하나의 프로세스들은 CPU와 메인 메모리를 다른 프로세스들 과 공유한다.
프로세스 -> 실행중인 프로그램, OS에 의해 관리되며 독립적으로 자원을 할당받을 수 있는 단위
여러 프로세스들이 메인 메모리를 공유하게 되면?
- 프로세스들은 점점 느려짐
- 너무 많은 메모리를 요구하게 되면 일부는 실행 못할 수도
- 메모리는 손실에도 취약 -> 일부 프로세스가 다른 프로세스가 사용하고 있는 메모리에 write 하게 되면 실패할수도 있음
=>
가상 메모리(Virtual Memory): 메인 메모리를 2차 저장장치(디스크)의 캐시로 이용하는 기술
- 3개의 주요한 기능
- 메인 메모리를 디스크에 저장된 주소공간에 대한 캐시로 취급 -> 메인 메모리 내에서 활성화된 영역만 유지, 데이터를 디스크와 메모리간 필요에 따라 전송하는 방법으로 메인 메모리 효율적으로 사용!
- 각 프로세스에게 통일된 주소 공간 제공 -> 메모리 관리 효율적
- 각 프로세스의 주소 공간을 다른 프로세스에 의한 손상으로 부터 보호

우리는 왜 가상 메모리를 이해해야할까
-> 프로그램은 변수를 참조하고, 포인터 역참조,
malloc같은 동적 할당 패키지 호출할 때마다 가상 메모리와 상호작용함.
프로그램은 가상 주소를 사용하여 메모리 접근, OS는 가상 주소를 물리적 주소로 매핑하여 실제 사용하는 메모리 위치에 접근 =>
가상 메모리를 이해하는 것은 프로그램 메모리 효율적 관리하는 것에 필수!
9.1 물리 및 가상주소 방식
- cpu가 메모리에 접근하는 가장 자연스러운 방식 : 물리 주소 사용하는 것

: cpu가 load instruction (명령어를 메모리에 가져와 실행할 준비)
유효 물리 주소 생성 -> 메모리 버스를 거쳐 메인 메모리에 전달
메인 메모리는 물리 주소 4에서 시작하는 4byte 워드 선입, 이를 cpu에 돌려주고, 다시 이걸 레지스터에 저장.
초기의 pc들은 모두 물리 주소 방식 -> 현대의 프로세스들은 가상 주소 방식 사용

CPU는 가상 주소 지정으로 가상 주소(VA)를 생성해서 메인 메모리에 접근 -> 메인 메모리로 보내지기 전에 적절한 물리 주소로 변환됨
Address Translation: 가상 주소를 물리 주소로 변환하는 작업
MMU(Memory Management Unit): 논리 주소 -> 물리 주소로 변환, 메모리 보호나 캐시 관리 등 CPU가 메모리에 접근하는 것을 총체적으로 관리해주는 하드웨어

=> MMU는 메인 메모리에 저장된 참조 테이블(lookup table)을 사용해서 실행 중에 VA(가상 주소) 번역 -> 이 테이블의 내용은 OS가 관리함
9.2 주소 공간
선형 주소 공간 => 주소 공간의 정수가 연속적인 상황

- 일반적으로 OS는 하나의 프로세스에 대해 하나의 주소 공간 제공, 프로세스 내의 사용자 스레드들은 주소 공간을 공유함
32비트 시스템 -> 0 ~ 2^32 -1까지의 주소 범위 제공
64비트 시스템 -> 0 ~ 2^64 -1까지의 주소 범위 제공
9.3 캐싱 도구로서의 VM
- 페이지(Page): 가상 메모리를 일정한 크기로 나눈 블록
- 프레임(frame):물리적 메모리를 일정한 크기로 나눈 블록
가상 페이지
- unallocated: 할당되지 않은 페이지, 비할당된 블록 -> 어떠한 데이터도 가지지 않고, 디스크 상의 어떠한 공간도 차지하지 않음
- cached: 물리 메모리에 캐시되어 할당된 페이지 -> 물리 메모리의 캐시에 저장되어 더 빠르게 접근 가능한 상태
- uncached: 물리 메모리에 캐시되지 않은 할당된 페이지
n-bit 주소 공간일 때
:가상 주소 크기 N= 2^n,
물리 주소공간 M= 2^m 이라고 가정할 때,
=> 각 가상 페이지 P = 2p 바이트,
각 물리 프레임도 P= 2p 바이트의 크기를 갖는다.

