1. Threadpool을 사용하는 이유
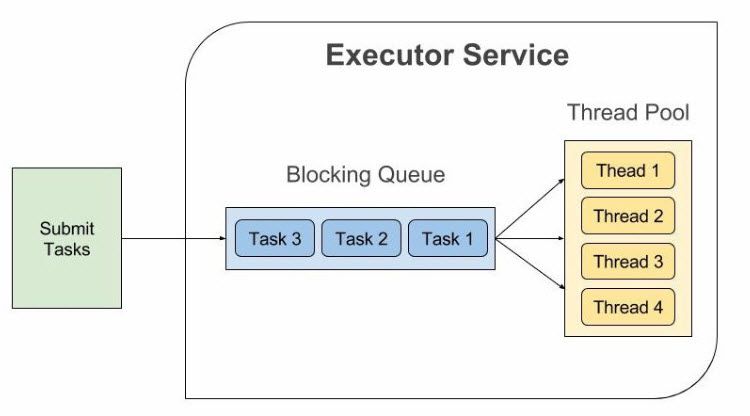
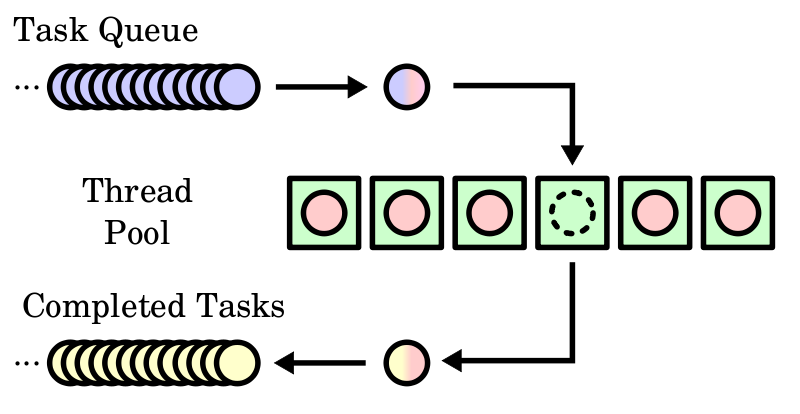
병렬 작업 처리를 하기 위해 멀티 쓰레드를 구현하게 되는데, 쓰레드가 과도하게 증가하면 쓰레드 생성과 스케줄링로 인해 CPU가 바빠져 메모리 사용량이 급격히 늘어나는 문제점이 발생하고, 이에 따라 애플리케이션의 성능 저하도 발생하게 된다.
이러한 단점을 상쇄하기 위해 쓰레드 풀(Threadpool)을 사용한다. 쓰레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고 작업 큐(Queue)에 들어오는 작업들을 하나씩 스레드가 맡아 처리하는 것이다. 작업 처리가 끝난 쓰레드는 다시 작업 큐에서 새로운 작업을 가져와 처리한다. 그렇기 때문에 작업 처리 요청이 증폭되어도 쓰레드의 전체 개수가 늘어나지 않으므로 애플리케이션의 성능이 급격히 저하되지 않는다.
쓰레드풀을 사용하는 이유를 2가지로 정리하면 다음과 같다.
1. 프로그램 성능 저하를 방지하기 위해
매번 발생하는 작업을 병렬처리하기 위해 쓰레드를 생성/수거하는 데 따른 부담은 프로그램 전체적인 퍼포먼스를 저하시킨다. 따라서 쓰레드풀을 만들어 놓고 사용한다.
쓰레드 또한 프로세스(JVM)가 할당한 메모리를 사용한다. 즉, 쓰레드를 생성하면 JVM 메모리를 소비하게 되는 것이다. Java8과 Java11에서는 쓰레드에게 최소 16KB에서 스택의 깊이가 최대로 늘어났을 때는 1MB의 메모리를 예약할당하게 된다. 쓰레드 자체도 레지스터와 스택을 가지고, 쓰레드도 컨텍스트 스위칭이 일어나기 때문에 쓰레드 생성에 따른 메모리 할당을 무시할 수 없다.
