230509 알고리즘/자료구조 - 파이썬 강의 2차시
not 연산자
print(not 0) # True print(not "") # True print(not "python") # False
- %2를 하면 값은 0 혹은 1 즉 False or True이다.
if number % 2 === 0 : 이런식으로 사용할 수도 있겠지만 if not number % 2 이렇게 쓸 수도 있다.
- not
""일 경우 -> not False 이므로 True이다.
단축평가
- 인덱스 값에 해당하는 값이 없다면 인덱스 에러가 뜨게 된다.
그러나 단축 평가가 일어난다면?a = [1,2,3] if len(a) < 3 and a[4] != 4: ### 뒤의 조건은 실행되지도 않음 - 단축 평가 print("if 통과") else: print("else 통과")이렇게 되면 if 절에서 단축평가가 일어나기 때문에 인덱스 에러가 뜨지 않고 바로 넘어가게 된다!
다중 조건문
조건이 여러 개인 경우 -> if 문 안에 또 다른 if 문 사용하기 or elif 사용하기
if age >= 30:
print("30대입니다.")
else:
if age >= 20:
print("20대입니다.")
else:
print("미성년자입니다.")
--------------------------------
**elif의 필요성
if age >= 30:
print("30대입니다.")
elif age >= 20:
print("20대입니다.")
else:
print("미성년자입니다.")- elif의 경우 여러개 사용 가능
컨테이너 자료형
-
여러 개의 데이터를 한 곳에 저장할 수 있는 자료형
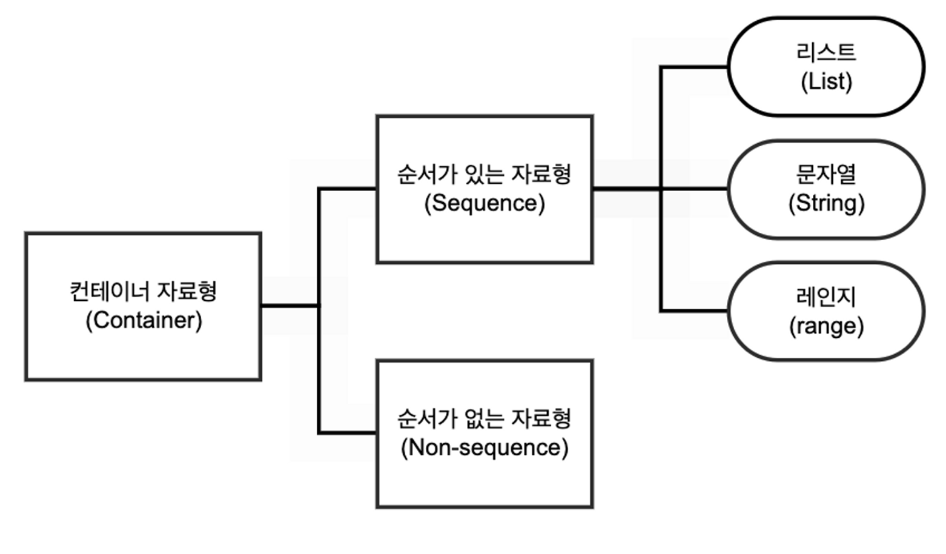
-
순서가 있는 컨테이너(Sequence): 데이터를 순서대로 저장 -> 인덱싱 가능
순서가 있다는 것, 인덱싱이 가능하다는 것과 정렬되었다는 것은 엄연히 다르다. -
순서가 없는 컨테이너(Non-sequence): 데이터를 무작위 순서로 저장
리스트
- 대괄호 [] 사용, 콤마로 구분
- 다양한 자료형 저장 가능
- 0개 이상의 데이터를 순서 있게 저장하는 컨테이너 : 빈 컨테이너도 존재 가능
- 빈 리스트 [] 는 list()와 같음
len(): 리스트의 길이
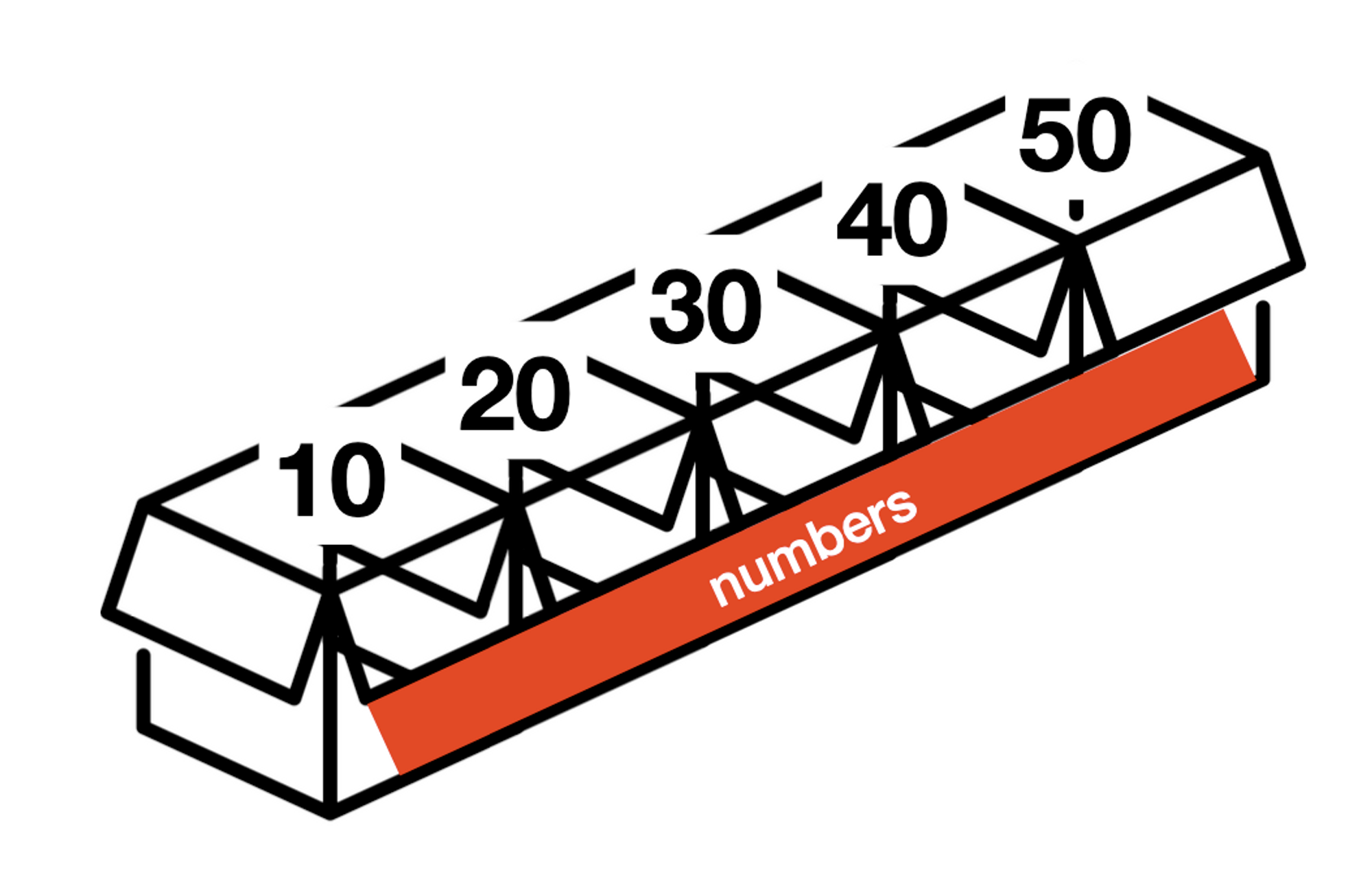
리스트의 연산
- 덧셈
- 리스트를 합칠 수 있다.
a = [1, 2] b = [3, 4] c = a + b # [1, 2, 3, 4]
- 곱셈
b = [0] c = b*5 c # [0, 0, 0, 0, 0]2차원 리스트
=> 현실생활에서의 다양한 데이터가 표현 가능하다.
- 그냥 하나의 행렬(Matrix)라고 생각하면 쉽다!
# 만약 8에 접근하고 싶다면 matrix = [[3, 7, 9], [4, 2, 6], [8, 1, 5]] print(matrix[2][0]) # 8
- 그래프의 노드들 간 간선을 2차원 리스트로 구조화할 수 있다.
=> 인접행렬을 떠올리면 쉽다.