VP 0, 3 -> unallocated: 실제 물리 메모리에 아직 할당되지 않음
VP 1, 4, 6 -> cached: 물리 메모리에 캐시됨.
VP 2, 5, 7 -> uncached: 가상 페이지는 할당되었지만 물리 메모리에 캐시되지는 않았음.
9.3.1 DRAM 캐시의 구성


RAM(Random access memory) - 휘발성 저장 장치
-> 영구적이지 않음. 전원을 끄면 모든 메모리는 소멸됨
SRAM(Static RAM): 정적 램
: 가만히 냅두면 내용이 소멸/변화하지 않는 안정적인 메모리
DRAM(Dynamic RAM)
: 시간이 흐르면 자연스럽게 메모리가 변함 -> 데이터 소멸을 막기 위해 일정 주기로 데이터 재활성화
용어 정의)
SRAM 캐쉬 - L1, L2, L3 캐시 메모리
DRAM 캐시 - 가상 페이지를 메인 메모리로 캐싱하는 VM 시스템 캐시.
SRAM 캐시: CPU와 메인 메모리 사이의 캐시 - L1, L2, L3
DRAM 캐시: 가상 페이지를 메모리에 캐싱하는 VM 시스템의 캐시
DRAM이 SRAM 보다 최소 10배 느리고, 디스크는 DRAM보다 약 100,000배 느리다.
-> DRAM 캐시의 미스는 SRAM캐시 의미스에 비하면 매우 비쌈 => DRAM 캐시가 미스 => 디스크에서 데이터 처리 => 처리 비용이 높고 오래 걸리는 작업
: DRAM 캐시는 가상 페이지를 메인 메모리의 물리적 위치와 직접 매핑이 아니라 어떤 가상 페이지든 어떤 물리 페이지에든 자유롭게 배치할 수 있는 구조
Write-through방식은 데이터가 캐시에 기록될 때마다 동시에 메인 메모리에도 기록
데이터가 캐시에 기록될 때마다 동시에 메인 메모리에도 기록Write-back: 데이터가 캐시에 기록될 때 즉시 메인 메모리에 업데이트 되지 않고 캐시 내에서만 유지 - 캐시 블록이 교체될 때만 해당 블록이 메인 메모리에 기록
디스크 큰 접근 시간 => DRAM은 항상 write-back 사용
9.3.2 페이지 테이블
page table: 가상페이지를 물리 페이지로 매핑하는 테이블

페이지 테이블 -> 페이지 테이블 엔트리(PTE)의 배열
: 페이지 테이블의 각각의 행
-> valid bit, N비트의 주소 필드로 구성
보호 비트, 프레임 번호, 참조 비트, 수정 비트
-
유효 비트(valid bit) : 해당 페이지 접근 가능 여부
: 페이지가 메모리에 배치되어 있다면 유효 비트 1, 아니면 0
-> 유효 비트 0인 페이지로 접근하려고 하면 Page fault -
유효 비트가 세팅 => 주소 필드는 가상 페이지가 캐시되어 대응되는 DRAM의 물리 페이지의 시작을 나타냄.
-
유효 비트가 세팅되지 않았다면 => NULL 주소는 가상페이지가 아직 할당되지 않았음을 나타냄.

