4.4 BSD Scheduler?
- MLFQ를 기반으로 프로세스의 우선순위를 동적으로 조정한다.
I/O 작업을 많이 수행하는 쓰레드는 빠른 응답시간이 필요하지만 CPU는 거의 필요하지 않는다.
but compute-bound trheads는 반대로 많은 CPU 시간이 필요하지만 빠른 응답 시간을 요구하지는 않는다.
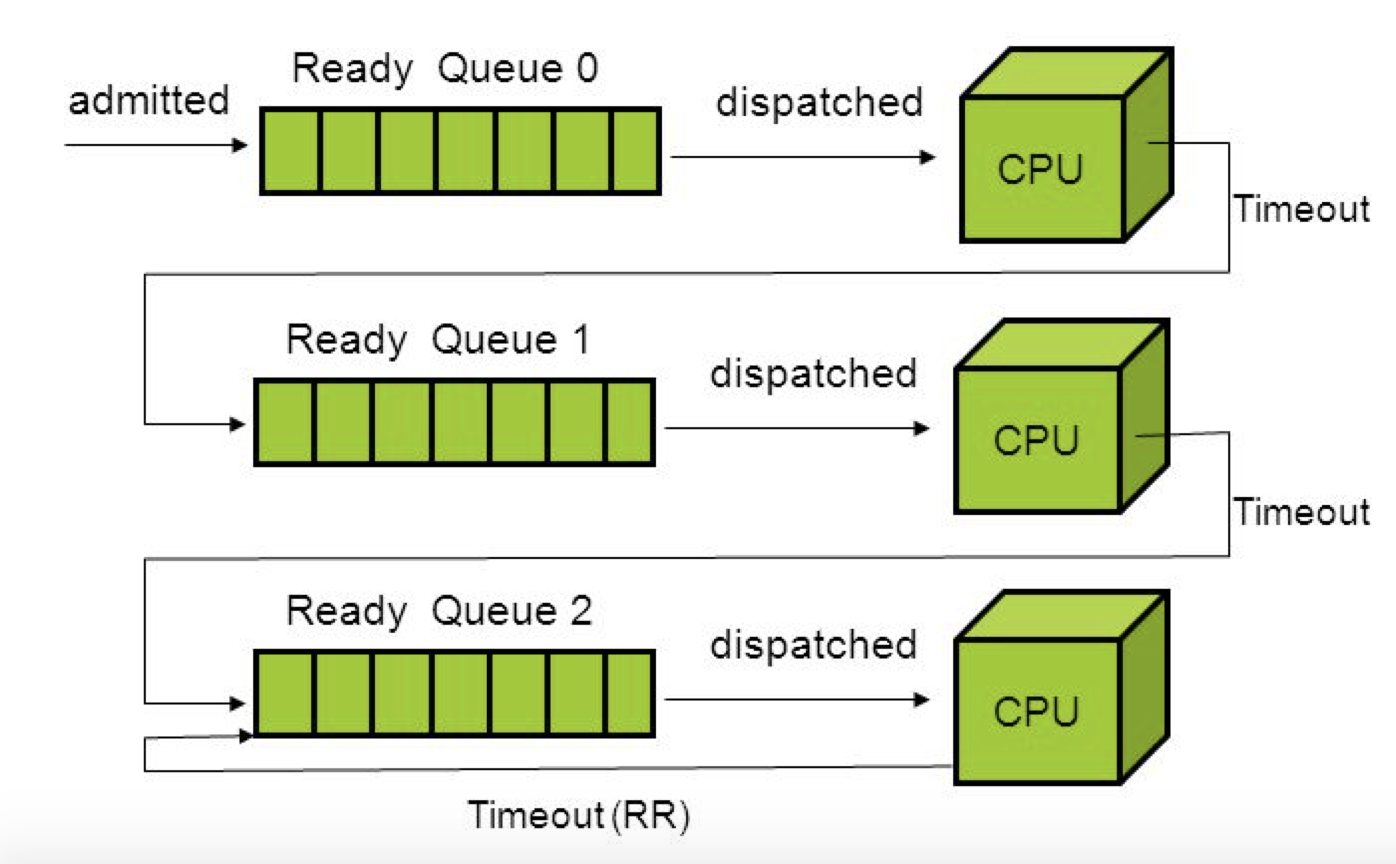
CPU를 많이 사용하는 프로세스는 점점 낮은 우선순위 큐로 이동한다.
