1. Fork/Join
자바 프로그램을 시작하면 하나의 프로세스가 시작하고, 그 프로세스에는 여러 개의 쓰레드가 동작한다. Java 7에서 추가된 클래스 중에는 Fork/Join과 관련된 클래스들이 존재한다. 여기서 Fork/Join이라는 것은 어떤 계산 작업을 할 때 "여러 개로 나누어 계산한 후 결과를 모으는 작업"을 의미한다. 즉, Fork는 여러 개로 나누는 것을 말하고, Join은 나누어서 작업한 결과를 모으는 것을 말한다.
그런데, Java 7에서 추가된 Fork/Join은 단순하게 작업을 쪼개고 그 결과를 받는 단순한 작업만을 포함하지 않는다. 여기에는 Work stealing이라는 개념이 포함되어 있다. 어떤 작업이 대기하고 있는 큐(Queue)가 있다고 할 때, 한쪽만 끝이 아니라 양쪽이 끝으로 인식되는 큐를 Dequeue라고 한다. 여려 개의 Dequeue에 작업이 나뉘어져 어떤 일이 진행될 때 만약 하나의 Dequeue는 매우 바쁘고, 다른 Dequeue는 바쁘지 않을 때가 있을 것이다. 이와 같은 상황에서 할 일이 없는 Dequeue가 바쁜 Dequeue에 대기하고 있는 일을 가져가서 해 주는 것이라고 생각하면 된다.
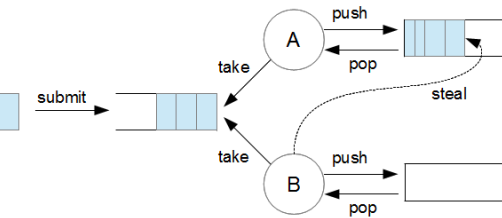
이러한 Work steal이라는 개념이 Fork/Join이라는 것에는 기본적으로 포함되어 있다. 다시 말하면, Fork/Join을 사용하면 별도로 구현하지 않아도 해당 라이브러리에서 Work steal 작업을 알아서 수행한다. 그리서 CPU가 많이 있는 장비에서 계산 위주의 작업을 매우 빠르게 해야 할 필요가 있을 때 매우 유용하게 사용할 수 있다.
Fork/Join 작업의 기본 수행 개념은 다음과 같다.
if(작업의 크기가 충분히 작을 경우){
해당 작업을 수행
}else{
작업을 반으로 쪼개어 두 개의 작업으로 나눔
두 작업을 동시에 실행시키고, 두 작업이 끝날 때까지 결과를 기다림이러한 식으로 Fork/Join이 실행되기 때문에 보통 이 연산은 회귀적으로(Recursive하게) 수행될 때 많이 사용된다. 여기서 회귀적이라는 말은 자신의 메소드를 자신이 부르는 경우를 말한다.
Fork/Join 기능은 java.util.concurrent 패키지의 RecursiveAction과 RecursiveTask라는 abstract 클래스를 사용해야 한다. 각 클래스의 선언은 다음과 같이 되어 있다.
| RecursiveAction | RecursiveTask |
| public abstract class RecursiveAction extends ForkJoinTask<Void> | public abstract class RecursiveTask extends ForkJoinTask<V> |
이 두 클래스의 차이는 뭘까? 클래스 선언문을 보며 생각해보자.
두 개의 클래스를 다시 비교해 보면
| 구분 | RecursiveTask | RecursiveAction |
| Generic | O | X |
| 결과 리턴 | O | X |
즉, RecursiveTask 클래스는 V라는 타입으로 결과가 리턴된다.
두 클래스 모두 ForkJoinTask라는 abstract 클래스를 확장한 것을 볼 수 있다.
public abstract class ForkJoinTask<V> extends Object
implements Future<V>, Serializable이 ForkJoinTask라는 클래스는 Future라는 인터페이스를 구현했다. 여기서 Future라는 인터페이스는 Java 5부터 추가된 인터페이스로 "비동기적인(asynchronoous) 요청을 하고 응답을 기다릴 때 사용"된다.
Fork/Join 작업을 수행하려면 RecursiveTask 클래스나 RecursiveAction 클래스를 확장하여 개발하면 된다. 두 클래스 모두 compute()라는 메소드가 있고, 이 메소드가 재귀 호출되고, 연산을 수행한다고 보면 된다.
작업을 수행하는 클래스를 만든 후에는 ForkJoinPool 클래스를 사용하여 작업을 시작한다. 이 클래스에서 제공하는 메소드는 용도에 따라서 다음과 같이 구분하여 사용한다.
| Fork/Join 클라이언트 밖에서 호출 | Fork/Join 클라이언트 내에서 호출 | |
| 비 동기적 호출 수행시 | execute(ForkJoinTask) | ForkJoinTask.fork() |
| 호출 후 결과 대기 | invoke(ForkJoinTask) | ForkJoinTask.invoke() |
| 호출 후 Future 객체 수신 | submit(ForkJoinTask | ForkJoinTask.submit() |
그러면 예제를 통해서 Fork/Join 클래스들을 어떻게 사용하는지 살펴보자. from부터 to까지의 합을 구하려면 다음과 같이 간단하게 구현하면 된다.
long total=0;
for(long loop=from;loop<=to;loop++){
total+=loop;
}이 로직을 Fork/Join으로 구현해보자. 그런데, 이렇게 간단한 계산은 그냥 for 루프를 실행하면 되지만, Fork/Join은 이보다 복잡한 연산을 여러 쓰레드에서 실행하기 위해서 만든 것이다. 이 for루프는 하나의 쓰레드로 수행하므로, 1개의 CPU만 사용할 수 밖에 없다. 다시 말해서 계산이 복잡하면 복잡할수록 Fork/Join의 효과는 크며, 계산을 수행하기 위해서 쓰레드를 관리할 필요가 없다는 것이 이 기능의 핵심이다.
