1. 자바의 역사
자바의 역사는 1981년으로 거슬러 올라간다. 1991년에 "Green"이라는 프로젝트가 생기면서 자바의 모태가 탄생하기 시작했다. 제임스 고슬링(James Gosling, Mike Sheridan, Patrick Naughton) 이렇게 3명의 젊은이가 TV와 시청자가 서로 상호 작용 할 수 있는(interactive한) 것을 만들기 위해서 시작되었다. 지금은 IPTV와 같은 것이 일반적으로 대중화되어 있지만, 그때만해도 너무 앞서가는 것이었다. 1992년 고슬링의 사무실 앞에 있는 참나무를 보고 이름을 지은 "Oak"라는 언어다.
그 이 후에 1995년 "Oak"라는 언어의 이름이 커피의 한 종류를 뜻하는 "자바 커피"의 이름을 본따 "Java"라고 바뀌면서 자바 기술이 시작하게 되었다. 1995년에 자바 언어를 만들면서 "Write Once, Run Anywhere"(WORA)라는 모토가 만들어졌으며, 여러 플랫폼에서 수행할 수 있는 개발 언어를 목표로 개발되었다.
2. JDK, JRE
- JDK : Java Development Kit
- JRE : Java Runtime Environment
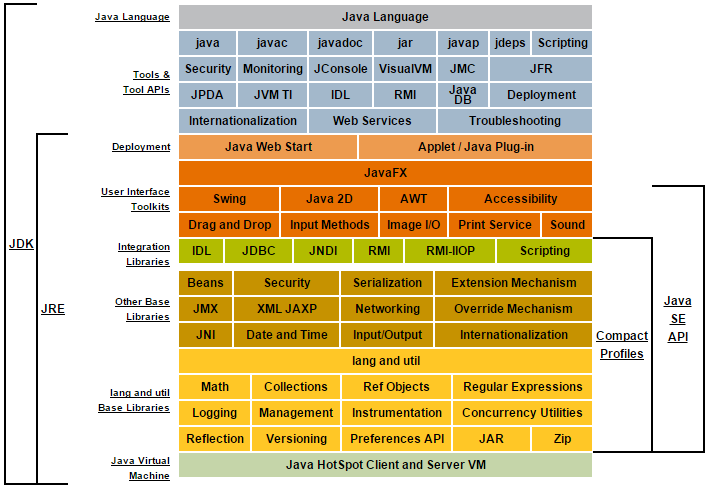
가장 좌측을 보면 JDK와 JRE로 나뉘어져 있는 것을 볼 수 있다. 즉, JRE는 자바를 실행하기 위한 환경의 집합이라고 보면된다. 그리고, JRE에 있는 여러 가지 레고 블록처럼 칸칸이 쌓여 있는 것들은 자바에서 제공하는 라이브러리들이라고 보면 된다.
3. 자바 언어의 특징
자바 언어는 다섯 가지의 특징이 있으며, 다음과 같다.
- It should be "simple, object-oriented and familiar"
- It should be "robust and secure"
- It should be "architecture-neutral and poratble"
- It should execute with "high performance"
- It should be "interpreted, threaded, and dynamic"
이를 번역해보면 다음과 같다.
1. 자바는 "단순하고, 객체지향이며, 친숙"해야 한다.
2. 자바는 "견고하며, 보안상 안전"하다.
3. 자바는 "아키텍처에 중립적이어야 하며 포터블"해야 한다.
4. 자바는 "높은 성능"을 제공해야 한다.
5. 자바는 "인터프리터 언어이며, 쓰레드를 제공하고, 동적인 언어"이다.
1. 자바는 "단순하고, 객체지향이며, 친숙"해야 한다.
자바는 처음 만들 때부터 객체지향으로 디자인되어 있다. 그리고, 다형성, 캡슐화 등 객체 지향 언어의 특징들을 지원할 수 있는 구조로 되어 있다.
