16. JVM은 도대체 어떻게 구동될까?
전 세계에 있는 대부분의 시스템은 지속적으로 변경된다. 다시 말해서 주기적으로 수정하고 배포(release)하는 작업을 반복한다. 만약 웹 기반 시스템을 배포할 때 그냥 재시작만 한다면, 배포 직후 시스템 사용자들은 엄청나게 느린 응답 시간과 함께 시스템에 대한 많은 불만을 갖게 될 수도 있다. 즉, Warming up이 필요한데, 왜 이러한 작업이 필요한지에 대해 알아보자.
- HotSpot VM의 구조
- JIT 옵티마이저
- JVM의 구동 절차
- JVM의 종료 절차
- 클래스 로딩의 절차
- 예외 처리의 절차
OpenJDK 문서 중에는 HotSpot 관련 용어들을 풀이한 페이지(http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html)을 제공하고 있다.
1. HotSpot VM은 어떻게 구성되어 있을까?
자바 관련 문서들을 읽다 보면, HotSpot VM이라는 용어를 종종 접했을 것이다. HotSpot VM에 대해서 살펴보기 전에 HotSpot이 무엇인지 알아보자.(http://en.wikipedia.org/wiki/HotSpot)
HotSpot이라는 단어는 일반적으로 붙여 사용하지 않고, Hot Spot이라는 숙어로 사용된다. 단어를 직역하면 '뜨거운 지점'이라고 번역할 수 있지만, '분쟁 지역', '활기 넘치는 곳'이라는 의미로 사용된다. 이 단어는 자바에서 HotSpot이라는 한 단어로 쓰이며, 정확한 명칭은 'Java HotSpot Performance Engine'이다. 그런데, 왜 이렇게 이름을 지었을까?
자바를 만든 Sun에서는 자바의 성능을 개선하기 위해서 Just In Time(JIT) 컴파일러를 만들었고, 이름을 HotSPot으로 지었다. 여기서 JIT 컴파일러는 프로그램의 성능에 영향을 주는 지점에 대해서 지속적으로 분석한다. 분석된 지점은 부하를 최소화하고, 높은 성능을 내기 위한 최적화의 대상이 된다.
이 HotSpot은 자바 1.3 버전부터 기본 VM으로 사용되어 왔기 때문에, 지금 운영하고 있는 대부분의 시스템들은 모두 HotSpot 기반의 VM이라고 생각하면 된다. HotSpot VM은 세 가지 주요 컴포넌트로 되어 있다.
- VM(Virtual Machine) 런타임
- JIT(Just In Time) 컴파일러
- 메모리 관리자
HotSpot VM은 높은 성능과 확장성을 제공한다. 일럐로 JIT 컴파일러는 자바 애플리케이션이 수행되는 상황을 보고 동적으로 최적화를 수행한다.
JIT는 우리나라말로 하면 '적절한 시간'이라는 의미다. JIT를 사용한다는 것은 '언제나 자바 메서드가 호출되면 바이트 코드를 컴파일하고 실행 가능한 네이티브 코드로 변환한다'는 의미다. 하지만, 매번 JIT로 컴파일을 하면 성능 저하가 심하므로, 최적화 단계를 거치게 된다.
HotSpot VM의 아키텍처 그림을 보자.