그러면 RecursiveTask 클래스를 확장한 GetSum이라는 클래스를 다음과 같이 만들자.
package f.forkjoin;
import java.util.concurrent.RecursiveTask;
public class GetSum extends RecursiveTask<Long>{
long from, to;
public GetSum(long from, long to){
this.from = from;
this.to = to;
}
@Override
public Long compute() {
long gap = to - from;
if(gap <= 3){
long tempSum = 0;
for(long loop=from; loop<=to; loop++){
tempSum+= loop;
}
return tempSum;
}
long middle=(from+to)/2;
GetSum sumPre=new GetSum(from, middle);
sumPre.fork();
GetSum sumPost=new GetSum(middle+1, to);
return sumPost.compute() + sumPre.join();
}
}
이 예제를 실행하기 위한 클래스를 다음과 같이 만들자.
package f.forkjoin;
import java.util.concurrent.ForkJoinPool;
public class ForkJoinSample {
static final ForkJoinPool mainPool = new ForkJoinPool();
public static void main(String[] args){
ForkJoinSample sample = new ForkJoinSample();
sample.calculate();
}
public void calculate(){
long from = 0;
long to = 10;
GetSum sum = new GetSum(from, to);
Long result = mainPool.invoke(sum);
System.out.println("Fork Join:Total sum of "+from+" ~ "+to+" = "+result);
}
}실행 결과는 다음과 같다.
Fork Join:Total sum of 0 ~ 10 = 55그렇다면 내부적으로 GetSum 클래스는 어떻게 동작할가? 그 방법을 확인하기 위해서, 다음과 같이 log()라는 메소드를 만들고, 중간 중간에 값을 출력하도록 하자. 추가로 중간에 Thread.sleep() 메소드를 호출하여 결과를 출력하고 대기하도록 해놓았다.
package f.forkjoin;
import java.util.concurrent.RecursiveTask;
public class GetSum2 extends RecursiveTask<Long>{
long from, to;
public GetSum2(long from, long to){
this.from = from;
this.to = to;
}
@Override
public Long compute() {
long gap = to - from;
try{
Thread.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
log("From="+from+" To="+to);
if(gap <= 3){
long tempSum = 0;
for(long loop=from; loop<=to; loop++){
tempSum+= loop;
}
log("Return !! "+from+" ~ "+to+" = "+tempSum);
return tempSum;
}
long middle=(from+to)/2;
GetSum2 sumPre=new GetSum2(from, middle);
log("Pre From="+from+" To="+middle);
sumPre.fork();
GetSum2 sumPost=new GetSum2(middle+1, to);
log("Pre From="+(middle+1)+" To="+to);
return sumPost.compute() + sumPre.join();
}
public void log(String message){
String threadName = Thread.currentThread().getName();
System.out.println("["+threadName+"]"+message);
}
}package f.forkjoin;
import java.util.concurrent.ForkJoinPool;
public class ForkJoinSample2 {
static final ForkJoinPool mainPool = new ForkJoinPool();
public static void main(String[] args){
ForkJoinSample2 sample = new ForkJoinSample2();
sample.calculate();
}
public void calculate(){
long from = 0;
long to = 10;
GetSum2 sum = new GetSum2(from, to);
Long result = mainPool.invoke(sum);
System.out.println("Fork Join:Total sum of "+from+" ~ "+to+" = "+result);
}
}실행 결과는 다음과 같다.
[ForkJoinPool-1-worker-3]From=0 To=10
[ForkJoinPool-1-worker-3]Pre From=0 To=5
[ForkJoinPool-1-worker-3]Pre From=6 To=10
[ForkJoinPool-1-worker-5]From=0 To=5
[ForkJoinPool-1-worker-3]From=6 To=10
[ForkJoinPool-1-worker-3]Pre From=6 To=8
[ForkJoinPool-1-worker-5]Pre From=0 To=2
[ForkJoinPool-1-worker-3]Pre From=9 To=10
[ForkJoinPool-1-worker-5]Pre From=3 To=5
[ForkJoinPool-1-worker-5]From=3 To=5
[ForkJoinPool-1-worker-3]From=9 To=10
[ForkJoinPool-1-worker-9]From=0 To=2
[ForkJoinPool-1-worker-7]From=6 To=8
[ForkJoinPool-1-worker-7]Return !! 6 ~ 8 = 21
[ForkJoinPool-1-worker-3]Return !! 9 ~ 10 = 19
[ForkJoinPool-1-worker-9]Return !! 0 ~ 2 = 3
[ForkJoinPool-1-worker-5]Return !! 3 ~ 5 = 12
Fork Join:Total sum of 0 ~ 10 = 55각 단계별로 값을 확인해 보면 어떤 쓰레드에서, 어떤 순서로 연산이 수행되는지를 확인할 수 있을 것이다. 전혀 쓰레드 객체를 만들지도 않았고, 쓰레드 작업을 할당하지도 않았다. 그런 작업은 JVM에서 알아서 수행하며, 결과가 제대로 나오는지만 신경쓰면 된다. 여기서 worker의 개수는 CPU 개수만큼 증가한다.
