논문 내용 요약과 인상 깊은 점
논문 내용 요약
- random channel pruning을 사용하여 channel configuration을 search하였다. 곧 channel pruning은 주어진 맨 처음의 architecture에서 가장 효율적인 architecture를 찾는 것이다.
- random channel pruning은 각 layer별 pruning ratio를 random으로 선택하는 것이고 내부 channel 중 어떤 것을 선택하는 지는 L1/L2 norm과 같은 pruning method를 활용한다.
- random channel pruning은 from scrath과 from pre-trained model 모두에서 적용가능하고 각각 특정한 제한을 설정하여 sampling population이 너무 커지는 것을 방지한다.
- sub-network의 fine-tune epoch가 성능에 영향이 크기 때문에 이를 맞춰주어야 공정한 비교가 가능하다.
- 여기서 나온 결과들은 다른 pruning method의 benchmark를 분석할 때 baseline이 될 수 있다. 즉 channel pruning의 baseline을 제공한다.
인상 깊은 점
- pre-trained network를 random channel pruning할 때 각각의 sub-network의 fine-tune에 시간이 많이 소모되기 때문에 이를 개선하고자 를 사용한 것이 인상깊었다.
- 실험 결과 pruning method에서 월등한 성능을 발휘하는 것이 없었고, 심지어 최신 방법들도 L1/L2 norm magnitude를 활용한 것과 비교했을 때 큰 차이가 없다는 것을 알고 뭔가 허무했다. * 결국 최적의 channel configuration을 효율적으로 찾기위한 방법으로 연구의 방향이 바뀌어야한다고 주장한 부분이 흥미로웠다.
- fine-tune의 epoch가 크기만 하다면 성능이 좋아질 수 있다는 것에 충격을 받았고 이전에 경량화 한 모델의 성능을 높이기 위해 무작정 fine-tune epoch를 키워서 올렸던 경험이 떠올랐다.
- 결국 channel pruning은 주어진 맨 처음의 architecture에서 가장 효율적인 architecture를 찾는 것이라는 점에서 큰 인사이트를 얻을 수 있었다.
Abstract
- Channel pruning이 neural network의 inference를 효과적으로 가속한다.
- 많은 Channal pruning 하는 알고리즘이 제안되었지만 이들을 직접적으로 비교하는 것은 알고리즘의 복잡도도 다르고 training process와 같은 개별적인 설정이 필요해서 불가능하다. 따라서 fair benchmark가 중요해졌다.
- 최근 연구에서 밝혀낸 것은 channel configuration이 pre-trained weight만큼이나 중요하다는 사실이다. 이는 channel pruning이 최적의 channel configuration을 찾는 새로운 역할을 한다는 것과 같다.
- 이 논문에서 우리는 random pruning을 사용하여 공정하게 비교하였고 그 결과 channel pruning 알고리즘 중에 확실하게 잘되는 것은 없다는 것을 알 수 있었다.
1. Introduction
- channel pruning은 CNN을 가속할 수 있는 방법 중에 하나다.
- 이 논문의 목적은 random pruning에 대한 channel pruning의 과정에 대해 실증적인 연구이다. 여기서 random pruning은 각각의 layer별로 random한 ratio로 특정 기준을 가지고 pruning하는 것을 말한다. 이는 최고의 channel pruning의 개선을 보여줄 수 있는 기준점이 된다.
- random pruning의 힘이 아직 완전히 알려지지 않았고 우리는 다음과 같은 발견을 했다.
Finding 1
- 최근 제안된 channel pruning 방식의 성능은 간단한 L1, L2 norm을 기준으로 한 것과 비슷하다.
Finding 2
- pre-trained model에서 시작한 것과 random pruning의 성능을 비교하면 random pruning이랑 성능이 비슷하거나 ramdom pruning이 더 좋다.
Finding 3
- nerwork architecture까지 최적화하는 최신 pruning 방법과 random pruning 방법과의 성능을 비교해봐도 그 차이가 적다.(ImageNet classification에서는 0.5% 미만)
Finding 4
- pruning이후 Fine-tuning epoch가 클수록 성능이 좋다는 결과가 나왔다.