2. 다수의 사용자 요청을 처리하기 위해
대규모 프로젝트에서 특히 중요하다. 다수의 사용자의 요청을 수용하고, 빠르게 처리하고 대응하기 위해 쓰레드풀을 사용한다.
특히 Bottle Neck 현상이 발생하는 I/O 작업과 데이터베이스 작업에서 주로 사용된다. 쓰레드가 아무리 빠르게 생성되더라도 시스템 스케줄러에서 쓰레드의 우선순위를 매번 할당해야 하는데, 쓰레드풀을 이용하면 일정 쓰레드가 이미 생성되기 때문에 쓰레드풀에 의해 라이프 사이클이 관리되고, 쓰레드 풀에 의해 작업이 큐를 이용하게 되어 우선순위가 배분되고 처리된다.
2. Threadpool의 장단점
Thread pool의 장점
- 쓰레드를 생성/수거하는데 비용이 들지 않는다.
- 쓰레드가 생성될 때 OS가 메모리 공간을 확보해주고 메모리를 쓰레드에게 할당해준다.
- 쓰레드 풀을 미리 만들어 두기 때문에 처음에 생성하는 비용은 들지만 이전의 쓰레드를 재사용할 수 있으므로 시스템 자원을 줄일 수 있고, 작업을 요청 시 이미 쓰레드가 대기 중인 상태이기 때문에 작업을 실행하는 데 딜레이가 발생하지 않는다.
Thread pool의 단점
- thread pool에 thread를 너무 많이 생성해 두었다가 사용하지 않으면 메모리 낭비가 발생한다.
Thread pool의 단점 개선 : Fork Join Thread Pool
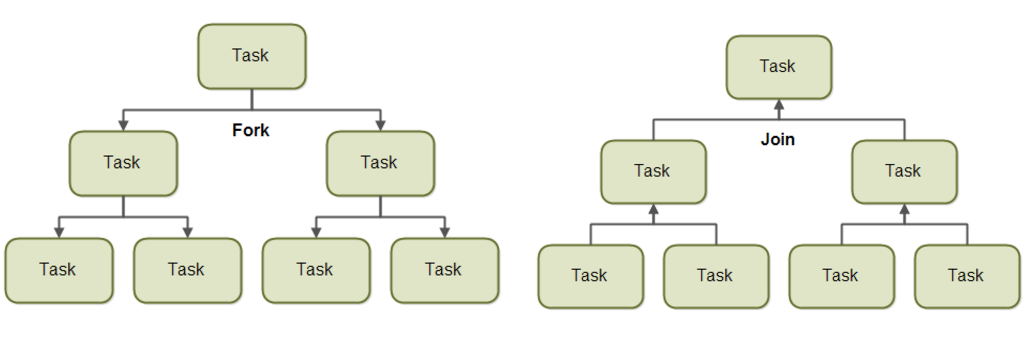
기존 쓰레드 풀을 개선하기 위한 방법으로 Java 7 이상의 쓰레드 풀에서 사용되고 있다. 기본적으로 큰 업무를 작은 업무로 나누어 배분해서, 일을 한 후에 일을 취합한 형태이다.
동작은 다음과 같다.
1. 작업을 하나의 큰 작업들로써 제공해준다.
2. 첫 쓰레드가 작업을 가져와 자신의 로컬 큐에 할당, 분할한다.
3. 두번째 쓰레드가 가져올 작업이 없다면, 첫 쓰레드의 큐에 있는 분할된 작업을 훔쳐간다.
4. 나머지 쓰레드도 반복
.png)
이렇게 Fork를 통해 업무를 분담하고 Join을 통해 업무를 취합한다. 자바에서 풀을 관리하는 ThreadPoolExecutor와 마찬가지로 ForkJoinPool도 내부에 inbound queue 라는 편지함이 하나 있다. 그걸 두고 싸우느라 시간을 낭비하는 것을 방지하기 위해 ForkJoinPool은 쓰레드 개별 큐를 만든다.
