Processors & Programs
what is a program?
- Processor는 program counter(PC)가 가리키는 instruction을 실행하는 것이다.
what is processor?
- instruction을 수행하는 것
what is latency?
- 한가지 작업을 할 때 얼마나 걸리는지
what is throughput?
- 일정 시간동안 얼마나 많은 일을 할 수 있는지
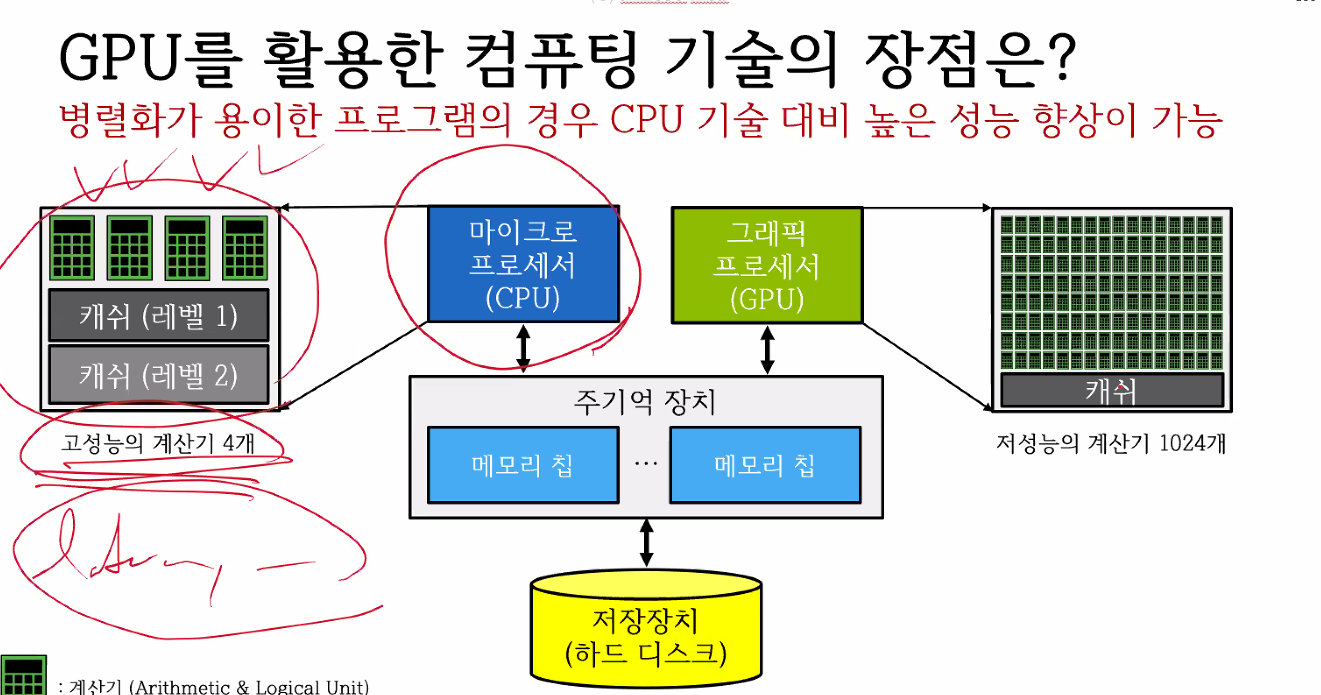
CPU와 GPU의 특징
CPU
특징
- Latency-optimized
- 하나의 thread에서 가장 빠르게 수행하는 것에 focus를 맞춘 것 - 방법
- Pipelining : instruction을 쪼개서 단계별로 동시에 수행할 수 있도록 하는 것
- Caches : 속도가 빠른 Caches에 미리 필요한 정보를 두어 메모리 접근 시간을 단축
- prefetching : 다음에 사용할 것을 미리 예측하여 미리 Caches에 올려두는 것
- Out-of-order excution + superscalars : data가 independant 하다면 동시에 실행시키는 것으로 이는 폰노이만의 순차적 실행에 위배되어 out-of-order라고 한다.
