네트워크
문대경 교수님 강의 정리
network: 개체(점) 관계를 선으로 표시
컴퓨터를 랜선으로 -> 컴퓨터망 (computer network)
Internet -> 점들을 선으로 연결한 덩어리 간의 연결
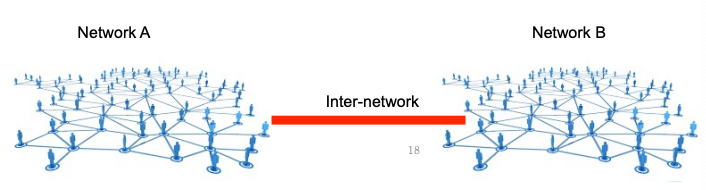
네트워크가 인터넷이 아니라. 네트워크 사이를 연결한 것을 인터넷이라고 하는 것임.=> The Internet
연결되지 않은 고립된 네트워크도 있음 (예시: 회사 내부망)
protocol?
- 약속, 규약. 의사소통을 위해 맞춰야 하는 것
- 컴퓨터 내부에서 또는 컴퓨터 사이에서 데이터의 교환 방식을 정하는 규칙 체계
IP(Internet Protocol)
: 네트워크를 연결하는 프로토콜
- 어떤 물리적 연결 기술이든 IP만 구현하면 다양한 서비스(소프트웨어)를 돌릴 수 있음.
- 어떤 서비스(소프트웨어)든 IP로만 구현하면 다양한 물리적 연결 기술로된 네트워크에서 동작
계층화(Layering)의 장점
- 단순화
: 각 계층은 자기가 제공할 기능만 생각하면 됨.
: 각 계층은 자기 바로 아래 계층을 어떻게 쓰는지만 알면 됨. - 문제 해결 편의성
: 문제가 있는 계층만 디버깅하면 됨
: 각 계층이 단순하기 때문에 문제 해결도 쉬움 - 진화의 편의성
: 각 계층은 바로 위 계층에 알려준 어떻게 쓰는지만 유지하면 됨.
: 그 안에서 자유롭게 기능 개선/추가 할 수 있음
계층화(Layering)의 단점
- 잠재적 비효율성
: 각 계층을 넘나드는 것이 비효율적일 수도.
: 바로 아래 계층이 아니라 아래 아래 계층처럼 계층을 건너 뛰어야될 때 쉽지 않음.
: 어떤 계층을 건드리면 그것을 사용하는 그 위의 모든 계층이 영향 받음.

OSI reference model
-> 실제 구현으로 존재하는게 아님. 대신 우리가 계층 구조를 만들 때 기준이 되니까 Reference model


-
Port 정보(in TCP segment)
어떤 포트 번호를 써야하는지 어떻게 알 수 있는가? -> 포트 번호는 정해놓고 씀. -
IP 정보(in IP datagram, IP packet)
어떤 IP를 써야하는지는 어떻게 알 수 있는가?
-> 정해진 IP 사용 or 서버의 이름
서버의 이름에서 IP 알아내기
- the Internet은 이름이 아닌 IP 주소로 통신.
DNS(Domain Name System): 도메인을 IP 네트워크에서 찾아갈 수 있는 IP로 변환해줌.
DNS Server: DNS를 운영하는 서버.
서버 이름과 IP 매칭을 기억하는 저장소. 서버이름으로 IP를 물어보면 대답해주는 역할.
DNS Name Resolution: 서버의 이름으로 IP를 알아내는 행동


DNS Caching
- DNS resolution은 iterative한 작업
- root -> com -> naver.com -> www.naver.com
문제점: root와 top-level domain(TLD)를 담당하는 서버는 엄청난 부하를 받음. Resolution까지 많은 시간이 걸림
=> DNS record는 빈번히 바뀌는 정보가 아니라 caching에 적합 => high scalability, low latency(지연 시간 감소, 서버 부하 감소 -> 높은 확장성)
DNS에 Private IP를 기재해도 되는가?
- 다음 IP 주소는 private IP 영역임
-10.0.0.0 ~ 10.255.255.255
-172.16.0.0 ~ 172.31.255.255
-192.168.0.0 ~ 192.168.255.255- Private IP는 누구나 내부 목적으로 쓸 수 있음
-> 내부에서 쓰는 것이니까 중복 가능. 외부 목적으로는 이 IP를 쓸 수 없음. 인터넷 상의 라우터는 public IP만 취급함.