왼쪽에서 업무를 보내면(submit) 하나의 inbound queue에 누적되고 그걸 A와 B 쓰레드가 가져다가 일 처리를 한다. A와B는 각자 큐가 잇으며, 자신의 큐에 아무 업무가 없으면 상대방의 큐에서 업무를 훔쳐온다. 최대한 노는 쓰레드가 없게 하기 위한 알고리즘이다. 이는 쓰레드 자신의 task queue로 덱(deque)를 구현했기 때문이다. 덱은 양쪽 끝으로 넣다 뺐다 할 수 있는 독특한 자료구조이다. 각 쓰레드는 스택처럼 덱의 한쪽 끝에서만 일하며 나머지 한쪽 끝에는 잡을 훔치러 온 다른 쓰레드가 접근한다. 따라서 훔치러 온 쓰레드끼리 동일한 큐에서 경쟁을 벌일 수 있게 되어 잠재적인 문제가 발생할 수 있다. 쓰레드가 다른 쓰레드의 잡을 훔치러 갔다가 실패하는 경우가 빈번할 때 이런 문제가 발생할 수 있다. 이것을 막기 위해 "unemployed" 워커 쓰레드는 룰에 따라 휴식 상태로 바꾼다.
3. Threadpool 생성/종료/작업시키기
1. 쓰레드 풀 생성
java.util.concurrent 패키지를 사용하여 스레드 풀을 생성할 수 있다.
- Executor 클래스
- ExecutorService 인터페이스
ExecutorService 구현 객체는 Executors 클래스의 다음 두 가지 메소드 중 하나를 이용해 간편하게 생성할 수 있다. 생성방법에 앞서 알아야 할 개념이 있다.
초기 쓰레드 수 : ExcecutorService 객체가 생성될 때 기본적으로 생성되는 쓰레드 수
코어 쓰레드 수 : 쓰레드가 증가한 후 사용되지 않은 쓰레드를 쓰레드 풀에서 제거할 때 최소한으로 유지해야 할 수
최대 쓰레드 수 : 쓰레드 풀에서 관리하는 최대 쓰레드 수
- newCachedThreadPool()
- 초기 쓰레드 수, 코어 쓰레드 수는 0개이고 최대 쓰레드 수는 integer 데이터타입이 가질 수 있는 최대값이다.(Integer.MAX_VALUE)
- 쓰레드 개수보다 작업 개수가 많으면 새로운 쓰레드를 생성하여 작업을 처리한다.
- 만약 60초 동안 아무 일을 하지 않으면 쓰레드를 종료시키고 쓰레드풀에서 제거한다.
- newFixedThreadPool(int n Threads)
- 초기 쓰레드 수는 0개, 코어 쓰레드 수와 최대 쓰레드 수는 매개변수 n Threads 값으로 지정한다.
- 이 쓰레드 풀은 쓰레드 개수보다 작업 개수가 많으면 마찬가지로 쓰레드를 새로 생성하여 작업을 처리한다.
- 아무 일을 하지 않아도 쓰레드를 제거하지 않는다.
newCachedThreadPool().newFixedThreadPool() 메서드를 사용하지 않고 직접 쓰레드 개수들을 설정하고 싶다면 직접 ThreadPoolExecutor 객체를 생성하면 된다.
2. 쓰레드 풀 종료
쓰레드 풀에 속한 쓰레드는 기본적으로 데몬쓰레드(주 쓰레드를 서포트하기 위해 만들어진 쓰레드, 주 쓰레드 종료 시 강제 종료)가 아니기 때문에 main 쓰레드가 종료되어도 작업을 처리하기 위해 계속 실행 상태로 남아있다. 즉, main() 메서드의 실행이 끝나도 어플리케이션 프로세스는 종료되지 안흔다. 어플리케이션 프로세스를 종료하기 위해서는 쓰레드풀을 강제로 종료시켜 쓰레드를 해체시켜줘야 한다.