2. NIO 2
자바의 NIO는 New I/O의 약자이며 JDk 1.4부터 제공되었다. NIO는 데이터를 보다 빠르게 읽고 쓰는 데 주안점을 두고 각종 API를 제공하고 있다. 어떻게 보면 이 NIO와 이름은 비슷하지만 크게 관련은 없는 NIO2라는 것이 Java 7부터 제공된다.
지금까지 자바에서 파일을 다루기 위해서 제공한 java.io 패키지의 File 클래스에 미흡한 부분이 많았다. 그래서 NIO2는 이를 보완하는 내용이 매우 많이 포함되어 있다.
자바에서 지금까지 다루지 않은 "파일의 속성"을 다룰 수 있으며, 심볼릭 링크(Symbolic link)까지 처리할 수 있는 기능을 제공한다. 또한, 어떤 파일이 변경되었는지를 쉽게 확인할 수 있는 WatchService라는 클래스도 제공된다. 그리고, 몇 가지 채널들도 추가되었다.
먼저 File 클래스를 어떻게 보완했는지 살펴보자. java.io 패키지의 File 클래스는 이름만 File이고, 실제로는 경로에 대한 정보를 담을 수 있어 사용할 때 많은 혼동이 있었다. 게다가, 확장성을 고려하지 않고 만들어졌기 때문에 많은 단점이 존재했다. 간단하게 Java 6까지 사용된 File 클래스의 단점들을 정리해 보면 다음과 같다.
- 심볼릭 링크, 속성, 파일의 권한 등에 대한 기능이 없음
- 파일을 삭제하는 delete() 메소드는 실패시 아무런 예외를 발생시키지 않고, boolean 타입의 결과만 제공해줌
- 파일이 변경되었는지 확인하는 방법은 lastModified()라는 메소드에서 제공해주는 long 타입의 결과로 이전 시간과 비교하는 수밖에 없었으며, 이 메소드가 호출되면 연계되어 호출되는 클래스가 다수 존재하여 성능상 문제도 많음
그렇다면 NIO2에서 File 클래스를 대체하는 클래스들을 알아보자.
| 클래스 | 설명 |
| Paths | 이 클래스에서 제공하는 static한 get() 메소드를 사용하면 Path라는 인터페이스의 객체를 얻을 수 있다. 여기서 Path라는 인터페이스는 파일과 경로에 대한 정보를 갖고 있다. |
| Files | 기존 File 클래스에서 제공되던 클래스의 단점을 보완한 클래스다. 매우 많은 메소드들을 제공하며, Path 객체를 사용하여 파일을 통제하는 데 사용된다. |
| FileSystems | 현재 사용중인 파일 시스템에 대한 정보를 처리하는 데 필요한 메소드를 제공한다. Paths와 마찬가지로 이 클래스에서 제공되는 static한 getDefault() 메소드를 사용하면 현재 사용중인 기본 파일 시스템에 대한 정보를 갖고 있는 FileSystem이라는 인터페이스의 객체를 얻을 수 있다. |
| FileStore | 파일을 저장하는 디바이스, 파티션, 볼륨 등에 대한 정보들을 확인하는 데 필요한 메소드들을 제공한다. |
여기서 나열된 모든 클래스들은 java.nio.file이라는 새로 추가된 패키지에 위치하고 있다. 이 중에서 자세히 살펴볼 클래스들은 Path/Paths와 Files 클래스다. 먼저 Paths 클래스를 살펴보자.
Paths 클래스는 생성자가 없고, 단지 두개의 static한 get()이라는 메소드를 통해 Path 객체를 얻을 수 있다.
| 리턴 타입 | 메소드 |
| static Path | get(String first, String... more) |
| static Path | get(URI uri) |
보는 것과 같이 디렉터리의 경로를 문자열로 지정하여 Path 객체를 얻을 수도 있고, URI 정보를 갖고 Path 객체를 얻을 수도 있다. 그리고, java.io 패키지에 있는 File 클래스의 toPath()라는 메소드를 통해서도 Path 객체를 얻을 수 있다. 이 클래스는 Java 7부터 추가되었다.
그러면 예제를 통해 Path에 대해서 살펴보자.
package f.niosecond;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.Files;
public class PathsAndFiles {
public static void main(String[] args){
PathsAndFiles sample = new PathsAndFiles();
String dir="C:\\godofjava\\nio\\nio2";
sample.checkPath(dir);
}
public void checkPath(String dir){
Path path = Paths.get(dir);
System.out.println(path.toString());
System.out.println("getFileName():"+path.getFileName());
System.out.println("getNameCount():"+path.getNameCount());
System.out.println("getParent():"+path.getParent());
System.out.println("getRoot():"+path.getRoot());
}
}checkPath() 메소드를 살펴보자. dir이라는 디렉터리 경로를 문자열로 받아서 Paths 클래스에 선언된 get() 메소드를 사용하여 객체를 생성한 것을 볼 수 있다. 이처럼 Path 객체는 Paths 클래스의 get() 메소드를 사용하면 쉽게 생성 가능하다. Paths 클래스의 get() 메소드를 호출하면 해당 메소드 내부에서는 다음과 같이 호출한다.
FileSystems.getDefault().getPath(first, more)즉, 파일 시스템의 기본 정보를 가져온 후 Path 정보를 얻는다.
실행 결과를 확인하자.
