1. Atomic 연산
예를 들어 i++를 원자 연산으로 분해해보자.
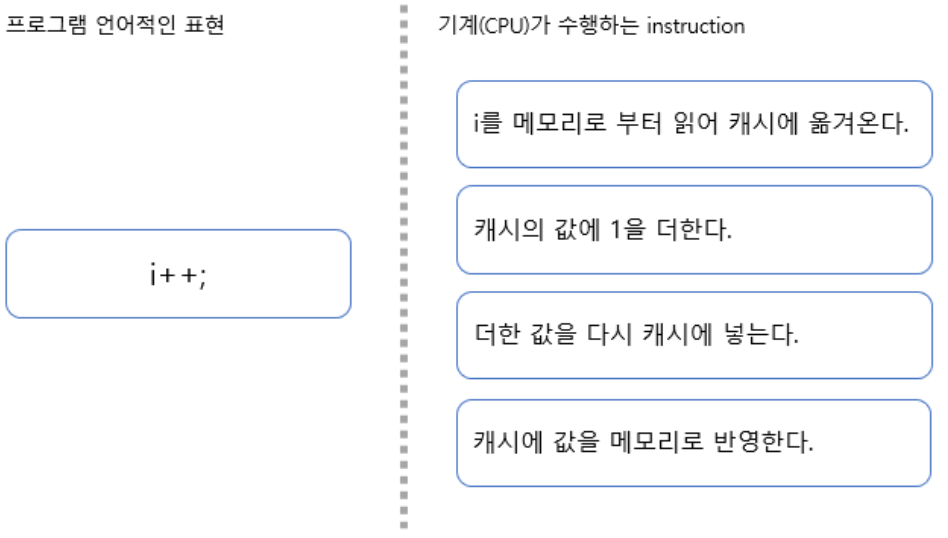
i++이 위 그림과 같이 캐싱을 배재하더라도 읽고 > 연산하고 > 저장하는 총 3가지의 Instruction이 수행된다. 이 원자단위의 연산이 수행 중에는 다른 Thread에 의해 컨트롤 되는 타 CPU의 개입이 있을 수 없는 최소 단위의 연산이라고 이해하면 된다. 여기에 Multi-Thread를 개입시키면 각 instruction의 수행 사이에 다른 thread의 공유메모리(변수)의 접근이 가능하여 값이 꼬이는 현상이 생기게 된다.
Atomic 연산이란 일련의 모든 연산이 끝나기 전에는 다른 프로세스가 해당 연산에 대해서 어떠한 변화도 줄 수 없어야 한다. 또한 전체 연산 중 하나라도 실패할 경우 모든 연산은 실패하며 시스템은 연산이 시작하기 전으로 복구되어야 한다. 즉 Atomic 연산이란 기본적으로 연산 수행 중 thread 전환이 되지 않는 것을 보장하는 연산을 일컫으며 이는 Context Switching을 발생시키지 않는다는 것이다.
2. Atomic 연산의 필요성
- 멀티 쓰레드 프로그램에서 여러 쓰레드간 공유되는 자원들은, 여러 쓰레드가 동시에 액세스하기 때문에 Race Condition이라는 경쟁이 돌입한다. 이를 막기 위해 보통 lock()을 사용한다. (윈도우의 경우 Critical Section)
- 이러한 각 자원들의 동기화(synchronization) 문제를 해결하기 위해 하드웨어에서 지원되는 Atomic operation의 개발로 많은 문제가 해결되고 있으며 lock-free 알고리즘이나 자료구조를 위한 툴로 많이 사용되고 있다.
3. Lock Free 알고리즘
synchronized 블럭과 Lock 객체를 사용하는 Blocking 동기화는 여러 가지 단점이 존재한다. 특히 성능 이슈가 가장 큰 문제이다. 어떤 Thread는 Lock을 확보하느라, 또 다른 Thread는 Lock을 확보하지 못해 Blocking 상태에 들어가느라 또 이 상태가 변경이 되는 동안 많은 시스템 자원이 쓰이고 이는 곧 성능 문제로 이어진다.
최근의 CPU는 이러한 문제를 해결하기 위해 atomic hardware primitives를 제공한다. 예를 들어 i++를 단일 연산으로 처리할 수 있는 방법을 제시하는 것이다. 이 instruction의 동작 원리는 다음과 같다.
- 인자로 기존 값과 변경할 값을 전달한다.
