들어가기 전
Java나 C같이 고급 언어로 작성된 코드들은 사람은 해석할 수 있지만 기계는 해석할 수 없습니다. 그래서 고급 언어로 작성된 코드를 실행하려면 저급 언어의 코드로 변환하는 과정이 필요합니다.
전통적인 변환 방식으로는 일단 실행하고 고급언어 명령어를 한줄한줄 기계어로 변환하며 작업을 수행하는 Interpreter 방식과 모든 고급언어 명령어를 실행 전에 기계어로 변환시키는 Compile 방식이 있습니다.
Interpreter 방식은 Compile 방식에 비해 초기 실행 속도가 빠르다는 장점이 있지만 실행 중에 기계어로 변환하고 연산을 수행하기 때문에 실행 중의 성능이 떨어집니다.
Compile 방식은 반대로 초기 실행 속도가 느리지만 실행 중일때의 성능은 좋습니다.
그러면 JIT Compiler는 Compile 방식이겠네?
JIT Compiler는 이름에서부터 알 수 있듯이 Compile 방식을 사용합니다.
그러나 JIT Compiler는 Compile 방식만 사용하는 것이 아니라 Interpreter 방식도 사용합니다.
두 방식을 다 사용하는 이유는 바로 두 방식의 장점을 모두 취하기 위해서입니다.
그게 가능해? 어떻게?
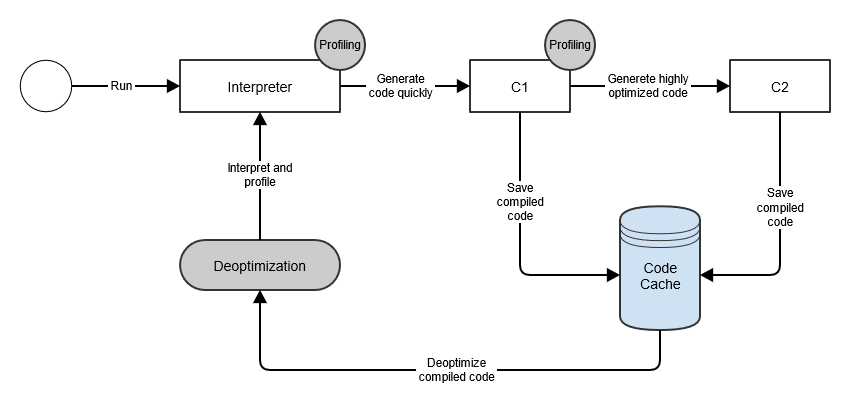
JVM은 처음에는 Interpreter 방식으로 모든 바이트코드를 실행합니다.
그와 동시에 메서드를 최적화할 수 있는지 그리고 얼마나 자주 사용되는지 프로파일링합니다.
실행된 메서드가 최적화가 가능하면 최적화를 진행하고 만약 자주 사용되는 메서드로 판명되면 해당 메서드를 컴파일하고 그 결과인 바이너리코드를 코드 캐시에 저장합니다.
추후에 해당 메서드가 다시 수행되면 Interpreter로 해석하지 않고 코드 캐시에서 컴파일된 바이너리코드를 바로 실행합니다.
이렇게 Interpreter의 초기 실행 속도가 빠르다는 장점과 Compile의 실행 중 성능이 좋다는 장점 두가지를 취할 수 있습니다.
그리고 이것이 바로 JVM이 JIT Compiler를 사용하는 이유입니다.
또한, 이런 특징 때문에 JVM 말고도 .NET(C#,F#,CLI…), V8(node.js) 등 에서도 JIT 컴파일러를 사용하고 있습니다.
JIT Compiler의 구조
JIT Compiler는 초기 실행 속도에 더 중점을 둔 C1과 실행 중 성능에 더 중점을 둔 C2 컴파일러로 이루어져 있습니다.
그리고 다시 C1은 Level1, Level2, Level3로 구분되는 세 단계의 컴파일 레벨이 있고 C2는 Level4의 컴파일 레벨이 있습니다.
그리고 각각의 Compiler들은 컴파일할 메서드들이 적재되는 각각의 우선순위 큐를 가지고 있습니다.
