1. 자바의 I/O
I/O는 만든 프로그램에 있는 어떤 내용을
- 파일에 읽거나 저장할 일이 있을 때
- 다른 서버나 디바이스로 보낼 일이 있을 때
사용한다. 즉, I는 Input, O는 Output의 약자로, 입력과 출력을 통칭하는 용어로 I/O라고 부르며, "아이오"라고 읽는다. I/O는 JVM을 기준으로 읽을 때에는 Input을, 파일을 쓰거나 외부로 전송할 때에는 Output이라는 용어를 사용한다.
초기 단계의 자바에서는 이러한 I/O를 처리하기 위해서 java.io 패키지에 있는 클래스만을 제공했다. 이 패키지에서는 바이트 기반의 데이터를 처리하기 위해서 여러 종류의 스트림(stream)이라는 클래스를 제공한다. 읽는 작업은 InputStream을 통해서, 쓰는 작업은 OutputStream을 통해서 작업하도록 되어 있다.
바이트가 아닌, char 기반의 문자열로만 되어 있는 파일은 Reader와 Writer라는 클래스로 처리한다. 이름에서 알 수 있듯이 읽을 때에는 Reader를, 쓸 때에는 Writer를 사용한다. 그런데 여기서 스트림이라는 것은 뭘까? 자바에서 스트림이라는 것은 끊기지 않고 연속적인 데이터를 말한다.
JDK 1.4부터는 보다 빠른 I/O를 처리하기 위해서 NIO(New I/O)라는 것이 추가 되었다. NIO는 스트림 기반이 아니라 버퍼(Buffer)와 채널(Channel) 기반으로 데이터를 처리한다.
그리고, Java 7에서부터는 NIO2라는 것이 추가되었다. 파일을 보다 효율적으로 처리하기 위해서 만들어졌으며, 기존에 있는 여러 단점들을 보완하고 있다.
2. 자바의 File과 Files 클래스
자바의 java.io 패키지에 File이라는 클래스가 있다. 이 클래스의 이름은 File이지만 정확하게는 파일만 가리키는 것이 아니라, 파일의 경로(path) 정보도 포함한다. File 클래스는 정체가 불분명하고, 심볼릭 링크(symbolic link)와 같은 유닉스 계열의 파일에서 사용하는 몇몇 기능을 제대로 제공하지 못한다. 그래서, java 7부터는 NIO2가 등장하면서 java.nio.file 패키지에 있는 Files 클래스에서 File 클래스에 있는 메소드들을 대체하여 제공한다. 그리고, File 클래스는 객체를 생성하여 데이터를 처리하는 데에 반하여, Files 클래스는 모든 메소드가 static으로 선언되어 있기 때문에 별도의 객체를 생성할 필요가 없다는 차이가 있다.
File 클래스는 파일 및 경로 정보를 통제하기 위한 클래스다. File 클래스는 생성한 파일 객체가 가리키고 있는 것이
- 존재하는지,
- 파일인지 경로인지,
- 읽거나, 쓰거나, 실행할 수 있는지
- 언제 수정되었는지
를 확인하는 기능과 해당 파일의
- 이름을 바꾸고,
- 삭제하고,
- 생성하고,
- 전체 경로를 확인
하는 등의 기능을 제공한다.
이 외에 File 객체가 가리키는 것이 파일이 아닌 경로일 경우에는 해당 경로에 있는
- 파일의 목록을 가져오거나,
- 경로를 생성하고,
- 경로를 삭제하는
등의 기능도 있다.
무엇보다도, 메소드를 사용하려면 File 객체를 생성해야 하니, 생성자들을 살펴보자.
| 생성자 | 설명 |
| File(File parent, String child) | 이미 생성되어 있는 File 객체(parent)와 그 경로의 하위 이름으로 새로운 File 객체를 생성한다. |
| File(String pathname) | 지정한 경로 이름으로 File 객체를 생성한다. |
| File(String parent, String child) | 상위 경로(parent)와 하위 경로(child)로 File 객체를 생성한다. |
| File(URI uri) | URI에 따른 File 객체를 생성한다. |
여기서 child라고 되어 있는 값은 경로가 될 수도 있고, 파일 이름도 될 수 있다. 그래서, 두 번째에 있는 pathname만 받는 생성자는 경로만 지정하는 것은 아니다. 만약 전체 경로와 파일 이름이 pathname에 지정되어 있을 경우에는 파일을 가리키는 File 객체가 된다. 그리고, 가장 마지막생성자에 있는 URI는 Uniform Resource Identifier의 약자로, 어떠한 리소스를 가리키기 위한 경로를 뜻한다.
3. File 클래스를 이용하여 파일의 경로와 상태를 확인해보자
예제 코드
package e.io;
import java.io.File;
public class FileSample {
public static void main(String[] args){
FileSample sample = new FileSample();
String pathName = "C:\\godofjava\\text";
// String pathname="/godofjava.text";
sample.checkPath(pathName);
}
public void checkPath(String pathName){
File file = new File(pathName);
System.out.println(pathName+" is exists? = "+file.exists());
}
}main() 메소드의 pathName 문자열을 보자. 보통 윈도우에서는 C:\godofjava\text와 같이 경로를 나타낼 때에는 역슬래쉬(혹은 원(\)기호를 한 번만 사용한다. 하지만, 자바에서는 String 안에 역슬래쉬를 한 번만 쓰면 그 뒤에 있는 단어에 따라서 미리 약속한 특수 기호로 인식한다. 예를 들면 탭(tab)을 타나내느 것은 \t이며, 다음 줄을 나타내는 것은 \n이다. 따라서 역슬래쉬를 나타내기 위해서는 두 개의 역슬래쉬를 연달아서 \\로 사용해야 한다. 이렇게 역슬래쉬로 처리를 하지만, 실제로는 탭과 줄바꿈 문자로 표현되는 것들을 "Escape character"라고 부른다.