C:\godofjava\nio\nio2
getFileName():nio2
getNameCount():3
getParent():C:\godofjava\nio
getRoot():C:\그러면, 방금 살펴본 메소드 외에 주요한 메소드들의 기능을 다음 예제를 통해 살펴보자.
package f.niosecond;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.Files;
public class PathsAndFiles {
public static void main(String[] args){
PathsAndFiles sample = new PathsAndFiles();
String dir="C:\\godofjava\\nio\\nio2";
// sample.checkPath(dir);
String dir2="C:\\WINDOWS";
sample.checkPath2(dir, dir2);
}
public void checkPath(String dir){
Path path = Paths.get(dir);
System.out.println(path.toString());
System.out.println("getFileName():"+path.getFileName());
System.out.println("getNameCount():"+path.getNameCount());
System.out.println("getParent():"+path.getParent());
System.out.println("getRoot():"+path.getRoot());
}
public void checkPath2(String dir1, String dir2){
Path path = Paths.get(dir1);
Path path2 = Paths.get(dir2);
Path relativized = path.relativize(path2);
System.out.println("relativized path="+relativized);
Path absolute=relativized.toAbsolutePath();
System.out.println("toAbsolutePath path="+absolute);
Path normalized=absolute.normalize();
System.out.println("normalized path="+normalized);
Path resolved = path.resolve("godofjava");
System.out.println("resolved path="+resolved);
}
}이 예제에서는 Path에 정의된 relativize(), toAbsolutePath(), normalize(), resolve()를 사용하였다. 먼저 각 메소드에 대해 알아보자.
- relativize() 메소드는 매개 변수로 넘어온 Path와 현재 Path와의 상대 경로를 리턴한다. 즉, 현재 Path에서 매개 변수로 넘긴 경로로 커맨드 창으로 이동하려고 할 때 어떻게 이동해야 할지를 알려준다.
- toAbsolutePath() 메소드는 relativize() 메소드의 결과와 같이 상대 경로로 되어 있는 것을 절대 경로로 변경한다. 여기서의 절대 경로에는 ".."와 같은 경로는 그대로 남게 된다.
- normalize() 메소드는 경로상에 있는 "."이나 ".."을 없애는 작업을 한다.
- resolve() 메소드는 매개 변수로 넘어온 문자열을 하나의 경로로 생각하고, 현재 Path의 마지막 path로 추가한다. 참고로 이 메소드는 Path를 매개 변수로 받기도 한다.
실행 결과는 다음과 같다.
relativized path=..\..\..\WINDOWS
toAbsolutePath path=C:\Users\User\JavaProject\java04\..\..\..\WINDOWS
normalized path=C:\Users\WINDOWS
resolved path=C:\godofjava\nio\nio2\godofjava3. Files 클래스
이번에는 Files 클래스에 대해 알아보자. Files 클래스는 기존의 File 클래스에서 제공되는 기능보다 더 많은 기능을 제공한다. 이 클래스의 주요 기능을 나열해보면 다음과 같다.
| 기능 | 관련 메소드 |
| 복사 및 이동 | copy(), move() |
| 파일 디렉터리 등 생성 | createDirectories(), createDirectory(), createFile(), createLink(), createSymbolicLink(), createTempDirectory(), createTempFile() |
| 삭제 | delete(), deleteIfExists |
| 읽기와 쓰기 | readAllBytes(), readAllLines(), readAttributes(), readSymbolicLink(), write() |
| Stream 및 객체 생성 | newBufferedReader(), newBufferedWriter(), newByteChannel(), newDirectoryStream(), newInputStream(), newOutputStream |
| 각종 확인 | get으로 시작하는 메소드와 is로 시작하는 메소드들로 파일의 상태를 확인함(매우 많음) |
1) 파일 쓰기
먼저 파일에 쓸 내용을 ArrayList에 제공하는 메소드들을 다음과 같이 작성하자.
package f.niosecond;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class FileManager {
public List<String> getContents(){
List<String> contents = new ArrayList<String>();
contents.add("이 책은 저자의 6번째 책입니다.");
contents.add("필자의 수년간의 자바 경험을 바탕으로 집필되었습니다.");
contents.add("많은 분들에게 도움이 되면 좋겠습니다.");
contents.add("책에 대한 질문은 god@godofjava.com 으로 문의 주시기 바랍니다.");
contents.add("Current Date="+new Date());
return contents;
}
}이번에는 내용을 파일로 저장하는 메소드를 살펴보자.
public Path writeFile(Path path) throws Exception{ //1.
Charset charset = Charset.forName("EUC-KR"); //2.
List<String> contents = getContents();
StandardOpenOption openOption = StandardOpenOption.CREATE; //3.
return Files.write(path, contents, charset, openOption); //4.
}- 파일을 저장하는 writeFile() 메소드는 Path 객체를 매개 변수로 받아서 해당 경로의 파일에 데이터를 저장한다.
- 선언한 charset 객체는 저장되는 파일의 문자열 캐릭터 셋을 지정하는 것이다. getContents() 메소드에서 한글 데이터를 제공하기 때문에, 한글 타입으로 "EUC-KR"로 지정했다.
- openOperation이라는 것은 파일을 열 때의 조건을 이야기하는 것이다. StandardOpenOption은 Enum 클래스이며 어떤 항목이 있는지는 이후에 살펴본다.
- 마지막 줄에 있는 write() 메소드는 두가지가 있으며, 선언은 다음과 같이 되어 있다.
public static Path write(Path path, byte[] bytes, OpenOption ... options)
public static Path write(Path path, Iterable<? extends CharSequence> lines, Charset cs, OpenOption ... options))이 중 예제에서 사용한 것은 두 번째 메소드다. ArrayList가 Iterable 인터페이스를 구현했고, String은 Charsequence를 확장한 것이기 때문에 사용하는데 전혀 무리가 없다.