서비스에서 호스트 이름 사용 vs. IP 사용
- 호스트 이름 사용
- 장점: 클라이언트 수정 없이 서버 IP의 주소 교체 가능. (IP resolve: 호스트 이름 -> IP 주소 변환)
DNS Round-Robin(RR)가능: 여러 IP를 하나의 이름에 맵핑해서 로드 밸런싱 - 단점: Resolve에 많은 시간이 소요. DNS 서버가 응답하지 않는 경우 서비스 장애 발생 가능
- 장점: 클라이언트 수정 없이 서버 IP의 주소 교체 가능. (IP resolve: 호스트 이름 -> IP 주소 변환)
- IP 사용시
-
장점: DNS에 대한 의존성 없음(DNS 장애에 영향 x). DNS resolve에 걸리는 시간 없음
-
단점:
서버가 항상 같은 IP 주소 가져야함. -> IP 변경시 클라이언트 패치 필요.
고정된 IP만 사용할 경우 로드 밸런싱 어려움. 클라이언트에 여러 IP를 넣어두고 Round Robin할 수도 있으나 역시 클라이언트 패치 필요.클서버의 IP 주소가 변경되면, 클라이언트에 배포된 IP 주소 목록도 업데이트되어야함. 관리의 복잡성을 증가, 클라이언트의 배포 및 업데이트에 추가 작업 필요
-
IP에서 MAC 알아내기 => ARP(Address Resolution Protocol)

ARP: 송신자는 목적지의 mac 주소가 필요. 물리 주소 요청을 위한 ARP 요청 패킷을 broadcast로 전송(목적지의 물리 주소를 모르기 때문에 모두에게 요청)


-> 해당되는 수신자는 자신의 IP주소와 MAC 주소 모두 넣어 응답 패킷을 유니 캐스트로 전송.
broadcast, unicast, multicast
Broadcast: 로컬 랜에 붙어있는 모든 장비들에게 보내는 통신

Gateway: 네트워크 간의 입출입을 위한 관문

접속할 서버가 다른 네트워크에 있다면?
-> Gateway에 던지고 맡긴다.

Gateway는 어떻게 A -> B로 보내는 선택을 하는가?
Routing: 길찾기: 내가 어떤 선택 가능한 경로들을 가지고 있는가?
데이터 전송의 본질적인 부분이 아닌 컨트롤 영역(control plane)Forwarding: 전송하기: 선택 가능한 경로 중 하나를 골라서 보냄.
데이터 전송의 본질적인 영역(Data plane)
목적지에 따라 골라서 보내기 때문에 switching이라고도 함.

- Latency(Network delay)
: 송신자가 보낸 데이터가 얼마만에 수신자에게 도달하는가?- Jitter
: Latency의 변화 정도
-> Latency data points간의 차이에 대한 평균값으로 계산
Interactive한 서비스 ->
latency: 반응이 늦게 온다는 느낌, Jitter -> 자꾸 튄다는 느낌을 줄 수 있음.
Switch
네트워크에서 스위치: 트래픽의 방향을 전환하는 것
-> 네트워크 스위치에서의 판단 근거 :해당 계층의 Header
그리고 그 계층의 숫자를 붙여서L Number 스위치라고 부름
-> 스위치는 기능을 의미하며 꼭 물리적인 장치를 뜻하지는 않는다.