- ILP(Instruction-level parallelism) : 독립적으로 수행 가능한 instruction을 찾는 것으로 이를 통해 실행 시간을 단축시킨다.
- explicit SIMD 개념의 프로그래밍으로 GPU보다 병렬처리 프로그래밍이 힘들다.
- 구성
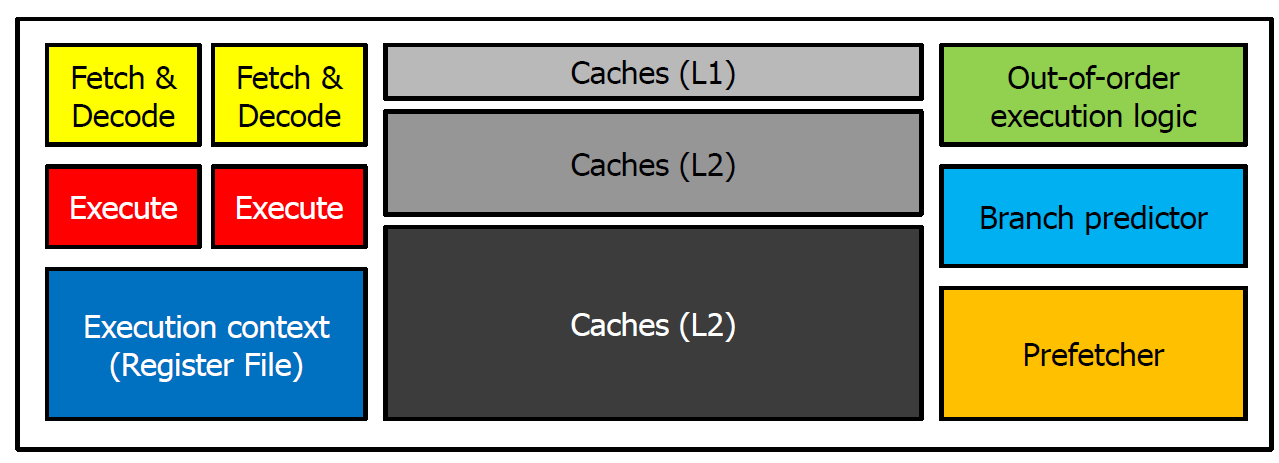
한계
- 코어 수를 여러개로 구성하여 병렬처리를 한다면 더 빠른 실행시간을 얻을 수 있지만 이를 위해서는 SW에서의 최적화가 필요하다. HW는 병렬처리를 위한 준비가 되어 있지만 SW가 받쳐주지 못하면 할 수 없다. 따라서 실행시간의 발전에는 한계가 있었다.
- 코어가 늘어나면서 필요한 power가 급격하게 커져서 감당할 수 없게 된다.
GPU
특징
- Throughput-optimized
- 일정한 시간동안 가장 많은 일을 처리하는 것에 focus를 맞춘 것
- 방법
- Get rid of compenents that help a single instruction stream run fast
- Scale the number of shader : 처리하는 shader의 수를 늘리기
- SIMD processing : 많은 ALU를 두어 비용을 최소화한다.
- CPU에 비해 더 많은 Register File를 둔다.
- thread의 수를 CPU에 비해 아주 크게 늘린다.
- bandwitdh를 크게 한다.
- 크게 만드는 관습으로 더 많은 칩을 넣을 수 있다.
- CUDA로 implicit SIMD를 구현할 수 있어서 병렬 처리 프로그래밍에 용이하다.
한계
- CPU가 명령해야지만 GPU에서 실행할 수 있다.
- CPU는 memory를 꽂으면 더 많이 늘릴 수 있지만 GPU는 memory가 제한되어 있다.