참고로 StandardOpenOption에는 다음의 항목들이 선언되어 있다.
| 항목 | 내용 |
| APPEND | 쓰기 권한으로 파열을 열고, 기존에 존재하는 데이터가 있으면 가장 끝부분부터 데이터를 저장할 때 사용 |
| CREATE | 파일이 존재하지 않으면 새로 생성할 때 사용 |
| CREATE_NEW | 파일을 생성하며, 만약 기존 파일이 있으면 실패로 간주함 |
| DELETE_ON_CLOSE | 파일을 닫을 때 삭제 |
| DSYNC | 파일을 수정하는 모든 작업이 동기적으로(순차적으로) 파일 저장소에서 처리되도록 할 때 사용 |
| READ | 읽기 권한으로 파일을 열 때 사용 |
| SPARSE | Sparse file, 파일을 Sparse 할 때 사용 |
| SYNC | 파일의 내용 및 메타 데이터에 대한 모든 업데이트는 순차적으로 파일 저장소에서 처리 되도록 할 때 사용 |
| TRUNCATE_EXISTING | 이미 존재하는 파일이 있을 때, 쓰기 권한으로 파일을 열고 해당 파일에 있는 모든 내용을 지울 때 사용 |
| WRITE | 쓰기 권한으로 파일을 열 때 사용 |
참고로 여기서 SYNC와 DSYNC의 차이는 메타 데이터까지 순차적으로 처리될지에 대한 부분만 다르다.
2) 파일 읽기
public void readFile(Path path) throws Exception{
Charset charset = Charset.forName("EUC-KR");
System.out.println("Path="+path);
List<String> fileContents = Files.readAllLines(path, charset);
for(String tempContents:fileContents){
System.out.println(tempContents);
}
System.out.println();
}이 readFile() 메소드는 파일을 읽어서 콘솔에 그 결과를 출력하는 예제이다. 즉, 방금 생성된 파일에 대한 위치 정보를 Path 객체로 받아서 파일을 읽는다. Files 클래스에 선언된 메소드 중 파일을 읽는 데 사용하는 메소드는 read로 시작하며, readAllBytes() 메소드와 readAllLines()라는 메소드가 있다.
public static byte[] readAllBytes(Path path)
public static List<String> readAllLines(Path path, Charset cs)readAllBytes() 메소드는 데이터는 바이트 배열로 받으며, readAllLines() 메소드는 List<String> 타입으로 결과를 받는다. 문자열 데이터를 읽기 때문에 Charset을 선언해 주도록 되어 있는 것을 볼 수 있다. 이 결과는 List로 리턴이 되기 때문에 반드시 java.util.List를 import 해주어야만 정상적으로 컴파일이 된다. 메소드 내용을 보면 알겠지만, 몇백 Mega Bytes나 몇 Giga bytes 짜리 파일을 이 메소드로 읽으면 당연히 OutOfMemoryError라는 예외가 발생한다. 따라서, 이 메소드는 파일의 용량이 작은 경우에만 사용해야 한다. 지금까지 만든 메소드들을 활용하는 writeAndRead() 메소드를 다음과 같이 만들자.
public Path writeAndRead(String fileName){
Path returnPath=null;
try{
Path path = Paths.get(fileName);
//Write a text file
returnPath=writeFile(path);
//Read written file
System.out.println("***** Created file contents *****");
readFile(returnPath);
}catch (Exception e){
e.printStackTrace();
}
return returnPath;
}파일 이름을 fileName이라는 문자열로 받아 Path 객체를 만든 후에 파일에 쓰고, 그 결과를 출력하도록 해 놓았다.
public static void main(String[] args){
FileManager sample = new FileManager();
String fileName = "AboutThisBook.txt";
Path fromPath = sample.writeAndRead(fileName);
}실행 결과
***** Created file contents *****
Path=AboutThisBook.txt
이 책은 저자의 6번째 책입니다.
필자의 수년간의 자바 경험을 바탕으로 집필되었습니다.
많은 분들에게 도움이 되면 좋겠습니다.
책에 대한 질문은 god@godofjava.com 으로 문의 주시기 바랍니다.
Current Date=Mon May 03 23:09:00 KST 2021윈도우 기준으로 C:\godofjava라는 디렉터리에 AboutThisBook.txt라는 파일이 반드시 존재해야 하며, 열어 보면 위에 출력된 내용과 동일한 값이 저장되어 있어야만 한다.
3) 파일 복사/이동/삭제하기
지금까지 제공된 자바의 기본 API를 사용하여 파일을 복사/이동하는 것은 쉽지 않았다. 삭제하는 것도 삭제가 되지 않으면 예외가 발생하는 것이 아니라 boolean 타입의 값만 리턴했다. 하지만 Files 클래스에서 제공되는 것은 다르다. 예제를 살펴보자.
public void copyMoveDelete(Path fromPath, String fileName){
try{
Path toPath=fromPath.toAbsolutePath().getParent();
// Make a directory if it is not exist.
Path copyPath=toPath.resolve("copied");
if(!Files.exists(copyPath)){
Files.createDirectories(copyPath);
}
// Copy file
Path copiedFilePath = copyPath.resolve(fileName);
StandardCopyOption copyOption = StandardCopyOption.REPLACE_EXISTING;
Files.copy(fromPath, copiedFilePath, copyOption);
// Read copied file
System.out.println("***** Copied file contents");
readFile(copiedFilePath);
// Move File
Path movedFilePath = Files.move(copiedFilePath, copyPath.resolve("moved.txt"), copyOption);
// Delete File
Files.delete(movedFilePath);
Files.delete(copyPath);
}catch (Exception e){
e.printStackTrace();
}
}예제가 길어서 복잡해 보이지만, 디렉터리 생성 -> 복사 -> 이동 -> 삭제의 단계를 거치는 것이므로 천천히 살펴보면 이해하기 어렵지 않을 것이다.
