13. XML과 JSON도 잘 쓰자
요즘 자바로 개발할 때 각종 설정 파일과 DB 쿼리를 XML에서 관리하는 것은 기본이고, 데이터를 XML 및 JSON 타입으로 주고 받는 시스템도 늘어나고 잇다. 하지만 XML이나 JSON을 쓸 경우 시스템의 성능이 안 좋아질수도 있다. 필요에 따라 써야 할 곳에서는 쓰는 것이 좋지만, 꼭 그럴 필요가 없는 곳까지 맹목적으로 쓰는 것은 좋지 않다.
1. 자바에서 사용하는 XML 파서의 종류는?
XML은 eXtensible Markup Language의 약자이다. XML의 가장 큰 장점은 누구나 데이터의 구조를 정의하고 그 정의된 구조를 공유함으로써 일관된 데이터 전송 및 처리를 할 수 있다는 점이다. 이러한 특성 때문에 데이터를 파싱(Parsing)해야 한다. 요즘 대부분의 프로젝트에서는 XML을 사용하므로, 간단히 파서(Parser)에는 어떤 종류가 있는지, 각 파서의 특징은 무엇인지 확인해 보자.
마크업 언어(Markup Language)이란 태그 기반의 텍스트로 된 언어를 의미한다. 태그 안에 필요한 데이터를 추가함으로써 데이터를 전달하거나 보여주는 것이 주 목적이다. 가장 유명한 마크업 언어로는 매일 접하는 HTML이 있다. HTML도 미리 선언되어 있는 태그 안에 데이터를 입력하여 처리하기 때문이다.
자바에서는 XML을 파싱하기 위해서 JAXP를 제공한다. JAXP는 SAX, DOM, XSLT에서 사용하는 기본 API를 제공한다. 그렇기 때문에 JAXP 기반의 API를 쓴다면, 파서를 제공하는 벤더에 종속되지 않을 수 있다. 참고로, 각 약어의 의미는 다음과 같다.
| 약어 | 의미 | 패키지 |
| JAXP | Java API for XML Processing | javax.xml.parsers |
| SAX | Simple API for XML | org.xml.sax |
| DOM | Document Obejct Model | org.w3c.dom |
| XSLT | Xml Stylesheet Language for Transformations | javax.xml.transform |
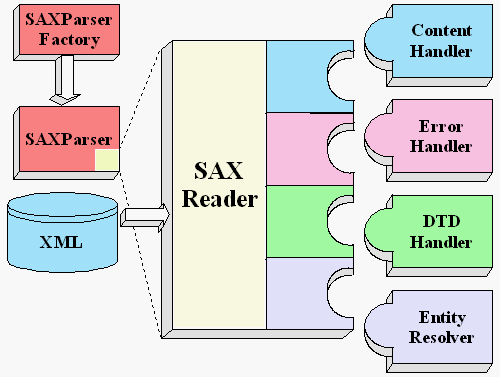
JAXP의 javax.xml.parsers 패키지는 SAX와 DOM에서 사용하는 SAXParserFactory와 DocumentBuilderFactory를 제공한다. 이 파서들은 각각 XML-DEV 그룹과 W3C에서 정의하였다. 그래서 관련 패키지가 자바의 표준 API에 포함되어 있다.
SAX는 순차적 방식으로 XML을 처리한다. 반면 DOM은 모든 XML을 읽어서 트리(Tree)를 만든 후 XML을 처리하는 방식이다. 다시 말하면, SAX는 각 XML의 노드를 읽는 대로 처리하기 때문에 메모리에 부담이 DOM에 비해서 많지 않다. 하지만 DOM은 모든 XML을 메모리에 올려서 작업하기 때문에 메모리에 부담이 가게 된다.
먼저 SAX의 처리 방식을 보자. SAX는 Content 핸들러, Error 핸들러, DTD 핸들러, Entity 리졸버를 통해서 순차적인 이벤틀르 처리한다. 그러므로 이미 읽은 데이터의 구조를 수정하거나 삭제하기 어렵다.
반면, DOM은 모든 XML의 내용을 읽은 이후에 처리한다. 읽은 XML을 통하여 노드를 추가, 수정, 삭제하기 쉬운 구조로 되어 있다.