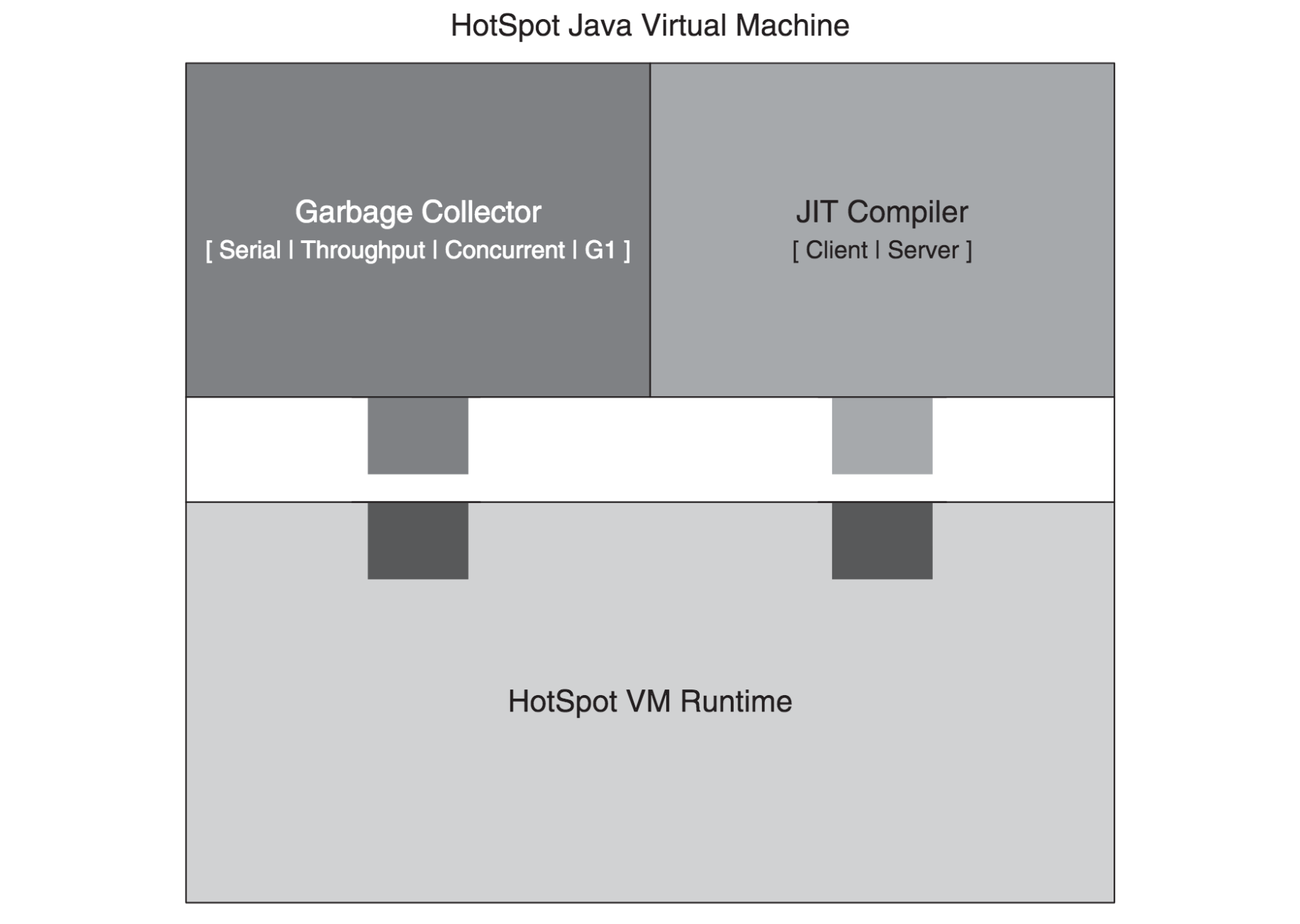
이 그림에서 보듯이 레고처럼 'HotSpot VM 런타임'에 'GC 방식'과 'JIT 컴파일러'를 끼워 맞춰 사용할 수 있다. 이를 위해서 'VM 런타임'은 JIT 컴파일러용 API와 가비지 컬렉터용 API를 제공한다. 그리고, JVM을 시작하는 런처와 스레드 관리, JNI 등도 VM 런타임 등에서 제공한다.
2. JIT Optimizer라는 게 도대체 뭘까?
HotSpot VM JIT 컴파일러에 대해서 자세히 이야기하기 전에 Client 버전과 Server 버전으로 나뉜다는 것을 기억해 두자.
컴파일이라는 작업은 상위 레벨의 언어로 만들어진 코드를 기계에 의존적인 코드로 변환하는 것을 말한다. 전통적으로 컴파일러인 C나 C++를 예를 들어 생각해 보자. C의 경우 먼저 소스코드에서 object 파일을 만들고, 이 object로 수행 가능한 라이브러리로 만든다. 이 작업은 애플리케이션이 수행되는 것과 비교해서 지속, 반복적으로 수행되지 않고 한 번만 수행된다. 그런데, 자바는 javac라는 컴파일러를 사용한다. 이 컴파일러는 소스코드를 바이트 코드로 된 class라는 파일로 변환해 준다. 그렇기 때문에 JVM은 항상 바이트 코드로 시작하여, 동적으로 기계에 의존적인 코드로 변환한다.
JIT는 애플리케이션에서 각각의 메서드를 컴파일할 만큼 시간적 여유가 많지 않다. 그러므로, 모든 코드는 초기에 인터프리터에 의해서 시작되고, 해당 코드가 충분히 많이 사용될 경우에 컴파일할 대상이 된다. HotSpot VM에서 이 작업은 각 메서드에 있는 카운터를 통해서 통제되며, 메서드에는 두 개의 카운터가 존재한다.