Finding 정리
- F1을 보면 Occam's razor(오컴의 면도날)에 따라 단순한 L1/L2 기반의 pruning이 좋은 성능을 보인다는 것을 알 수 있다.
- F2, F3를 보면 network pruning 출현 이후 별로 발전하지 않았다는 것을 말하고, channel pruning network의 최대 성능은 original network의 성능이며, 많은 계산량 끝에 작은 성능 개선이 이루어지는 것을 말한다.
- F4에 의하면 fine-tuning epoch가 표준화되어야 비교할 수 있다는 것을 말한다.
-
random pruning은 다른 channel pruning 방식의 benchmark가 될 수 있고, 다른 방면에서는 또다른 pruning 기준이라고 할 수 있다. 또한 random pruning은 random한 하위 네트워크에서 가장 성능이 좋은 것을 고르는 단순한 방법이다.
-
이 논문에서는 random pruning을 2가지 방식으로 다뤘다.
- pre-trained network에서 prune하는 것
- random-initialized network에서 prune하는 것으로 이는 구조를 찾는 문제와 같다. 이는 논문에서 pruning from scratch라고 언급할 것이다.
-
2가지 방식 모두 작은 network를 위해 최적의 채널 수를 찾는 것이 목표이다.
Contributions
- 우리는 다른 channel pruning 방식의 비교를 위한 random pruning이라는 강력한 benchmark를 제안한다.
- 우리는 왜 random pruning이 세심하게 고안된 pruning 방식과 비슷한 성능이 나오는지를 분석한다.
- 우리는 많은 channel pruning 방식의 성능과 random pruning 성능을 모두 비교해보며 channel pruning의 현위치를 느끼게 한다.
2. Related Works
- 처음에는 unstructured pruning을 주로 하였는데 이는 hardware에 적용하는 것이 어려웠다. 그래서 structured pruning 방식을 연구하게 되었고 이는 가속에 용이하였다.
- structured pruning의 종류
- weight의 L1/L2 norm의 크기순 또는 median 이용
- feature map을 근사화하는 방식
- loss 함수의 기울기 이용
- KL divergence 이용 등
- 최신 pruning method가 제안됨에도, 이러한 method는 어떤 filter가 더 중요한지를 알려주는 것이지 얼마나 많은 parameter를 없애야하는지, 어떤 모델 구조로 정의할지에 대해서는 알 수 없다.
- 우리의 연구는 단순하게 random architecture search를 제안하고, 대부분의 pruning method를 편향되지 않고 일반적인 접근으로 비교한다. 그리고 이미 정의된 architecture에서 부터 가장 좋은 architecture를 찾는 것이다.
- 우리의 연구는 다른 pruning method를 비교하기 위해 baseline을 제시하기 위한 목적이다.
3. Definition and Preliminaries
3.1. Basic concepts and formalization
Definition 1
random sampling에는 3가지 방식이 있다.
1. layer별 pruning할 채널 개수도 랜덤, pruning할 채널을 고르는 것도 랜덤
2. layer별 pruning할 채널 개수는 규칙에 따라 설정, pruning할 채널 고르는 것 랜덤
3. layer별 pruning할 채널 개수 랜덤, pruning할 채널 고르는 것은 규칙에 따라 선택
이 논문에서는 3번째 방식을 random pruning이라고 한다.
Definition 2
- channel configuration의 경우의 수를 다음과 같이 정의한다.
: i번째 Layer
: i번째 Layer의 채널 수
: i번째 Layer의 채널의 경우의 수로 -1을 한 이유는 아무것도 고르지 않는 경우를 빼준 것이다.
: 전체 Layer에 대한 채널을 고르는 경우의 수로 n은 layer 수를 말한다. - Channel pruning method는 최대 정확도를 가지는 channel configuration을 찾는 것이 목표이다.
- channel pruning에 매우 영향력 있는 2가지는 다음과 같다.
- Property 1
channel configuration은 이산적이기때문에 미분 분석이 불가능하다. 따라서 reinforce learning, evolutionary algorithm, proximal gradient descent를 사용하기도 한다. - Property 2
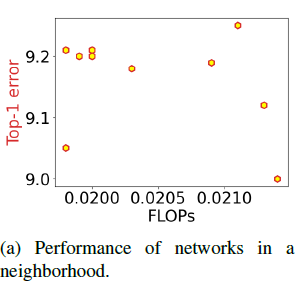
비슷한 크기의 channel configuration은 정확도가 크게 차이나지않는다. 이는 다음 그래프의 왼쪽 위를 보면 비슷한 FLOPs에서 Top-1 error 값이 모여 있는 것을 확인할 수 있다.