반면 인터랙티브한 성격을 가진 프로세스는 높은 우선순위를 유지한다.
이때 일정 시간이 지나면, 우선순위가 낮아진 프로세스의 우선순위를 다시 높여주는 방식으로 기아 현상을 방지하게 설정해준다.
pintos project의 mlfqs goal은?
실제로 Multi-level의 여러개의 큐들을 사용해서 구현하기 보다
일단 프로세스의 우선순위를 실시간으로 조정하는 로직을 사용해서 프로세스의 우선순위를 동적으로 조정하는 방식의 스케줄러 구현해보자!
이전에 구현했던 priority donation 함수들은 mlfqs 과제에서 사용하지 않는다.
MLFQ => 프로세스의 우선순위를 동적으로 조정한다. 별도로 Priority donation 기법을 사용해서 우선순위 역전 문제를 해결할 필요가 없다.
nice value
niceness of a thread
⇒ from -20 to 20
쓰레드가 친절하다는 것은 그 쓰레드가 자신의 CPU 사용시간을 다른 쓰레드에게 양보할 용의가 있다는 것이다.
- Nice(0) : initial value, 우선순위에 영향을 주지 않음.
- Nice(positive): 쓰레드의 우선순위를 낮춤. nice 값이 클수록 쓰레드는 더 많은 cpu시간을 다른 쓰레드에게 양보하겠다는 것. ⇒ 우선순위는 낮아짐
- Nice(negative): 쓰레드의 우선순위를 높임. nice값이 낮을수록, 쓰레드는 더 적은 CPU 시간을 양보하겠다는 것 ⇒ 우선순위는 높아짐. - 쓰레드가 더 높은 우선순위 → 더 급한 작업 처리에 용이
우선순위 계산 매커니즘
개념이 너무 많아서 초반에 많이 힘들었는데 일단 쉽게 쉽게 큰 그림을 그려보도록 하자.
먼저 mlfqs의 핵심은 우선순위를 동적으로 조정하는 매커니즘이 있다는 것이다.
그럼 어떻게 우선순위를 조정하겠다는 말인가?
recent_cpu와 niceness를 고려해서 우선순위를 동적으로 조절한다는 것이 큰 틀이다.
-
여기서 recent_cpu는 프로세스가 최근에 사용한 cpu 시간이다. =>
- recent_cpu/4
=> 최근에 cpu를 많이 사용해줬었더라면 우선순위를 낮춰준다.(batch 작업)
반면에 cpu를 적게 사용한 프로세스의 경우에는 우선순위를 높여준다(I/O bound) -
nice는 사용자가 프로세스의 우선순위를 조정할 수 있도록 하는 값이다.
=>- nice * 2: 사용자가 nice 값을 증가시키면 프로세스의 우선순위는 낮아지고, 감소시키면 우선순위는 커진다.
Priority

그렇다면 이렇게 설계한 이유는?
최근에 CPU를 많이 사용한 프로세스의 우선순위를 낮춤으로써, 모든 프로세스가 공정하게 CPU 시간을 나눠 가질 수 있게끔 한다. 그리고 I/O 바운드 프로세스나 인터랙티브 프로세스가 더 높은 우선순위를 가지게 되면, 사용자 경험이 향상될 것이다.