- 수행 카운터(invocation counter) : 메서드를 시작할 때마다 증가
- 백에지 카운터(backedge counter) : 높은 바이트 코드 인덱스에서 낮은 인덱스로 컨트롤 흐름이 변경될 때마다 증가
여기서 백에지 카운터는 메서드가 루프가 존재하는지를 확인할 때 사용되며, 수행 카운터 보다 컴파일 우선순위가 높다.
이 카운터들이 인터프리터에 의해서 증가될 때마다, 그 값들이 한계치에 도달했는지를 확인하고, 도달했을 경우 인터프리터는 컴파일을 요청한다. 여기서 수행 카운터에서 사용하는 한계치는 CompileThreshold이며, 백에지 카운터에서 사용하는 한계치는 다음의 공식으로 계산된다.
CompileThreshold * OnStackReplacePercentage / 100이 두개의 값들은 JVM이 시작할 때 지정 가능하며 다음과 같이 시작 옵션에 지정할 수 있다.
- XX:CompileThreshold=35000
- XX:OnStackReplacePercentage=80
즉, 이렇게 지정하면, 메서드가 3만 5천 번 호출되었을 때 JIT에서 컴파일을 하며, 백에지 카운터가 35,000 * 80 / 100 = 28,000이 되었을 때 컴파일된다.
컴파일이 요청되면 컴파일 대상 목록의 큐에 쌓이고, 하나 이상의 컴파일러 스레드가 이 큐를 모니터링한다. 만약 컴파일러 스레드가 바쁘지 않을 때는 큐에서 대상을 빼내서 컴파일을 시작한다. 보통 인터프리터는 컴파일이 종료되기를 기다리지 않는 대신, 수행 카운터를 리셋하고 인터프리터에서 메서드 수행을 계속 한다. 컴파일이 종료되면, 컴파일된 코드와 메서드가 연결되어 그 이후부터는 메서드가 호출되면 컴파일된 코드를 사용하게 된다. 만약 인터프리터에서 컴파일이 종료될 때까지 기다리도록 하려면, JVM 시작시 -Xbatch나 -XX:BackgroudCompilation 옵션을 지정하여 컴파일을 기다리도록 할 수도 있다.
HotSpot VM은 OSR(On Stack Replacement)라는 특별한 컴파일도 수행한다. 이 OSR은 인터프리터에서 수행한 코드 중 오랫동안 루프가 지속되는 경우에 사용된다. 만약 해당 코드의 컴파일이 완료된 상태에서 최적화되지 않는 코드가 수행되고 있는 것을 발견한 경우에 인터프리터에 계속 머무르지 않고 컴파일된 코드로 변경한다. 이 작업은 인터프리터에서 시작된 오랫동안 지속되는 루프가 다시는 불리지 않을 경우엔 도움이 되지 않지만, 루프가 끝나지 않고 지속적으로 수행되고 있을 경우에는 큰 도움이 된다.
Java 5 HotSpot VM이 발표되면서 새로운 기능이 추가되었다. 이 기능은 JVM이 시작될 때 플랫폼과 시스템 설정을 평가하여 자동으로 garbage collector를 설정하고, 자바 힙 크기와 JIT 컴파일러를 선택하는 것이다. 이 기능을 통해서 애플리케이션의 활동과 객체 할당 비율에 따라서 garbage collector가 동적으로 자바 힙 크기를 조절하며, New의 Eden과 Survivor, Old 영역의 비율을 자동적으로 조절하는 것을 의미한다. 이 기능은 -XX:+UseParallelGC와 -XX:+UseParallelOldGC에서만 적용되며, 이 기능을 제거하려면 -XX:-UseAdaptiveSizePolicy라는 옵션을 적용하여 끌 수가 있다.
3. JRockit의 JIT 컴파일 및 최적화 절차
아쉽게도 Oracle JVM의 경우 JIT 컴파일러 최적화에 대한 자세한 문서가 존재하지 않는다. 그런데, JRockit JVM과 IBM의 경우 문서화된 JIT 최적화 내용이 있으니 한 번 살펴 보자.
먼저 다음 그림을 보자.