-
ethernet frame의 목적지 정보에 따라 출력 포트를 선택해서 트래픽 전달 =>
L2 스위치 -
: IP packet의 목적지 정보에 따라 출력 포트를 선택하는 장비. 같은 목적지라도 해당 패킷의 출처(송신자)가 사내/사외인지에 따라 다시 출력 포트 조정 =>
L3 스위치 - 라우터
=> 방화벽 장비, 침입 탐지 시스템 IDS(Intrusion Detection System) 등이 여기에 해당 -
HTTP 요청은 이를 처리하는 동등한 역할의 서버를 여러 대 운용한다 (pooling 이라고 하고, HTTP server pool 이 있다라고 한다) 한 서버만 과부하가 걸리는 것을 막기 위해서 이 앞단에 pool 내 서버들에 round-robin 방식으로 분산해주는 장비가 있다. 이는 크게 봐서 뭐라고 부를 수 있을까?
=>L7 스위치
참고)
L4 Load balancer

L7 Load balancer

IP packet

Data link layer의 Ethernet frame -> 오류를 걸러낼 수 있다.
=> CRC(Cyclic Redundancy Check) - FCS(Frame Check Sequence)
헤더 구조를 봤을 떄 최대 보낼 수 있는 길이? -> 최대 길이가 정해져 있음(일반적으로 최대 데이터는 1500 bytes. 그걸 넘으면 버려지므로 상위 계층에서 쪼개서 보내야함)

Network layer의 IP packet(Datagram)의 최대 길이는?
total length = 16 bit -> header 포함해서 64kB
64KB 보다 더 큰 데이터를 보내려면? -> 상위 계층에서 64KB 단위로 쪼개서 보내야함.
Ethernet에서 데이터의 최대가 1500 byte라고 했는데 어떻게 64KB까지 담을 수 있을까?
IP packet 하나가 여러 Ethernet frame 으로 쪼개진다. (=fragmentation)
-> Ethernet에서는 데이터 부분의 최대 크기 1500바이트로 제한. =>MTU(Maximum Transmission Unit): 네트워크를 통해 한 번에 전송할 수 있는 데이터의 최대 크기
-> IP 패킷의 최대 길이는 64KB - 이더넷의 MTU 보다 훨씬 큰 값.
=> (Fragmentation): IP 패킷은 필요한 경우 여러 개의 이더넷 프레임으로 분할되어 전송됨. 큰 데이터 패킷을 네트워크의 MTU에 맞게 작은 조각들로 나누는 과정.IP는 에러를 검출할 수 있을까? -> 있다. header checksum
IP는 왜 header의 오류만 체크하는가?
TTL-> 라우터들이 packet을 전달할 때 TTL 값이 1씩 감소한다. TTL이 0이 되면 라우터는 이 packet을 버린다.IP는 전송을 보장하지는 않음.
header에 관련된 필드 없음



Transport Layer : UDP datagram

- IP와 마찬가지로 datagram 이름 사용
-> IP와 구분하기 위해 User Datagram - port 제공, checksum 계산하는 것 외에는 특별한 기능 없음.
-> L3 (network layer)인 IP의 기능을 L4(transport layer)에서 그대로 가져다 쓰기 위해 만들어진 프로토콜이기 때문 - 독자적으로 쪼개고 재결합하는 기능 제공 x -> IP에 의존
IP와 마찬가지로 best effort(전달만 하는 최선의 서비스)
IP -> 신뢰성 없는/비 연결형
- 패킷이 잘 전달되는지 보장x -> IP는 목적지까지 데이터를 잘 전달하기 위한 행위만 함. 정보가 도착할 것이라는 약속 x.
- IP는 데이터 주고받을 때 주소 지정, 해당 주소까지 어떻게 데이터를 전달할지 경로 지정하는 프로토콜
-> 데이터가 제대로 도착하는지를 체크하는 것은 전송 계층 TCP의 몫
Transport Layer: TCP Segment