CPU와 GPU의 차이
- CPU는 코어 수를 늘리며 병렬 처리를 할 수 있도록 HW적으로 바꿀 수는 있지만 SW가 뒷받침되어야하기 때문에 한계가 있었다. 하지만 GPU는 thread를 늘려 병렬처리를 하기 때문에 바로바로 병렬 처리가 반영되어 성능이 선형적으로 향상되었다.
Parallel Programming Models
What is an SPMD programming model?
- Single Program that operates over Multiple Data
- 프로그래머는 함수 하나만 사용하면 되고 이 때 여러 thread가 수행하게 된다. 이 후 다시 하나로 처리되어 합쳐진다.
- 이러한 것을 CUDA나 OpenMP이라고 한다.
실행 과정
- CPU에 함수들이 올라가 있다.
- CPU가 GPU에게 병렬 처리 연산을 명령한다.
- 실행 결과가 GPU memory에 저장된다.
- 연산이 끝난 다음 GPU memory에서 CPU memory로 전달해준다.
- threadIdx라는 CUDA에서의 특수한 변수로 thread의 ID를 의미한다. 이는 미리 선언이 되어 있어서 선언할 필요가 없고 함수 내에서 사용하면 된다.
abstraction vs implementation
- abstraction은 함수를 사용하는 것
- implementation 함수 내부를 구현하는 것
- 효율적인 SPMD programming을 위해서는 어떤 구현을 하는지에 따라 SIMD를 할 지 MIMD를 할 지 생각해야한다.
Summary
- Single program, multiple data(SPMD) abstraction
- 프로그래머가 어떤 가정하에 코드를 짤지
- Single program, multiple data(SPMD) implementation
- 프로그램이 어떻게 구현이 되어 있는지
Parallel Programming "Models"
1. Shared Memory Model
- bytes의 배열로 이루어진 주소 저장 공간을 공유한다.
- 한 메모리 공간을 한 thread는 쓰고 한 thread는 읽으려고 한다면 충돌이 있어나서 잘못된 결과를 초래할 수 있다. 이럴 때는 lock을 걸어서 쓰는 동안 다른 thread가 읽지 못하게 한다. 이를 Synchronization(동기화)라고 한다.
- 동기화를 위한 것을 atomicity라고 하며 atomic하게 더이상 쪼갤 수 없게 한번에 실행되는 것 처럼 고정 시키는 것이다.
Summary
- Communication abstraction
- threads들이 공유 메모리를 사용할 수 있으며 이때 충돌하는 문제를 해결하기 위해서 synchronization이 필요하다.
- Requires hardware support to implement efficiently
- 공유 메모리 사용을 위해서는 하드웨어 적으로 실행이 효율적으로 가능하도록 뒷받침이 되어야한다.
2. Message passing model
- Open MPI(Message Passing Interface)
- message를 넘겨주는 것
CUDA Programming
1. CUDA Programming(part 1)
특징
- Host(CPU), GPU(co-processor)으로 CPU가 GPU에게 명령을 보낸다.
- GPU에는 수십만개의 thread가 있다. 이 때 실제로는 thread를 그룹화하여 이를 계층을 만들어 사용한다.
- thread Id를 이용하여 thread를 사용
- CUDA는 implicit SIMD로 암묵적으로 알아서 병렬 처리할 수 있도록 처리한다.
what is a thread-block?
- data를 빠르고 효율적으로 전달할 수 있다.
- 이는 compute당 memory 비율을 높이는 것이다.