그리고, 자바로 개발할 때에는 처음부터 모든 것을 만들 필요가 없다. 개발하면서 필요한 여러 기능들은 이미 API를 통해서 제공하고 있다. 파일을 읽고 쓰거나 네트워크로 데이터를 주고 받는 I/O, 그래프 UI 등을 개발하기 위한 여러 라이브러리를 통해서 보다 쉽게 개발할 수 있는 환경을 제공하고 있다. 파일을 읽고 쓰거나 네트워크로 데이터를 주고 받는 I/O, 그래픽 UI 등을 개발하기 위한 여러 라이브러리를 통해서 보다 쉽게 개발할 수 있는 환경을 제공한다.
2. 자바는 "견고하며, 보안상 안전"하다.
자바는 컴파일할 때와 실행할 때 문법적 오류에 대한 체크를 한다. 메모리 관리 모델이 매우 단순하고, C를 배우고 사용하는 개발자들의 머리를 아프게 하는 포인터의 개념이 없다. 이 특징들은 자바를 매우 믿을 수 있고(reliable) 견고한 소프트웨어가 될 수 있도록 도와준다.
자바는 기본적으로 분산 환경에서 사용하기 위하여 디자인되었다. 분산 환경에서 보안은 중요한 부분 중 하나다. 자바 기술은 외부에서 침입이 불가능한 애플리케이션을 만들 수 있도록 해준다.
3. 자바는 "아키텍처에 중립적이어야하며 포터블"해야 한다.
자바로 작성한 프로그램은 매우 다양한 하드웨어 아키텍처에서 수행할 수 있도록 되어 있다. 따라서 자바는 아키텍처에 중립적인 바이트 코드를 제공한다. 따라서, 자바의 버전만 동일하다면, 동일한 프로그램은 어떤 플랫폼에서도 실행할 수 있다. 이러한 호환성과 포터블한 환경을 제공하는 것은 JVM 덕분이다.
4. 자바는 "높은 성능"을 제공해야 한다.
자바는 실행 환경에서 최대한의 성능을 낼 수 있도록 되어 있다. 게다가 자동화된 가비지 컬렉터는 낮은 우선 순위의 쓰레드로 동작하기 때문에 보다 높은 성능을 낼 수 있다. 그리고, 보다 빠른 성능을 위해서 네이티브 언어로 작성한 부분을 자바에서 사용할 수 있도록 되어 있다.
5. 자바는 "인터프리터 언어이며, 쓰레드를 제공하고, 동적인 언어"이다.
자바 인터프리터는 자바 바이트 코드를 어떤 장비에서도 수행할 수 있게 해준다. 따라서, 시존에 사용하던 무거운 컴파일과 링크와 테스트 사이클을 거쳐야 하는 개발 환경보다 빠른 환경을 구축할 수 있다.(하지만 지금의 자바 개발 환경은 각종 라이브러리들로 인해 그렇게 단순하지만은 않다.)
자바는 멀티 쓰레드 환경을 제공하기 때문에, 동시에 여러 작업을 수행할 수 있다. 따라서 사용자에게 매우 빠른 사용 환경을 제공한다.
자바 컴파일러는 컴파일시 매우 엄격한 정적인 점검을 수행한다. 그리고, 실행시에 동적으로 필요한 프로그램들을 링크시킨다. 게다가 새로운 코드는 다양한 소스에서 요청에 의해서 연결될 수 있다.
4. JIT 컴파일러
JIT라는 것은 Just-In-Time의 약자다. JIT를 사용하는 언어에는 자바와, NET 등이 있다. 즉, 자바에서만 사용하는 개념이 아니다. JIT를 좀 더 쉬운 말로 하자면 "동적 변환(dynamic transition)"이라고 보면 된다. 이러한 JIT라는 것을 만든 이유는 프로그램 실행을 보다 빠르게 하기 위해서이다. 명칭이 컴파일러지만, 실행시에 적용되는 기술이다.