- 간선에 방향이 있다면 비대칭 인접 행렬
- 간선에 방향이 없으면 대칭 인접 행렬, 전치행렬
슬라이싱(slicing)
슬라이싱(Slicing): 특정 구간을 나누어 자르는 것
원본에는 변화를 주지 않는다.
왼쪽은 포함, 오른쪽은 포함x
리스트[start:end:step]의 형식
start: 리스트를 자를 범위의 시작 인덱스end: 리스트를 자를 범위의 끝 인덱스 (이때 end 인덱스에 해당하는 원소는 포함되지 않는다.)step: 리스트를 자를 간격 (음수는 반대 방향을 의미)a = [10, 20, 30, 40, 50] # 0 1 2 3 4 # -5 -4 -3 -2 -1 --- a[1:4:2] # [20, 40] a[-5:-2:2] # [10, 30] a[1:4:-1] # [] a[4:1:-1] # [50, 40, 30] a[::-1] # [50, 40, 30, 20, 10]
shallow copy 얕은 복사 / deep copy 깊은 복사
Deep Copy: '실제 값'을 새로운 메모리 공간에 복사하는 것
Shallow Copy: '주소 값'을 복사 - 실제 값이 아니라 참고하고 있는 주소값을 복사b= a[:] # [10, 20, 30, 40, 50]이렇게 전체를 도려내면 리스트를 copy할 수 있는데, 이는 얕은 복사이다.
id(a), id(b)를 확인해보면 값이 달라 깊은 복사인 것처럼 보인다.
2차원 리스트 슬라이싱을 확인해보면 슬라이싱[:]통해 copy하는 것은 얕은 복사임을 알 수 있다.a = [[1,2,3],[4,5,6]] b = a[:] print(b) #[[1,2,3],[4,5,6]] a[0][0] = 100을 하게 되면 a와 b
[[100, 2, 3], [4, 5, 6]]로 둘다 바뀐다. 얕은 복사인 것이다.
깊은 복사를 하려면?
1) import 하는 방법 import copy copy.deepcopy()2) slicing을 이용해서 deep copy를 해야한다면? a = [[1,2],[3,4]] b = [] for i in a: b.append(i[:]) -------------------- a # [[1, 2], [3, 4]] b # [[1, 2], [3, 4]] a[[0][0]] = 99 a # [99, [3, 4]] b # [[1, 2], [3, 4]]
인덱싱
- 파이썬에서 Iterable
: 한 번에 하나의 member를 반환할 수 있는 객체,
: for 문을 통해순회할 수 있는 모든 객체
=> 리스트, 튜플 등등등- 파이썬에서 mutable/ immutable
mutable: 객체 수정 가능한 타입 - int, float, str, tuple
immutable: 객체 수정 불가능 - list, dict
리스트는 리스트[인덱스] = 새로운 원소의 형식으로 기존 원소 값을 수정할 수 있다.
.append()
: append()는 pop()과 달리 return값이 없다.
따라서 None 값이 반환된다.
sorting
- sort와 sorted는 다르다!
sort: 원본 자체를 정렬 - id 값 변하지 않음
sorted: 정렬한 새로운 리스트를 만듦 - id 값이 변함a.sort(reverse=True) # 내림차순
2차원 리스트는 어떻게 sort할 것인가?
- sort: 문자열도 숫자열처럼 sort가 가능하다.
- lexicographic sorting(사전식 정렬): 사전처럼 앞의 순서대로 정렬된다.
그렇다면 특정 기준을 잡고 sorting을 해야할 경우에는?
- key 옵션과 익명 함수 lambda를 활용하면 된다.
nums = [3, 5, 1, 4, 2] nums.sort() print(nums) # [1, 2, 3, 4, 5] => 원본 자체를 정렬 # 만약 역순으로 정렬하고 싶은 경우? # nums.sort(key= lambda x: -x) => 함수를 빠르게 쓰고 싶어서 lambda 활용 첫번째값 기준(사전식 정렬)이 아니라, 다르게 sorting 하고 싶다면? a.sort(key=lambda x:(x[1],x[2])) # 2번째, 3번째 값을 기준으로 정렬
해야할 것이 점점 많아진다... ㅇ<-<
그래도 아는 만큼 보일테니
열심히
블로그에 기록을 남겨놔야지~ ㅎㅇㅌ.