참고로 StandardCopyOption이라는 Enum 클래스에는 다음의 3개 항목이 선언되어 있다.
| 항목 | 내용 |
| ACTIVE_MOVE | 시스템 처리를 통하여 단일 파일을 이동, 복사를 할 때에는 사용 불가 |
| COPY_ATTRIBUTES | 새로운 파일에 속성 정보도 복사 |
| REPLACE_EXISTING | 기존 파일이 있으면 새 파일로 변경 |
main() 메소드를 변경한 뒤에 실행해보면 결과는 다음과 같다.
public static void main(String[] args){
FileManager sample = new FileManager();
String fileName = "AboutThisBook.txt";
Path fromPath = sample.writeAndRead(fileName);
sample.copyMoveDelete(fromPath, fileName);
}컴파일하고 실행한 결과는 다음과 같다.
***** Created file contents *****
Path=AboutThisBook.txt
이 책은 저자의 6번째 책입니다.
필자의 수년간의 자바 경험을 바탕으로 집필되었습니다.
많은 분들에게 도움이 되면 좋겠습니다.
책에 대한 질문은 god@godofjava.com 으로 문의 주시기 바랍니다.
Current Date=Mon May 03 23:30:34 KST 2021
***** Copied file contents
Path=C:\Users\User\JavaProject\java04\copied\AboutThisBook.txt
이 책은 저자의 6번째 책입니다.
필자의 수년간의 자바 경험을 바탕으로 집필되었습니다.
많은 분들에게 도움이 되면 좋겠습니다.
책에 대한 질문은 god@godofjava.com 으로 문의 주시기 바랍니다.
Current Date=Mon May 03 23:30:34 KST 2021이렇게 copy() 및 move() 메소드를 사용하면 아주 쉽게 파일을 복사하고, 이동할 수 있는 것을 볼 수 있다.
지금까지 Files 클래스의 주요 메소드를 살펴보았다. 추가로 Files 클래스에는 임시 디렉터리와 파일을 만들 수 있는 createTempDirectory(), createTempFile()이라는 메소드도 제공한다.
4. WatchService 클래스
어떤 프로그램을 작성하더라도, 파일이 변경되었는지 확인하는 작업이 필요하다. 특히 자바에서는 파일이 변경되었는지 확인하는 방법은 다음과 같은 꼼수밖에 없었다.
long lastModified = -1;
public boolean fileChangeCheck(String fileName){
boolean result = false;
File file = new File(fileName);
long modifiedTime=file.lastModified();
if(lastModified==-1){
lastModified=modifiedTime;
}else{
if(modifiedTime!=lastModified){
result=true;
}
}
return result;
}File 클래스에서 제공하는 lastModified() 메소드를 사용하여 최근에 변경된 파일의 시간을 가져와서 기존에 저장된 시간과 비교하는 방법이다. 이 방법을 사용하게 되면, lastModified() 메소드를 주기적으로 호출해야 한다는 단점이 존재하게 된다. 게다가 이 메소드를 한 번 호출하면 내부적으로 호출되는 연계된 메소드가 많아 성능에 영향이 적지 않았다.
이러한 단점을 보완하기 위해서 Java 7 부터는 WatchService라는 인터페이스를 제공한다. 이 WatchService는 쉽게 생각하면 문지기라고 보면 된다. 어떤 디렉터리 문 앞에 지키고 있다가, 누군가가 해당 디렉터리에 파일을 생성하거나, 수정하거나 삭제하면 WatchService를 고용한 주인에게 연락을 해 준다. 즉, 방금 살펴본 lastModified() 메소드를 사용하는 방법은 주기적으로 순찰을 돌아야 했지만, 이제는 항상 지키고 있는 담당자가 문제가 발생했을 때에만 알려준다고 보면 된다.
예제를 통해서 살펴보자.
package f.niosecond;
import java.io.File;
import java.io.IOException;
import java.nio.file.*;
import java.util.List;
import static java.nio.file.StandardWatchEventKinds.ENTRY_CREATE;
import static java.nio.file.StandardWatchEventKinds.ENTRY_DELETE;
import static java.nio.file.StandardWatchEventKinds.ENTRY_MODIFY;
public class WatcherSample extends Thread {
String dirName;
public static void main(String[] args) throws Exception{
String dirName = "C:\\godofjava";
String fileName = "WatcherSample.txt";
WatcherSample sample = new WatcherSample(dirName);
sample.setDaemon(true);
sample.start();
Thread.sleep(1000);
for(int loop=0; loop<10; loop++){
sample.fileWriteDelete(dirName, fileName+loop);
}
}
public WatcherSample(String dirName){
this.dirName = dirName;
}
public void run(){
System.out.println("### Watcher thread is Standard ###");
System.out.format("Dir=%s\n", dirName);
addWatcher();
}- 이 클래스의 생성자에는 감시하고자 하는 디렉터리 경로를 문자열로 받아서 dirName 이라는 인스턴스 변수에 저장해 둔다.
public void addWatcher(){
try{
Path dir = Paths.get(dirName);
WatchService watcher = FileSystems.getDefault().newWatchService(); //1.
WatchKey key = dir.register(watcher, ENTRY_CREATE, ENTRY_DELETE, ENTRY_MODIFY); //2.
while(true){
key = watcher.take(); //3.