역사적으로 보면, 컴퓨터 프로그램을 실행하는 방식은 두 가지로 나눌 수 있다. 하나는 인터프리터(interpret) 방식이며, 다른 하나는 정적(static) 컴파일 방식이다. 인터프리터 방식은 프로그램을 실행할 때마다 컴퓨터가 알아 들을 수 있는 언어로 변환하는 작업을 수행한다. 따라서, 간편하기는 하지만 성능이 매우 느릴 수 밖에 없다. 정적 컴파일 방식은 실행하기 전에 컴퓨터가 알아 들을 수 있는 언어로 변환하는 작업을 미리 실행한다. 따라서, 변환 작업은 딱 한번만 수행된다. JIT는 이 두 가지 방식을 혼합한 것이라고 보면 된다. 변환 작업은 인터프리터에 의해서 지속적으로 수행되지만, 필요한 코드의 정보는 캐시에 담아두었다가(메모리에 올려두었다가) 재사용하게 된다.
그런데, 지금까지 설명한 내용만 보면 매우 의아할 수 있다. "분명히 나는 javac 명령어를 사용해서 컴파일을 했는데, 그럼 그냥 정적 컴파일 방식 아닌가?"라고 생각할 수 있다. javac라는 명령어를 사용하여 컴파일을 하는 단계에서 만들어진 class라는 파일은 바이트 코드(bytecode)일 뿐이다. 자바의 모토 중 하나가 "Compile once, Run anywhere"다. 한 번 컴파일한 코드로 리눅스, 맥, 윈도우 등에서 모두 사용할 수 있다. 다시 말해서, javac라는 명령어를 수행한다는 것은 텍스트로 만든 java 파일을 어떤 OS에서도 수행될 수 있도록 바이트 코드라는 파일로 만든 것 뿐이다. 컴퓨터가 알아먹을 수 있도록 하려면 다시 변환 작업이 필요하다. 이 변환 작업을 JIT 컴파일러에서 한다고 보면 된다.
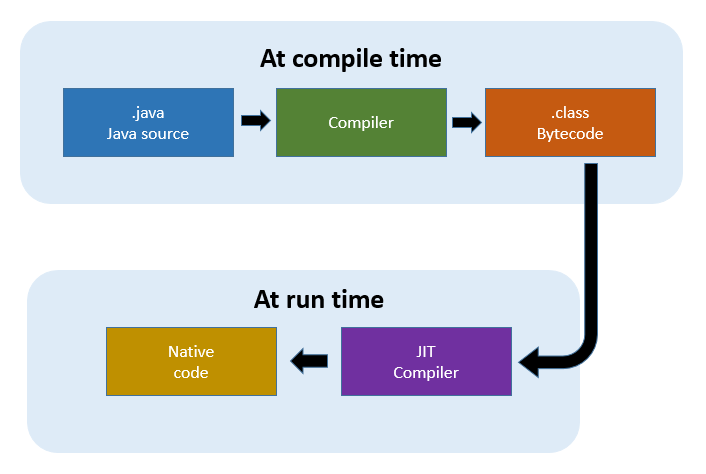
JVM -> 기계 코드로 변환되는 부분을 JIT에서 수행하는 것이다. JIT를 사용하면 반복적으로 수행되는 코드는 매우 빠른 성능을 보인다는 장점이 있지만, 반대로 처음에 시작할 때에는 변환 단계를 겨쳐야 하므로 성능이 느리다는 단점이 있다.