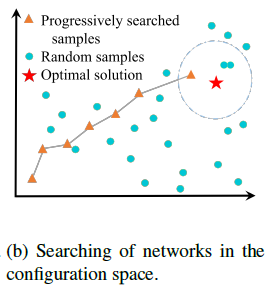
Regularization-based method는 점차적으로 optimal solution으로 나아가지만 random pruning은 근처의 optimal solution으로 sampling을 통해 나아간다는 차이가 있다. 이는 다음 그래프로 설명하였다.
우리는 random pruning을 다음과 같은 2가지의 설정으로 하였다.
Setting 1: Pruning pre-trained networks
이미 학습된 network를 사용하여 중요도가 낮은 channel을 pruning한다.
Setting 2: Pruing from scratch
학습되는 동안 mini-batch마다 channel configuration space를 만들고 4개의 sub-networks를 병렬로 학습하여 parameters를 업데이트한다. 자세한 내용은 Section 5에서 설명한다.
- Property 1
- network를 pruning하고 바로 성능을 측정하는 것은 성능 저하가 클 수 있기 때문에 신뢰할 수 없기 때문에 어떻게 해야 pruned network의 성능을 효과적으로 평가할 수 있을지가 문제다. 이 문제를 해결하기 위해 2가지 설정이 있다.
- pre-trained network를 pruning하고 각 layer 별로 original feature map과 pruned network의 feature map의 차이를 최소화하도록 업데이트한다. 이는 더 빠르게 parameter를 업데이트 할 수 있다.
- from scratch부터 pruning을 할 때는 학습 시 많은 sub-networks가 샘플링 된다. The network is trained such that the accuracy of all of the sub-networks tends to decrease. Parallel training arms the network with the capability of interpolating the accuracy of unsampled sub-networks.(?)
3.2. Pruning criteria
- channel pruning에서 각 channel의 중요성을 판단하는 것은 중요한데, 가장 직관적인 방법으로 L1/L2 norm magnitude를 기준으로 작으면 덜 중요하여 pruning하고 크다면 남겨두는 방법이 있다.
- 하지만 여기서 batch normalization layer때문에 feature map의 magnitude가 달라 질 수 있고, 분포에 따라서 작은 norm을 가지는 것이 덜 중요하다고만은 할 수 없다. 따라서 나온 방식이 geometric median을 제안하고 비슷한 filter를 없애는 연구도 있다.
- 위의 두 방식은 filter의 분포를 이용한 방식이지만 Kullback-Leibler divergence를 이용하여 중요도를 판단하여 값이 작다면 영향을 덜준다고 판단하여 pruning한다. 하지만 이 방버은 forward-pass마다 모두 계산해주어야해서 비교적 느리다.
- prediction error의 first- or second- order Tayler expansion을 사용하여 가속화 할 수 있다.
4. Pruning Pre-trained Networks
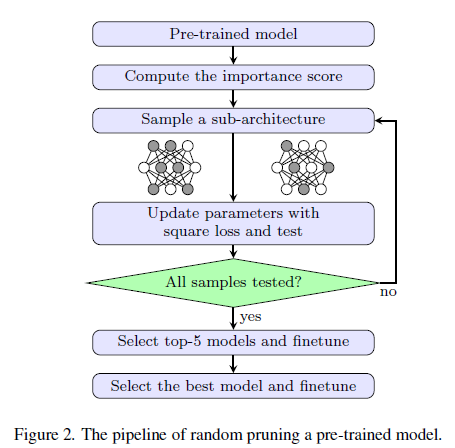
- pre-trained model을 위한 random 절차를 소개하는 부분
- pre-trained network에서 시작
- pre-trained network에서 각각의 channel별 중요도를 계산한다. 이는 다음 단계에 어떤 channel을 pruning할 것인지를 결정한다.
