
학습결과
실험 1
사용한 Dataset : 770장 이미지
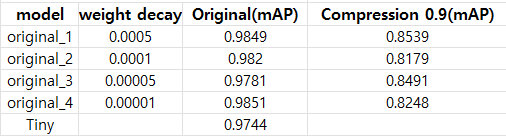
- original은 YOLOv3 모델을 사용한 것이고 weight decay를 바꿔가며 실험을 하였습니다.
- 데이터 수도 적고 물체도 비교적 크기 때문에 Tiny YOLO 모델에서도 mAP0.5 기준 0.9744를 달성하여 90% 압축한 것과 비교하여 10% 이상 성능이 좋은 것을 확인했습니다.
- 하지만 실제 환경에서는 물체가 작은 경우가 대다수이기 때문에 데이터 증폭할 때 사진의 크기를 줄여서 증폭하기로 하였습니다.
실험 2
사용한 Dataset : 770장 + 770 * 3 (Data augmentation) = 3080장
Train : 2100장, Valid : 980장
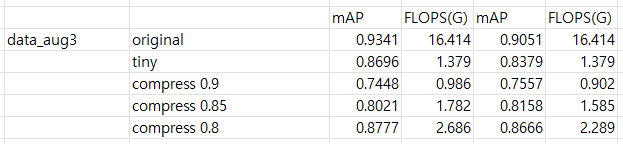
- 물체의 크기가 작은 사진들이 늘어났기 때문에 tiny는 0.8696으로 성능이 내려갔지 original을 90%, 85% 압축한 모델들의 성능보다 좋은 것을 확인하였고 original을 80% 압축한 모델보다는 성능이 안좋았다.
- 하지만 FLOPS 관점에서 여전히 FLOPS 대비 성능이 tiny 모델이 좋았다.
실험 3
사용한 Dataset : 770장 + 770 * 5 (Data augmentation) = 4620장
Train : 3200장, Valid : 1420장
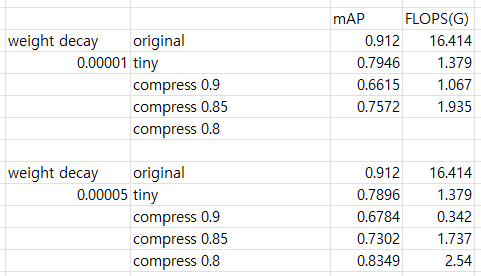
- 물체의 크기가 작은 사진들을 더 증폭하여 데이터 수를 4620장으로 학습하고 weight decay를 바꿔가며 실험해본 결과 FLOPS 대비 성능이 tiny 모델이 더 좋은 것을 확인하였다.
⭐ 촬영한 Dataset에는 한 사진당 하나의 물체만 있는 사진들이다. Dataset의 한계로 인해 FLOPS 대비 성능이 tiny 모델이 더 좋은 것으로 생각되어 추가적인 Dataset을 촬영하는 것이 필요하다고 판단하였다.