또한 nice 값을 통해서 사용자가 더 중요한작업에 더 높은 우선순위도 부여할 수 있다. 사용자의 요구에 맞게 우선순위를 조정할 수 있는 것이다!
recent_cpu

최근에 얼마나 많은 CPU time을 사용했는가
timer interrupt마다 1씩 증가, 매 1초 마다 재 계산한다.
decay

시스템 부하가 낮을 때(low load_avg): decay 값은 1에 가까워진다. -> 최근에 cpu를 많이 사용한 프로세스의 recent_cpu 값이 더 크게 반영될 수 있다.시스템 부하가 높을 때(high load_avg): decay 값은 1보다 작아진다.
-> recent_cpu값의 증가율이 감소한다. => 시스템이 바쁠 때 새로운 프로세스가 시스템에 과도한 부담을 주지 않도록 하기 위함
decay를 쓰는 이유
decay값을 통해 시스템 부하가 높을 떄 자주 cpu를 요구하는 프로세스의 recent_cpu 증가율을 줄임
-> 해당 프로세스가 시스템을 독점하는 것을 방지함!
- nice도 포함하여 사용자가 설정한 우선순위도 반영
: nice 값이 높은 프로세스는 recent_cpu 값이 더 빨리 증가하여 우선순위가 낮아지게 되고, nice 값이 낮은 프로세스는 recent_cpu 값이 더 천천히 증가하여 우선순위가 높아진다.
load_avg

- 최근 1분 동안 수행 가능한 프로세스의 평균 개수, exponentially weighted moving average 사용
=>이전의 load_avg와 현재 ready_threads를 가중평균하여 계산 ready_threads: ready_list에 있는 쓰레드들과 실행 중인 쓰레드의 개수를 합한 값(idle thread 제외)
=> idle thread는 실제 작업을 수행하고 있지 않고 있기 때문에 시스템 부하 계산에서 제외!
소수점 연산 구현하기
Priority, nice, ready_thread 값은 정수인 반면, recent_cpu, load_avg 값은 실수이다!
- pintos는 커널에서 부동소수점 연산을 지원하지 않는다.
- recent_cpu와 load_avg 값 계산을 위해서 소수점 연산이 필요하다.
- 17.14 fixed-point number representation을 이용하여 소수점 연산을 구현한다.
총 32 비트
오른쪽 14비트 => 소숫점
그 다음 17 비트 => 정수
제일 왼쪽 1비트 - 부호 비트 (0이면 양수, 1이면 음수)

- 14 bit => 소수 부분을 위해 사용 => 실제 값을 표현하기 위해 2^14를 곱해준다.
- 숫자 1 = 16384
- 숫자 0.5 = 0.5 * 2^14 = 8192
- 숫자 2.75 = 2 + 0.5 + 0.25 = 22^14 + 0.52^14 + 0.25*2^14 = 45056


궁금해서 찾아본 부분)
부동 소수점 연산 지원을 하는 OS인 경우
: 부동소수점 레지스터의 상태를 저장하고 복원하는 과정이 성능 저하 유발 가능 but 시스템의 복잡성이 증가
아닌 경우
: 커널이 부동 소수점 레지스터의 상태를 저장하고 복원하는 작업을 피함으로써 성능 저하를 방지할 수 있음.
그러나 부동 소수점 연산이 필요한 작업을 커널 모드에서 처리할 수 없어서 사용자 모드로 전환하는 등의 추가 작업이 필요함. 그리고 표현할 수 있는 숫자의 범위가 제한적이다.
코드로 구현하기!
- 매 4번째 틱마다 모든 쓰레드의 priority 재계산
- 매 틱마다 실행 중인 recent_cpu 값 1증가
- 매 초마다 모든 쓰레드의 recent_cpu, load_avg 업데이트
=> 일단 모든 쓰레드 순회를 위해 all_list라는 새로운 리스트를 만들어줬다!
static struct list all_list ; nice, recent_cpu는 각 쓰레드별로 존재하는 고유 값이고,
load_avg는 시스템에 하나의 값으로 존재한다.