JIT Compiler는 C1 compiler와 C2 Compiler로 구성되어져 있고 각각의 Compiler들은 각각의 우선순위큐를 가지고 있습니다.
C1 Compiler는 가능한 한 빨리 코드를 최적화하고 컴파일 하기에 최적화되어 있습니다.
C2 Compiler는 C1에 비해 더 오랜 시간 동안 코드를 관찰하고 분석해 더 나은 최적화를 수행합니다.
이제부터는 JIT Compiler의 세부적인 내용을 살펴보겠습니다.
어떻게 자주 사용되어지는 메서드인지 판별할까?
JIT Compiler의 계층형 구조
JIT Compiler는 C1 compiler와 C2 Compiler로 구성되어져 있고 각각의 Compiler들은 각각의 우선순위큐를 가지고 있습니다.
C1 Compiler는 가능한 한 빨리 코드를 최적화하고 컴파일 하기에 최적화되어 있습니다.
C2 Compiler는 C1에 비해 더 오랜 시간 동안 코드를 관찰하고 분석해 더 나은 최적화를 수행합니다.
Compilation Level
Level0
모든 Java 코드를 Interpreter 방식으로 해석하는 단계.
C1
Level 1
메소드를 프로파일링을 하지않고 컴파일 하는 단계입니다. 메소드 복잡성이 낮기 때문에 최적화가 필요한 부분이 없프로파일링을 통한 C2 컴파일이 의미가 없기 때문입니다.
Level 2
C2 컴파일 큐가 가득 찼을때 최대한 빠르게 컴파일 하기 위해 사용되는 단계이다.
Level 3
사소하고 간단한 메소드(Level 1)가 아니거나 C2 컴파일 큐가 가득찬 경우(Level 2)가 아닌 그 외의 모든 경우에 사용되는 단계입니다. 가장 일반적인 컴파일 단계 시나리오는 Level 0에서 Level 3로 점프하는 것입니다.
Level4
이를 그림으로 보면 아래와 같습니다.
테스트 진행
-XX:+PrintCompilation flag를 사용하면 메소드가 몇 레벨의 어떤 컴파일러로 컴파일 되었는지 확인할 수 있습니다.
아래의 코드를 통해 정말로 위의 그림처럼 동작하는지 살펴보겠습니다.
public class main {
public static void main(String[] args) {
List list;
for (int i=0; i<100_000; i++) {
if (i<50_000) list = new ArrayList();
else list = new LinkedList();
list.clear();
}
}
}실행 결과
Time ID Level Method
88 18 3 java.util.ArrayList::clear (39 bytes)
89 19 3 java.util.ArrayList::<init> (12 bytes)처음에는 list 변수를 ArrayList로 선언하고 초기화하는 작업에 C1의 Level 3 컴파일이 사용되어졌습니다.
Time ID Level Method
92 21 4 java.util.ArrayList::clear (39 bytes)
93 22 4 java.util.ArrayList::<init> (12 bytes)몇 초 후 해당 메서드들이 반복적인 호출로 인해 컴파일 임계점을 돌파하게 되었고(C1 → C2), 그 결과 C2의 Level 4 컴파일이 사용되어졌습니다.
Time ID Level Method
94 19 3 java.util.ArrayList::<init> (12 bytes) made not entrant
95 18 3 java.util.ArrayList::clear (39 bytes) made not entranti가 50_000을 넘어서 list가 LinkedList를 할당받게 되자 기존의 ArrayList로 할당하는 최적화된 코드가 틀리게 되었습니다. 그래서 다시 해당 메소드들을 Level 0 컴파일하는 Deoptimization이 수행되어졌습니다. 위 결과는 다시 Level 0 에서 Level 3으로 점프한 결과입니다.
Time ID Level Method
100 23 3 java.util.LinkedList::<init> (10 bytes)
100 25 3 java.util.LinkedList::clear (60 bytes)
101 27 4 java.util.LinkedList::<init> (10 bytes)
101 28 4 java.util.LinkedList::clear (60 bytes)list 변수가 LinkedList를 할당받은 후의 컴파일 로그입니다. 처음 ArrayList를 할당받았을 때와 같게 동작하는 것을 확인할 수 있습니다.
참조
