 제공하는 API, 또는 Hibernate가 제공하는 API를 사용할 수도 있다. 글로벌 트랜잭션이 필요한 경우에는 JTA를 사용하여 트랜잭션을 처리하는 코드를 작성해야 한다.
이렇게 비슷한 기술을 구현하기 위해 코딩하는 방법은 사용할 라이브러리나 프레임워크에 따라 달라지기 때문에, 추상화가 매우 중요하다. 만약 A라는 라이브러리를 사용하던 중에 심각한 성능 문제가 있는 것을 발견하고, 더 빠르고 안정적인 라이브러리를 사용해야 한다면, A 라이브러리로 모든 코드를 변경해야 하는 사태가 발생한다. 만약 개발 초기에 이런 문제를 발견했다면, 몇 줄 수정하지 않아도 금방 변경할 수 있겠지만, 다음 주에 시스템 오픈을 하기 위해서 오늘 성능 테스트를 했는데 이러한 문제를 발견했다면 어떻게 될까? 만약 시스템의 사용자가 적어서 오픈 후에 천천히 여유 있을 때 변경해도 되는 상황이라면 상관없겠지만, 구글 I/O 행사 신청과 같이 전 세계에서 수십만 명의 개발자가 등록을 하는 상황이라면 밤새면서 A 라이브러리와 관련된 부분을 찾아 고쳐야만 할 것이다.
스프링은 그런 일이 생기지 않도록 비슷한 기술을 모두 아우를 수 있는 추상화 계층을 제공하여, 사용하는 기술이 바뀌더라도 비즈니스 로직의 변화가 없도록 도와준다. 제대로만 개발했다면, 이러한 일이 발생했을 때 해야할 일은 앞서 언급한 스프링의 의존성 주입 기능으로 사용할 객체를 바꿔주는 것 뿐이다.
6. 스프링 프레임워크를 사용하면서 발생할 수 있는 문제점들
스프링을 사용하면서 여러 가지 문제가 발생할 수 있다. 빈 설정을 잘못해서 발생하는 문제도 있을 수 있고 스프링의 동작 원리를 이해하지 않고서는 해결되지 않는 문제도 발생할 수 있다. 여기서는 주로 성능과 관련 있는 문제만 살펴보자.
스프링 프레임워크를 사용할 때 성능 문제가 가장 많이 발생하는 부분은 '프록시(Proxy)'와 관련되어 있다. 스프링 프록시는 기본적으로 실행 시에 생성된다. 따라서, 개발할 때 적은 요청을 할 때는 이상이 없다가, 요청량이 많은 운영 상황으로 넘어가면 문제가 나타날 수 있다. 스프링이 프록시를 사용하게 하는 주요 기능은 바로 트랜잭션이다. @Transactional 어노테이션을 사용하면 해당 어노테이션을 사용한 클래스의 인스턴스를 처음 만들 때 프록시 객체를 만든다. 이밖에도, 개발자가 직접 스프링 AOP를 사용해서 별도의 기능을 추가하는 경우에도 프록시를 사용하는데, 이 부분에서 문제가 많이 발생한다. @Transactional처럼 스프링이 자체적으로 제공하는 기능은 이미 상당히 오랜 시간 테스트를 거치고 많은 사용자에게 검증을 받았지만, 개발자가 직접 작성한 AOP 코드는 예상하지 못한 성능 문제를 보일 가능성이 매우 높다. 따라서, 간단한 부하 툴을 사용해서라도 성능적인 면을 테스트해야만 한다.
추가로, 스프링이 내부 메커니즘에서 사용하는 캐시도 조심해서 써야 한다. 예를 들어 스프링 MVC에서 작성하는 메서드의 리턴 타입으로 다음고 같은 문자열을 사용할 수 있다.
public class SampleController {
@RequestMapping("/member/{id}")
public String hello(@PathVariable int id) {
return "redirect:/member/" + id;
}
}즉, 이렇게 문자열 자체를 리턴하면 스프링은 해당 문자열에 해당하는 실제 뷰 객체를 찾는 메커니즘을 사용하는데, 이 때 매번 동일한 문자열에 대한 뷰 객체를 새로 찾기 보다는 이미 찾아본 뷰 객체를 캐싱해두면 다음에도 동일한 문자열이 반환됐을 때 훨씬 빠르게 뷰 객체를 찾을 수 있다. 스프링에서 제공하는 ViewResolver에서 자주 사용되는 InternalResourceViewResolver에는 그러한 캐싱 기능이 내장되어 있다.
만약 매번 다른 문자열이 생성될 가능성이 높고, 상당히 많은 수의 키 값으로 캐시 값이 생성될 여지가 있는 상황에서는 문자열을 반환하는 게 메모리에 치명적일 수 잇다. 따라서 이런 상황에서는 뷰 이름을 문자열로 반환하기보다는 뷰 객체 자체를 반환하는 방법이 메모리 릭을 방지하는 데 도움이 된다.
public class SampleController {
@RequestMapping("/member/{id}")
public View hello(@PathVariable int id) {
return new RedirectView("/member/" + id);
}
}참고
- 자바 성능 튜닝 이야기