예제
- CPU에서 GPU로 데이터 옮기기
- cudaMalloc() : GPU의 메모리에 공간 할당하기
- cudaFree() : GPU의 메모리 공간 할당 해제
- cudaMemcpy(src, dst) : CPU에서 GPU, GPU에서 CPU로 데이터 복사하기
- 연산
- GPU에서 CPU로 데이터 옮기기

- __host__는 CPU에서 실행된다는 것 __global__은 GPU에서 실행된다는 것
- dim3 DimGrid : 몇개의 thread block인지 프로그래머가 정의
- dim3 DimBlock : 한 thread block에 몇개의 thread가 있는지 프로그래머가 정의
2. CUDA Memory Model
Example - Matrix Multiplication

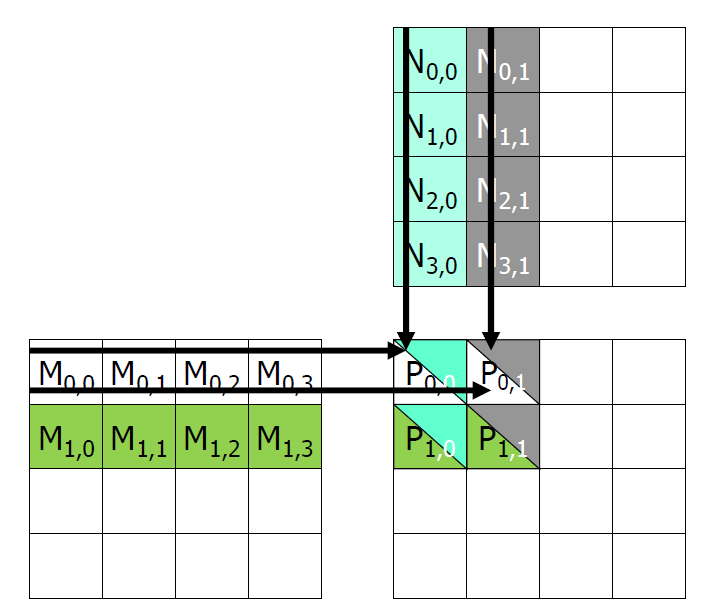
- 여기서 같은 row에 대해서 다른 column이 계산될 때 같은 데이터를 계속 복사하기 때문에 불필요한 데이터 복사가 일어난다. 따라서 shared memory가 필요하다. 이것이 scratch memory 개념과 관련있다.
Shared Memory in CUDA
- 쓰고 싶은 만큼 명시적으로 shared memory 할당을 선언해야한다.
Scratchpad vs caches
- 공통점은 빠른 저장소 이다.
- 차이점은 Caches는 명시적으로 프로그램을 작성하지 않아도 자동으로 적용된다. 하지만 Scratchpad는 명시적으로 프로그램을 작성해야하기 때문에 더 어렵다. 이를 해야하는 것이 CUDA 프로그래밍이다.
3. CUDA Programming(part 2)
Tiling Algorithms
- DRAM에서 필요한 것을 SRAM에 한번만 올려서 중복으로 메모리를 복사하는 것을 방지하는 것
- 서로의 필요한 시간을 맞추는 synchronization이 필요하다.
- Identify a tile of global memory contents that are accessed by multiple threads