그리고, OS마다 각 디렉터리를 구분하는 기호가 다르다. 예를 들어 유닉스 계열을 사용한다면 /로 디렉터리를 구분할 것이다. 이러한 모호함을 없애기 위해서, File 클래스에 separator라는 것이 static 변수로 존재한다. 따라서, 다음과 같이 사용하는 것이 안전하다.
String pathName = File.separator+"godofjava"+File.separator+"test";유닉스 계열의 OS에서 사용하는 /는 /를 두 개 쓸 필요 없이 하나만 쓰면 된다.
이 메소드를 실행한 결과를 확인해보자.

이렇게 존재하지 않는 디렉터리를 File 클래스를 사용하여 만들려면 mkdir()나 mkdirs()라는 메소드를 사용하면 된다. 왜 makedir이 아니라 mkdir일까? 왜냐하면, 윈도우 커맨드 창이나 유닉스의 콘솔에서 디렉터리를 만드는 명령어가 mkdir이기 때문이다.
그런데, 뒤에 s가 붙은 메소드와 붙지 않은 메소드의 차이는 뭘까?
차이는 단 하나다. mkdir() 메소드는 디렉터리를 하나만 만들고, mkdirs() 메소드는 여러 개의 하위 디렉터리를 만든다. 예를 들어 C:
\godofjava\text1\text2라는 경로를 만들려고 하면, mkdirs() 메소드를 사용하면 text1과 text2 디렉터리를 만든다. 반면 mkdir() 메소드는 디렉터리를 하위 디렉터리 하나만 만들기 때문에, 해당 경로의 디렉터리가 만들어지지 않는다.
예제 코드
public void makeDir(String pathName) {
File file = new File(pathName);
System.out.println("Make "+pathName+" result = "+file.mkdir());
}방금 만든 것은 디렉터리다. 그래서 File 객체가 나타내는 것이 파일인지 경로인지 알고 있지만, 매개 변수로 File 객체를 받았을 때에는 해당 객체가 파일을 나타내는지, 경로를 나타내는지 알 수가 없다. 그럴 때 사용하는 메소드가 바로 isDirectory()라는 메소드다. 반대로 파일인지 확인하려면 isFile() 메소드를 사용하면 된다. 추가로, 숨겨진 파일일 수도 있는데, 숨김 파일인지는 isHidden() 메소드를 사용하면 된다.
예제 코드
public void checkFileMethods(String pathName){
File file = new File(pathName);
System.out.println(pathName+" is directory? = "+file.isDirectory());
System.out.println(pathName+" is file? = "+file.isFile());
System.out.println(pathName+" is hidden? = "+file.isHidden());
}정상적인 상황이라면, makeDir() 메소드를 수행한 후 이 메소드를 수행했을 때의 결과는 순서대로 true, false, false를 리턴한다.
File 클래스의 메소드를 사용하여 현재 수행하고 있는 자바 프로그램이 해당 File 객체에 읽거나, 쓰거나, 실행할 수 있는 권한이 있는지를 확인할 수도 있다. 이렇게 권한을 확인할 때 사용하는 메소드는 can으로 시작하며, canRead(), canWrite(), canExecute() 메소드가 그 역할을 수행한다.
public void canFileMethods(String pathName){
File file = new File(pathName);
System.out.println(pathName+" can read? = "+file.canRead());
System.out.println(pathName+" can write? = "+file.canWrite());
System.out.println(pathName+" can execute? = "+file.canExecute());
}파일이나 경로가 언제 생성되었는지를 확인하는 File 클래스의 메소드는 lastmodified()다. 그런데, 이 메소드는 long 타입의 현재 시간을 리턴해 주기 때문에, java.util 패키지의 Date 클래스를 사용하여 시간을 확인하면 된다.
public void lastModified(String pathName){
File file = new File(pathName);
System.out.println(pathName+" last modified = "+new Date(file.lastModified()));
}마지막으로, 파일을 삭제하고자 할 때에는 delete() 메소드를 사용하면 된다. 이 메소드는 정상적으로 삭제한 경우에 true를 리턴한다.
3. File 클래스를 이용하여 파일을 처리하자.
이번에는 디렉터리가 아닌 파일을 처리하는 메소드를 예제를 통해서 살펴보자. 먼저 createNewFile()이라는 메소드를 사용하자. 이 메소드는 비어 있는 새로운 파일을 생성한다.
package e.io;
import java.io.File;
import java.io.IOException;
public class FileManagerClass {
public static void main(String[] args){
FileManagerClass sample = new FileManagerClass();
String pathName = File.separator+"godofjava"+File.separator+"text";
String fileName = "test.txt";
sample.checkFile(pathName, fileName);
}
public void checkFile(String pathName, String fileName){
File file = new File(pathName, fileName);
try{
System.out.println("Create result = " + file.createNewFile());
}catch (IOException e){
e.printStackTrace();
}
}
}createNewFile()이라는 메소드는 IOException을 던진다고 정해져 있기 때문에 이와 같이 try~catch로 묶어주었다. 그리고, 정상적으로 컴파일하기 위해서 java.io.IOException 클래스를 import 해주어야 한다.