XSLT는 SAX, DOM, InputStream을 통해서 들어온 데이터를 원하는 형태의 화면으로 구성하는 작업을 수행한다. XML이 화면에서 보기 쉬운 데이터가 되도록 처리하는 것이라고 생각하면 된다.
지금까지 알아본 세 가지 XML 파서 중 서버단 프로그램에서 사용하기 적합한 파서는 SAX와 DOM이다. 먼저 SAX와 DOM 파서에 대해서 간단히 알아보고, 두 파서의 성능을 비교해 보자.
2. SAX 파서는 어떻게 사용할까?
SAX 파서는 순차적으로 처리하는 이벤트 기반의 모델이다. DOM보다는 손이 많이 간다. 모든 이벤트를 다 처리할 필요는 없지만, 원하는 데이터를 만들려면 데이터를 어떻게 처리할지 결정해서 구현해야 하기 때문이다.
기본적으로 제공되는 SAX API에는 무엇이 있는지 알아보자.
- SAXParserFactory : 파싱을 하는 파서 객체를 생성하기 위한 추상 클래스이다.
- SAXParser : 여러 종류의 parse() 메서드를 제공하기 위한 추상 클래스이다. 이 클래스의 parse() 메서드를 호출하면 파싱을 실시한다.
- DefaultHandler : 아래에 있는 ContentHandler, ErrorHandler, DTDHandler, EntityResover를 구현한 클래스이다. 상황에 따라 XML을 처리하려면 이 클래스를 구현하면 된다.
- ContentHandler : XML의 태그의 내용을 읽기 위한 메서드를 정의한 인터페이스다. startDocument, endDocument, startElement, endElement 메서드가 정의되어 있다.
- ErrorHandler : 에러를 처리하는 메서드가 정의되어 있는 인터페이스이다.
- DTDHandler : 기본 DTD 관련 이벤트를 식별하기 위한 인터페이스이다.
- EntityResover : URI를 통한 식별을 하기 위한 인터페이스이다.
요청한 XML 파일의 엘리먼트 개수를 세는 프로그램을 통하여 실제 어떻게 XML을 처리하는지 알아보자. 먼저 주요 메서드들을 보자.
package com.perf.xml.sax;
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import java.util.*;
public class ParseSAX extends DefaultHandler {
public HashMap<String, Integer> elementMap = new HashMap<String, Integer>();
private StringBuffer returnData = new StringBuffer();
public ParseSAX() {
}
public void startDocument() {
returnData.append("### Start Document !!!\n");
}
public void endDocument() {
returnData.append("### End Document !!!\n");
setNodeCountData();
}
public void startElement(String uri, String local, String nodeName,
Attributes attrs) throws SAXException {
addNode(nodeName);
}
public void addNode(String nodeName) {
if (!elementMap.containsKey(nodeName)) {
elementMap.put(nodeName, 1);
} else {
elementMap.put(nodeName, elementMap.get(nodeName) + 1);
}
}
public void setNodeCountData() {
Set<String> keySet = elementMap.keySet();
Object[] keyArray = keySet.toArray();
Arrays.sort(keyArray);
for (Object tempKey : keyArray) {
returnData.append("Element=").append(tempKey).append(" Count=")
.append(elementMap.get(tempKey.toString())).append("\n");
}
}
public String getData() {
return returnData.toString();
}
public void print(String data) {
returnData.append(data).append("<BR>");
}
}이 소스에서는 아무런 처리를 하지 않았기 때문에, 각 엘리먼트를 처리하는 메서드를 만들어 주어야 한다. startDocument()와 endDocument() 메서드는 각각 XML 문서가 시작할 때와 끝날 때 오직 한 번씩만 수행된다. 만약 XML을 읽기 시작했을 때나 읽기가 완료되었을 때 어떤 처리를 하고 싶다면 이 메서드에 추가하면 된다. 여기서는 간단히 시작 및 종료를 나타내기 위해서 프린트만 하였다. startElement() 메섯드에서는 addNode() 메서드를 호출한다.
addNode() 메서드에서는 HashMap에 해당 엘리먼트가 있는지를 확인한 후, 엘리먼트 개수를 추가하는 작업을 수행한다. setNodeCount()에서는 각 엘리먼트당 개수 정보를 returnData라는 StringBuffer에 담는다. 이 코드를 실행하는 JMH 소스는 다음과 같다.
