📗 샤딩(Sharding)이란?
-
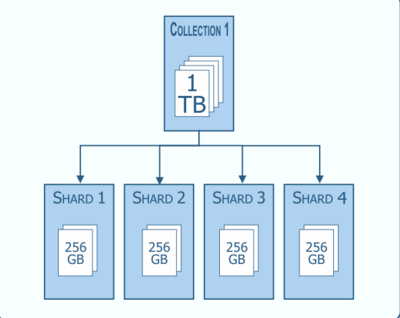
샤딩(Sharding)은 데이터베이스 관리에서 사용되는 기술 중 하나로, 대용량의 데이터를 여러 개의 작은 파티션으로 나누어 분산 저장하는 방법입니다.
-
좀 더 쉽게 작성하자면 샤딩이란 데이터베이스 테이블을 조각내어 각각 새로운 노드에 저장하는 데이터 관리 방법을 의미합니다. 하나의 데이터베이스에서 다루기에는 데이터의 양이 너무 많을 경우 여러 노드에 데이터를 나누어 처리 속도를 향상시킬 수 있습니다.
📗 샤딩을 접하는 경우
-
열심히 기획 제작한 앱이 인기가 높아져 사용자가 증가할 경우 기분이 좋긴 하지만 한 가지 대비를 해야합니다. 이용자가 많아져 데이터의 사용량이 급격히 증가하면 병목현상이 발생할 수 있기 때문입니다.
-
4차선에 걸쳐 달리던 차들이 도로 구간 공사 때문에 모두 한 차선에서만 달려햐 하는 상황이 생기는 경우 도로가 마비되고 빠른 속도로 달리기 어렵습니다. 앱도 서버 용량 문제로 서비스가 느려진다면 사용자 경험이 매우 안좋아질 수 밖에 없습니다. 이럴 경우 데이터 처리의 대안으로 샤딩이 사용될 수 있습니다.
-
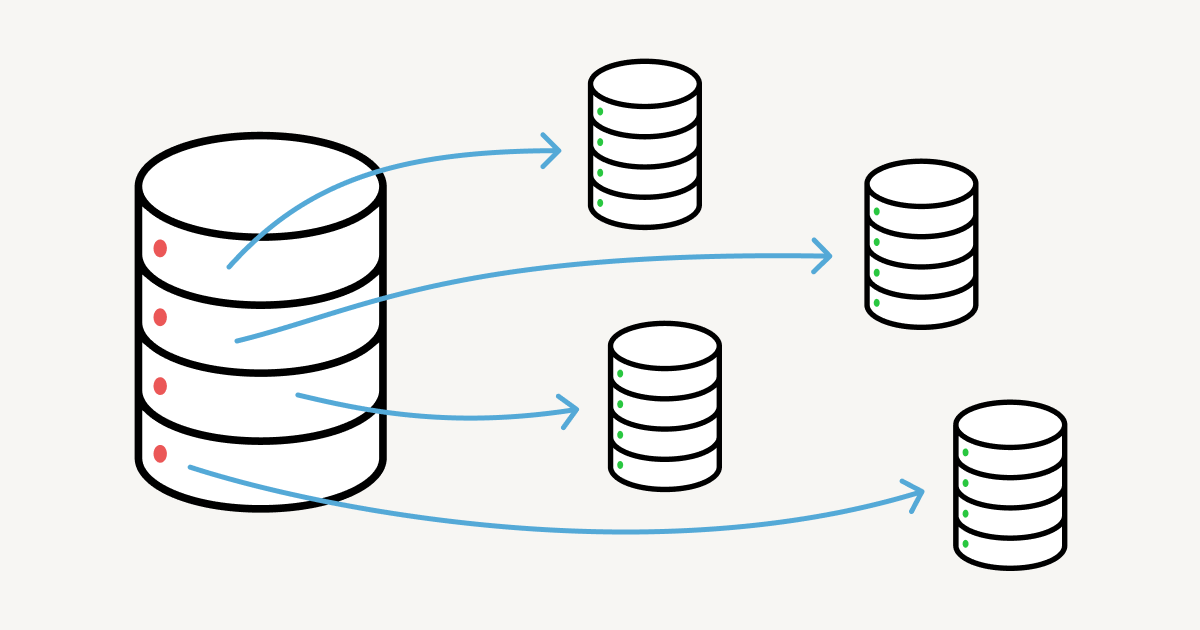
샤딩은 데이터를 여러 노드에 분산해 두기 때문에 한 장소로 트래픽이 몰리는 것을 방지해주고 더 많은 양의 정보를 수용 가능합니다.