- nice: 특정 프로세스/쓰레드에게 부여할 수 있는 우선순위 수정 값 -> 각 쓰레드가 다 다르게 작업하게끔, 각각의 중요도가 다를 수 있어서 각 쓰레드마다 고유하게 설정됨
- recent_cpu: 특정 쓰레드가 최근에 얼마나 많은 cpu 시간을 사용했는지 -> 쓰레드의 CPU 사용량이라 고유함
- load_avg: 시스템 전체의 평균 부하량 -> 시스템에 하나의 값
struct thread
int nice;
int recent_cpu;
struct list_elem all_elem; all_list를 관리하기 위해 thread 구조체 안에 all_elem 필드를 추가해주었다. 추후 all_list 관리해주기 위함이다.
all_list는 struct list 타입으로 선언되고, 시스템 내의 생성된 모든 쓰레드의 all_elem 필드를 통해 연결된 연결리스트다!
=> 특정 쓰레드의 all_elem 필드를 사용하여 list_remove로 연결을 끊게되면 all_list에서 제거된다!!
init_thread()
새로 추가된 필드를 초기화하는 코드를 추가해준다.
static void
init_thread (struct thread *t, const char *name, int priority) {
ASSERT (t != NULL);
ASSERT (PRI_MIN <= priority && priority <= PRI_MAX);
ASSERT (name != NULL);
memset (t, 0, sizeof *t);
t->status = THREAD_BLOCKED;
strlcpy (t->name, name, sizeof t->name);
t->tf.rsp = (uint64_t) t + PGSIZE - sizeof (void *);
t->priority = priority;
t->magic = THREAD_MAGIC;
list_push_back(&all_list, &t->all_elem);
/*priority scheduling을 위한 initialization*/
t->init_priority = priority;
t->wait_on_lock = NULL;
list_init(&t->donations);
/*advanced scheduler*/
t->nice = NICE_DEFAULT; /*initial value = 0*/
t->recent_cpu = RECENT_CPU_DEFAULT; /*init thread의 초기값은 0*/
}
list_push_back(&all_list, &t->all_elem);함수도 추가해준다.
처음에 thread_init()함수에 추가해줘야 하는지 init_thread함수에 이를 추가해줘야 하는지 헷갈렸었다.
그런데 init_thread()함수의 경우 쓰레드를 초기화하는 과정에서 호출되고 이때 새롭게 초기화된 쓰레드가
all_list에 추가되어야 하므로 init_thread()함수에 추가해주었다.
thread_init()
load_avg = LOAD_AVG_DEFAULT 선언 코드는
thread_init()함수에 추가해주었다. 시스템이 처음 부팅될 떄 호출되어 전체 쓰레드 시스템을 초기화하는 역할을 하기 때문에load_avg도 여기서 초기화 해준다.
void
thread_init (void) {
ASSERT (intr_get_level () == INTR_OFF);
/* Reload the temporal gdt for the kernel
* This gdt does not include the user context.
* The kernel will rebuild the gdt with user context, in gdt_init (). */
struct desc_ptr gdt_ds = {
.size = sizeof (gdt) - 1,
.address = (uint64_t) gdt
};
lgdt (&gdt_ds);
/* Init the globla thread context */
lock_init (&tid_lock);
list_init (&ready_list);
list_init (&destruction_req);
list_init(&sleep_list);
list_init(&all_list);
load_avg = LOAD_AVG_DEFAULT;
/* Set up a thread structure for the running thread. */
initial_thread = running_thread ();
init_thread (initial_thread, "main", PRI_DEFAULT);
initial_thread->status = THREAD_RUNNING;
initial_thread->tid = allocate_tid ();
}do_schedule()
static void
do_schedule(int status) {
ASSERT (intr_get_level () == INTR_OFF);
ASSERT (thread_current()->status == THREAD_RUNNING);
while (!list_empty (&destruction_req)) {
struct thread *victim =
list_entry (list_pop_front (&destruction_req), struct thread, elem);
list_remove(&victim->all_elem);
palloc_free_page(victim);
}
thread_current ()->status = status;
schedule ();
}나도 처음에는 thread_exit부분에서
list_remove(&t->all_elem); 함수를 추가해주었었는데 테스트 통과가 계속 안됐었다.
thread_exit()은 현재 실행 중인 쓰레드를 종료시키는 함수이다. 이 함수가 호출될 때 현재 쓰레드는 아직 실행 중이다, all_elem을 바로 제거하게 되면 스케줄러가 이 쓰레드를 참조할 때 문제가 생길 수 있을 것이다.