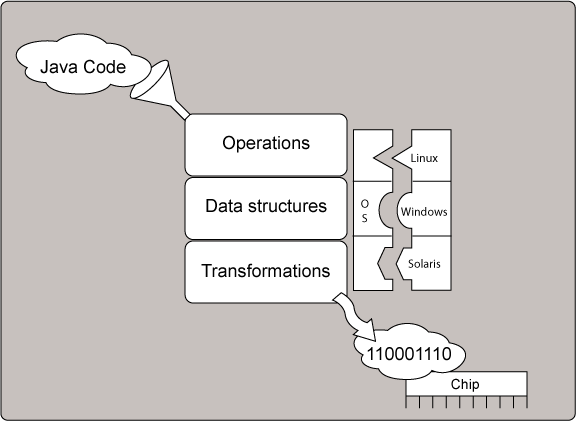
JVM은 각 OS에서 작동할 수 있도록 자바 코드를 입력 값(정확하게는 바이트 코드)으로 받아 각종 변환을 거친 후 해당 칩의 아키텍처에서 잘 돌아가는 기계어 코드로 변환되어 수행되는 구조로 되어 있다. 보다 상세한 최적화 절차는 다음의 그림을 보자.
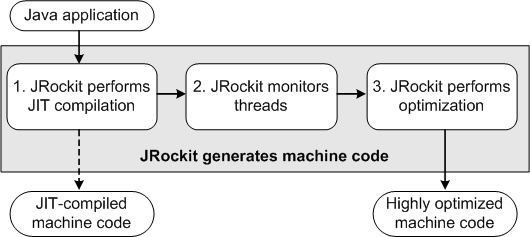
JRockit은 이와 같이 최적화 단계를 거치도록 되어 있으며, 각각의 단계는 다음과 같이 작업을 수행한다.
-
JRockit runs JIT Compilation
자바 애플리케이션을 실행하면 기본적으로는 1번 단계인 JIT 컴파일을 거친 후 실행이 된다. 이 단계를 거친 후 메서드가 수행되면, 그 다음부터는 컴파일된 코드를 호출하기 때문에 처리 성능이 빨라진다.
애플리케이션이 시작하는 동안 몇천 개의 새로운 메서드가 수행되며 이로 인해 다른 JVM보다 JRockit JVM이 더 느릴 수 있다. 그리고, 이 작업으로 인해 JIT가 메서드를 수행하고 컴파일하는 작업은 오버헤드가 되지만, JIT가 없으면 JVM은 계속 느린 상태로 지속될 것이다. 다시 말해서, JIT를 사용하면 시작할 때의 성능은 느리겟지만, 지속적으로 수행할 때는 더 빠른 처리가 가능하다. 따라서, 모든 메서드를 컴파일하고 최적화하는 작업은 JVM 시작 시간을 느리게 만들기 때문에 시작할 때는 모든 메서드를 최적화하지는 않는다. -
JRockit monitors threads
JRockit에는 'sampler thread'라는 스레드가 존재하며 주기적으로 애플리케이션의 스레드를 점검한다. 이 스레드는 어떤 스레드가 동작 중인지 여부와 수행 내역을 관리한다. 이 정보들을 통해서 어떤 메서드가 많이 사용되는지를 확인하여 최적화 대상을 찾는다. -
JRockit JVM Runs Optimization
'sampler thread'가 식별한 대상을 최적화한다. 이 작업은 백그라운드에서 진행되며 수행중인 애플리케이션에 영향을 주지는 않는다.
간단하게 JRockit JIT가 어떻게 동작하는지 살펴봤다. 실제로 코드가 어떻게 최적화되는지를 보면 이해가 좀 더 쉬울 것이다. 다음과 같이 간단한 A와 B 클래스가 있다.
Class A {
B b;
public void foo() {
y = b.get();
// 중간 생략
z = b.get();
sum = y + z;
}
}
Class B {
int value;
final int get() {
return value;
}
}foo()라는 메서드를 보면 y와 z 변수에 b.get()이라는 메서드를 호출하고, 그 결과를 더한다. 여기서 중복 호출이 되는 것을 알 수 있다. 게다가 B 클래스의 get() 메서드는 value 값만들 리턴하는 아주 단순한 코드다. 이 코드를 JRockit JIT 컴파일러에서는 다음과 같이 최적화한다.
Class A {
B b;
publid void foo() {
y = b.value;
// 중간 생략
sum = y + y;
}
}B 클래스의 코드는 전혀 바뀌지 않으며, A 클래스의 foo 클래스는 이와 같이 바뀐다. 아주 단순한 것 같지만 다음의 절차를 통해서 최적화 작업이 수행된다.
| 최적화 단계 | 코드 변환 | 설명 |
| 시작 단계 | 변경 없음 | |
| 1. final로 선언된 메서드 인라인(inline 처리) | public void foo() {
y = b.value; // 중간 생략 z = b.value; sum = y + z; } |
b.get()이 b.value로 변환된다.