실행 결과

그리고, 해당 경로에 text.txt 파일이 생성되어 있을 것이다. 이 파일은 아무런 데이터를 추가하지 않았기 때문에 파일을 열어봤자 데이터는 전혀 없다. 그리고, 만약 이 프로그램을 아무런 작업을 하지 않고 다시 실행하면, 이미 파일을 만들어 두었기 때문에, 실행 결과는 false로 출력될 것이다.
이번에는 파일의 정보를 확인하는 메소드들을 살펴보자. 다음과 같이 getFileInfo() 메소드를 만들고, checkFile() 메소드에서 호출하도록 하자.
public void checkFile(String pathName, String fileName){
File file = new File(pathName, fileName);
try{
System.out.println("Create result = " + file.createNewFile());
getFileInfo(file);
}catch (IOException e){
e.printStackTrace();
}
}
public void getFileInfo(File file) throws IOException{
System.out.println("Absolute path = "+file.getAbsolutePath());
System.out.println("Absolute file = "+file.getAbsoluteFile());
System.out.println("Canonical path = "+file.getCanonicalPath());
System.out.println("Canonical file = "+file.getCanonicalFile());
System.out.println("Name = "+file.getName());
System.out.println("Path = "+file.getPath());
}getFileInfo()의 메소드 중에서 File로 끝나는 메소드들은 File 객체를 리턴하고, Path로 끝나는 메소드들은 전체 경로를 String으로 리턴한다. 그리고, 아래에 있는 getName() 메소드는 파일일 경우에는 파일의 이름, 경로는 전체 경로를 String으로 리턴한다.
실행 결과

여기서 Absolute와 Canonical의 결과가 동일한 것을 볼 수 있다. Absolute는 단어 의미대로 "절대" 경로를 의미한다. Canonical은 "절대적이고, 유일한" 경로를 의미한다. 그냥 보면 별 차이가 없겠지만, file 객체의 경로가 상대 경로일 경우에는 결과가 달라진다.
만약 "C:\godofjava\a"라는 경로에서 자바를 실행하고, "C:\godofjava\b"라는 경로도 있다고 가정하자. "a" 디렉터리에서 "b" 디렉터리로 이동하려 "..\b"와 같이 상대 경로로 움직일 수 있다. 이 경우 Absolute 경로는 "C:\godofjava\a..\b"가 되고, Canonical 경로는 "C:\godofjava\b"가 된다. 즉, Canonical 경로는 절대적이고 유일하게 표현할 수 있는 경로를 말한다.
getPath() 메소드의 결과는 경로만이 아니라 파일 이름까지 포함되어 있는 것을 볼 수 있다. 단, 윈도우라 할지라도 앞에 C:\와 같이 드라이브 이름은 포함되어 있지 않다. 그런데, 파일 이름을 제외한 경로만을 확인하려면 어떻게 해야 할까?
여러 방법이 있겠지만 만약 해당 File 객체가 파일을 가리키고 있다면, getParent()라는 메소드를 사용하면 된다. 해당 메소드의 가장 마지막 줄에 다음과 같이 한 줄을 추가하면 된다.
System.out.println("Parent = "+file.getParent());이렇게 getParent() 메소드를 사용하면, 파일 이름을 제외한 경로만을 출력한다.
4. 디렉터리에 있는 목록을 살펴보기 위한 list 메소드들
File 클래스에 대한 설명의 마지막으로 list 메소드에 대해 살펴보자. File 클래스에 있는 list로 시작하는 메소드에는 다음의 6개가 있다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| static File[] | listRoots() | JVM이 수행되는 OS에서 사용중인 파일 시스템의 루트(root) 디렉터리 목록을 File 배열로 리턴한다. static 메소드이므로, File 객체를 별도로 생성할 필요가 없다. |
| String[] | list() | 현재 디렉터리의 하위에 있는 목록을 String 배열로 리턴한다. |
| String[] | list(FilenameFilter filter | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 String 배열로 리턴한다. |
| File[] | listFiles() | 현재 디렉터리의 하위에 있는 목록을 File 배열로 리턴한다. |
| File[] | listFiles(Filter filter) | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 File 배열로 리턴한다. |
| File[] | listFiles(FilternameFilter filter | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 File 배열로 리턴한다. |
가장 앞에 있는 listRoots() 메소드는 설명에 있는 대로, 파일 시스템의 루트 디렉터리 목록을 제공한다. 예를 들어 윈도우 시스템에 여러 드라이브가 지정되어 있으면, "C:\", "D:\"와 같이 각 드라이브의 루트 디렉터리 목록을 제공한다. 그리고, 유닉스 계열의 OS는 기본 디렉터리인 "/"와 함께 추가로 마운트되어 있는 파일 시스템의 루트 디렉터리 목록이 제공된다.