9.9 동적 메모리 할당(Dynamic Memory Allocation)
동적 메모리 할당기 = 힙 메모리의 관리자, 동적 할당을 수행

프로세스에 대해서 커널은 힙의 꼭대기를 가리키는 변수 brk를 사용
- 프로세스의 virtual memory address space
Stack Segment: 아래 방향으로 확장
Heap Segment: 위 방향으로 확장
uninitialized data: 초기화되지 않은 데이터 영역(.bss)
initialized data: Data segment (.data)
Program text=> program text
할당기 -> 다양한 크기의 블록의 집합으로 힙을 관리함
-> 각 블록은 allocateod or free인 가상 메모리 묶음
- allocated: remains allocated until it is freed explicitly by the applicatior or implicitly by the memory allcoator itself
- free: 명시적으로 할당할 때까지 Free
9.9.4 단편화
- 내부 단편화(internal fragmentation): 할당된 블록이 데이터 보다 더 클 때 => 다시 말해 할당된 블록이 좀 남을 때
: 간단하게 측정 가능. 할당된 블록과 해당 payload 사이의 크기 차이의 합으로 계산하면 됨.
- 외부 단편화(external fragmentation): 할당 요청을 만족시킬 수 있는 메모리 공간(empty)이 전체적으로 합쳤을 때는 충분한 크기 존재 But
이 요청을 처리할 수 있는 단일한 free block은 없는 경우
: 내부 단편화 보다 측정하기 어려움. 이전의 요청 패턴과 미래의 요청 패턴에도 영향을 받기 때문~
-> attempt to maintain small numbers of larger free blocks rather than large numbers of smaller free blocks.
free block 관리하는 방법
1. implicit list
2. explicit list
3. segregated free list(분리 가용 리스트)
4. blocks sorted by size

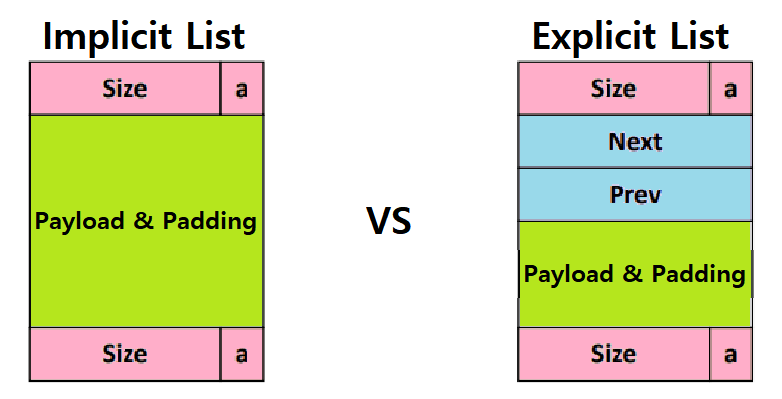
implicit free list 묵시적 가용 리스트


a one-word header , the payload, and possibly some additional padding
header : block size(header와 추가적인 패딩 포함) 와 블록이 allocated인지 free인지 인코딩
payload, 데이터
padding(optional)

메모리 할당 정책 (first fit, next fit, best fit)
first fit: 처음부터 검색해서 크기가 맞는 첫번째 free 블록 선택
장점) 리스트의 마지막에 가장 큰 free 블록들을 남겨두는 경향.
단점) 리스트의 앞 부분에 작은 free 블록들을 남겨두는 경향이 있어서 큰 블록을 찾는 경우 검색 시간이 늘어남.next fit
: first fit과 비슷하지만 검색을 리스트의 처음에서 시작하는 대신, 이전 검색이 종료된 지점에서 검색 시작.
=> first fit보다 매우 빠른 속도 가지지만 최악의 메모리 이용도best fit
: 모든 가용 블록을 검사하며 크기가 맞는 가장 작은 블록 선택 => 일반적으로 first fit, next fit 보다 더 좋은 메모리 이용도
but 힙을 완전히 다 검색해야 한다는 단점
-> 이를 개선한 것이 segregated free list

false fragmentation, 오류 단편화
: 할당기가 할당한 블록 반환할 때
새롭게 반환하는 블록에
인접한 다른 free block이 있을 수 있다.
이때의 인접한 free block들은 오류단편화 유발 가능