ExecutorService 구현객체는 기본적으로 3개 종료 메서드를 제공한다.
- executorService.shutdown()
- 작업 큐에 남아있는 작업까지 모두 마무리 후 종료 (오버헤드를 줄이기 위해 일반적으로 많이 사용)
- executorService.shutdownNow()
- 작업 큐에 남아있는 작업 잔량에 상관없이 강제 종료
- executorService.awaitTermination(long timeout, TimeUnit unit)
- 모든 작업 처리를 timeout 시간 안에 처리하면 true 리턴, 처리하지 못하면 작업쓰레드들을 interrupt() 시키고 false 리턴
3. ThreadPool에게 작업시키기
쓰레드 풀에게 작업을 시키기 전에 작업을 생성해야 작업처리를 요청할 수 있다. 작업 생성은 Runnable 인터페이스나 Callable 인터페이스를 구현한 클래스로 작업 요청할 코드를 삽입해 작업을 만들 수 있다. 이 두 인터페이스의 차이는 Runnable 인터페이스의 run() 메서드는 리턴 값이 없고, Callable의 call() 메서드는 리턴 값이 있다는 것이다.
쓰레드 풀에게 작업 처리 요청을 하기 위해서는 execute(), submit() 2가지 메서드가 있다.
- execute()
- 작업 처리 결과를 반환하지 않는다.
- 작업 처리 도중 예외가 발생하면 쓰레드가 종료되고 해당 쓰레드는 쓰레드 풀에서 제거된다.
- 다른 작업을 처리하기 위해 새로운 쓰레드를 생성한다.
- submit()
- 작업 처리 결과를 반환한다.
- 작업 처리 도중 예외가 발생하더라도 쓰레드는 종료되지 않고 다음 작업을 위해 재사용된다.
- 쓰레드의 생성 오버헤드 방지를 위해서라도 submit()을 가급적 사용한다.