이 작업을 통해서 메서드 호출로 인한 성능 저하가 개선된다. |
| 2. 불필요한 부하 제거 | public void foo() {
y = b.value; // 중간 생략 z = y; sum = y +z; } |
z와 y 값이 동일하므로, z에 y 값을 할당한다. |
| 3. 복제 | public void foo() {
y = b.value; // 중간 생략 y = y; sum = y + y; } |
z와 y의 값이 동일하므로 불필요한 변수인
z를 y로 변경한다. |
| 4. 죽은 코드 삭제 | public void foo() {
y = b.value; // 중간 생략 sum = y + y; } |
y = y 코드가 불필요하므로 삭제한다. |
이 절의 내용은 오라클 홈페이지에서 확인할 수 있다.
http://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/geninfo/diagnos/underst_jist.html
4. IBM JVM의 JIT 컴파일 및 최적화 절차
IBM JVM의 JIT 컴파일 방식은 5가지로 나뉜다.
- 인라이닝(Inlining)
- 지역 최적화(Local optimization)
- 조건 구문 최적화(Control flow optimization)
- 글로벌 최적화(Global optimization)
- 네이티브 코드 최적화(Native code generation)
인라이닝
메서드가 단순할 때 적용되는 방식이며, 호출된 메서드가 단순할 경우 그 내용이 호출한 메서드의 코드에 포함돼 버린다. 이렇게 될 경우 자주 호출되는 메서드의 성능이 향상된다는 장점이 있다.
지역 최적화(Local optimization)
작은 단위의 코드를 분석하고 개선하는 작업을 수행한다.
조건 구문 최적화(Control flow optimization)
메서드 내의 조건 구문을 최적화하고, 효율성을 위해서 코드의 수행 경로를 변경한다.
글로벌 최적화(Global optimizations)
메서드 전체를 최적화하는 방식이다. 매우 비싼 방식이며, 컴파일 시간이 많이 소요된다는 단점이 있지만, 성능 개선이 많이 될 수 있다는 장점이 있다.
네이티브 코드 최적화(Native code generatinon)
이 방식은 플랫폼 아키텍처에 의존적이다. 다시 말해서 아키텍처에 따라서 최적화를 다르게 처리하는 것을 말한다.
컴파일된 코드는 '코드 캐시(Code cache)'라고 하는 JVM 프로세스 영역에 저장된다. 결과적으로 JVM 프로세스는 JVM 수행 파일과 컴파일된 JIT 코드의 집합으로 구분된다.
이 절의 내용은 IBM 리눅스용 JDK 문서를 참고하였다.
http://publib.boulder.ibm.com/infocenter/java7sdk/v7r0/topic/com.ibm.java.Inx.70.doc/diag/understanding/jit.html
5. JVM이 시작할 때의 절차는 이렇다
java 명령으로 HelloWorld라는 클래스를 실행하면 어떤 단계로 수행될까? 간단히 정리해 보면 다음과 같다.
1) java 명령어 줄에 있는 옵션 파싱 :
일부 명령은 자바 실행 프로그램에서 적절한 JIT 컴파일러를 선택하는 등의 작업을 하기 위해서 사용하고, 다른 명령들은 HotSpot VM에 전달된다.
2) 자바 힙 크기 할당 및 JIT 컴파일러 타입 지정 : (이 옵션들이 명령줄에 지정되지 않았을 경우)
메모리 크기나 JIT 컴파일러 종류가 명시적으로 지정되지 않은 경우에 자바 실행 프로그램이 시스템의 상황에 맞게 선정한다. 이 과정은 좀 복잡한 과정(HotSpot VM Adaptive Tuning)을 거친다.
3) CLASSPATH와 LD_LIBRARY_PATH 같은 환경 변수를 지정한다.
4) 자바의 Main 클래스가 지정되지 않았으면, jar 파일의 manifest 파일에서 Main 클래스를 확인한다.
5) JNI의 표준 API인 JNI_CreateJavaVM를 사용하여 새로 생성한 non-primordial이라는 스레드에서 HotSpot VM을 생성한다.
6) HotSpot VM이 생성되고 초기화되면, Main 클래스가 로딩된 런처에서는 main() 메서드의 속성 정보를 읽는다.