각가 3 word의 데이터를 갖는 2개의 인접한 블록
-> 나중에 4 word 요청하면 2개의 가용 블록 전체크기는 충분히 크지만 실패하게 됨
이를 해결하려면?
연결(coalescing)이라는 과정으로 인접 가용 블록들 통합해야함!
즉시 연결(Immediate coalescing): 할당기는 블록이 반환될 때마다 인접 블록 통합
지연 연결(deferred coalescing): 일정 시간 후 free block 들을 연결하기 위해 기다림
-> 할당기는 일부 할당 요청 실패할 때까지 연결 지연할 수 있음, 그 후에 전체 힙을 검색해서 모든 Free block을 연결할 수 있다.
9.9.11 경계 태그로 연결하기

각 블록의 끝에 경계 태그 footer 추가.
footer 는 헤더의 복제본. 각 블록에 이런 footer가 포함되어 있다면, 할당기는 항상 현재 블록의 시작 위치와 이전 블록의 상태를 확인해서 이전 블록의 시작 위치를 확인할 수 있음.
4가지 case
- 이전과 다음 블록 둘 다 allocated
- 이전 블록은 allocated, 다음 블록은 free
- 이전 블록은 free, 다음 블록은 allocated
- 이전과 다음 블록은 둘 다 free


9.9.13 명시적 가용 리스트, explicit free list

블록 할당 시간이 전체 힙 블록의 수에 비례 -> implicit free list는 범용 할당기에는 적합하지 않다.

free block들을 일종의 명시적 자료구조로 구성.
=> 이중 연결 free list: pred, succ포인터를 포함
=> first fit 할당 시간을 전체 블록 수에 비례하는 것에서 free blocks 수에 비례하는 것으로 줄일 수 있다.

새로운 Free block을 어디에 끼워넣을 것인가?
- LIFO(Last-in First-out, 후입선출)
: 새로운 free block들을 free 리스트의 시작 부분에 삽입
굉장히 간단하고 수행 속도가 빠름.
단편화가 주소 순으로 관리하는 방식보다 심하다고 함




- 리스트를 주소 순으로 관리
addr(prev) < addr(curr) < addr(next)
Newly freed block을 Free list에 삽입할 때 항상 address order에 맞게 정렬해서 삽입
-> 상대적으로 LIFO 방식보다 수행 속도가 느림
단편화가 LIFO 방식보다 덜하다는 장점
단점) Free block들이 헤더와 필요한 경우 Footer까지 포함할 수 잇는 충분한 크기여야 함. -> 더 큰 최소 블록 크기가 필요하며 내부 단편화의 가능성이 커짐
9.9.14 분리 가용 리스트(Segregated Free List)

Segregated list allocator: 각 클래스의 블록크기별 자체적인 free list 갖고 있음. 작은 크기의 경우 각각 별도의 클래스를 가지는 경우도 있음.
크기의 range를 하나의 클래스로 두기도 함.
큰 크기의 경우, 2의 거듭 제곱 크기마다 하나의 클래스가 존재하게 나눌 수도 있다.
[1], [2], [3], [4], ... , [1024], [1025], ... , [2048 ~ 4095], [4096 ~ 8192] ...] 버디 시스템(Buddy System)
메모리 블록을 작은 조각으로 나누어서 관리. 각 블록들은 고정된 크기, 크기는 2의 거듭제곱으로 설정 -> 예) 4byte, 8byte, 16byte ...
장점):빠른 검색과 병합단점): 블록 크기가 2의 거듭 제곱 -> 내부 단편화 유발 가능.

DMA (Direct Memory Access)
: 직접 메모리 접근 -> CPU의 개입 없이 I/O 장치와 기억 장치 사이의 데이터를 전송하는 접근 방식
-> CPU의 부담을 줄이고 데이터 전송의 효율성을 높일 수 있다.
CPU 대신 DMA Controller가 데이터 전송을 관리해서 CPU가 다른 작업에 할당될 수 있음