반면 do_schedule함수는 쓰레드가 완전히 종료된 후에 리스트에서 제거한다.
mlfqs_priority()
mlfqs에서 쓰레드의 priority를 계산하고 업데이트 해주는 함수!
void mlfqs_priority (struct thread *t ){
if (t == idle_thread){
return;
}
int temp = PRI_MAX + fp_to_int(divide_mixed(t->recent_cpu, -4));
temp = temp + t->nice * (-2);
t->priority = temp;
}현재 쓰레드가 idle_thread라면 우선순위 계산이 필요없으니 return해준다.
mlfqs_recent_cpu()
void mlfqs_recent_cpu (struct thread *t) {
if (t == idle_thread){
return;
}
//load_avg : 고정 소수점 연산 사용
// t->recent_cpu = (2*(load_avg))/(2*(load_avg)+1)*(t->recent_cpu) + t->nice;
int decay = mlfqs_calc_decay();
t->recent_cpu = add_mixed( mult_fp(decay, t->recent_cpu), t->nice);
}mlfqs_calc_decay()
int mlfqs_calc_decay(void) {
int decay_val;
decay_val = divide_fp(mult_mixed(load_avg, 2), add_mixed(mult_mixed(load_avg, 2), 1));
return decay_val;
}mlfqs_load_avg()
최근 1분 동안 수행 가능한 프로세스의 평균 개수
load_avg = (59/60) * load_avg + (1/60)*ready_threads
void mlfqs_load_avg(void) {
int left, right;
/*주의: 현재 쓰레드가 idle thread일수도 */
int ready_threads;
ready_threads = list_size(&ready_list);
if (thread_current() != idle_thread){
ready_threads = list_size(&ready_list) + 1;
}
left = divide_fp(int_to_fp(59), int_to_fp(60));
left = mult_fp(left, load_avg);
right = divide_fp(int_to_fp(1), int_to_fp(60));
right = mult_mixed(right, ready_threads);
load_avg = add_fp(left, right);
}
현재 실행중인 스레드가 idle 스레드가 아니라면, 실행 대기중인 스레드의 수에 1을 추가한다.
현재 실행중인 스레드도 곧 실행 가능한 스레드로 간주하여 계산에 포함시킨 것!
mlfqs_increase_recent_cpu()
void mlfqs_increase_recent_cpu (void) {
struct thread *cur = thread_current();
if (cur == idle_thread){
return;
}
cur->recent_cpu = add_mixed(cur->recent_cpu, 1);
}
recent_cpu 값 1 증가시켜준다.
mlfqs_recalc
모든 쓰레드의 recent_cpu와 priority를 재계산해주는 함수를 따로 만들어주었다.
/*모든 쓰레드의 recent_cpu 값 재계산*/
void mlfqs_recalc_recent_cpu(void) {
struct list_elem *e;
for (e = list_begin(&all_list); e != list_end(&all_list); e = list_next(e)){
struct thread *t = list_entry(e, struct thread, all_elem);
mlfqs_recent_cpu(t);
}
}
/*모든 쓰레드의 Priority 값 재계산*/
void mlfqs_recalc_priority(void) {
struct list_elem *e;
struct thread *t;
for (e = list_begin(&all_list); e != list_end(&all_list); e = list_next(e)){
struct thread *t = list_entry(e, struct thread, all_elem);
mlfqs_priority(t);
}
}
thread_set_priority()
void
thread_set_priority (int new_priority) {
if (thread_mlfqs) {
return;
}
thread_current() -> init_priority = new_priority;
revoke_priority();
preempt_thread(); //현재 쓰레드의 우선순위를 변경한다면 ready_list에서 우선순위가 가장 높은 쓰레드와 비교해서 선점할지 말지 여부를 결정해야 함.
