Redshift란?
AWS Redshift는 Peta-byte 규모의 데이터까지 처리할 수 있는 완전 관리형 Data Warehouse 서비스이다. Redshift는 AWS에서 제공하는 Cloud DB 이긴 한데 MPP DB 서비스라고 보면 된다.
MPP (Mass Parallel Processing)란 대규모 병렬 컴퓨터로서, 많은 독립적인 Node들이 Network로 서로 연결이 된 하나의 매우 커다란 분산 메모리 컴퓨터 시스템을 말한다. MPP DB는 하나의 Query를 여러 개의 Process로 병렬 처리한다. (MPP에 대한 건 나중에 자세히..)
Redshift는 매우 빠른 처리 속도와 높은 확장성을 제공한다. Storage 용량이나 처리속도를 증가시키고 싶으면 간단히 Node 수를 증가시키거나(Scale-Out) 사양을 높이면 된다(Scale-Up).
그러니까 Redshift는 저장 용량이나 처리 속도를 마음대로 조절할 수 있고, 소규모 데이터부터 대규모 데이터까지 처리하며, 병렬로 실행되는 DB라고 보면 된다.
예를 들어 SELECT 문을 날렸는데 Query 실행시간이 너무 오래걸린다? 그러면 사양을 높이거나 Node 수를 늘리면 된다. (물론 사양을 높이거나 Node 수를 늘리는 것만이 답은 아니다)
Redshift Architecture
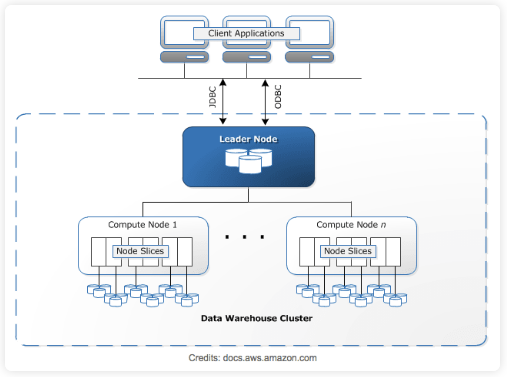
Redshift의 각 Component들에 대해서 알아보자.
Cluster
Cluster는 1개 이상의 Compute Node로 구성된다. 만약 2개 이상의 Compute Node가 Cluster에 Provisioning되면 추가 Leader Node가 Compute Node를 Coordinate하고, 외부 통신을 처리한다.
모든 Client applications은 오직 Leader Node와 상호작용한다.
Leader Node
- Client application과의 통신과 모든 Compute Node와의 통신을 관리한다.
- DB Operation을 수행하기 위해 실행 계획을 분석하고 개발한다. 실행 계획에 따라 Leader Node는 Code를 Compile하고, Compile된 Code를 Compute Node에 배포하고, 데이터의 일부를 각 Compute Node에 할당한다.
- Leader Node는 Query가 Compute Node에 저장된 Table을 참조할 때만 Compute Node에 SQL 문을 배포한다. 다른 모든 Query는 Leader Node에서만 실행된다.
Redshift는 Leader Node에서만 특정 SQL 기능을 구현하도록 설계되었다. 이런 Leader Node에서만 실행되는 기능을 사용하는 Query는 Compute Node에 있는 Table을 참조하는 경우 Error를 반환한다.
예를 들어current_schema()함수의 경우 Leader Node 전용 함수이다.


System catalog table을 참조하는 Query도 Leader Node에서만 실행된다.

Compute Node에 있는 System table을 참조하면 Error를 반환한다.