그리고, File 클래스에서 제공하는 파일 목록을 확인하는 메소드는 list()와 listFiles()로 구분할 수 있다. list() 메소드의 경우 리턴값이 String의 배열이며, listFiles() 메소드의 경우는 리턴값이 파File의 배열이다. 매개 변수가 없는 메소드들은 직관적으로 보기에도 파일의 목록에 해당한다는 것을 알 수 잇을 것이다. 그런데, 이 메소드들의 매개 변수로 넘어가는 FileFilter와 FilenameFilter는 도대체 뭘까? 만약 디렉터리에 .txt로 끝나는 텍스트 파일과 .jpg로 끝나는 이미지 파일이 있다고 가정해보자. 처리하고자 하는 파일이 이미지 파일이라면, .txt로 끝나는 텍스트 파일은 전혀 필요 없을 것이다. 매개 변수가 없는 list 관련 메소드를 사용하면, 리턴된 객체들을 검색하여 일일이 대상 파일인지를 확인해야만 한다. 하지만, 필터를 지정하는 생성자를 사용하면 목록을 가져올 때부터 필요한 파일만 선택할 수 있다.
예제를 살펴보기에 앞서, 두 Filter 인터페이스에 선언되어 있는 메소드들에 어떤 것들이 있는지 확인해보자. 먼저 FileFilter 인터페이스에 선언되어 있는 메소드들은 다음과 같다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| boolean | accept(File pathname) | 매개 변수로 넘어온 File 객체가 조건에 맞는지 확인한다. |
이번에는 FilenameFilter 인터페이스에 선언된 메소드를 보자.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| boolean | accept(File dir, String name) | 매개 변수로 넘어온 디렉터리(dir)에 있는 경로나 파일 이름(name)이 조건에 맞는지 확인한다. |
이 두 개의 필터는 모두 인터페이스로 선언되어 있다. 따라서 어떤 조건을 주려면, 이 인터페이스를 구현해야만 한다. 구현한 클래스의 객체를 list로 시작하는 메소드의 매개 변수로 넘겨주려면, 메소드에서 파일이나 경로를 만날 때마다 여기에 있는 accept() 메소드가 자동으로 수행된다. 따라서, accept() 메소드를 어떻게 구현했느냐에 따라서, 필요한 파일의 목록이 달라진다.
Filefilter를 구현하여 .jpg인 파일만 가져오려고 하면 다음과 같이 구현할 수 있다.
package e.io;
import java.io.File;
import java.io.FileFilter;
public class JPGFileFilter implements FileFilter {
@Override
public boolean accept(File file) {
if(file.isFile()){
String fileName = file.getName();
if(fileName.endsWith(".jpg")) return true;
}
return false;
}
}이번에는 FilenameFilter를 구현한 예를 살펴보자.
package e.io;
import java.io.File;
import java.io.FilenameFilter;
public class JPGFilenameFilter implements FilenameFilter {
@Override
public boolean accept(File file, String fileName) {
if(fileName.endsWith(".jpg")) return true;
return false;
}
}보다시피 FileNameFilter는 메소드 매개 변수로 fileName이 넘어오기 때문에 별도로 File 객체의 getName() 메소드를 호출할 필요가 없다. 언뜻 보면, FilenameFilter가 더 좋아 보이지만, 디렉터리와 파일을 구분하지 못하기 때문에, 만약 jpg로 끝나는 디렉터리가 있으면 필터로 걸러낼 수 없다.
이 디렉터리에 있는 이미지 파일 목록을 가져오는 코드는 다음과 같다.
예제 코드
package e.io;
import java.io.File;
public class FileFilterSample {
public static void main(String[] args){
FileFilterSample sample = new FileFilterSample();
String pathName = File.separator+"godofjava"+File.separator+"text";
sample.checkList(pathName);
}
public void checkList(String pathName){
File file;
try{
file = new File(pathName);
File[] mainFileList = file.listFiles();
//File[] mainFileList = file.listFiles(new JPGFilenameFilter());
for(File tempFile:mainFileList){
System.out.println(tempFile.getName());
}
}catch (Exception e){
e.printStackTrace();
}
}
}.이나 ..은 현재 디렉터리와 상위 디렉터리를 의미하므로 파일 목록에 포함되지 않는다.
5. InputStream과 OutputStream은 자바 스트림의 부모들이다
이제 본격적으로 데이터의 입력과 출력을 다루는 방법을 살펴보자. 자바의 I/O는 기본적으로 InputStream과 OutputStream이라는 abstract 클래스를 통해서 제공된다. 따라서, 어떤 대상의 데이터를 읽을 때에는 InputStream의 자식 클래스를 통해서 읽으면 되고, 어떤 대상의 데이터를 쓸 때에는 OutputStream의 자식 클래스를 통해서 쓰면 된다.
먼저 InputStream에 대해 알아보자. 간만에 클래스 선언문부터 살펴보자.
public abstract class InputStream
extends Object
implement Closeable앞서 말한대로 abstract 클래스로 선언되어 있다. 따라서, InputStream 클래스를 제대로 사용하려면, 이 클래스를 확장한 자식 클래스들을 살펴봐야만 한다. 그런데 여기서 구현한 Closeable이라는 인터페이스는 무엇일까? 이 인터페이스에는 close()라는 메소드만 선언되어 있는데, 어떤 리소스를 열었던 간에 이 인터페이스를 구현하면 해당 리소스는 close() 메소드를 이용하여 닫으라는 것을 의미한다. 이름에서 알 수 있듯이, 해당 인터페이스가 "닫을 수 있다"는 것을 의미한다. 하지만, 해당 메소드를 다른 클래스에서도 작업할 수 있도록, java.io 패키지에 있는 클래스를 사용할 때는 하던 작업이 종료되면 close() 메소드로 "항상" 닫아 주어야 한다.