List<WatchEvent<?>> eventList = key.pollEvents();
for(WatchEvent<?> event : eventList){ //4.
Path name = (Path) event.context(); //5.
if (event.kind() == ENTRY_CREATE){
System.out.format("%s created%n", name);
}else if(event.kind() == ENTRY_DELETE){
System.out.format("%s delete%n", name);
}else if(event.kind() == ENTRY_MODIFY){
System.out.format("%s modified\n", name);
}
}
key.reset(); //6.
}
}catch (IOException | InterruptedException e){
e.printStackTrace();
}
}
private void fileWriteDelete(String dirName, String fileName){
Path path = Paths.get(dirName, fileName);
String contents = "Watcher sample";
StandardOpenOption openOption = StandardOpenOption.CREATE;
try{
System.out.println("Write "+fileName);
Files.write(path, contents.getBytes(), openOption);
Files.delete(path);
Thread.sleep(100);
}catch(IOException | InterruptedException e){
e.printStackTrace();
}
}
}- WatchService 객체를 얻는다. 이 객체를 얻기 쉬운 방법은 FileSystems.getDefault()를 호출하여 기본 파일 시스템 객체를 얻은 후에, 그 객체의 newWatchService() 메소드를 호출하여 WatchService 객체를 얻는 것이다.
- Path 클래스에 선언되어 있는 register() 메소드를 사용하여 어떤 작업에 대해서 감시를 할 것인지를 지정한다. 여기서 register() 메소드는 다음과 같이 두 가지가 있다. 이 중에서 예제에서는 위에 있는 것을 사용했다. 리턴값인 WatchKey는 WatchService와 관련된 작업을 수행했을 때 받는 타입이다.
public WatchKey register(WatchService watcher, WatchEvent.kind<?>... events)
public WatchKey register(WatchService watcher, WatchEvent.kind<?>[] events, WatchEvent.Modifier ... modifiers)register() 메소드에 WatchService 다음에 있는 매개 변수들은 java.nio.file 패키지에 있는 StandardWatchEventKinds라는 클래스에 선언되어 있는 상수들이다.
StandardWatchEventKinds 클래스에 선언되어 있는 상수는 총 4가지가 있으며, register() 메소드에서는 이 중 3개의 상수를 선언하였다. 이렇게 상수를 지정하면, 지정된 3개의 상수에 해당하는 이벤트만 처리하겠다는 의미다.
-
선언된 3개의 이벤트 중 한 가지가 발생하면 watcher에 해당 이벤트가 등록되고, take() 메소드로 전달된다. take() 메소드 호출 부분에는 이벤트가 발생할 때까지 기다리게 된다. 이벤트를 받으면 WatchKey 인터페이스에 선언된 pollEvents() 메소드를 호출하면 WatchEvent 객체가 들어 있는 List 형태로 리턴한다.
List에 들어 있는 각 WatchEvent 객체를 꺼내기 위해서 for 루프를 실행해야만 한다. 일반적인 경우 이벤트는 하나만 저장되어 있으나, 두 개 이상 저장되어 있을 수도 있기 때문에, 이와 같이 처리해 주어야 정상적인 동작을 보장할 수 있다.
-
WatchEvent 인터페이스에 선언되어 있는 context() 메소드를 실행하면, 객체 선언시 선언했던 제네릭 타입을 리턴하는데, 일반적인 경우에는 Path 객체가 리턴된다.
-
모든 처리가 끝난 후에 key 객체에 reset() 메소드를 호출하면 여러 가지 조건에 따라서 처리되는데, 일반적으로는 이벤트가 다시 발생할 때까지 대기 상태로 넘어간다고 생각하면 된다.
실행결과는 다음과 같다.
### Watcher thread is Standard ###
Dir=C:\godofjava
Write WatcherSample.txt0
WatcherSample.txt0 created
WatcherSample.txt0 modified
WatcherSample.txt0 delete
Write WatcherSample.txt1
WatcherSample.txt1 created
WatcherSample.txt1 modified
WatcherSample.txt1 delete
Write WatcherSample.txt2
WatcherSample.txt2 created
WatcherSample.txt2 modified
WatcherSample.txt2 delete
Write WatcherSample.txt3
WatcherSample.txt3 created
WatcherSample.txt3 modified
WatcherSample.txt3 delete
Write WatcherSample.txt4
WatcherSample.txt4 created
WatcherSample.txt4 modified
WatcherSample.txt4 delete
Write WatcherSample.txt5
WatcherSample.txt5 created
WatcherSample.txt5 modified
WatcherSample.txt5 delete
Write WatcherSample.txt6
WatcherSample.txt6 created
WatcherSample.txt6 modified
WatcherSample.txt6 delete
Write WatcherSample.txt7
WatcherSample.txt7 created
WatcherSample.txt7 modified
WatcherSample.txt7 delete
Write WatcherSample.txt8
WatcherSample.txt8 created
WatcherSample.txt8 modified
WatcherSample.txt8 delete
Write WatcherSample.txt9
WatcherSample.txt9 created
WatcherSample.txt9 modified
WatcherSample.txt9 deleteC:\godofjava 디렉터리를 감시하기 시작했고, 파일이 생성, 수정, 삭제 작업을 수행한 것은 볼 수 있다. 수정 작업은 파일을 만든 후에 수정 작업이 수행되기 때문에 잡힌 것으로 보면 된다.
그리고, WatcherSample 클래스가 쓰레드로 동작하는데, setDaemon(true)로 지정했기 때문에, while 메소드가 종료되지 않아도 프로그램이 자동으로 멈춘다.