- 기존 값으로 던진 값이 현재 시스템이 가지고 있는 값과 같다면 변경할 값을 반영해준다. 반환 값으로 true를 리턴한다.
- 반대로 기존 값으로 던진 값이 현재 시스템이 가지고 있는 값과 다르다면 값을 반영하지 않고 false를 리턴한다.
이와 같은 연산 방식을 CAS(Compare and Swap)이라고 한다. 이를 이용하여 자료구조를 안전하게 처리하는 것을 lock-free 알고리즘이라고 한다.
만약 여러 쓰레드가 동시에 CAS 연산을 사용해 한 변수의 값을 변경하려고 한다면, 쓰레드 가운데 하나만 성공적으로 값을 변경할 것이고, 다른 쓰레드들은 모두 실패한다. 대신 값을 변경하지 못했다고 해서 Lock을 확보하는 것처럼 대기 상태에 들어가는 대신, 값을 변경하지 못했지만 다시 시도할 수 있다고 알림을 받는 셈이다. CAS 연산에 실패한 쓰레드들도 대기상태에 들어가지 않기 때문에 쓰레드마다 CAS 연산을 다시 시도할 것인지, 아니면 다른 방법을 취할 것인지, 아니면 아예 아무 조치도 취하지 않을 것인지 결정할 수 있다.
4. Non-Blocking 알고리즘
Lock 기반으로 동작하는 알고리즘은 항상 다양한 종류의 가용성 문제에 직면할 위험이 있다. Lock을 현재 확보하고 있는 쓰레드가 I/O 작업 때문에 대기 중이라거나, 메모리 페이징 때문에 대기 중이라거나, 기타 어떤
원인 때문에라도 대기 상태에 들어가면 다른 모든 쓰레드(Lock을 획득하기 위해 대기하고 있는)가 전부 대기 상태에 들어갈 가능성이 있다. 특정 쓰레드에서 작업이 실패하거나 또는 대기 상태에 들어가는 경우에, 다른 어떤 쓰레드라도 그로 인해 실패하거나 대기 상태에 들어가지 않는 알고리즘을 Non-Blocking 알고리즘이라고 한다. 또한 각 작업 단계마다 일부 쓰레드는 항상 작업을 진행할 수 있는 경우 Lock-Free 알고리즘이라고 한다. 쓰레드 간의 작업 조율을 위해 CAS 연산을 독점적으로 사용하는 알고리즘을 올바로 구현한 경우에는 대기 상태에 들어가지 않는 특성과 Lock-Free 특성을 함께 가지게 된다. 여러 쓰레드가 경쟁하지 않는 상황이라면 CAS 연산은 항상 성공하고, 여러 쓰레드가 경쟁을 한다고 해도 최소한 하나의 쓰레드는 반드시 성공하기 때문에 성공한 쓰레드는 작업을 진행할 수 있다. Non-Blocking 알고리즘은 Dead-Lock이나 우선 순위 역전(priority-inversion) 등의 문제점이 발생하지 않는다. 그러나 지속적으로 재시도만 하고 있을 가능성도 있기 때문에 라이브락 등의 문제점이 발생할 가능성이 있기는 하다.
5. LockSupport
Lock-Free 알고리즘은 Thread의 활동성을 제한하지 않도록 하다보니 경합이 발생했을 경우 Spin-Waiting 형태로 구현되는 경향이 있다. 즉, 진행되는 조건이 만족되지 않으면 계속해서 다시 시도하는 형태로 작동하게 된다는 말이다.
그런데 이 Spin-Waiting은 경합이 적은 경우에는 아주 효과적인 방법이지만, 경합이 많거나 동기화 구간이 큰 경우에는 CPU의 낭비를 가져오는 원인이 된다. 그래서 현실적으로는, 일정 조건 동안의 Spin-Waiting 이후에는 Thread를 블록시키는, 즉 잠재우도록 하는 형태로 알고리즘을 만들게 된다.
여기서 Thread를 블록시키는, 혹은 잠재운 다는 것은 단순히 일정시간 동안 Sleep 시키는 것이 아니라, 특정 조건이 만족되면 가능한 빠르게 다시 깨어나도록 하는 것도 포함되어야 한다.
기존의 Java에서는 Synchronized 도구(synchronized, wait, notify 등) 없이 Thread를 임의로 블록시키고 다시 재기동 시킬만한 도구가 없었다. (Thread.suspend와 Thread.resume은 deprecated 된 것이므로 사용하지 말아야 한다.) 따라서 synchronized 없이 Lock-Free하게 구현하는 알고리즘에서 특정 조건에 따라 Thread를 블록시키는 것이 마땅치 않았다.