참고로 여기서 "리소스"라는 것은 파일이 될 수도 있고, 네트워크 연결도 될 수 있다. 스트림을 통해서 작업할 수 있는 모든 것을 리소스라고 생각하면 된다.
간단하게, InputStream 클래스에 어떤 메소드들이 선언되어 있는지 확인해보자.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| int | available() | 스트림에서 중단없이 읽을 수 있는 바이트의 개수를 리턴한다. |
| void | mark(int readlimit) | 스트림에서 현재 위치를 표시(mark)해 둔다. 여기서 매개 변수로 넘긴 int 값은 표시해 둔 자리의 최대 유효 길이이다. 이 값이 넘어가면, 표시해 둔 자리는 더 이상 의미가 없어진다. |
| void | reset() | 현재 위치를 mark() 메소드가 호출되었던 위치로 되돌린다. |
| boolean | markSupported() | mark()나 reset() 메소드가 수행 가능한지를 확인한다. |
| abstract int | read() | 스트림에서 다음 바이트를 읽는다. 이 클래스에서 선언된 유일한 abstract 메소드다. |
| int | read(byte[] b) | 매개 변수로 넘어온 바이트 배열에 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| int | read(byte[] b, int off, int len) | 매개 변수로 넘어온 바이트 배열에 특정 위치(off)부터 지정한 길이(len) 만큼의 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| long | skip(long n) | 매개 변수로 넘어온 길이(n) 만큼의 데이터를 건너 뛴다. |
| void | close() | 스트림에서 작업중인 대상을 해제한다. 이 메소드를 수행한 이후에는 다른 메소드를 사용하여 데이터를 처리할 수 없다. |
이 중에서 꼭 기억해야 되는 메소드는 read()와 close()이다. 데이터를 읽을 때에는 read() 메소드를 사용하면 되고, 해당 리소스를 닫을 때에는 close() 메소드를 호출해야 한다.
이러한 메소드들이 있는 InputStream을 확장한 주요 클래스들은 다음과 같다.
AudioInputStream, ByteArrayInputStream, FileInputStream, FilterInputStream, InputStream, ObjectInputStream, PipedInputStream, SequenceInputStream, StringBufferInputStream이 중에서 보통 주로 많이 사용되는 스트림은 다음의 3개 정도다.
| 클래스 | 설명 |
| FileInputStream | 파일을 읽는 데 사용된다. 주로 우리가 쉽게 읽을 수 있는 텍스트 파일을 읽기 위한 용도라기보다 이미지와 같이 바이트 코드로 된 데이터를 읽을 때 사용한다. |
| FilterInputStream | 이 클래스는 다른 입력 스트림을 포괄하여, 단순히 InputStream 클래스가 Override 되어 있다. |
| ObjectInputStream | ObjectOutputStream으로 지정한 데이터를 읽는 데 사용된다. |
FileInputStream과 ObjectInputStream은 객체를 생성해서 데이터를 처리하면 된다. 하지만, FilterInputStream 클래스의 생성자는 protected로 선언되어 있기 때문에, 상속 받은 클래스에서만 객체를 생성할 수 있다. 따라서, 이 클래스를 확장한 클래스들을 주의깊게 볼 필요가 있다. FilterInputStream 클래스를 확장한 클래스는 다음과 같다.
BufferedInputStream, CheckedInputStream, CipherInputStream, DataInputStream, DeflaterInputStream, DigestInputStream, LineNumberInputStream, ProgressInputstream, PushbackInputStream아주 많은 종류의 Stream이 존재하는 것을 볼 수 있다.
이번에는 OutputStream에 대해서 살펴보자. 이 클래스의 선언문은 다음과 같다.
public abstract class OutputStream
extends Object
implements Closeable, FlushableInputStream과 마찬가지로 abstrat 클래스로 선언되어 있는 것을 볼 수 있다. 그리고, Closeable과 Flushable이라는 두 개의 인터페이스를 구현하였다. Closeable 인터페이스는 앞에서 한 번 살펴봐서 이해하겠는데, Flushable 인터페이스는 뭘까? 이 인터페이스도 Closeable 인터페이스처럼 하나의 메소드만 선언되어 있으며, 그 이름은 flush()이다. 일반적으로 어떤 메소드에 데이터를 쓸 때, 매번 쓰기 작업을 "요청할 때마다 저장"하면 효율이 안좋아진다.
예를 들어 누군가 마루에 있을 때 안방에 가서 연필을 가져오고, 휴지도 가져오고, 노트를 가져오라고 시켰을 때, 세 번 안방에 가서 가져오는 것보다는 한번에 가사 연필과 휴지, 노트를 가져오는 것이 훨씬 효과적일 것이다. 따라서, 대부분 저장을 할 때 버퍼(buffer)를 갖고 데이터를 차곡차곡 쌓아두었다가, 어느 정도 차게 되면 한번에 쓰는 것이 좋다. 그러한 버퍼를 사용할 때, flush() 메소드는 "현재 버퍼에 있는 내용을 기다리지 말고 무조건 저장해"라고 시키는 것이다.