어떻게 보면, 예전에 사용했던 lastModified() 메소드를 사용하는 것이 더 간단하다고 생각할 수도 있다. 하지만, 그 메소드를 사용하면 필요 없는 작업이 수행되기 때문에 리소스 낭비가 심하다. 따라서, Java 7 이상을 사용한다면 lastModified() 보다는 WatchService를 사용하여 변경된 파일을 확인하는 것을 적극 권장한다.
5. 파일과 관련된 다른 새로운 API는 어떤 것들이 있을까?
지금까지 살펴본 것 외에 NIO2에서 추가된 클래스에는 다음과 같은 것들이 있다.
- SeekableByteChannel (random access)
- NetworkChannel 및 MulticastChannel
- Asynchronous I/O
SeekablyByteChannel (random access)
NIO의 채널에 대해서 알아보자. 채널은 디바이스, 파일, 네트워크 등과의 연결 상태를 나타내는 클래스라고 보면 된다. 파일을 읽거나 네트워크에서 데이터를 받는 작업을 처리하기 위한 통로라고 생각하면 이해가 쉬울 것이다.
Java 7에서 새로 추가된 SeekablyByteChannel이라는 인터페이스는 java.nio.channels 패키지에 선언되어 있으며, 바이트 기반의 채널을 처리하는 데 사용된다. 그리고, 현재의 위치를 관리하고, 해당 위치가 변경되는 것을 허용하도록 되어 있다. 따라서, 채널을 보다 유연하게 처리하는 데 사용된다.
NetworkChannel 및 MulticastChannel
NetworkChannel은 네트워크 소켓을 처리하기 위한 채널이다. 네트워크 연결에 대한 바인딩, 소켓 옵션을 셋팅하고, 로컬 주소를 알려주는 인터페이스다.
MulticastChannel은 IP 멀티캐스트를 지원하는 네트워크 채널이다. 여기서 멀티 캐스트라는 것은 네트워크 주소인 IP를 그룹으로 묶고, 그 그룹에 데이터를 전송하는 방식을 말한다.
AsynchronousFileChannel
Asynchronous라는 말은 비동기 처리를 의미한다. 자바 스크립트를 처리할 때 사용하는 AJAX도 여기에 속한다. 자바에서는 쓰레드를 구현하지 않는 이상 비동기 처리를 하기 어렵다. 작성한 메소드에 두 줄의 문장이 있다면, 첫 번째 줄의 처리가 끝날 때까지 두 번째 줄은 시작도 못한다. 하지만, 비동기 처리를 하게 되면 첫 번째 줄이 비동기 처리 문장이면, 두 번째 줄은 첫째 줄의 작업이 모두 끝나지 않아도 실행할 수 있다.
AsynchronousFileChannel을 처리한 결과는 java.util.concurrent 패키지의 Future 객체로 받게 된다. Future 인터페이스로 결과를 받지 않으면, CompletionHandler라는 인터페이스를 구현한 객체를 받을 수도 있다. 이 CompletionHandler는 모든 데이터가 성공적으로 처리되었을 때 수행되는 completed() 메소드와, 실패했을 때 처리되는 failed() 메소드를 제공하므로 필요에 따라 적절한 구현체를 사용하면 된다.
이 외에 AsynchronousChannelGroup이라는 것도 제공되는데, 이 그룹은 비동기적인 처리를 하는 쓰레드 풀(Thread pool)을 제공하여 보다 안정적으로 비동기적인 처리가 가능하다.
6. Fork/Join과 NIO2 외에 추가 및 변경된 것들을 간단히 살펴보자.
지금까지 살펴본 Fork/Join과 NIO2 이외에 Java 7에서 변경된 사항에 대해서 정리해 보면 다음과 같다.
- JDBC 4.1
- TransferQueue 추가
- Objects 클래스 추가
JDBC 4.1
JDBC의 버전이 4.1로 업그레이드 되면서 변경된 내용이 많다. 그 중에서 주목할 만한 것은 RowSetFactory와 RowSetProvider라는 클래스가 추가되었다. RowSet이라는 인터페이스는 JDK 1.4부터 제공되었는데, 이 인터페이스를 사용하면 Connection 및 Statement 객체를 생성할 필요 없이 SQL Query를 수행할 수 있다. RowSetFactory와 RowSetProvider를 사용하면 아주 쉽게 이 RowSet의 객체를 생성할 수 있다.
TranserQueue 추가
java.util.concurrent 패키지에 TransferQueue가 추가되었다. 이 인터페이스는 어떤 메시지를 처리할 때 유용하게 사용할 수 있다. 쓰레드와 관련된 공부를 더 자세히 하면 Producer/Consumer라는 패턴을 만나게 된다. 이 패턴은 특정 타입의 객체를 처리하는 쓰레드풀을 미리 만들어 놓고, 해당 풀이 객체들을 받으면 처리하도록 하는 구조를 의미한다. 이 기능을 보다 일반화하여 SynchronousQueue의 기능을 인터페이스로 끌어올리면서 좀 더 일반화해서 BlockingQueue를 확장한 것이다.
Objects 클래스 추가
java.util 패키지에 Objects라는 클래스가 추가되었다. 이 클래스는 compare(), equals(), hash(), hashCode(), toString() 등의 static한 메소드들을 제공한다. 이 클래스는 매개 변수로 넘어오는 객체가 null이라고 할지라도 예외를 발생시키지 않도록 구현해 놓은 것이 특징이다. 만약 null 체크를 할 것이 많고, 객체 두 개를 비교하는 등의 작업이 필요할 때에는 이 클래스를 활용하면 좋다.
참고
- 자바의 신