- sub-architectures를 선택하고 덜 중요한 channel을 pruning한다. 이 때 sub-architectures는 샘플링된 pruning ratio로 이루어져있고 최소 ratio로 설정한다. 최소 ratio를 라고 하여 pruning ratio의 범위는 이 된다.
- pruned network의 parameters는 original network와 pruned network의 feature map의 squared difference를 최소화하는 방향으로 업데이트 한다.
- validation dataset을 이용하여 pruned networks를 평가한다.
- top 5의 정확도를 가지는 model을 선택하고 이들을 추가 epoch동안 fine-tuned하여 network의 정확도를 보상한다.
- 최고 정확도를 가지는 것을 선택하고 더 긴 epoch 동안 fine-tuned한다.
- 자세한 사항은 아래 세부 섹션에서 다룬다.
4.1. Random sampling
: pruned network의 FLOPs
: original network의 FLOPs
: 목표 pruning ratio
: 목표 pruning ratio와 실제 pruning ratio의 차이 임계값- 는 랑 같거나 조금 작게 설정하였다.
- 이러한 설정의 효과
- 단순하고 hyperparameter tuning이 복잡해지지 않는다.
- 이는 샘플링하는 sub-space를 타당하게 제한한다. 를 설정하여 주요 channel이 pruning되는 것을 방지한다.
- bottleneck은 pruned network의 성능을 악화시킬 수 있다.
4.2. Updating network parameter
- pruned network의 성능을 측정하여 좋은 network를 찾는 것이 중요한데 이때 성능을 평가할 때 바로 평가하면 신뢰성이 떨어지고 fine-tune을 하면 시간 소모가 많은 단점이 있다. 따라서 이를 해결하고자 아래의 수식에 따라 parameter를 업데이트한다.
: pruned network의 feature map으로 의 차원을 가진다.
: original network의 feature map으로 의 차원을 가진다.
: pruned network가 더 작은 차원의 feature map을 가진다. 따라서 를 이용하여 reshape 한다.
: original network의 feature map에서 pruned network에 상응하는 채널을 남기고 나머지를 제거한 feature map
: 의 차원을 로 바꾸기 위해 생성한 matrics- matric를 Least mean square를 이용하여 구하고 이는 를 그대로 에 merge될 수 있다. 따라서 이는 추가적인 계산없이 pruned network를 업데이트 할 수 있게 된다.
- 위의 내용은 각 layer마다 적용되는 것이다.
5. Pruning From Scratch
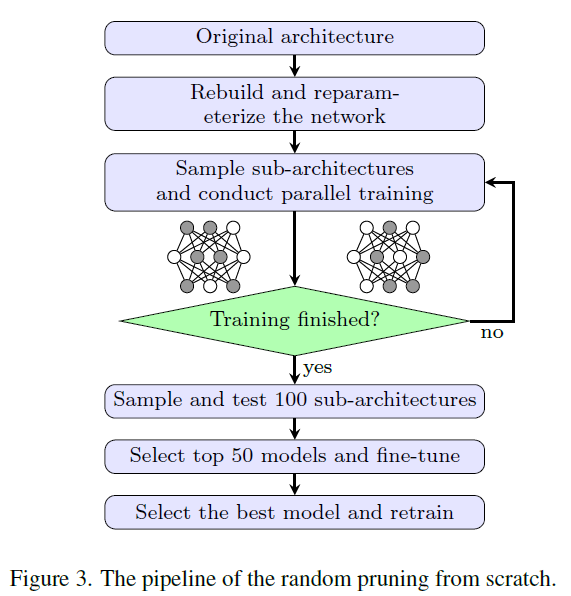
- from scrach에서 pruning하는 절차를 설명하는 부분이다.
- original architecure로 시작
- Slimmable Neural Network의 논문을 활용하여 slimmable network로 재구성하며, 이는 Sec. 5.1.에서 자세히 설명
- 병렬 훈련으로 구성되며, 이는 mini-batch당 4개의 sub-network를 샘플링하며 여기에는 1개의 온전한 network와 3개의 랜덤 샘플된 network이다.
- 4개의 forward와 4개의 backward가 구성된다.
- 4개의 backward가 gradient가 누적되어 parameter를 업데이트 한다.
- 온전한 network를 유지하는 이유는 모든 parameter가 업데이트 되는 것을 보장하기 위해서다.