OutputStream의 메소드에는 어떤 것들이 있는지 살펴보자.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| void | write(byte[] b) | 매개 변수로 받은 바이트 배열(b)를 저장한다. |
| void | write(byte[] b, int off, int len) | 매개 변수로 받은 바이트 배열(b)의 특정 위치(off)부터 지정한 길이(len) 만큼 저장한다. |
| abstract void | write(int b) | 매개 변수로 받은 바이트를 저장한다. 타입은 int이지ㅏㅁㄴ, 실제 저장되는 것은 바이트로 저장된다. |
| void | flush() | 버퍼에 쓰려고 대기하고 있는 데이터를 강제로 쓰도록 한다. |
| void | close() | 쓰기 위해 열은 스트림을 해제한다. |
InputStream과 마찬가지로 OutputStream 관련 클래스도 close() 메소드를 꼭 호출해서 열었던 리소스를 닫아 주어야만 한다. 그렇지 않으면, 애플리케이션에 문제가 발생하는 것은 순식간이다.
OutputStream 클래스를 확장한 자식 클래스들은 InputStream에서 간단히 살펴본 클래스들의 이름 뒤에 InputStream 대신 OutputStream을 붙여주면 된다.
6. Reader와 Writer
지금까지 살펴본 Stream은 byte를 다루기 위한 것이며, Reader와 Write는 char 기반의 문자열을 처리 하기 위한 클래스이다. 즉, 우리가 일반적인 텍스트 에디터로 쉽게 볼 수 있는 파일들을 처리하기 위한 클래스라고 보면 된다.
먼저 Reader 클래스의 선언부를 보자.
public abstract class Reader
extends Object
implements Readable, CloseableInputStream이나 OutputStream 클래스들처럼 이 Reader 클래스도 abstract으로 선언되어 있다. 이 클래스에 선언되어 있는 abstract 메소드는 close()와 read() 메소드다. 그리고, 메소드들의 목록을 보면 알 수 있겠지만, InputStream에 있는 메소드와 많이 중복되는 것을 볼 수 있다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| boolean | ready() | Reader에서 작업할 대상이 읽을 준비가 되어 있는지를 확인한다. |
| void | mark(int readAheadLimit) | Reader의 현재 위치를 표시(mark)해 둔다. 여기서 매개 변수로 넘긴 int 값은 표시해 둔 자리의 최대 유효 길이이다. 이 값이 넘어가면, 표시해 둔 자리는 더 이상 의미가 없어진다. |
| void | reset() | 현재 위치를 mark() 메소드가 호출되었던 위치로 되돌린다. |
| boolean | markSupported() | mark()나 reset() 메소드가 수행 가능한지를 확인한다. |
| int | read() | 하나의 char를 읽는다. |
| int | read(char[] cbuf) | 매개 변수로 넘어온 char 배열에 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| abstract int | read(char[] cbuf, int off, int len) | 매개 변수로 넘어온 char 배열에 특정 위치(off)부터 지정한 길이(len) 만큼의 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| int | read(CharBuffer target) | 매개 변수로 넘어온 CharBuffer 클래스의 객체에 데이터를 담는다. 리턴 값은 데이터를 담은 개수다. |
| long | skip(long n) | 매개 변수로 넘어온 개수 만큼의 char를 건너 뛴다. |
| void | close() | Reader에서 작업중인 대상을 해제한다. 이 메소드를 수행한 이후에는 다른 메소드를 사용하여 데이터를 처리할 수 없다. |
마찬가지로 close() 메소드는 모든 작업이 끝난 후에 호출해 주어야만 한다.
이러한 메소드들이 있는 Reader를 확장한 주요 클래스들은 다음과 같다.
BufferReader, CharArrayReader, FilterReader, InputStreamReader, PipedReader, StringReader여기에 있는 클래스들 중에서 BufferedReader와 InputStreamReader가 많이 사용된다.
이번에는 Writer 클래스를 살펴보자. 선언부는 다음과 같다.
public abstract class Writer
extends Object
implements Appendable, Closeable, Flushable마찬가지로 abstract 클래스다. 여기에 다른 클래스에는 없는 Appendable이라는 인터페이스가 구현되어 있다. Appendable 인터페이스는 Java 5부터 추가되었으며, 각종 문자열을 추가하기 위해서 선언되었다.
Writer 클래스도 OutputStream 클래스에 선언된 메소드와 대부분 동일하지만, append()라는 메소드가 존재한다는 점이 다르다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
| Writer | append(char c) | 매개 변수로 넘어온 char를 추가한다. |
| Writer | append(CharSequence csq) | 매개 변수로 넘어온 CharSequence를 추가 한다. |
| Writer | append(CharSequence csq, int start, int end) | 매개 변수로 넘어온 CharSequence를 추가하며, 쓰여지는 해당 문자열의 시작 위치(start)와 끝 위치(end)를 지정하면 된다. |
| void | write(char[] cbuf) | 매개 변수로 받은 char의 배열를 추가한다. |
| abstract void | write(char[] cbuf, int off, int len) | 매개 변수로 받은 char의 배열의 특정 위치(off)부터 지정한 길이(len) 만큼을 추가한다. |
| void | write(int c) | 매개 변수로 넘어온 int 값에 해당하는 char를 추가한다. |
| void | write(String str) | 매개 변수로 넘어온 문자열을 쓴다. |
| void | write(String str, int off, int len) | 매개 변수로 넘어온 문자열을 추가하며, 쓰여지는 해당 문자열의 시작 위치(start)와 끝 위치(end)를 지정하면 된다. |
| abstract void | flush() | 버퍼에 있는 데이터를 강제로 대상 리소스에 쓰도록 한다. |
| abstract void | close() | 쓰기 위해 열은 스트림을 해제한다. |
이 중에서 append() 메소드의 매개 변수로 넘겨지는 CharSequence는 인터페이스이다. 이 인터페이스를 구현한 대표적인 클래스에는 String, StringBuilder, StringBuffer가 있다. 그래서, 매개 변수로 CharSequence를 넘긴다는 것은 대부분의 문자열을 다 받아서 처리한다는 말이다.
