개요
DAG 설계 및 Library를 잘못 활용함으로서 발생할 수 있는 문제를 살펴보고, DAG 최적화의 중요성 및 효과에 대해 다뤄보고자 한다.
Worker Node의 사양 산정은 중요하다. (Autoscaling 이런 거는 우선 논외로 하자)
Task를 실행하다보면 Out Of Memory 에러 현상 등을 경험할 수 있기 때문이다.
우선 이 에러가 발생하게 되면 Worker Node 사양을 높여야 된다고 생각할 수 있고, 사양을 업그레이드하면 이는 비용의 증가로 이어진다.
이 때 생각해봐야될 점은, Memory 부족 현상이 정말 Node 리소스가 부족해서 일까? 이다.
Memory 점유율이 8-90% 대에서 OOM 에러를 경험하면 Node 리소스 부족 문제로 착각할 수 있기 때문이다.
다시 한 번 생각해보자.
Memory 부족 현상이 정말 Node 리소스가 부족해서 일까?
아니다.
예를 들면 잘못된 Python Library의 활용 등이 문제가 될 수 있다.
다시 말해,
잘못된 DAG 설계가 근본적인 원인일 수 있다.
이 포스팅에서는 잘못된 DAG 설계가 미치는 영향과 최적화의 중요성에 대해 필자가 겪은 사례를 통해 살펴보려 한다.
번외
물론 대용량 처리와 같은 무거운 작업은 Airflow가 처리하는 것은 바람직하지 않다.
Airflow는 Workflow Orchestration Tool이기 때문에 Airflow Cluster는 가볍게 유지하고, 대용량 처리는 Spark와 같은 대용량 처리에 최적화된 서비스로 위임하는 것이 좋을 것이다.
하지만 무조건 위임하는 것만이 능사는 아니다.
어쨋든 Airflow의 Worker Node가 놀고 있다면 적당한 선에서 활용할 수도 있는 노릇..
잘못된 DAG 설계로 인해 겪었던 문제
Airflow에서 DAG가 실행될 때, Negsignal.SIGKILL 로그를 던지면서 Task가 Fail나는 경우가 있다.

SIGKILL 에러는 보통 Memory가 부족할 때 발생하며, 따라서 Task를 실행하는 Worker Node의 Memory를 올리면 된다.
단, DAG 설계가 큰 문제가 없다고 가정할 때 해당된다.
자세한 내용은 아래 포스팅에 정리되어 있다.
https://velog.io/@jskim/Airflow-Negsignal.SIGKILL
한 때는 Node Memory 업그레이드로 해결이 되었으나, Memory 업그레이드는 근본적인 문제 해결은 아니었다.
어느 순간부터 Negsignal.SIGKILL 에러를 다시 던지기 시작했고, Task 실행 중에 유휴 Memory도 매우 많이 남아돌고 있었기 때문이다.
문제 현상
500MB 대 Parquet 파일 하나를 4GB Memory를 가진 Worker Node에서 내려받는데 (다른 실행되는 Task는 없고, 이 Task만 실행) Negsignal.SIGKILL 에러가 난다.
Memory 사용량을 모니터링해보니 Task가 실행 중에도 유휴 Memory는 2.3GB 정도 이하로 내려가지 않았다.
그리고 Task가 실행될 때 Memory를 생각보다 너무 잡아먹는 경향도 있는 것 같다.
원인 분석 및 해결
하지만 유휴 Memory가 많기 때문에 Negsignal.SIGKILL 에러가 Out Of Memory 문제가 맞는지도 의심이 되었다.
CPU, Network 리소스가 문젠가 싶어 EC2 모니터링도 살펴보았지만 전혀 문제될 게 없어보인다.
dmesg (diagnostic message) 명령어는 커널 Log를 출력한다고 한다.
Worker Node에서 dmesg 명령을 실행해보니 확실히 Memory 문제라는 것을 알 수 있었다.
OOM Killer가 Airflow Task 프로세스를 죽였다.

그렇게 Memory 문제라는 것은 알았지만,
Node 자체 Memory 문제는 아니라고 분석되었고,
requests 모듈이 Memory에 응답 데이터를 받는 부분도 의심이 되어 DAG 최적화를 했다.
