ASCII 코드와 UTF-8 호환
아스키코드(ASCII)는 컴퓨터가 문자를 이해할 수 있도록 숫자와 문자를 1:1로 매칭시킨 국제적인 표준이다. 아스키코드는 한 문자당 1바이트, 즉 8비트의 데이터를 사용한다.
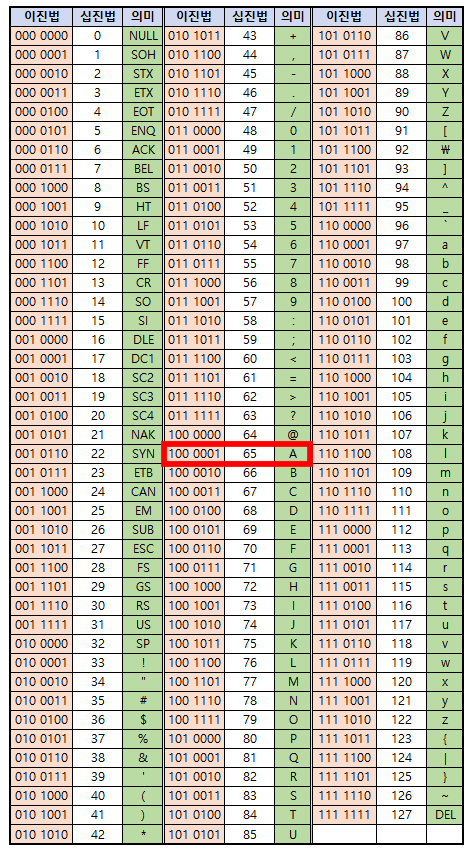
아스키코드는 한 문자당 1바이트, 8비트로 이루어져 있는데 이 표의 이진수는 7자리로 되어있다. 나머지 한 자리는 패리티 비트(parity bit)인데, 데이터의 에러를 감지하기 위해 사용한다. 일곱자리의 이진수에서 '1'의 개수가 홀수개이면 끝에 1을, '1'의 개수가 짝수개이면 끝에 0을 붙인다. 따라서, 패리티 비트를 제외하면 아스키코드는 총 7자리의 이진수를 문자로 나타낼 수 있기 때문에 총 2^7 = 128개의 문자를 나타낼 수 있다.
아스키코드 표를 보면 알파벳만 표현할 수 있는 것을 확인할 수 있다. 따라서 영어가 아닌 다른 언어권의 문자도 표현할 필요가 생겼고, 이에 따라 유니코드(Unicode)가 등장하게 되었다. 유니코드는 모든 언어의 문자를 정의하기 위해 2바이트(2^16=65,535)를 사용한다.
그러나 유니코드가 영어를 표현할 때는 1바이트, 한글을 표현할 때는 2바이트, 다른 특수문자를 표현할 때는 3바이트를 표현하는 가변적인 표현의 문제가 생겼다. 따라서 컴퓨터에게 혼란을 주지 않기 위해 어떤 글자는 1바이트로, 어떤 글자는 2바이트로 읽을지 정해줘야 한다.
위의 문제점을 보완하기 위해 유니코드에는 다양한 인코딩 방식이 존재한다. 인코딩 방식이란 컴퓨터가 어떤 글자를 만났을 때 얼만큼씩 읽어야 하는지 미리 말해주는 것이다. 유니코드의 인코딩 방식으로는 USC-2, USC-4, UTF-7, UTF-8, UTF-16, UTF-32 등이 있다.
UTF-8(8-bit Unicode Transformation Format)이란 문자열 집합과 인코딩 형태를 8비트 단위로 한다는 의미를 가지고 있다.
UTF-8에서는 유니코드 한 문자를 나타내기 위해서 1바이트에서 4바이트까지 사용하고 이를 가변길이 인코딩 방식이라고 한다. 아스키코드의 문자들은 1바이트로 하나의 문자를 표현할 수 있는데, 모든 문자를 4바이트로 표현하는 것은 지나친 저장소의 낭비가 된다. 따라서 아스키코드로 표현 가능한 것들은 1바이로 표현하고 그 이외의 문자는 2바이트 이상을 사용하는 방식이 UTF-8 방식이다.
그렇다면 어떻게 1바이트로 읽을지 4바이트로 읽을 지 알 수 있을까?
그것은 첫번째 바이트를 시작하는 비트가 어떤 것인지 보면 알 수 있다.
- 0xxxxxxx : 첫번째 바이트가 0으로 시작하면 0이외의 7비트를 아스키로 인식한다.
- 110xxxxx 10xxxxxx : 두번째 바이트까지 읽어서 하나의 문자로 표현
- 1110xxxx 10xxxxxx 10xxxxxx : 세번째 바이트까지 읽어서 하나의 문자로 읽어서 하나의 문자로 표현
- 111110xxx 10xxxxxx 10xxxxxx : 네번째 바이트까지 읽어서 하나의 문자로 표현
따라서 UTF-8과 아스키코드는 완벽하게 호환된다.
참고