📗 샤딩 알아보기
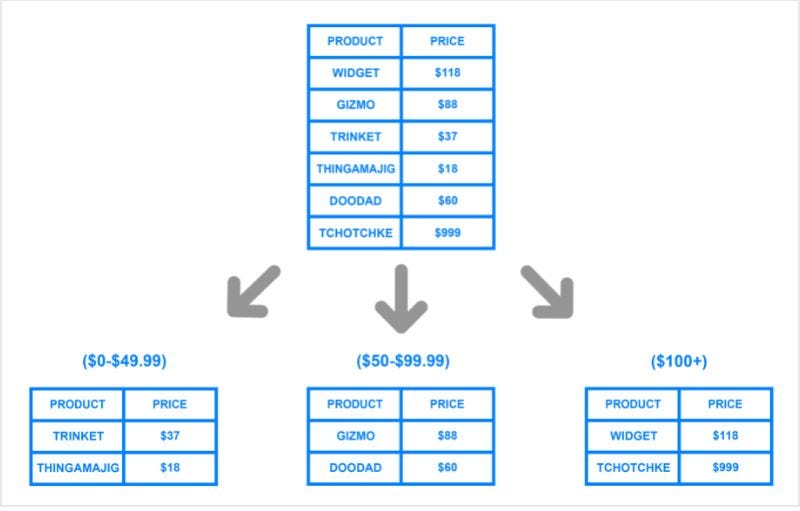
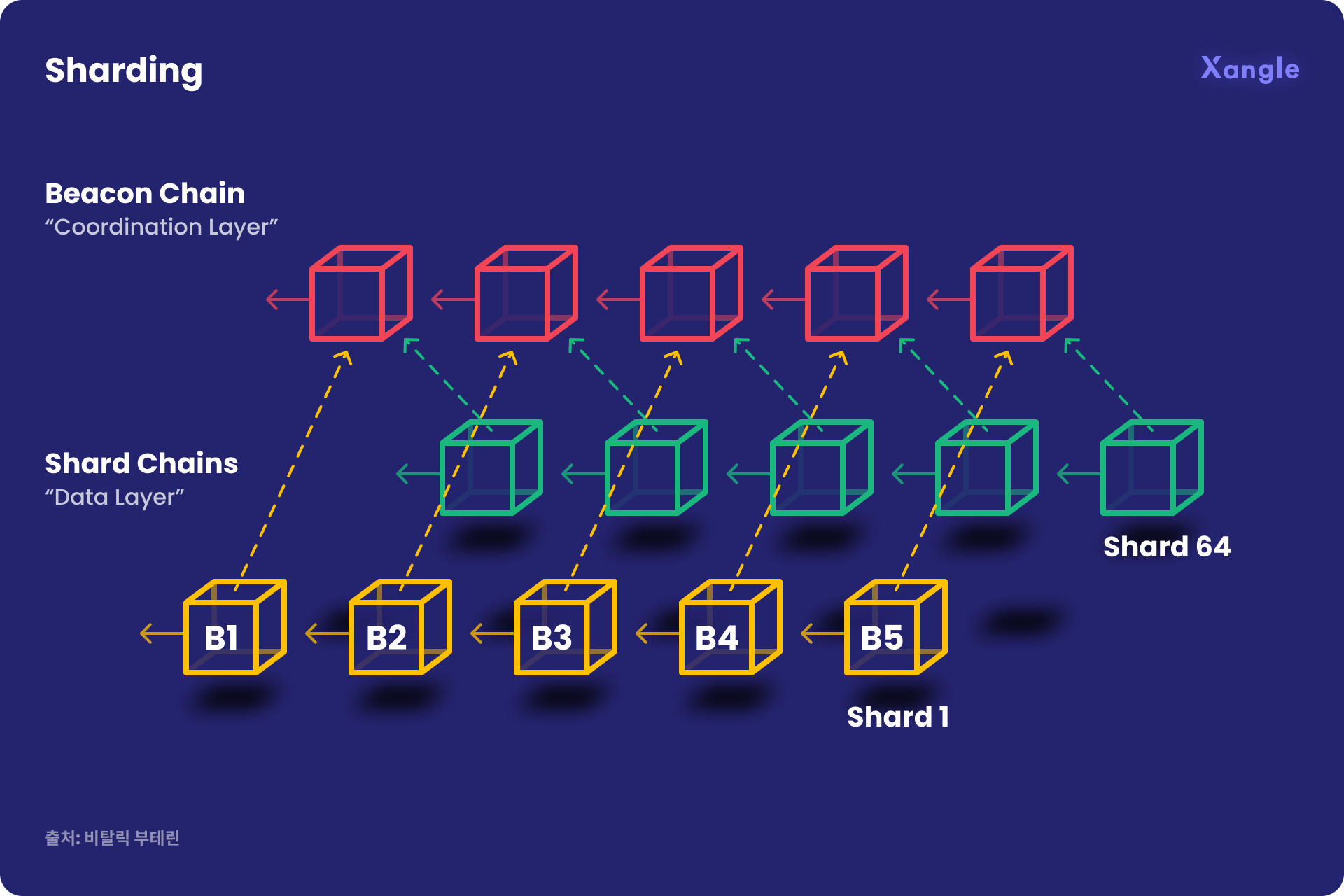
- 샤딩은 수평적 분할 이라고도 부릅니다. 데이터를 수평적으로 분할한다는 것은 데이터 테이블의 행을 기준으로 나누는 것이죠. 따라서 샤트마다 스키마는 동일하지만 담고 있는 정보는 모두 다릅니다. 그리고 이에 맞는 각각의 샤딩이 존재합니다.