Writer 클래스는 JDK 1.1부터 제공되었는데, 그 때 데이터를 저장하기 위한 메소드는 write() 밖에 없었다. 그래서, 언뜻 보기에도 어느 정도 append()와 write() 메소드가 비슷해 보일 것이다. 만약 만들어진 문자열이 String이라면 그냥 write() 메소드를 사용해도 별 상관은 없겠지만, StringBuilder나 StringBuffer로 문자열을 만들면 append() 메소드를 사용하는 것이 훨씬 편할 것이다.
7. 텍스트 파일을 써보자
자바에는 char 기반의 내용을 파일로 쓰기 위해서는 FileWriter라는 클래스를 사용한다. 먼저 이 클래스의 생성자를 살펴보자.
| 생성자 | 설명 |
| FileWriter(File file) | File 객체를 매개 변수로 받아 객체로 생성한다. |
| FileWriter(File file, boolean append) | File 객체를 매개 변수로 받아 객체를 생성한다. append 값을 통하여 해당 파일의 뒤에 붙일지(append=true), 해당 파일을 덮어 쓸지(append=false)를 정한다. |
| FileWriter(FileDescriptor fd) | FileDescriptor 객체를 매개 변수로 받아 객체를 생성한다. |
| FileWriter(String fileName) | 지정한 문자열의 경로와 파일 이름에 해당하는 객체를 생성한다. |
| FileWriter(String fileName, boolean append) | 지정한 문자열의 경로와 파일 이름에 해당하는 객체를 생성하낟. append 값에 따라서, 데이터를 추가할지, 덮어쓸지를 정한다. |
그런데, 이 Writer에 있는 write()나 append() 메소드를 사용하여 데이터를 쓰면, 메소드를 호출했을 때마다 파일에 쓰기 때문에 매우 비효율적이다. 이러한 단점을 보완하기 위해서 BufferedWriter라는 클래스가 있다.
| 생성자 | 설명 |
| BufferedWriter(Writer out) | Writer 객체를 매개 변수로 받아 객체를 생성한다. |
| BufferedWriter(Writer out, int size) | Writer 객체를 매개 변수로 받아 객체를 생성한다. 그리고, 두 번재 매개 변수에 있는 size를 사용하여, 버퍼의 크기를 정한다. |
이름 그대로, BufferedWriter는 버퍼라는 공간에 저장할 데이터를 보관해 두었다가, 버퍼가 차게되면 데이터를 저장하도록 도와준다. 따라서, 매우 효율적인 저장이 가능하다. 매개 변수로, Wirter를 받듯이 앞서 살펴본 FileWriter를 사용하면, 파일에 저장할 수 있다.
예제 코드
package e.io;
import static java.io.File.separator;
import java.io.BufferedWriter;
import java.io.FileDescriptor;
import java.io.FileWriter;
import java.io.IOException;
public class ManageTextFile {
public static void main(String[] args){
ManageTextFile manager = new ManageTextFile();
int numberCount = 10;
String fullPath = separator+"godofjava"+separator+"text"+separator+"numbers.txt";
manager.writeFile(fullPath, numberCount);
}
public void writeFile(String fileName, int numberCount){
FileWriter fileWriter = null;
BufferedWriter bufferedWriter = null;
try{
fileWriter = new FileWriter(fileName);
bufferedWriter = new BufferedWriter(fileWriter);
for(int loop=0; loop<=numberCount; loop++){
bufferedWriter.write(Integer.toString(loop));
bufferedWriter.newLine();
}
System.out.println("Write Success !!!");
}catch(IOException ioe){
ioe.printStackTrace();
}catch(Exception e){
e.printStackTrace();
}finally {
if(bufferedWriter!=null){
try{
bufferedWriter.close();
}catch(IOException ioe){
ioe.printStackTrace();
}
}
if(fileWriter!=null){
try{
fileWriter.close();
}catch(IOException ioe){
ioe.printStackTrace();
}
}
}
}
}여기서 꼭 기억해야 되는 규칙이 있다. 만약 FileWriter나 BufferedWriter 변수를 try문 안에서 선언했다면, finally에서 close() 메소드를 호출할 수가 없다.
변수들을 try 중괄호 안에서 선언할 경우, catch나 finally, 그리고 try~catch 문장 밖에서 참조하려고 하면, "쟤가 누구야?"라고 하면서 컴파일 에러가 발생한다. 따라서, finally에서 close()를 하려면, 반드시 try 문장 전에 변수를 선언해야 한다.
그런데, 왜 finally에서 close()를 할까? 만약 try 블록의 끝 부분에서 close() 메소드를 구현했다면, 중간에 예외가 발생했을 때 close() 메소드가 호출되지 않는다. 이를 피하려면 catch 블록에서 일일이 close()를 모두 구현해 주어야만 한다. 이러한 단점을 해결하기 위해서 finally 블록에서 close()를 처리해 주는 것이다.