Compute Node
- Leader Node는 실행 계획의 개별 요소에 대한 Code를 Compile하고, 각 Compute Node에 Code를 할당한다. Compute Node는 Compile된 Code를 실행하고 최종 집계를 위해 중간 결과를 Leader Node로 보낸다.
- 각 Compute Node는 Node 유형에 의해 결정되는 자체 전용 CPU, Memory 및 연결된 Disk Storage를 가진다. Workload가 증가함에 따라 Node 수를 늘리거나 Node 유형을 Upgrade하여 Computing 성능과 Storage 용량을 늘릴 수 있다.
Node 유형
Cluster를 Launch할 때 Node 유형을 선택해야 한다. Node 유형은 각 Node의 CPU, RAM, Storage 용량, Storage drive 유형을 결정한다.
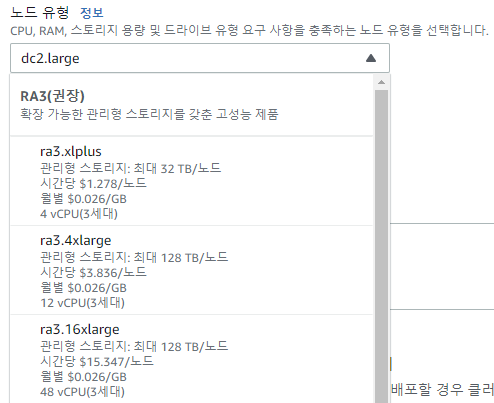
- RA3
RMS(Redshift Managed Storage)에 의해 관리되는 관리형 Storage를 갖춘 고성능 유형.
Computing + RMS로 구성된다. 즉 Computing과 Storage를 독립적으로 구성할 수 있다. 따라서 비용 구성도 컴퓨팅 비용 + RMS 비용으로 나뉜다.
사진에서 보이는 옵션을 보면 결국 Computing 사양을 선택하는 옵션이고 (시간당 $*.***/노드), Storage 용량의 경우는 RMS에 의해 별도로 늘어나기 때문에 동일한 것을 볼 수 있다 (월별 $0.0026/GB).
RMS는 고정된 저장용량을 가지지 않고, 수십 TB 이상의 용량까지 늘어나는 AWS에서 관리하는 Storage이다.
Computing 비용은 DC2에 비해 비싸긴 하다. 기본 4 vCPU부터 시작이기도 하고... RA3 유형에 CPU 낮은 걸 제공해주진 않는다 쩝...
ra3.xlplus1개 Node 기준으로 Computing 비용만 단순 계산하면 월별 이 나온다. 물론 Cluster를 24시간 틀어놓진 않을테니..
Storage 비용은 월별 /GB이다.
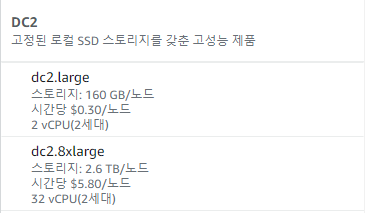
- DC2 (Dense Compute)
고정된 Local SSD Storage를 갖춘 고성능 유형.
Computing과 Storage 사양을 별도로 구성할 수 없다. Storage를 늘리고 싶으면 Node 수를 늘려야한다.
기본적으로 160GB 이상의 고정된 Storage를 갖게 된다. 흔히 말해 우리가 SSD 160GB짜리 노트북이 필요하다고 할 때, 아예 그 노트북을 구입하는게 아니라 빌려서 사용한만큼 돈을 지불하는 것이다.
컴퓨팅 비용은 RA3에 비해 확실히 저렴하다(여기에 Storage 비용이 포함된 것 같다?).dc2.large의 경우 월별 가 나온다.
- DS2 (Dense Storage)
고정된 Local HDD Storage를 갖춘 대규모 Workload에 적합한 유형
대용량 저장이 가능한 HDD를 활용한 유형같지만, SSD의 저장 용량도 좋아져서 권장하지 않는 Node 유형같다. 8개 이상의ds2.xlarge또는ds2.8xlarge를 사용하는 경우 RA3로 Upgrade하여 동일한 비용으로 2배 많은 Storage와 향상된 성능을 얻을 수 있다고 한다.

Node 유형 설명
https://aws.amazon.com/ko/redshift/pricing/

Node Slice
- Compute Node는 Slice로 분할된다. 각 Slice는 Node에 할당된 Workload의 일부를 처리하기 위해 해당 Node의 Memory 및 Disk 공간의 일부를 할당받는다.
- Leader Node는 Slice에 데이터를 배포하는 것을 관리하고, Query 또는 DB Operation에 대한 Workload를 Slice에 분배한다. 그런 다음 Slice가 병렬로 작업을 완료한다.
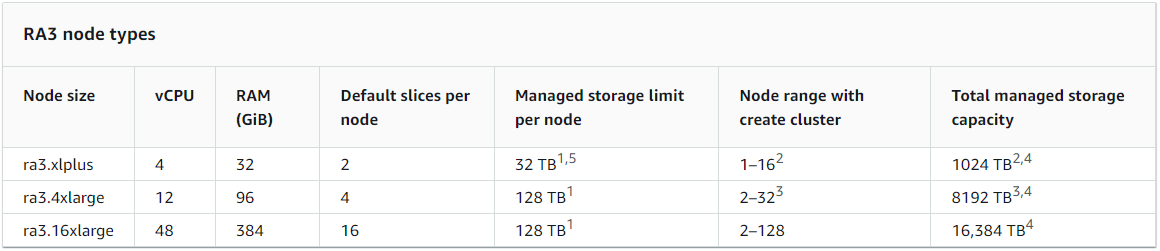
- Node 당 Slice의 수는 Node 크기에 의해 결정된다.
예를 들어 RA3 Node 유형의 경우 아래와 같은 Slice 수를 가진다.
- Redshift에 테이블을 생성할 때, 선택적으로 한 개의 Column에 Distribution Key를 명시할 수 있다. 테이블에 데이터가 Load되면, Rows들은 테이블에 정의된 Distribution Key에 따라 Node Slice에 배포된다.
Distribution Key를 잘 선택하면 병렬 처리를 사용하여 효율적으로 데이터를 Load하고 Query를 수행할 수 있다.
(여기서 다룰 내용은 아닌 것 같고 나중에 더 자세히...)
Internal Network
- Redshift는 고대역폭 연결, 근접성 및 Custom 통신 Protocol을 활용하여 Leader Node와 Compute Node 간에 Private 초고속 Network 통신을 제공한다.
- Compute Node는 Client application이 결코 직접 Access 할 수 없는 별도의 격리된 Network에서 실행된다.
DB
- Cluster는 1개 이상의 DB를 가진다. 사용자 데이터는 Compute Node에 저장되고, SQL client는 Leader Node와 통신하여 Compute Node와 Query 실행을 Coordinate한다.
- Redshift는 RDBMS이기 때문에 다른 RDBMS와도 호환된다. Redshift는 DML(Insert, Delete, ...)같은 OLTP (Online Transaction Processing) 기능을 포함하여 일반적인 RDBMS의 동일한 기능을 제공할 뿐만 아니라, 매우 큰 데이터셋의 고성능 분석과 Reporting에 최적화되어 있다.
- Redshift는 PostgreSQL을 기반으로 하지만 DW를 설계하고 개발할 때 많은 차이점이 있다.