7) CallStaticVoidMethod는 네이티브 인터페이스를 불러 HotSpot VM에 있는 main() 메서드가 수행된다. 이때 자바 실행 시 Main 클래스 뒤에 있는 값들이 전달된다.
추가로 5)에 있는 자바의 가상 머신(JVM)을 생성하는 JNI_CreateJavaVM 단계에 대해서 더 알아보자. 이 단계에서는 다음의 절차를 거친다.
1) JNI_CreateJavaVM은 동시에 두개의 스레드에서 호출할 수 없고, 오직 하나의 HotSpot VM 인스턴스가 프로세스 내에서 생성될 수 있도록 보장된다. HotSpot VM이 정적인 데이터 구조를 생성하기 때문에 다시 초기화는 불가능하기 때문에, 오직 하나의 HotSpot VM이 프로세스에서 생성될 수 있다.
2) JNI 버전이 호환성이 있는지 점검하고, GC 로깅을 위한 준비도 완료된다.
3) OS 모듈들이 초기화된다. 예를 들면 랜덤 번호 생성기, PID 할당 등이 여기에 속한다.
4) 커맨드 라인 변수와 속성들이 JNI_CreateJavaVM 변수에 전달되고, 나중에 사용하기 위해서 파싱한 후 보관한다.
5) 표준 자바 시스템 속성(properties)이 초기화된다.
6) 동기화, 메모리, safepoint 페이지와 같은 모듈들이 초기화된다.
7) libzip, libhpi, libjava, libthread와 같은 라이브러리들이 로드된다.
8) 시그널 처리기가 초기화 및 설정된다.
9) 스레드 라이브러리가 초기화된다.
10) 출력(output) 스트림 로거가 초기화된다.
11) JVM을 모니터링하기 위한 에이전트 라이브러리가 설정되어 있으면 초기화 및 시작된다.
12) 스레드 처리를 위해서 필요한 스레드 상태와 스레드 로컬 저장소와 초기화된다.
13) HotSpot VM의 '글로벌 데이터'들이 초기화된다. 글로벌 데이터에는 이벤트 로그(event log), OS 동기화, 성능 통계 메모리(perfMemory), 메모리 할당자(chunkPool)들이 있다.
14) HotSpotVMp에서 스레드를 생성할 수 있는 상태가 된다. main 스레드가 생성되고, 현재 OS 스레드에 붙는다. 그러나 아직 스레드 목록에 추가되지는 않는다.
15) 자바 레벨의 동기화가 초기화 및 활성화된다.
16) 부트 클래스로더, 코드 캐시, 인터프리터, JIT 컴파일러, JNI, 시스템 dictionary, '글로벌 데이터' 구조의 집합인 universe 등이 초기화된다.
17) 스레드 목록에 자바 main 스레드가 추가되고, universe의 상태를 점검한다. HotSpot VM의 중요한 기능을 하는 HotSpot VMThread가 생성된다. 이 시점에 HotSpot VM의 현재 상태를 JVMTI에 전달한다.
18) java.lang 패키지에 있는 String, System, Thread, ThreadGroup, Class 클래스와 java.lang의 하위 패키지에 있는 Method, Finalizer 클래스 등이 로딩되고 초기화된다.
19) HotSpot VM의 시그널 핸들러 스레드가 시작되고, JIT 컴파일러가 초기화되며, HotSpot의 컴파일 브로커 스레드가 시작된다. 그리고, HotSpot VM과 관련된 각종 스레드들이 시작한다. 이때부터 HotSpot VM의 전체 기능이 동작한다.
20) JNIEnv가 시작되며, HotSpot VM을 시작한 호출자에게 새로운 JNI 요청을 처리할 상황이 되었다고 전달해 준다.
이렇게 복잡한 JNI_CreateJavaVM 시작 단계를 거치고, 나머지 단계들을 거치면 JVM이 시작된다.
6. JVM이 종료될 때의 절차는 이렇다
그러면 JVM이 종료될 때는 어떤 절차를 거칠까? 만약 정상적으로 JVM을 종료시킬 때는 다음의 절차를 거치지만, OS의 kill -9와 같은 명령으로 JVM을 종료시키면 이 절차를 따르지 않는다는 것을 명심해야 한다.
만약 JVM이 시작할 때 오류가 있어 시작을 중지할 때나, JVM에 심각한 에러가 있어서 중지할 필요가 있을 때는 DestroyJavaVM이라는 메서드를 HotSpot 런처에서 호출한다.
HotSpot VM의 종료는 다음의 DestroyJavaVM 메서드의 종료 절차를 따른다.