1. 데이터가 연속적인 것 같은 환상을 지원한다(stream)
2. 받았는지 안받았는지 체크한다.
3. 수신자의 여력을 체크한다.
- TCP의 sequence 번호(ACK 번호)는 전송되는 데이터를 byte 단위로 트래킹한다.
- IP 패킷이 헤더 포함 64KB까지이므로 TCP는 전송하는 데이터 양에 따라 IP packet 여러 개로 쪼개서 전송한다.
- 수신 측에서는 여러 IP에 걸쳐 있는 TCP Segment를 sequence 번호를 이용해 결합해서 복원
- 이때문에 TCP는 하나씩 끊겨서 전송하는 IP위에서 마치 data가 연속적
- TCP 특정 상대방을 가정하고 전송한 data의 byte 단위 sequence 번호, 어디까지 수신했는지 byte 단위의 ack 번호를 관리한다.
- 통신 양 끝단(end-point)의 state를 관리하기 때문에, TCP는 stateful하고 connection 기반.
TCP의 전송 제어가 신경 쓰는 것
수신자의 여력 (버퍼크기)
=> TCP header 중Window Size필드중간에 거쳐가는 게이트웨이(라우터)들의 여력 (버퍼크기)
=> 받았는지 여부(=TCP header 중 SEQ/ACK 필드)
SEQ(Sequence Number): 해당 세그먼트가 전송 순서 어디에 위치하는지. 데이터가 올바른 순서로 재조립되는 것 보장
ACK(Acknowledge Number): 수신자가 다음에 받기를 기대하는 세그먼트의 SEQ 번호. 수신자가 정상적으로 데이터를 받았음을 알림. -> 데이터손실이 있었는지 확인, 필요한 경우 재전송 요청.
TCP Window Size
- 상대방에게 자신이 얼마나 큰 데이터를 한 번에 받을 수 있는지 advertise
- advertise된 window size 단위로 데이터가 전송되는건 아님. 혼잡 제어 알고리즘에 따른 window 크기와 비교해서 둘 중 작은 사이즈로 데이터 전송
TCP 혼잡 제어 (Congestion Control)
- 수신자는 데이터를 받으면 송신자에게
다음에 보낼 SEQ를 의미하는 ACK전송 - 송신자는 한번에 보낼 수 있는 데이터 양만큼 보내고
ACK기다림 - 이때
ACK를 받을 때마다 한번에 보낼 수 있는 데이터 양 증가시킴 - 그러다가
ACK가 누락되거나 순서가 뒤집혀 오면 혼잡이라고 판단하고 1) 한번에 보낼 수 있는 데이터 크기를 리셋하고 2) 이전 보낸 데이터를 재전송함 congestion window: 한번에 보낼 수 있는 데이터 크기


TCP로 100B를 보내려고 한다. 몇 개의 IP패킷으로 갈까?
-> Congestion window 크기가 1B인 상태에서는 1B + 2B + 4B + 8B + ... 이렇게 여러개로 쪼개서 갈 것.
그러나 window 가 100B 이상인 경우는 한번에 갈 것.
UDP vs. TCP
- UDP: 누락 되어도 상관없고 가급적 빨리 전송해야 되는 것
: 일반적으로 interactive한 audio, video 등
: 누락되는 것을 대비해서 각각의 datagram에 충분한 데이터를 넣는다.
ㄱ래서 앞의 것이 누락되어도 뒤의 것을 받고 복구할 수 있게끔. - TCP: 누락 되면 안되는 데이터를 안정적으로 전송해야 되는 것
: file 전송, 인증 처리 등
- TCP는 패킷 유실을 경험하면 네트워크 과부하로 판단.
-> congestion window를 줄이고 전송 트래픽 줄임- 그러나 UDP는 과부하를 신경쓰지 않고 TCP가 양보한 대역폭 차지

TCP
전송 속도를 서서히 올린다.
재전송을 제공한다.
혼잡 제어를 통해 트래픽 양보한다.
위의 특성들 때문에 전송 속도는 진동한다. - jitter
end-to-end의 state를 관리하므로 연결 기반
속도 상관없이 안정적인 통신에 적합UDP
IP와 마찬가지로 best-effort
안정성이 희생되더라도 빠른 통신
end-to-end로 관리되는 state가 없으므로 연결 기반
