1. 세그멘테이션과 페이징
세그멘테이션과 페이징을 설명하기 전 먼저 고전적이고 기초적인 가상주소할당방식을 이야기해야 한다.
동적 재배치
동적 재배치 dynamic relocation 또는 베이스와 바운드 base and bound라고 불리는 방식은 베이스 레지스터와 바운드 레지스터를 이용해서 가상 주소공간을 물리 메모리에 배치한다.[^정적재배치]
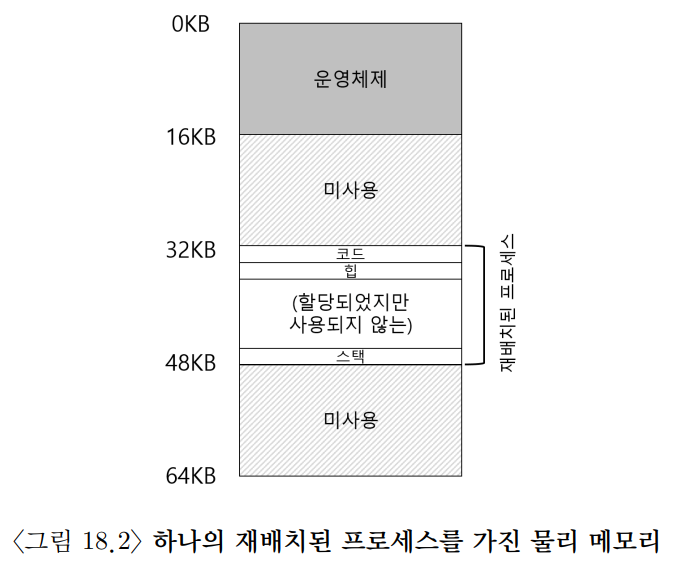
64KB의 물리 메모리, 16KB의 가상 주소공간을 가진 16비트 시스템을 가정했을 때의 동적 재배치는 위 그림과 같이 표현된다.
이 때 베이스 레지스터는 재배치된 프로세스가 존재하는 시작부분의 주소인 0x8000을 값으로 갖는다. 따라서 프로세스마다 다른 값을 갖는다.[^예시1]
0x0000가상 주소를 갖는 코드세그먼트의 시작 부분은 0x8000인 물리주소로 번역된다.
가상주소와 물리주소는 (가상주소)+(베이스 레지스터 값) = (물리주소)의 관계를 가진다.
바운드 레지스터에는 프로세스 블록의 경계가 저장되어 있어 다른 영역을 침범하였는지를 검사할 때 사용한다.
필요한 하드웨어 기능
- 베이스/바운드 레지스터
- 동적 재배치를 구현하기 위해서는 베이스/바운드 레지스터 값을 변경(문맥 전환 시)하는 명령어가 필요하고, 이 명령어는 커널 모드에서만 호출할 수 있어야 한다.
필요한 운영체제 기능
- 물리 메모리 상의 가용 프레임 리스트를 만들고 관리해야 한다.
- 프로세스가 종료될 때 메모리를 모두 회수하도록 해야 한다.
- 문맥 교환 시 베이스/바운드 레지스터의 값을 저장하고 복원해야 한다.
- 범위를 벗어난 메모리 접근 등의 상황에 실행할 예외 핸들러를 제공해야 한다.
[^정적재배치]: 정적 재배치는 실행파일을 로드할 때 코드 내의 모든 주소를 물리 메모리 주소로 바꾸어 놓는다. 간단하지만 보호기능이 없고 실행된 이후에는 주소 공간을 옮기는 것이 불가능해진다는 단점이 있다.
[^예시1]: 만약 그림에서 48KB 구간에 새로운 프로세스가 배치된다면 그 프로세스의 베이스 레지스터 값은 0xc000일 것이다.
세그멘테이션
동적 재배치 방식은 간단하지만 내부 단편화가 항상 발생한다.
즉, 프로세스마다 가상주소공간의 크기만큼을 물리메모리에 할당하기 때문에, 프로세스에서 사용하지 않는 공간(특히 스택과 힙 사이 공간)이 낭비된다.
세그멘테이션은 물리 메모리의 이용률과 내부 단편화를 방지하기 위해 동적 재배치를 일반화한 방식이다.
세그멘트 segment는 가상 메모리를 구성하는 논리적 단위로, 크게 코드영역, 힙영역, 스택영역으로 볼 수 있다.
세그멘테이션은 세그멘트마다 베이스와 바운드 쌍을 갖는다. 따라서 운영체제는 각 세그멘트를 물리 메모리의 다른 위치들에 배치할 수 있다.