5. HotSpot
이 그림의 가장 밑에는 HotSpot이라는 단어가 있다. 자바에서는 이와 같이 "HotSpot 클라이언트 컴파일러"와 "HotSpot 서버 컴파일러"의 두 가지 컴파일러를 제공한다. 예전에는 PC에서만 수행되는 프로그램을 사용할 때는 많은 CPU 코어를 사용할 수 없었다. 요즘에는 넷북이나 스마트폰도 듀얼 코어가 대새이고, 데스크탑은 쿼드 코어도 사용하지만 몇 년 전만 하더라도 대부분 PC의 CPU 코어의 개수는 하나였다. CPU 코어가 하나뿐인 그런 사용자를 위해서 만들어진 것이 HotSpot 클라이언트 컴파일러다. 이 컴파일러의 주요 특징은 애플리케이션 시작 시간을 빠르게 하고, 적은 메모리를 점유하도록 하는 것이다. 그리고, 코어가 많은 장비에서 애플리케이션을 돌리기 위해서 만들어진 것이 HotSpot 서버 컴파일러 라고 생각하면 되며, 이 컴파일러는 애플리케이션 수행 속도에 초점이 맞추어져 있다.
그러면, 클라이언트 컴파일러와 서버 컴파일러는 어떻게 선택할 수 있을까? 기본적으로는 자바가 시작할 때 알아서 클라이언트 장비인지 서버 장비인지를 확인하다. 그 기준은 다음과 같다.
- 2개 이상의 물리적 프로세서
- 2GB 이상의 물리적 메모리
이 조건을 만족하면 Oracle에서 만든 JVM은 서버 컴파일러를 선택한다.
만약 명시적으로 어떤 종류의 JVM인지를 지정하고 싶다면 클라이언트 JVM은 -client, 서버 JVM은 -server라고 지정해주면 된다. 어디에 지정해주면 되냐면 java 명령에 포함하면 된다. 다음과 같이 java 명령과 클래스 이름 사이에 옵션을 추가하면 된다.
$ java -server Calculator이 외에도 여러 가지 옵션을 지정할 수 있는데, 그 옵션들도 마찬가지로 java와 클래스 이름 사이에 넣어주면 된다. 각 옵션들은 공백으로 구분해주면 된다. 예를 들어 JVM의 시작 메모리 크기를 지정하는 -Xms라는 옵션으로 512 메가 바이트의 시작 크기를 지정하려면 다음과 같이 하면 된다.
$ java -server -Xms5512m Calculator참고로 OS에 따라서 클라이언트 컴파일러를 사용할지, 서버 컴파일러를 사용할지가 정해져 있기도 하는데, 윈도우는 기본적으로 지정해주지 않으면 클라이언트 컴파일러가 사용된다.
6. JVM과 GC
일반적으로 자바를 실행할 때 많이 사용되는 용어들은 다음과 같은 것들이 있다.
- JVM : Java Virtual Machine(자바 가상 머신)
- GC : Garbage Collector(가비지 컬렉터)
먼저 JVM에 대해서 간단히 알아보자. JVM은 작성한 자바 프로그램이 수행되는 프로세스를 의미한다. 다시 말해서, java라는 명령어를 통해서 애플리케이션이 수행되면, JVM 위에서 애플리케이션이 동작한다. 이 JVM에서 작성한 프로그램을 찾고 수행하는 일련의 작업이 진행된다.
자바의 메모리 관리는 개발자가 하지 않아도 된다. 메모리 관리를 JVM이 알아서 하기 때문이다. 이때 JVM 내에서 메모리 관리를 해주는 것을 바로 "가비지 컬렉터"라고 부른다. Garbage는 우리나라말로 "쓰레기"라는 의미이며, 사용하고 남아 있는 전혀 필요 없는 객체들이 여기에 속한다. 아무리 가비지 컬렉터가 쓰레기를 알아서 청소한다고 하더라도, 메모리를 효율적으로 사용하도록 개발하는 것은 매우 중요하다. 예를 들어, 쓰레기를 청소하는 작업이 수행되면 "가비지 컬렉션이 수행되었다"라고 표현한다. 아니면 짧게 "GC가 발생했다"라고 이야기 한다.