package com.perf.xml;
import java.util.concurrent.TimeUnit;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
import com.perf.xml.dom.ParseDOM;
import com.perf.xml.sax.ParseSAX;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class XMLParser {
@GenerateMicroBenchmark
public void withSAXParse100() throws Exception {
ParseSAX handler = new ParseSAX();
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
saxParser.parse("dummy100.xml", handler );
}
@GenerateMicroBenchmark
public void withSAXParse1000() throws Exception {
ParseSAX handler = new ParseSAX();
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
saxParser.parse("dummy1000.xml", handler );
}
}먼저 ParseSAX라는 클래스를 DefaultHandler의 상속을 받아서 SAX로 XML을 처리할 수 있도록 했다. 가장 먼저 handler 객체를 정의한 후, SAXParserFactory의 newInstance() 메서드를 호출하여 factory 객체를 만든다. 이 객체를 통하여 SAXParser의 객체인 saxParser를 생성한다. 그 다음엔 saxParser의 parse() 객체를 통해 파일 객체 및 handler 객체를 사용하여 파싱을 수행한다.
파싱한 결과를 화면에 프린트하려면 다음과 같이 한 줄을 메서드 마지막 줄에 추가하면 된다.
System.out.println(handler.getData());파싱할 XML은 다음과 같이 간단한 XML 파일이다.
<DataStart>
<Product name='prod1'><Price>1</Price></Product>
<Product name='prod2'><Price>2</Price></Product>
...
</DataStart>실행한 결과는 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| SAX 100 | 847 |
| SAX 1000 | 3,925 |
데이터가 100개일 경우에는 847마이크로초가 소요되고, 1000개일 경우에는 3.9ms 정도가 소요되는 것을 볼 수 있다. 데이터의 크기가 10배라고 할지라도 반드시 10배의 시간이 소요되지는 않는다.
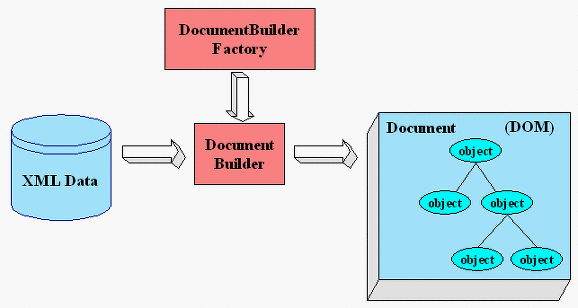
3. DOM 파서는 어떻게 사용할까?
DOM 파서는 SAX 파서와 다르게 XML을 트리 형태의 데이터로 먼저 만든 후, 그 데이터를 가공하는 방식을 사용한다. DOM에서의 주요 클래스를 알아보면 다음과 같다.
- DocumentBuilderFactory : 파싱을 하는 파서 객체를 생성하기 위한 추상 클래스
- DocumentBuilder : 여러 종류의 parse() 메서드를 제공하는 추상 클래스, 이 클래스의 parse() 메서드를 호출하면 파싱을 실시한다.
- Document : SAX와 다르게 파싱을 처리한 결과를 저장하는 클래스
- Node : XML과 관련된 모든 데이터의 상위 인터페이스. 단일 노드에 대한 정보를 포함하고 있다.
그럼 소스를 통해서 사용법을 알아보자.
package com.perf.xml.dom;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Set;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class ParseDOM {
HashMap<String, Integer> elementMap = new HashMap<String, Integer>();
private StringBuffer returnData = new StringBuffer();
public void parseDOM(String XMLName) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(XMLName);
Node rootNode = document.getChildNodes().item(0);
addNode(rootNode.getNodeName());
readNodes(rootNode);
setNodeCountData();
} catch (Exception e) {
e.printStackTrace();
}
}
public void readNodes(Node node) {
NodeList childs = node.getChildNodes();
int childCount = childs.getLength();
for (int loop = 0; loop < childCount; loop++) {
Node tempNode = childs.item(loop);
if (tempNode.hasChildNodes()) {
readNodes(tempNode); // 재귀 호출
}
String nodeName = tempNode.getNodeName();
if (!nodeName.equals("#comment") && !nodeName.equals("#text")) {
addNode(nodeName);
}
}
}
public void addNode(String nodeName) {
if (!elementMap.containsKey(nodeName)) {
elementMap.put(nodeName, 1);
} else {
elementMap.put(nodeName, elementMap.get(nodeName) + 1);
}
}
public void setNodeCountData() {
Set<String> keySet = elementMap.keySet();
Object[] keyArray = keySet.toArray();
Arrays.sort(keyArray);
for (Object tempKey : keyArray) {
returnData.append("Element=").append(tempKey).append(" Count=")
.append(elementMap.get(tempKey.toString())).append("<BR>");
}
}
public String getData() {
return returnData.toString();
}
}SAX와 크게 다른 점은 따로 핸들러를 지정하지 않고, 파싱한 데이터를 Document 클래스의 객체에 담아서 리턴해 준다는 것이다.