그러나 java 1.5에 추가된 Concurrent Package에는 이를 위한 도구가 마련되었는데 바로 java.util.concurrent.lock.LockSupport가 그것이다.
가능한 Thread가 블록되지 않도록 알고리즘을 작성하다가 더이상 CPU를 낭비하지 않도록 Thread를 잠재우는 것이 필요한 경우에 해당 Thread 스스로가 LockSupport.park를 호출하면 그 Thread는 블록된다. 그 후 다른 Thread가 앞서 블록된 Thread에 대해 LockSupport.unpart를 호출해주면, 블록된 Thread는 깨어나서(즉 park 메소드가 리턴되면서) 활동을 재개하게 된다.
1. 해당 Thread가 park를 호출했고, 이후에 다른 Thread가 unpark를 호출해 준 경우
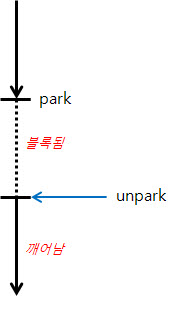
unpark한 시점에 해당 Thread는 깨어나게 된다.
2. 다른 Thread가 먼저 unpark를 호출한 후에 해당 Thread가 park를 호출한 경우
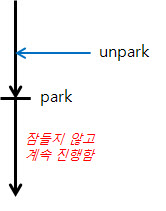
unpark 할 때 permition이 세팅되었으므로, park를 호출하더라도 잠들지 않고 바로 진행하게 된다.
3. 다른 Thread가 먼저 여러번 unpark를 호출한 후에 해당 Thread가 park를 호출한 경우
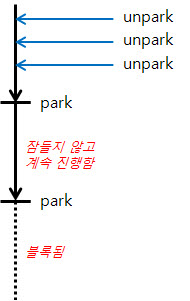
unpark를 여러번 하더라도 permition은 한 번만 세팅되므로, 처음 park를 호출했을 때는 잠들지 않고 바로 진행하게 되지만 이후 다시 park를 호출시에는 블록되게 된다.
park라는 인수를 통해 타임아웃을 세팅할 수도 있고, Thread.Interrupt를 통해 인터럽트도 깨울 수 있다. 다만 문서에는 park가 특별한 이유 없이 깨어날 수도 있다고 되어 있으므로, 알고리즘을 구현할 때는 park가 깨어났다고 해서 특정 조건이 만족된 상황이 아닐 수 있음을 가정하고, park에서 깨어난 이후에도 해당 조건이 만족되었는지 확인하는 코드를 넣어야 한다.
LockSupport를 써서 Thread를 블록시킨다는 것은 블록되어 대기하는 Thread의 리스트를 직접 관리해야 한다는 의미가 된다. synchronized, wait, notify 등의 도구를 쓰면 java 자체적으로 이 도구에 의해 블록된 Thread들이 관리되므로 알고리즘 안에서는 특별히 대기 Thread 리스트들을 관리할 필요가 없다. 하지만 LockSupport를 쓰기로 했다면 이 대기 Thread들에 대한 관리가 알고리즘에 포함되어야 한다. 어떤 Thread를 블록시키고, 또 이후에 어떤 블록된 Thread를 해제시킬지 결정할 수 있어야 하기 때문이다. 그러나 이것은 장점이 될 수도 있는데, java의 구현에 의존한 Thread 리스트 관리가 아니라, 직접적으로 세밀한 관리를 할 수 있기 때문이다. java의 Concurrent Package에 있는 알고리즘의 소스를 살펴보면 대기 Thread 리스트를 직접 관리하면서 LockSupport를 사용하는 것을 볼 수 있다.
참고
- https://m.blog.naver.com/PostView.nhn?blogId=jjoommnn&logNo=130169259898&proxyReferer=https:%2F%2Fwww.google.com%2F
- https://rightnowdo.tistory.com/entry/JAVA-concurrent-programming-Atomic%EC%9B%90%EC%9E%90%EC%84%B1
- https://its-fusion-blog.tistory.com/7
- https://effectivesquid.tistory.com/entry/Lock-Free-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98Non-Blocking-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
- http://cloudrain21.com/atomic-vs-non-atomic-calculation
- https://blog.daum.net/junek69/5