또 한 가지 규칙이 있다. 이 예제에서 FileWriter, BufferedWriter 순으로 객체를 생성했다. 여기서 생성한 객체들을 닫아 줄 때에는 BufferedWriter, FileWriter 순으로 닫아야만 한다. 즉, 가장 마지막에 연(open 한) 객체부터 닫아주어야 정상적인 처리가 가능하다.
실행 결과
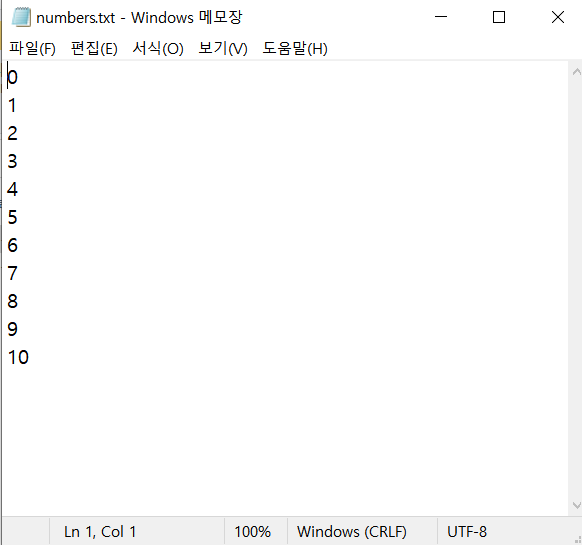
만약, 다음과 같이 FileWriter의 생성자에 true를 같이 넘겨주면 어떻게 결과가 나올까?
fileWriter = new FileWriter(filename, true);여기서 true라는 매개 변수를 넘겨주면, 두 번 이상 이 메소드를 실행시키면, 기존 파일의 긑에 새로운 내용이 추가된다. 따라서, 0에서 10까지 출력된 뒷부분에 0에서 10까지의 숫자가 다시 추가되어 저장된다. true 값을 false로 변경한 후 실행하면, 지금까지 저장된 값들은 모두 없어지고, 0에서 10까지 한 번만 출력하여 저장되어 있을 것이다. 다시 말해서, true는 파일 붙여쓰기, false는 파일에 덮어 쓰기가 된다.
8. 텍스트 파일을 읽어보자
파일에 저장한 후 일일이 열어보는 것은 매우 귀찮은 작업니다. 해당 파일을 바로 다시 열어볼 수는 없을까? 직접 파일을 열어서 확인해 보려면 FileReader와 BufferedReader를 사용하면 된다. 앞에서 사용한 메소드에서 Writer를 Reader로 변경해주면 대부분의 코드는 쉽게 작성된다.
public void readFile(String fileName){
FileReader fileReader = null;
BufferedReader bufferedReader = null;
try{
fileReader = new FileReader(fileName);
bufferedReader = new BufferedReader(fileReader);
String data;
while((data = bufferedReader.readLine()) != null){
System.out.println(data);
}
System.out.println("Read Success !!!");
}catch(IOException ioe){
ioe.printStackTrace();
}catch(Exception e){
e.printStackTrace();
}finally {
if(bufferedReader!=null){
try{
bufferedReader.close();
}catch (IOException ioe){
ioe.printStackTrace();
}
}
if(fileReader!=null){
try{
fileReader.close();
}catch(IOException ioe){
ioe.printStackTrace();
}
}
}
}실행 결과

그런데 이렇게 코드를 작성하면, 코드의 길이도 길어지고, 가독성도 많이 떨어진다. 따라서, java.util 패키지에 있는 Scanner 클래스를 사용하면 매우 쉽게 파일을 읽을 수 있다.
public void readFileWithScanner(String fileName){
File file = new File(fileName);
Scanner scanner = null;
try{
scanner = new Scanner(file);
while(scanner.hasNextLine()){
System.out.println(scanner.nextLine());
}
System.out.println("Read Success !!!");
}catch(FileNotFoundException fnfe){
fnfe.printStackTrace();
}catch(Exception e){
e.printStackTrace();
}finally {
if(scanner != null){
scanner.close();
}
}
}Scanner 클래스는 텍스트 기반의 기본 자료형이나 문자열 데이터를 처리하기 위한 클래스다. 게다가 정규 표현식(Regular Expression)을 사용하여 데이터를 잘라 처리할 수도 있다. Scanner 클래스의 생성자는 종류가 다양한데, 여기서는 File의 객체를 매개 변수로 받아 파일의 내용을 읽는 데 사용했다. Scanner 클래스의 hasNextLine()이라는 메소드는 다음 줄이 있는지 확인하기 위해서 사용되며, nextLine() 메소드는 다음 줄의 내용을 문자열로 한 줄씩 리턴해준다. 따라서, 이 예제에서 while문의 조건식에는 hasNextLine() 메소드로 다음 줄이 있는지를 확인한 후, nextLine() 메소드로 한 줄씩 읽어들이도록 한 것을 볼 수 있다.
여기서 Scanner 클래스는 java.util 패키지의 클래스이므로, 반드시 import를 해 주어야 제대로 수행이 된다. 이 메소드를 실행해보면, 앞서 살펴본 예제와 동일한 결과가 나오는 것을 볼 수 있을 것이다.
추가로 Java 7에서 제공하는 Files라는 클래스를 사용하면 다음과 같이 한 줄로 파일을 읽을 수도 있다.
String data = new String(Files.readAllBytes(Paths.get(fileName)));참고
- 자바의 신