readNodes() 메서드를 보면, 노드의 getChildNodes() 메서드를 호출하여 자식 노드의 목록을 얻는다. 자식 노드의 개수만큼 반복하여 자식 노드의 정보를 읽는다. 만약 그 자식 노드도 자식이 있다면 이 메서드도 호출해야 하므로, 재귀적으로 처리하였다. 나머지 3개의 메서드(addNode(), setNodeCountData(), getData())는 SAX의 예와 동일하다. 이 코드를 수행하는 JMH 메서드는 XMLParser 클래스에 다음의 내용을 추가하면 된다.
@GenerateMicroBenchmark
public void withDOMParse100() {
ParseDOM pd=new ParseDOM();
pd.parseDOM("dummy100.xml");
}
@GenerateMicroBenchmark
public void withDOMParse1000() {
ParseDOM pd=new ParseDOM();
pd.parseDOM("dummy1000.xml");
}만약 JMH로 실행하지 않고 결과를 확인하고 싶다면 다음과 같이 출력문을 추가하면 된다.
System.out.println(pd.getData());소스는 매우 간단하고 SAX와 거의 동일하다. 수행한 결과를 보자.
| 대상 | 평균 응답 시간(마이크로초) |
| DOM 100 | 1,395 |
| DOM 1,000 | 7,129 |
DOM 파서를 사용하면 보는 것과 같이 100건일 경우 1.4ms, 1,000건일 경우 7.1ms가 소요된다. 그러면 SAX 파서와 DOM 파서의 성능을 한 자리에 놓고 같이 비교해 보자.
| 대상 | 응답 시간(마이크로초) | 대상 | 응답 시간(마이크로초) |
| SAX 100 | 847 | DOM 100 | 1,395 |
| SAX 1,000 | 3,925 | DOM 1,000 | 7,129 |
데이터의 크기가 커지면 커질수록 두 파서간의 차이가 커지는 것을 볼 수 있다. 그러나, 이 예제에서 처리한 XML의 구조는 단순하다. 복잡하고 큰 파일일수록 SAX와 DOM 파서에서 처리하는 시간은 더 늘어날 것이다. 그리고 처리하는 데 소요되는 대부분의 시간은 parse() 메서드에서 처리하는 CPU 시간이다. 즉, 대기 시간은 없지만, XML을 처리하는 과정에서 CPU에 순간적으로 많은 부하가 발생한다는 것이다.
만약 자신의 시스템이 XML을 기반으로 처리한다면, 반드시 좋은 CPU를 사용해야만 할 것이다. 내부적으로 처리하는 readNodes() 메서드와 addNodes() 메서드를 제거하고, 순수하게 파서에서 사용하는 메모리 사용량만 측정해 보면 다음과 같다.(이 값은 데이터가 50만 건이고, 크기가 31MB인 XML 데이터를 처리한 경우의 예이다.)
| SAX 파서 사용시 | DOM 파서 사용시 | |
| 메모리 사용량 | 56MB | 292MB |
SAX 파서는 XML 파일 크기의 거의 두 배의 메모리를, DOM 파서는 거의 열 배의 메모리를 사용한다. 참고로, 이 결과는 파서의 종류에 따라서 메모리 사용량이 다를 수 있다. 즉, XML 파일의 크기가 클 때 DOM 파서를 사용한다면, OutoOfMemory가 빈번히 일어날 확률이 매우 크다.