- Load the tile from global memroy into on-ship memory
- Use barrier synchronization to make sure that all threads are ready to start the phase
- Have ther multiple threads to access their data from the on-chip memory
- Use barrier synchronization to make sure that all threads have completed the current phase
- Move on to the next tile
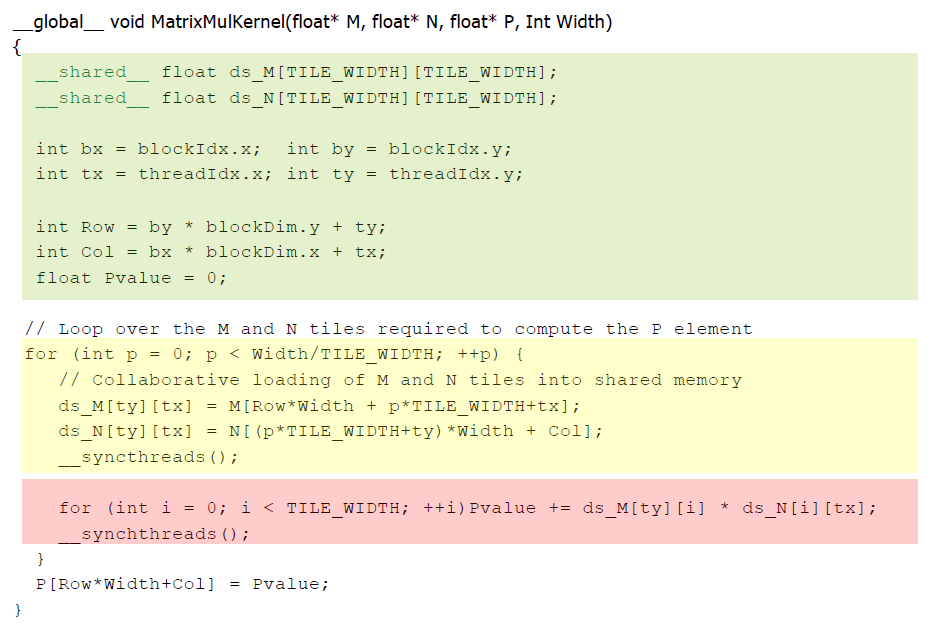
- 공유 메모리로 ds_M, ds_N이 사용
- matrix M, N은 DRAM에 저장되어 있는데 scratchpad ds_M, ds_N으로 복사하도록 작성했다. 이것이 명시적으로 scratchpad memory에 복사하라고 명령하는 부분이다.
4. Atomics
- Read -> modify -> write를 한번의 operation에 되도록 보장하는 것
- 이는 데이터 충돌을 방지하기 위해서다.
example
- atomicAdd()

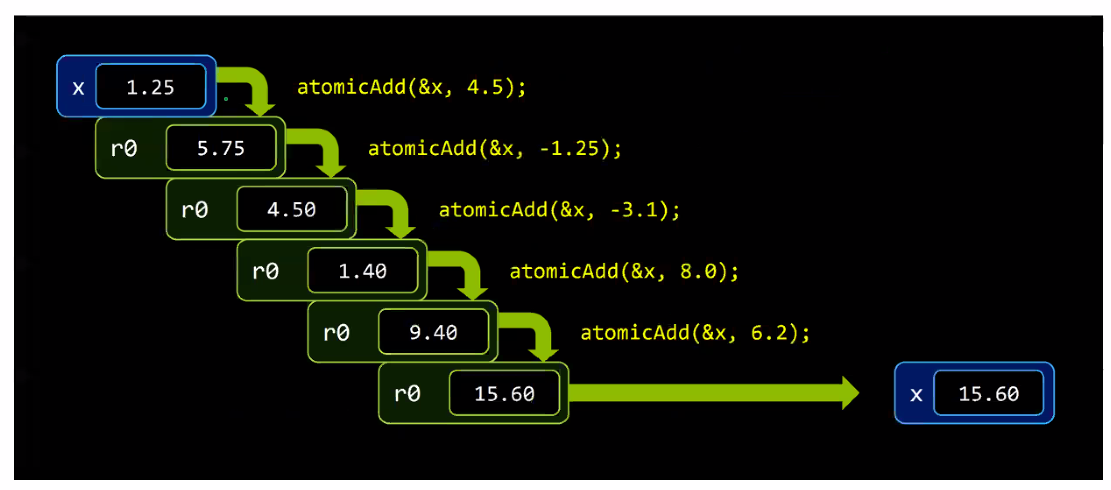
- 임의의 순서로 사용할 수 있도록 보장해주는 API
특징
- 아키텍처마다 실행이 달라질 수 있는데 이를 방지하기 위해서 memory-fence를 사용한다.
- memory-fence에서는 __threadfence_block, __threadfence, __threadfence_system이 있다.
GPU와 인공지능의 만남
딥러닝이란?
- 뉴럴-네트워크 기반의 기계-학습 알고리즘 레이어 수를 깊게 구성하는 기법
딥러닝 연산 특성
- 병렬/분산화가 용이한 수많은 덧셈 및 곱셈 연산으로 구성되어 있다.