- 내부 knowledge distillation이 사용되는 것이다.
- 에 의해 sub-networks를 샘플링하고 병렬 학습을 통해 샘플링 되지 않은 sub-network의 정확도를 보간할 수 있다. 따라서 sub-networks는 validation set으로 바로 평가할 수 있고 이는 신뢰할 수 있다.
- 성능 상위 50개의 model을 선택하여 few epochs동안 fine-tune을 한다.
- 최고 성능의 model을 선택하여 scratch부터 다시 학습한다.
5.1. Designing the network pruning space
- sub-networks의 종류가 너무 많기 때문에 이를 줄이기 위해 다음과 같은 규칙을 따른다.
- channel의 수는 8의 배수로 제한한다. 이는 비슷한 크기의 network는 비슷한 성능을 가진다는 Property 2에 의해서 제안하여 ResNet-18의 정우 가능한 sub-network configuration을 에서 로 줄였다.
- 최소 채널 개수를 8의 배수로 되게 반올림한다. 이는 너무 좁은 bottleneck을 피할 수 있다.
- pruning pre-trained networks와의 공정한 비교를 위해서 최대 network witdh는 늘리지 않는다.
6. Experimental Results
- pre-trained network
- ImageNet : PyTorch에서 제공하는 모델
- CIFAR : 직접 학습
- 300 epochs
- initial learning rate 0.1, 150, 225에서 0.1배씩 감소
- batch size 64
- pruning pretrained model
- top-5 fine-tune 5 epochs
- top-1 fine-tune 50 epochs(CIFAR)
- top-1 fine-tune 24 epochs(ImageNet)
- pruning from scratch
- 처음 학습 40 epochs
- pruning 후 학습 90 epochs
- sub-networks는 100개
- : 0.02
6.1. Benchmarking channel pruning criteria
- filter의 L1, L2 norm
- geometric median(GM)
- Taylor expansion(TE)
- KL-divergence importance metric(KL)
- empirical sensitivity analysis(ES)
- slimmable network(baseline)
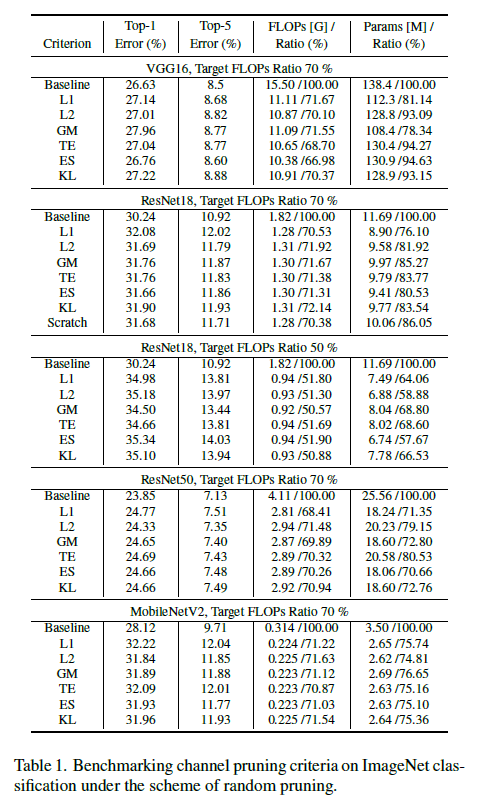
- 표 결론
- KL, ES로 기준을 한 것과 기본적인 L1, L2 norm 기준의 성능 차이가 크게 나지 않는다.
- 중요한 parameter가 있기 때문에 비슷한 computational complexity가 비슷해도 성능차이가 날 수 있다.
- 위의 2개의 결론에 따르면 기준에서 확신한 승자는 없었다.
- 최신 pruning criteria을 사용하는 이점은 pruned network의 25 epochs 이상의 fine-tune으로 대체될 수 있다.
- 효율적인 channel configuration을 찾는 것은 주요 연구 방향의 중의 하나가 되야한다.