4. XML 파서가 문제가 된 사례
힙 덤프는 현재 JVM의 힙 메모리에서 점유하고 있는 객체에 대한 정보를 파일로 생성해 놓은 것이다. OutOfMemoryError가 발생했을 때 자동으로 힙 덤프를 저장하도록 하려면 "-XX:HeapDumpPath=/app/tomcat/dump/"와 같이 저장하는 경로를 추가하면 된다.
어떤 사이트는 여러 지역에 WAS가 분리되어 있는데, 특정 지역의 WAS에서 힙 덤프가 1분에 한 번씩 발생하고 있었다. 힙 덤프를 분석하자 다음의 결과가 나왔다.
이를 표로 정리하면 다음과 같다. 여기서, 가장 위에 있는 객체 두 개의 메모리 사용량이다.
| 메모리 사용량 | 비율 | 클래스 |
| 737,306,056 | 68% | java.lang.ref.Finalizer |
| 327,686,792 | 30% | java.lang.UnixProcess |
여기서 UnixProcess와 관련된 부분은 WAS에서 기본적으로 점유하고 사용하는 메모리이다. 문제는 Finalizer 클래스에서 잡고 있는 메모리였다. 이 클래스는 GC를 하기 위해서 호출되는데, 추적을 해서 들어가 보니 하나의 XML을 처리하기 위한 Handler 클래스에서 700MB 정도의 메모리를 점유하고 있었다.
해당 사이트는 XML로 문서를 주고 받는다. XML을 파싱하기 위해서 파서가 있어야 하는데, 대부분의 WAS에는 파서가 내장되어 있다. 여기서는 그 내장된 파서가 문제였다. 그 파서는 특수문자가 XML에 들어오면 무한 루프를 돌아 OutOfMemoryError가 발생하는 것이다. 그러므로 WAS에 있는 파서를 쓰면 안되고, 아파치 그룹에서 제공하는 SAX 파서를 사용해야 하는 것이다.
5. JSON과 파서들
JSON은 XML 다음으로 유명한 데이터 교환 형식 중 하나다. 요즘은 XML로 서버 간에 데이터를 주고 받는 것 보다는 JSON으로 데이터를 주고 받는 경우가 더 많아졌다. JSON 데이터는 다음과 같은 두 가지의 구조를 기본으로 하고 있다.
- name/value 형태의 쌍으로 collection 타입
- 값의 순서가 있는 목록 타입
앞서 XML 예제로 사용한 데이터로 JSON으로 표현하자만 다음과 같이 나타낼 수 있을 것이다.
{
"DataStart":
[
{"productName":"prod1","price":"1"},
{"productName":"prod2","price":"2"},
...,
{"productName":"prod100","price":"100"}
]
}JSON도 많은 CPU와 메모리를 점유하며 응답 시간도 느리다. 만약 꼭 써야 한다면 어쩔 수 없겠지만, 그러한 상황이 아니라면 데이터 전송을 위한 라이브러리를 확인하는 것을 권장한다.
JSON 홈페이지를 보면 많은 종류의 자바 기반 JSON 파서들이 존재하는데, 가장 많이 사용되는 JSON 파서로는 Jackson JSON과 google-gson 등이 있다. 이 중에서 Jackson JSON을 살펴보자.
먼저 JSON을 파싱하는 코드를 보자.
package com.perf.json;
import java.io.File;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.core.JsonToken;
public class ParseJSON {
public void parseStream(String json) {
JsonFactory f = new JsonFactory();
StringBuilder jsonResult=new StringBuilder();
try {
JsonParser jp = f.createJsonParser(new File(json));
jp.nextToken();
while (jp.nextToken() != JsonToken.END_ARRAY) {
String fieldName = jp.getCurrentName();
if(fieldName!=null) {
jp.nextToken();
String text=jp.getText();
if(fieldName.equals("productName")) {
jsonResult.append("Product=").append(text).append("\t");
} else if(fieldName.equals("price")) {
jsonResult.append("Price=").append(text).append("\n");
}
}
}
} catch(Exception e) {
e.printStackTrace();
}
}
}이렇게 코드를 작성하면 SAX처럼 스트리밍 방식으로 데이터를 파싱하여 처리할 수 있다. 이 코드를 테스트하는 JMH 코드는 다음과 같다.