어떤 객체를 생성하더라도 그 객체는 언젠가는 쓰레기가 되어 메모리에서 지워져야만 한다. 예를 들어 "abc"라는 문자열이 있는데, 더 이상 사용할 일이 없다면 메모리에서 삭제 되어야만 한다. 만약 지워지지 않으면, 자바 프로그램은 엄청난 메모리가 필요할 것이다. 그래서 C를 사용하여 개발할 때에는 메모리를 해제하는 작업을 꼭 해줘야만 한다. 하지만, 자바는 그런 작업을 해 줄 필요가 없다. 가비지 컬렉터라는 것이 알아서 쓰레기들을 치워주기 때문이다. Java7부터 공식적으로 사용할 수 있는 G1(Garbage First)라는 가비지 컬렉터를 제외한 나머지 JVM은 다음과 같이 영역을 나누어 힙(Heap)이라는 공간에 객체들을 관리한다.
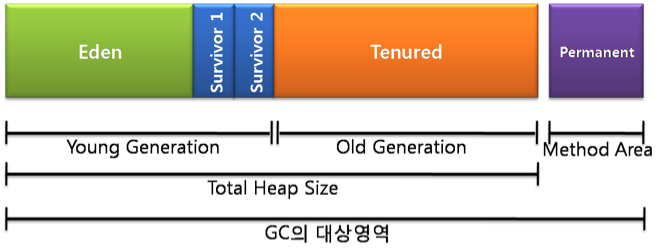
가장 왼쪽에 있는 Young 영역에는 말 그대로 젊은 객체들이 존재하며, Old 영역에는 늙은 객체들이 자리잡게 된다. 그리고, Perm이라는 영역에는 클래스나 메소드에 대한 정보가 쌓인다.
Young 영역에는 Eden과 두 개의 Survivor 영역으로 나뉘는데, 이 중에서 객체를 생성하자마자 저장되는 장소는 Eden이다. 일반적으로 자바에서 메모리가 살아가는 과정은 다음과 같다.
- Eden 영역에서 객체가 생성된다.
- Eden 영역이 꽉 차면 살아있는 객체만 Survivor 영역으로 복사되고, 다시 Eden 영역을 채우게 된다.
- Survivor 영역이 꽉 차게 되면 다른 Survivor 영역으로 객체가 복사된다. 이 때, Eden 영역에 있는 객체들 중 살아있는 객체들도 다른 Survivor 영역으로 간다. 즉, Survivor 영역의 둘 중 하나는 반드시 비어 있어야만 한다.
지금까지 과정을 마이너(minor) GC 혹은 영(Young) GC라고 부른다. 여기서 GC는 가비지 컬렉터가 아니라 가비지 컬렉션을 말한다.
그러다가, 오래 살아있는 객체들은 Old 영역으로 이동한다. 지속적으로 이동하다가 Old 영역이 꽉 차면 GC가 발생하는데 이것을 메이저(major) GC, 풀(Full) GC라고 부른다.
그렇다면 영 GC와 풀 GC 중 어떤 것이 더 빠를까?
영 GC가 풀 GC보다 빠르다. 왜냐하면 일반적으로 더 작은 공간이 할당되고, 객체들을 처리하는 방식도 다르기 때문이다. 그렇다고, 전체의 힙 영역을 영 영역으로 만들면 장애로 이어질 확률이 매우 높아진다.
오라클 JDK에서 제공하는 GC의 방식은 크게 4가지가 있으며, Java7부터 추가된 G1(Garbage First)를 포함하여 총 5가지의 가비지 컬렉터가 존재한다. 정리하자면 다음과 같다.
- Serial GC
- Parallel Young Generation Collector
- Parallel Old Generation Collector
- Concurrent Mark & Sweep Collector(줄여서 CMS)
- G1(Garbage First)
이중에서 WAS로 사용하는 JVM에서 사용하면 안되는 것은 Serial GC다. 이 GC 방식은 -client 옵션을 지정했을 때 사용된다. 즉, 클라이언트용 장비에 최적화된 GC이기 때문에 만약 WAS에서 이 방식을 사용하면 GC 속도가 매우 느려 웹 애플리케이션이 엄청 느려진다.
참고
- 자바의 신