}mlfqs 스케줄러에서는 우선순위를 임의로 변경할 수 없다! 그래서 조건문으로 바로 return 시켜주는 코드를 추가해준다.
thread_set_nice()
void
thread_set_nice (int nice UNUSED) {
enum intr_level old_level;
old_level = intr_disable();
struct thread *cur = thread_current();
cur->nice = nice;
mlfqs_priority(cur);
preempt_thread();
intr_set_level(old_level);
}현재 쓰레드의 nice의 값을 설정해주는 함수다. 그리고 우선순위를 재계산해준다.
-> 그리고 우선순위가 재계산되었으니 우선순위에 따라 우선순위가 높은 쓰레드가 실행될 수 있도록 preempt_thread()함수를 호출해준다.
여기서 왜 인터럽트를 비활성화해주는가?
해당 작업 중에 인터럽트를 비활성화를 해주는데 쓰레드가 다른 cpu나 인터럽트 핸들러에 의해 중단될 경우 데이터의 일관성이 깨질 수 있기 때문이다.-> 예를 들어 현재 쓰레드의 Nice값을 바꿔주고 나서 우선순위를 재계산해주기 전에 인터럽트가 발생하여 다른 쓰레드로 전환된다면 새로운 우선순위가 계산되지 못할 수도 있다. 또한 우선순위가 제대로 반영되지 않아서 잘못된 쓰레드가 스케줄러에 의해 선택될 수 있게 된다.
thread_get_nice()
int
thread_get_nice (void) {
enum intr_level old_level;
int nice_val;
old_level = intr_disable();
struct thread *cur = thread_current();
nice_val = cur->nice;
intr_set_level(old_level);
return nice_val;
}
thread_get_load_avg()
시스템의 현재 load_avg에 100을 곱해서 return 해주는 함수
/* Returns 100 times the system load average. */
int
thread_get_load_avg (void) {
int load_avg_val;
enum intr_level old_level;
old_level = intr_disable();
load_avg_val = fp_to_int_round(mult_mixed(load_avg, 100));
// printf("load_avg_val: %d\n", load_avg_val);
intr_set_level(old_level);
return load_avg_val;
}thread_get_recent_cpu()
int
thread_get_recent_cpu (void) {
enum intr_level old_level;
old_level = intr_disable();
struct thread *cur = thread_current();
int temp_recent_cpu = fp_to_int_round(mult_mixed(cur->recent_cpu, 100));
intr_set_level(old_level);
return temp_recent_cpu;
}
자세히는 모르겠지만 왜 100을 곱하는가에 대한 의문
고정 소수점 표기법에서는 실제 값에 스케일링 팩터(여기서는 100)를 곱하여 소수점 아래 값을 정수 부분으로 옮긴다. 이렇게 스케일링 함으로써, 소수점 아래 값의 손실 없이 정밀한 계산이 가능해진다고 한다.
timer_interrupt()
: mlfqs 스케줄러라면
매 틱마다 recent_cpu를 1증가시키고,
1초마다 Load_avg, 모든 쓰레드의 recent_cpu 재계산.