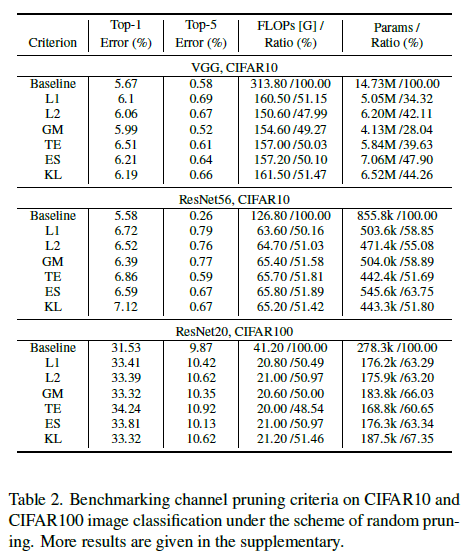
6.2. Benchmarking channel pruning methods

- 표를 보면 Epoch이 쓰여 있는데 이는 fine-tune epoch 수이며 이는 성능에 큰 영향을 주기 때문에 추가하여 비교하였다. 하지만 다른 방법들은 다른 training과 fine-tuning을 거치기 때문에 공정하게 비교할 수는 없다.
- 표 결론
- CIFAR10에서는 random pruning이 다른 비교 방법들보다 나쁘지 않았다. 이는 random pruning의 목적을 달성함을 알 수 있다.
- ImageNet에서는 이전의 pruning 방식인 SFP, GAL, SSS보다 적은 fine-tune epochs에서 월등히 좋은 성능을 보였다.
- fine-tuning epochs가 더 많은 HRank와 비교했을 때 random pruning이 경쟁력있다.
- MetaPruning과 비교하면 random pruning은 아주 약간 성능이 떨어진다. 하지만 MetaPruning의 baseline network의 작은 차이가 이미 FLOPs 감소에 도움을 주는 것을 알고 있어야 한다. 또한 fine-tuning이 더 많다.
- pre-trained network를 pruning하는 것과 비교하여 pooling layer의 배치와 최대 network width의 확장이 추가적인 이점을 가져올 수 있다.
6.3. Ablation study
Influence of the sampling population
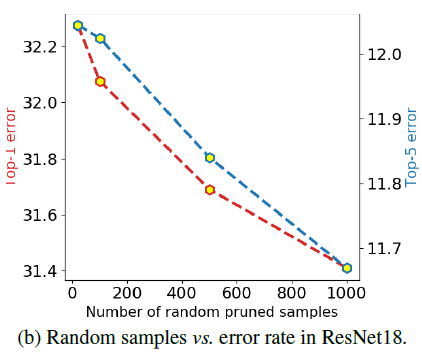
- random sample population을 점점 키워서 결과를 보면 population이 클수록 성능이 좋았다. 그리고 성능이 satuated 되지 않았다.(더 성능이 좋아질 수 있다는 것 의미)
- top-1 error를 보면 convex한 모습을 띠는데 이는 population 증가로 인한 정확도 상승이 점차 감소하는 것을 말한다.
Influence of fine-tuning epochs
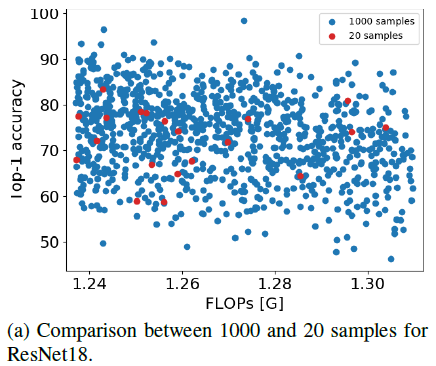
- sample population이 많아지면 좋은 sub-network와 나쁜 sub-network 둘 다 수가 늘어나는 것을 확인할 수 있고 이는 random이기 때문이다. 따라서 이는 더 나은 searching method가 필요하는 것을 의미한다.
Analysis of additional computational cost

- fine-tune의 epoch의 영향력에 대한 실험으로 epoch가 커질수록 성능이 좋아지는 것을 확인할 수 있다.
7. Conclusion
- 최적의 network architecture를 찾기위한 편향되지 않은 random search의 연구이다.
- random search는 scratch부터 적용하는 것뿐만아니라 pre-trained network에도 적용할 수 있다.
- random pruning은 단순하고, 일반적이고 더 복잡한 pruning method의 benchmark로 baseline을 제시한다.