1) HotSpot VM이 작동 중인 상황에서는 단 하나의 데몬이 아닌 스레드(nondaemon thread)가 수행될 때까지 대기한다.
2) java.lang 패키지에 있는 Shutdown 클래스의 shutdown() 메서드가 수행된다. 이 메서드가 수행되면 자바 레벨의 shutdown hook이 수행되고, finalization-on-exit이라는 값이 true일 경우에 자바 객체 finalizer를 수행한다.
3) HotSpot VM 레벨의 shutdown hook을 수행함으로써 HotSpot VM의 종료를 준비한다. 이 작업은 JVM_OnExit() 메서드를 통해서 지정된다. 그리고, HotSpot VM의 profiler, stat sampler, watcher, garbage collector 스레드를 종료시킨다. 이 작업들이 종료되면 JVMTI를 비활성화하며, Signal 스레드를 종료시킨다.
4) HotSpot의 JavaThread::exit() 메서드를 호출하여 JNI 처리 블록을 해제한다. 그리고, guard pages, 스레드 목록에 있는 스레드들을 삭제한다. 이 순간부터는 HotSpot VM에서는 자바 코드를 실행하지 못한다.
5) HotSpot VM 스레드를 종료한다. 이 작업을 수행하면 HotSpot VM에 남아 있는 HotSpot VM 스레드들을 safepoint로 옮기고, JIT 컴파일러 스레드들을 중지시킨다.
6) JNI, HotSpot VM, JVMTI barrier에 있는 추적(tracing) 기능을 종료시킨다.
7) 네이티브 스레드에서 수행하고 있는 스레드들을 위해서 HotSpot의 "vm exited" 값을 설정한다.
8) 현재 스레드를 삭제한다.
9) 입출력 스트림을 삭제하고, PerfMemory 리소스 연결을 해제한다.
10) JVM 종료를 호출한 호출자로 복귀한다.
이 절차를 거쳐 JVM이 종료된다.
7. 클래스 로딩 절차도 알고 싶어요?
자바 클래스가 메모리에 로딩되는 절차도 알아보자.
1) 주어진 클래스의 이름으로 클래스 패스에 있는 바이너리로 된 자바 클래스를 찾는다.
2) 자바 클래스를 정의한다.
3) 해당 클래스를 나타내는 java.lang 패키지의 Class 클래스의 객체를 생성한다.
4) 링크 작업이 수행된다. 이 단계에서 static 필드를 생성 및 초기화하고, 메서드 테이블을 할당한다.
5) 클래스의 초기화가 진행되며, 클래스의 static 블록과 static 필드가 가장 먼저 초기화 된다. 해당 클래스가 초기화 되기 전에 부모 클래스의 초기화가 먼저 이루어진다.
이렇게 나열하니 단계가 복잡해 보이지만, loading -> linking -> initializing로 기억하면 된다.
클래스가 로딩될 때 다음과 같은 에러가 밠애할 수 있다. 참고로, 일반적으로 이 에러들은 자주 발생하지 않는다.
- NoClassDefFoundError : 만약 클래스 파일을 찾지 못한 경우
- ClassFormatError : 클래스 파일의 포맷이 잘못된 경우
- UnsupportedClassVersionError : 상위 버전의 JDK에서 컴파일한 클래스를 하위 버전의 JDK에서 실행하려고 하는 경우
- ClassCircularityError : 부모 클래스를 로딩하는 데 문제가 있는 경우(자바는 클래스를 로딩하기 전에 부모 클래스들을 미리 로딩해야 한다.)
- IncompatibleClassChangeError : 부모가 클래스인데 implements를 하는 경우나 부모가 인터페이스인데 extends하는 경우
- VerifyError : 클래스 파일의 semantic, 상수 풀, 타입 등의 문제가 있을 경우
그런데 클래스 로더가 클래스를 찾고 로딩할 때 다른 클래스 로더에 클래스를 로딩해 달라고 하는 경우가 있다. 이를 'class loader delegation'이라고 부른다. 클래스 로더는 계층적으로 구성되어 있다. 기본 클래스 로더는 '시스템 클래스 로더'라고 불리며 main 메서드가 있는 클래스와 클래스 패스에 있는 클래스들이 이 클래스 로더에 속한다. 그 하위에 있는 애플리케이션 클래스 로더는 자바 SE의 기본 라이브러리에 있는 것이 될 수도 있고, 개발자가 임의로 만든 것일 수도 있다.