🎁 수평 샤딩(Horizontal Sharding)
- 수평 샤딩은 데이터를 특정 기준에 따라 여러 파티션으로 분할하는 것을 의미합니다. 예를 들어, 사용자 ID, 지역, 시간 등의 기준으로 데이터를 나눌 수 있습니다. 각 파티션은 독립적으로 관리되며, 별도의 서버나 데이터베이스 인스턴스에 저장됩니다.
🎁 수직 샤딩(Vertical Sharding):
- 수직 샤딩은 데이터 스키마의 열을 기준으로 데이터를 분할하는 것을 의미합니다. 이는 열의 데이터를 서로 다른 테이블이나 데이터베이스에 나누어 저장하는 것을 의미할 수 있습니다. 예를 들어, 자주 사용되는 열과 드물게 사용되는 열을 분리하여 별도의 테이블에 저장할 수 있습니다.
🎁 해시 샤딩(Hash Sharding)
- 해시 샤딩은 데이터를 해싱 알고리즘을 사용하여 여러 파티션으로 분할하는 것을 의미합니다. 이러한 방식에서는 해시 함수를 사용하여 데이터의 특정 키 또는 속성을 해싱한 후 그 해시 값을 기준으로 파티션을 결정합니다
🎁 범위 샤딩(Range Sharding)
범위 샤딩은 데이터의 특정 범위를 기준으로 여러 파티션으로 나누는 것을 의미합니다. 예를 들어, 시간 범위 또는 알파벳 순서 등의 기준을 사용하여 데이터를 분할할 수 있습니다.
📗 샤딩의 장단점
🎁 장점
-
샤딩을 하면 데이터 저장공간을 확장할 수 있습니다. 샤드의 수가 증가하면서 전체적인 저장 공간이 늘어가는 효과가 나타나는 것이죠. 뿐만 아니라 데이터들이 일정한 기준으로 분산되어 있으므로 데이터의 양에 비해 쿼리 속도가 빠르다는 장점도 존재합니다.
-
분산되지 않은 데이터 세트에서 원하는 정보를 찾으려면 모든 정보를 다 거쳐가면 정보를 찾아야 하므로 시간상 비효율적입니다. 하지만 샤딩으로 정보를 일정한 기준으로 나누어 저장해 두면 원하는 정보가 담겨있는 샤드에서만 정보를 찾으면 되기 때문에 훨씬 효율적입니다.
-
수천 명이 넘는 학생 정보를 모두 훑어 가며 원하는 정보를 찾으려면 시간이 오래 걸리지만, 전공별로 정보를 분리해 두면 원하는 정보를 더욱 빠르게 찾을 수 있는 예시와 같습니다.
🎁 단점
-
샤딩은 데이터의 양이 불균형하게 증감하면 문제가 발생합니다. 샤드별로 균일하게 변화가 발생하면 문제가 덜하지만, 간혹 한 샤드에 데이터가 몰리는 경우가 있습니다.
-
예를 들어, 학교에서 전공별로 샤드를 나누어 학생 정보를 관리하고 있다고 가정해봅시다. 그런데 건축과가 해를 거듭할수록 인기가 많아져 학교에서 과 정원을 3배나 늘리게 되었습니다. 매년 정원에 꽉 차게 신입생이 입학한다면 건축과 전공자 수는 다른 전공에 비해 매해 빠르게 증가할 것이고, 건축과 전공 샤드에 데이터가 상대적으로 몰릴 것입니다. 그러면 샤드 간 불균형이 생기고 데이터가 많이 축적된 건축과 전공 샤드는 정보 열람에 시간이 더 소요되며 샤딩의 이점은 없어질 것입니다.