그 결과 Memory 과점유 현상을 해결하고, Node 사양도 다운그레이드하여 사용할 수 있었다.
원인은 Python에서 Memory 과부하에 대한 Signal을 OS로 보낸 것 같다고 결론을 내었다.
(Python Memory에 대해 Deep Dive 해봐야 명확해 질 것 같긴 하다.)
결론
Memory 부족 현상을 단순히 Node의 Memory 사양 부족으로 판단해선 안된다.
DAG를 잘못 설계함으로서,
- Memory 과점유 현상을 동반함과 동시에
- 유휴 Memory가 실질적으로는 많은데 이를 인지하지 못하고 Worker Node 사양을 업그레이드하는 잘못된 해결 방식을 택할 수도 있다.
최적화
OOM 에러로부터 최적화까지 하게 되었는데, 이제 최적화의 효과를 확인해보고 최적화의 중요성에 대해 다시 한 번 느껴보자.
DAG 로직 개선 비교
requests 모듈의 stream 기능과 S3 Multipart Upload 기능을 이용하여 대용량 데이터를 쪼개서 처리하는 방식으로 최적화하였다.
기존
한 번에 대용량의 데이터를 Memory에 다운받고, Memory에 있는 데이터를 S3에 한 번에 업로드 하는 로직
최적화 후
데이터를 100MB Chunk 단위로 쪼개서 Memory에 다운받고, 100MB Chunk 데이터가 받아질 때마다 S3에 업로드
Chunk 단위 처리에 대한 내용은 아래 포스팅에 자세하게 나와있다.
대용량 데이터 다운로드 & S3에 업로드 최적화하기 with Python
https://velog.io/@jskim/대용량-데이터-다운로드-S3에-업로드-with-Python
기존 로직
response = requests.get(url)
data = response.content
s3 = boto3.client("s3", aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key)
s3.put_object(Bucket=bucket, Key=key, Body=data)최적화 후
MB = 1024 * 1024
chunk = 100 * MB
with requests.get(url, stream=True) as r:
if r.ok:
mpu = s3.create_multipart_upload(Bucket=bucket, Key=key)
mpu_id = mpu["UploadId"]
parts = []
for i, chunk in enumerate(r.iter_content(chunk_size=chunk), start=1):
part = s3.upload_part(
Body=chunk,
Bucket=bucket,
Key=key,
UploadId=mpu_id,
PartNumber=i
)
part_dict = {'PartNumber': i, 'ETag': part['ETag']}
parts.append(part_dict)
result = s3.complete_multipart_upload(
Bucket=bucket,
Key=key,
UploadId=mpu_id,
MultipartUpload={'Parts': parts}
)
Memory 사용량 개선 효과 비교
Memory 사용률이 매우 많이 떨어졌다.
기존에는 800MB에 가까운 Memory를 사용하다가, 실제 데이터를 100MB 단위로 처리하니까 200MB 안되게 사용하는 것을 볼 수 있다.
4배의 개선효과가 나타났다!
더불어, 잘못된 판단으로 업그레이드 했던 Node 인스턴스도 t2.medium → t2.small ( 4 GiB → 2 GiB Memory )로 다운그레이드 시켰는데도 충분히 많은 Memory를 사용할 수 있게 되었다.
기존
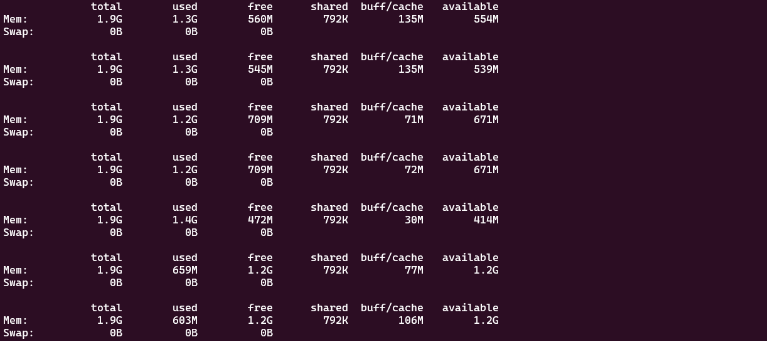
최적화 후