부트스트랩(Bootstrap) 클래스 로더
HotSpot VM은 부트스트랩 클래스 로더를 구현한다. 부트스트랩 클래스 로더는 HotSpot VM의 BOOTCLASSPATH에서 클래스들을 로드한다. 예를 들면, Java SE(Standard Edition) 클래스 라이브러리들을 포함하는 rt.jar가 여기에 속한다.
보다 빠른 JVM의 시작을 위해서 클라이언트 HotSpot VM은 '클래스 데이터 공유'라고 불리는 기능을 통해서 클래스를 미리 로딩할 수도 있으며, 이 기능은 기본적으로 켜져 있다. 이 기능은 -Xshare:on이라는 옵션을 상요해서 명시적으로 켤 수 잇으며, - Xshare:off 옵션을 사용해서 기능을 끈다. 그런데, 서버 HotSpot VM은 '클래스 데이터 공유' 기능을 제공하지 않고, 또 클라이언트 VM도 시리얼 GC를 사용하지 않을 경우에는 이 기능을 제공하지 않는다.
HotSpot의 클래스 메타데이터(Metadata)
HotSpot VM 내에서 클래스를 로딩하면 클래스에 대한 instanceKlass와 arrayKlass라는 내부적인 형식을 VM의 Perm 영역에 생성한다. instanceKlass는 클래스의 정보를 포함하는 java.lang.Class 클래스의 인스턴스를 말한다. HotSpot VM은 내부 데이터 구조인 klassOop라는 것을 사용하여 내부적으로 instanceKlass에 접근한다. 여기서 Oop라는 것은 ordinary object pointer의 약자다. 즉, klasOop는 클래스를 나타내는 ordinary object pointer를 의미한다.
내부 클래스 로딩 데이터의 관리
HotSpot VM은 클래스 로딩을 추적하기 위해서 다음의 3개 해시 테이블을 관리한다.
- SystemDictionary
로드된 클래스를 포함하며, 클래스 이름 및 클래스 로더를 키를 갖고 그 값으로 klassOop를 갖고 있다. SystemDictionary는 클래스 이름과 초기화한 로더의 정보, 클래스 이름과 정의한 로더의 정보도 포함한다. 이 정보들은 safepoint에서만 제거된다. - PlaceholderTable
현재 로딩된 클래스들에 대한 정보를 관리한다. 이 테이블은 ClassCircularity Error를 체크할 때 사용하며, 다중 스레드에서 클래스를 로딩하는 클래스 로더에서도 사용된다. - LoaderConstraintTable
타입 체크 시의 제약 사항을 추정하는 용도로 사용된다.
8. 예외는 JVM에서 어떻게 처리될까?
마지막으로 예외가 발생했을 때 JVM에서 어떻게 처리되는지 알아보자.
JVM은 자바 언어의 제약을 어겼을 때 예외(exception)라는 시그널(signal)로 처리한다. HotSpot VM 인터프리터, JIT 컴파일러 및 다른 HotSpot VM 컴포넌트는 예외 처리와 모두 관련되어 있다. 일반적인 예외 처리 경우는 아래 두 가지 경우다.
- 예외를 발생한 메서드에서 잡을 경우
- 호출한 메서드에 의해서 잡힐 경우
후자의 경우에는 보다 복잡하며, 스택을 뒤져서 적당한 핸들러를 찾는 작업을 필요로 한다.
예외는,
- 던져진 바이트 코드에 의해서 초기화 될 수 있으며,
- VM 내부 호출이 결과로 넘어올 수도 있고,
- JNI 호출로부터 넘어올 수도 있고,
- 자바 호출로부터 넘어올 수도 있다.
여기서 가장 마지막 경우는 단순히 앞의 세가지 경우의 마지막 단계에 속할 뿐이다.
VM이 예외가 던져졌다는 것을 알아차렸을 때, 해당 예외를 처리하는 가장 가까운 핸들러를 찾기 위해서 HotSpot VM 런타임 시스템이 수행된다. 이 때, 핸들러를 찾기 위해서는 다음의 3개의 정보가 사용된다.
- 현재 메서드
- 현재 바이트 코드
- 예외 객체
만약 현재 메서드에서 핸들러를 찾지 못했을 때는 현재 수행되는 스택 프레임을 통해서 이전 프레임을 찾는 작업을 수행한다. 적당한 핸들러를 찾으면, HotSpot VM 수행 상태가 변경되며, HotSpot VM은 핸들러로 이동하고 자바 코드 수행은 계속된다.
참고
- 자바 성능 튜닝 이야기