4. 예제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | package ThreadPoolExample; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.ThreadPoolExecutor; public class main { public static void main(String[] args){ // ExecutorService 인터페이스 구현 객체 Executors 정적 메서드를 최대 쓰레드 ExecutorService executorService = Executors.newFixedThreadPool(2); for(int i = 0; i < 10; i++){ Runnable runnable = new Runnable() { @Override public void run() { // 쓰레드에게 시킬 작업 내용 ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorService; // 쓰레드 풀 사이즈 얻기 int poolSize = threadPoolExecutor.getPoolSize(); // 쓰레드 풀에 있는 해당 쓰레드 이름 얻기 String threadName = Thread.currentThread().getName(); System.out.println("[총 쓰레드 개수 : " + poolSize + "] 작업 쓰레드 이름 : " + threadName); // 일부러 예외 발생 시킴 int value = Integer.parseInt("예외"); } }; // 쓰레드풀에게 작업 처리 요청 executorService.execute(runnable); // executorService.submit(runnable); // 콘솔 출력 시간을 주기 위해 메인쓰레드 0.01초 sleep을 걸어둠 try{ Thread.sleep(10); }catch (InterruptedException e){ e.printStackTrace(); } } // 쓰레드풀 종료 executorService.shutdown(); } } | cs |
1. execute() 실행결과
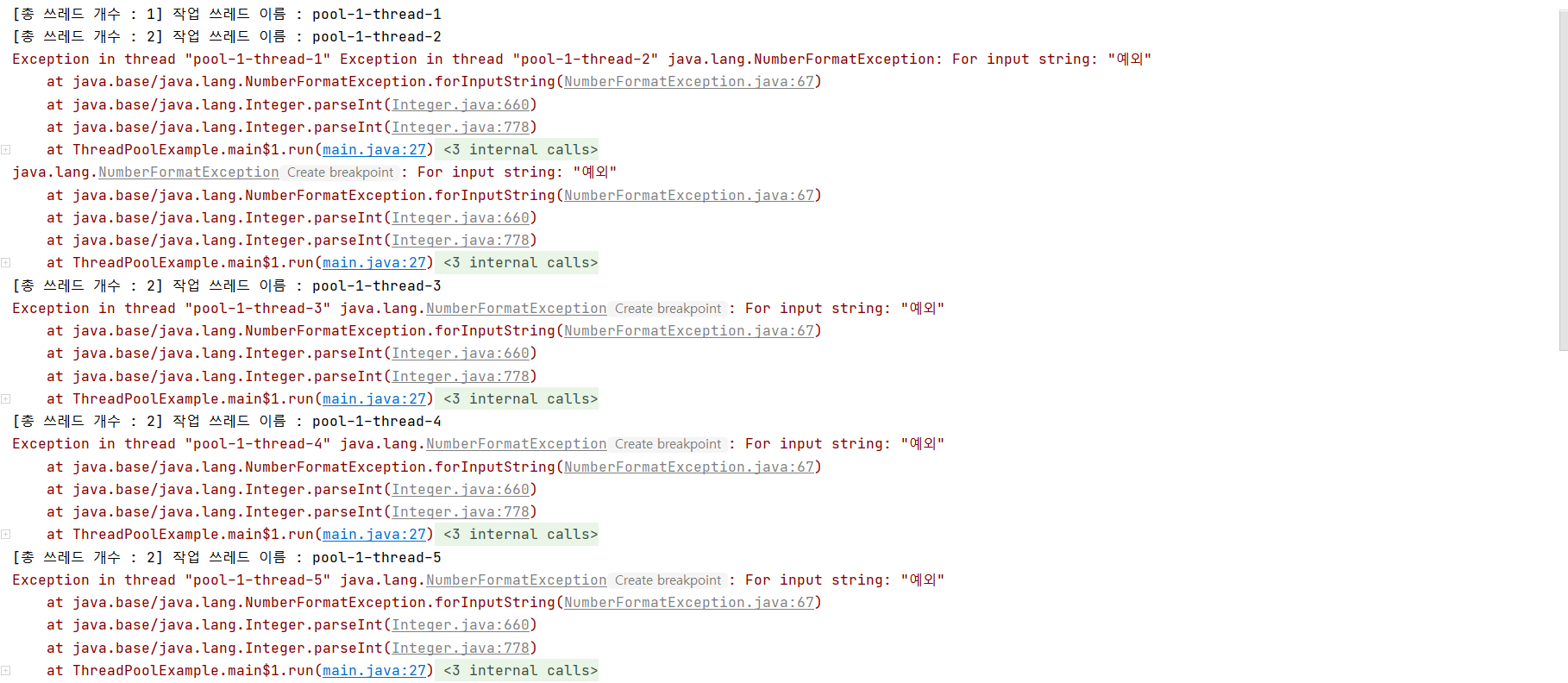
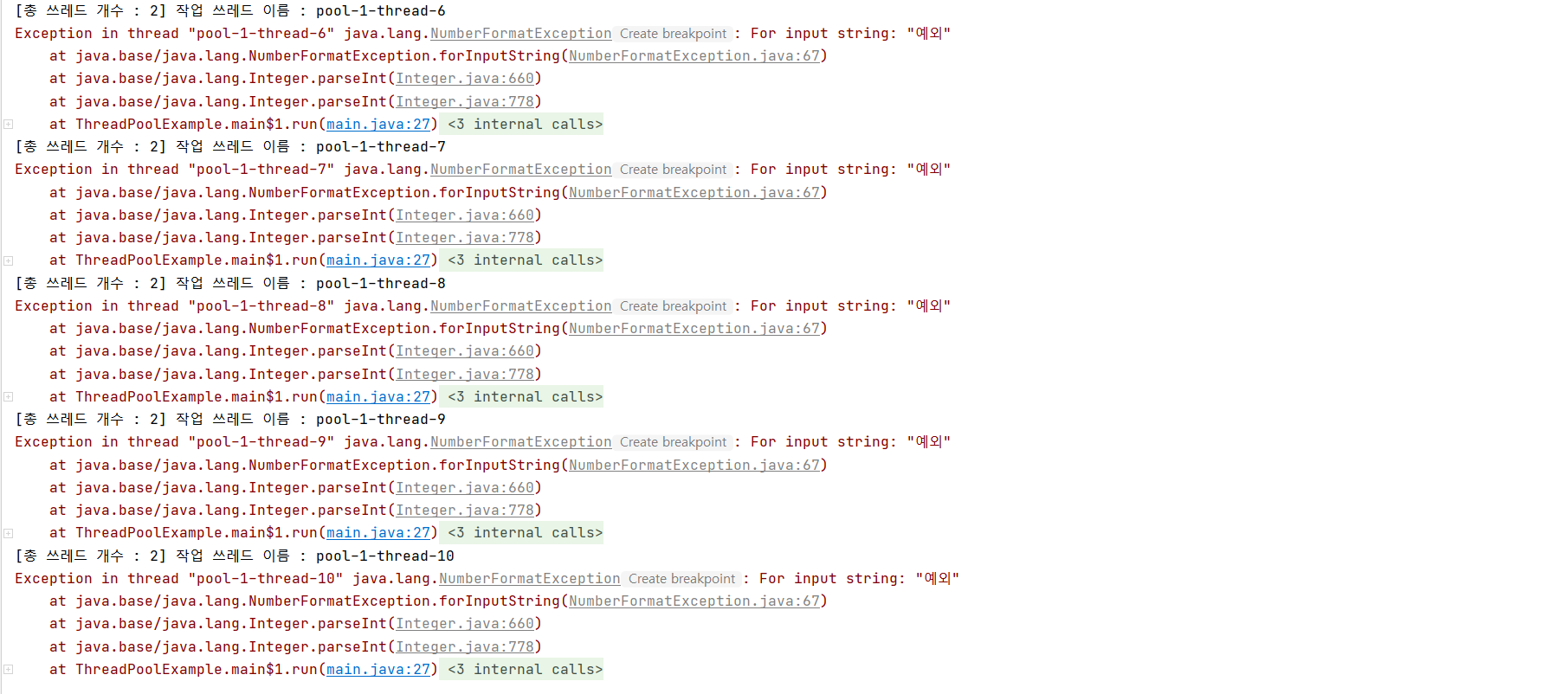
execute() 메서드를 실행시켰기 때문에 쓰레드 작업 중 예외가 나면 쓰레드를 바로 종료시키고 새로운 쓰레드를 생성한다. 따라서 결과가 thread-1, 2, 3, 4 ... 10까지 늘어나게 된다.
2. submit() 실행결과

submit() 메서드를 실행시키면, 위와 같이 예외가 발생되어도 해당 객체를 죽이지 않고 계속 재사용한다.
참고
- https://parkcheolu.tistory.com/30?category=654619
- https://velog.io/@agugu95/%EC%9E%90%EB%B0%94%EC%99%80-%EC%93%B0%EB%A0%88%EB%93%9C%ED%92%80-%EC%93%B0%EB%A0%88%EB%93%9C%EC%9D%98-%EC%83%9D%EC%84%B1%EB%B9%84%EC%9A%A9
- https://cornswrold.tistory.com/197
- https://m.blog.naver.com/PostView.nhn?blogId=qbxlvnf11&logNo=221240265744&proxyReferer=https:%2F%2Fwww.google.com%2F
- https://hamait.tistory.com/612
- https://jsravn.com/2019/05/01/jvm-thread-actual-memory-usage/
