
A씨: 나는 나랑 비슷한 사람을 만나고 싶어요.
좋아하는 음식이나, 취미를 공유할 수 있는 그런 사람..
💬 : 좋아하는 걸 말해볼래요?
A씨: "운동 너무 좋아해요"
A씨에게 추천해줄 상대 리스트를 살펴보고, 가장 어울리는 사람을 찾아보자.
<A씨의 추천 상대>
| 이름 | 운동에 대한 본인의 생각 |
|---|---|
| B씨 | "운동 별로에요" |
| C씨 | "운동 싫어요" |
| D씨 | "운동 좋아해요" |
각각의 생각을 나타낸 텍스트만 보고 누가 가장 A씨랑 잘 어울릴지 어떻게 알 수 있을까?
A씨의 생각과 추천 상대들의 생각을 나타낸 텍스트 유사성을 측정해보면
누가 가장 적합한 상대일 지 고를 수 있을 것이다.
그렇다면, 텍스트 유사성을 측정하는 방법 중 자주 쓰이는 코사인 유사도를 통해 상대를 알아보도록 하자.
코사인 유사도
지난 수업에서 배운 TF-IDF나 BOW(Bag of Words)등과 같이 단어를 벡터화 할 수 있는 표현 방법에 대해
코사인 유사도를 이용하면 문서의 유사도를 구하는 게 가능해진다.
What is it?
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여
구할 수 있는 두 벡터의 유사도를 의미한다.
쉽게 말해 두 벡터가 얼마나 유사한 방향을 가르키고 있는 지!
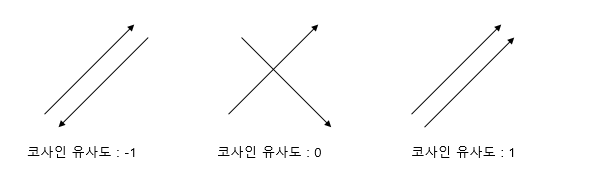
코사인 유사도는 -1에서 1사이의 값을 가지고, 다음과 같이 해석할 수 있다.
1에 가까울수록 유사도 ↑
-1에 가까울수록 유사도 ↓
0인 경우, 서로 독립적
How to calculate
두 벡터 A, B에 대해 코사인 유사도를 구하는 공식이다.
(두 벡터의 내적값을 총 벡터 크기로 정규화 해준 것!)

텍스트 매칭에 적용될 경우, A, B의 벡터로는 일반적으로 해당 문서에서의 단어 빈도가 사용된다.
A씨에게 추천해줄 상대는?
A씨와 A씨의 추천 상대들의 특징을 띄어쓰기 단위로 토큰화를 진행했다고 가정하고,
문서 단어 행렬을 만들면 이와 같다.
| 이름 | 너무 | 운동 | 좋아해요 | 별로에요 | 싫어요 |
|---|---|---|---|---|---|
| A씨 | 1 | 1 | 1 | 0 | 0 |
| B씨 | 0 | 1 | 0 | 1 | 0 |
| C씨 | 0 | 1 | 0 | 0 | 1 |
| D씨 | 0 | 1 | 1 | 0 | 0 |
Numpy를 사용해서 코사인 유사도를 계산하는 함수를 구현하고 A와 나머지 상대들의 코사인 유사도를 계산해보자.
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B) / (norm(A)*norm(B))
# 벡터 내적 / 정규화 값
doc1 = np.array([1,1,1,0,0])
doc2 = np.array([0,1,0,1,0])
doc3 = np.array([0,1,0,0,1])
doc4 = np.array([0,1,1,0,0])
print('A씨와 B씨의 적합성 :', round(cos_sim(doc1, doc2), 2))
print('A씨와 C씨의 적합성 :', round(cos_sim(doc1, doc3), 2))
print('A씨와 D씨의 적합성 :', round(cos_sim(doc1, doc4), 2))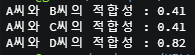
A씨의 연애 상대로는 코사인 유사도가 가장 높은 D씨가 적합!

내 연애 상대는 찾기 어려울 것 같다. 비교 대상 자체가 없어서..^^
참고
코사인 유사도
딥러닝을 이용한 자연어 처리 입문
NLP - 8. 코사인 유사도(Cosine Similarity)