package com.perf.json;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class JSONParser {
@GenerateMicroBenchmark
public void parseStream100(){
ParseJSON pj=new ParseJSON();
pj.parseStream("dummy100.json");
}
@GenerateMicroBenchmark
public void parseStream1000(){
ParseJSON pj=new ParseJSON();
pj.parseStream("dummy1000.json");
}
}실행하는 코드도 매우 간단하다. 실행한 결과를 XML 결과와 비교해보자.
| 데이터 개수 | XML SAX | XML DOM | JSON |
| 100 | 847 | 1,395 | 245 |
| 1,000 | 3,925 | 7,129 | 1,379 |
이 결과만 보면 XML 파싱이 JSON 보다 매우 느리다고 생각할 수 있다. 그런데, 데이터를 전송하기 위해서 XML 및 JSON 데이터를 Serialize와 Deserialize할 경우도 있다.
Serialize는 데이터를 전송할 수 있는 상태로 처리하는 것을 말하고, Deserialize는 전송 받은 데이터를 사용 가능한 상태로 처리하는 것을 말한다.
그런데, JSON 데이터는 Serialize와 Deserialize를 처리하는 성능이 좋지 않다. XML 파서보다 JSON 파서가 더 느린 경우가 대부분이다. 그래서, 요즘에는 데이터를 전송하는 기술들이 많이 나오고 있다.
6. 데이터 전송을 빠르게 하는 라이브러리 소개
XML이나 JSON을 사용하여 데이터를 전송하는 방식은 많이 사용해 왔지만, 요즘에는 자바 객체를 전송하는 방식을 많이 사용한다. 어떤 라이브러리들이 있는지는 각 라이브러리들의 벤치마크를 제공하는 위키 페이지(https://github.com/eishay/jvm-serializers/wiki)를 보면 쉽게 알 수 있을 것이다.
이 위키에서는 여러 자바 기반의 Serializer에 대한 성능 비교 결과를 제공한다. 결과 목록을 보면 대표적으로 많이 사용되는 Serializer는 어떤 것들이 있는지 알 수 있다. 그렇다면, 이 목록의 가장 위에 있는 (변환 시간이 가장 작은)라이브러리가 가장 좋은 것일까? 꼭 그렇지는 않다. 여기서 테스트한 결과는 일부의 조건에서만 수행된 내용이다. 문자열을 전송하는 일이 많은지, 배열 형태의 데이터를 전송하는 일이 많은지에 따라서 결과가 달라질 수가 있다.
일반적으로 많이 사용되는 라이브러리에는 protobuf, Thrift, avro 등이 있다. 이 중에서 protobuf는 구글에서 제공하는 오픈소스 라이브러리이며, Thrift의 경우는 페이스북에서 만들어 Apache 프로젝트로 오픈된 라이브러리이다. protobuf는 C++, Java, Python 등의 언어로, Thrift는 C++, Java, Python, PHP, Ruby, Erlang, Perl, Hashkell, C#, Cocoa, JavaScript, Node.js, Smalltalk 등의 언어로 사용할 수 있는 가이드를 제공한다. 왜 이렇게 여러 언어로 라이브러리를 제공할까? 우리나라의 웹사이트 대부분은 자바나 PHP, ASP 등으로 구성되어 있는 사이트들이 많다. 물론 C나 C++, C#으로 구성된 사이트도 있다. 하지만, 이런 사이트들의 경우 대부분 정해진 표준 프로토콜만 통신하거나 JSON이나 XML 등 텍스트 기반의 데이터로 통신하는 것이 일반적이다. 하지만 JSON이나 XML은 데이터가 커질수록 전송해야하는 양도 증가하고, 파싱하는 성능도 무시할 수 없다. 따라서, 서로 다른 언어로 표현된 구글이나 페이스북의 시스템 사이에 데이터를 주고 받기 위해서 이러한 라이브러리를 만들었다고 보면 된다.
결론적으로 서버와 서버간, 서버와 클라이언트 사이에 데이터를 주고 받기 위해 어떤 자바 라이브러리를 사용할지에 대해서는 성능 비교를 통해 사이트에 가장 적합한 라이브러리를 선택하는 것이 가장 좋다.
avro, protocol buffer, thrift가 어떤 형식으로 데이터를 Serialize 하는지 정리된 블로그
https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
참고
- 자바 성능 튜닝 이야기