4 tick마다 쓰레드의 priority 재계산해준다.
static void
timer_interrupt (struct intr_frame *args UNUSED) {
ticks++;
thread_tick ();
//mlfqs 스케줄러일 때
if (thread_mlfqs){
mlfqs_increase_recent_cpu(); //매 틱마다 recent_cpu + 1 증가
//TIMER_FREQ = 1초 동안의 틱 수
//ticks % TIMER_FREQ == 0 => 정확히 1초마다 True
if (ticks % TIMER_FREQ == 0) {
mlfqs_load_avg();
mlfqs_recalc_recent_cpu();
}
if (ticks % 4 == 0){
mlfqs_recalc_priority();
}
}
thread_awake(ticks);
}lock_release()
void
lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock)); //lock을 해제하기 전에 현재 쓰레드가 Lock의 소유자인지 확인
lock->holder = NULL; //lock의 소유자를 NULL로
if(!thread_mlfqs){
remove_with_lock(lock);
revoke_priority();
}
sema_up (&lock->semaphore); /*세마포어의 값 1증가. ->
만약 세마포어의 값이 0이하였다면, 하나 이상의 쓰레드가 lock을 얻기 위해 대기 중이었음.
-> 하나의 쓰레드가 깨어나서 lock을 얻을 수 있게 됨 */
}mlfqs 스케줄러를 사용하면 priority donation을 하지 않도록 코드를 수정해줘야 한다.
lock_acquire()
void
lock_acquire (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context ());
//Lock을 획득하는 동작은 인터럽트 컨텍스트에서 수행되면 안됨. 일반적으로 사용자 레벨의 코드에서만 수행되어야 한다.
ASSERT (!lock_held_by_current_thread (lock)); //현재 쓰레드가 이미 해당 락을 보유하고 있지 않는지 확인
//락을 이미 보유한 쓰레드가 다시 시도할 경우 데드락 발생시킬 수 있음.
if (thread_mlfqs) {
sema_down(&lock->semaphore);
lock->holder = thread_current();
return ;
}
//해당 Lock의 holder가 이미 존재한다면(다른 쓰레드가 Lock을 보유하고 있다면)
if (lock->holder != NULL) {
thread_current()->wait_on_lock = lock;
// list_push_back(&lock->holder->donations, &thread_current()->d_elem);
//현재 쓰레드를 락을 보유한 쓰레드의 donations 리스트에 우선순위에 따라 삽입
list_insert_ordered(&lock->holder->donations, &(thread_current()->d_elem),compare_donation_priority, NULL);
donate_priority(); // priority donation: lock을 보유한 쓰레드의 우선순위를 현재 쓰레드의 우선순위로 설정
}
sema_down (&lock->semaphore);
//lock에 연결된 세마포어의 값이 0보다 크면 1감소, 그렇지 않으면 대기 상태로 전환
//lock을 획득하기 위해 대기하거나 즉시 획득하는 역할 -> Lock 획득시 1--(공유 자원에 대한 접근 권한 획득했음을 의미)
//현재 쓰레드가 lock을 획득하게 되면,
thread_current()->wait_on_lock = NULL; //현재 쓰레드가 더 이상 이 lock을 기다리고 있지 않음 표시
lock->holder = thread_current(); //lock의 소유자는 현재 쓰레드로 설정
}마찬가지로 mlfqs 스케줄러일 경우에는 priority donation 코드가 실행되지 않도록 그냥 return 하게끔 코드를 수정한다.
회고🫡
생각보다 디버깅에 애를 먹었던 advanced scheduler 구현
고정 소수점과 부동 소수점 연산을 처음 배워서 개념 이해부터 어려웠다.
하지만 priority scheduling의 경우 우선순위 순으로 스케줄링하지만 advanced scheduler의 경우 우선순위를 동적으로 조정함으로써 기아현상을 방지할 수 있게끔 매커니즘을 짤 수 있다는 것이 확실히 더 좋은 것 같다.
내가 구현한 핀토스 과제에서는 진짜 Multi-level queues로 스케줄링을 하고 있지는 않지만 비슷하게 스케줄할 수 있게끔 구현된 것이다.
실제 MLFQ는 여러개의 큐로 작업들을 관리한다고 해서 기회가 되면 공부해보고 싶다!
이상 프로젝트 1 정리 끝
이제부터는 프로젝트 2 User Program이다.
더 어렵다는데,,, 1.5주 또 화이팅해보자..
정신줄 꽉 잡아야지 ㅎㅎ.. 🫠🫠🫠