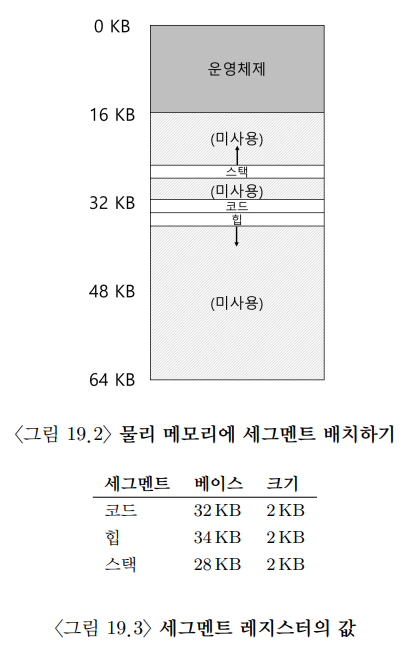
그러면 그림과 같이 미사용 영역이 큰 주소 공간(희소 주소 공간 sparse address space)도 스택과 힙을 각기 다른 위치에 배치하여 내부 단편화를 줄일 수 있다. [^3-2]
[^3-2]: segmentation fault은 세그멘트의 바운드를 벗어난 주소를 참조한 경우에 발생시키던 오류로부터 기원한 용어이다.
필요한 하드웨어 기능
- [[#필요한 하드웨어 기능|동적 재배치의 기능]]
- 세그멘트 별 베이스/바운드 레지스터를 가져야 한다.
필요한 운영체제 기능
- [[#필요한 운영체제 기능|동적 재배치의 기능]]
- 메모리의 빈 공간을 관리하는 알고리즘은 말록 랩에서 배웠던 것과 유사하다.
장점
- 메모리를 논리적 단위로 나누어 프로그램의 구조를 반영함.
- 세그먼트 별 보호와 공유가 용이함.
단점
- 외부 단편화 발생 가능성이 있음.
- 메모리 관리가 복잡.
페이징
세그멘테이션에서는 내부 단편화를 해결하였지만 외부 단편화의 문제가 있다.
공간을 다양한 크기의 블록들로 나누면서 가용 공간 자체가 나뉘어 가용 블록들의 합인 공간 자체는 충분하지만 할당할 블록이 존재하지 않을 수 있다.
공간을 동일한 크기의 블록들로 나누는 방식이 외부 단편화의 해결책이 될 수 있으며 이를 페이징이라고 한다.
페이징에서는 주소 공간을 논리 세그멘트로 나누지 않고 동일한 크기의 페이지로 나눈다.
주소공간을 나눈 페이지를 할당할 물리 메모리 또한 같은 크기로 나누어야 하는데 이 조각을 페이지 프레임(또는 그냥 프레임)이라고 한다.

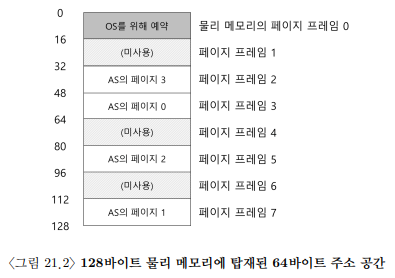
페이징은 세그멘테이션에 비해 여러 장점을 가지고 있다.
- 유연성: 물리 메모리에 할당할 때 주소 공간을 어떻게 사용하는지를 고려하지 않아도 된다.
- 단순함: 4개의 페이지를 할당해야 한다면 네 개의 빈 프레임을 찾기만 하면 된다.
필요한 하드웨어 기능
- 페이징에서는 베이스/바운드 레지스터가 따로 필요 없다.
필요한 운영체제 기능
- [[#필요한 운영체제 기능|동적 재배치의 기능]]
- 페이지의 크기는 모두 같기 때문에 복잡한 가용 페이지 관리 방식이 필요 없다.
- 물리 메모리 상의 페이지 정보를 저장하는 페이지 테이블을 관리해야한다.
장점
- 외부 단편화에서 자유로움.(페이지가 모두 같은 크기)
- 메모리 관리가 상대적으로 단순함.
단점
- 내부 단편화 발생 가능성이 있음.(페이지 내 미 사용 공간 생김)
- 페이지 테이블 관리에 추가적인 메모리(페이지 테이블)가 필요.
실제 시스템에서는

IA-32(x86)에서는 세그멘테이션과 페이징기법을 혼용해서 사용하였다.
세그멘트별로 분리된 논리주소를 선형주소로 변환하고, 선형주소를 페이징을 이용해서 물리 주소로 변환하였다.
그러나 리눅스, 윈도우 등 현대 운영체제는 세그멘트별 베이스를 0으로 설정함으로써 대체로 페이징만을 주로 사용하였다.
페이징이 더 단순한 메모리 관리가 가능하고, 페이징으로도 세그멘테이션의 메모리 보호 등을 구현할 수 있어졌기 때문이다.
또한 64비트 시스템에 이르면서 물리 메모리 공간에 여유가 생기면서 더더욱 세그멘테이션의 필요성이 작아져 x86-64에서는 세그멘테이션이 거의 비활성화 되어있다.
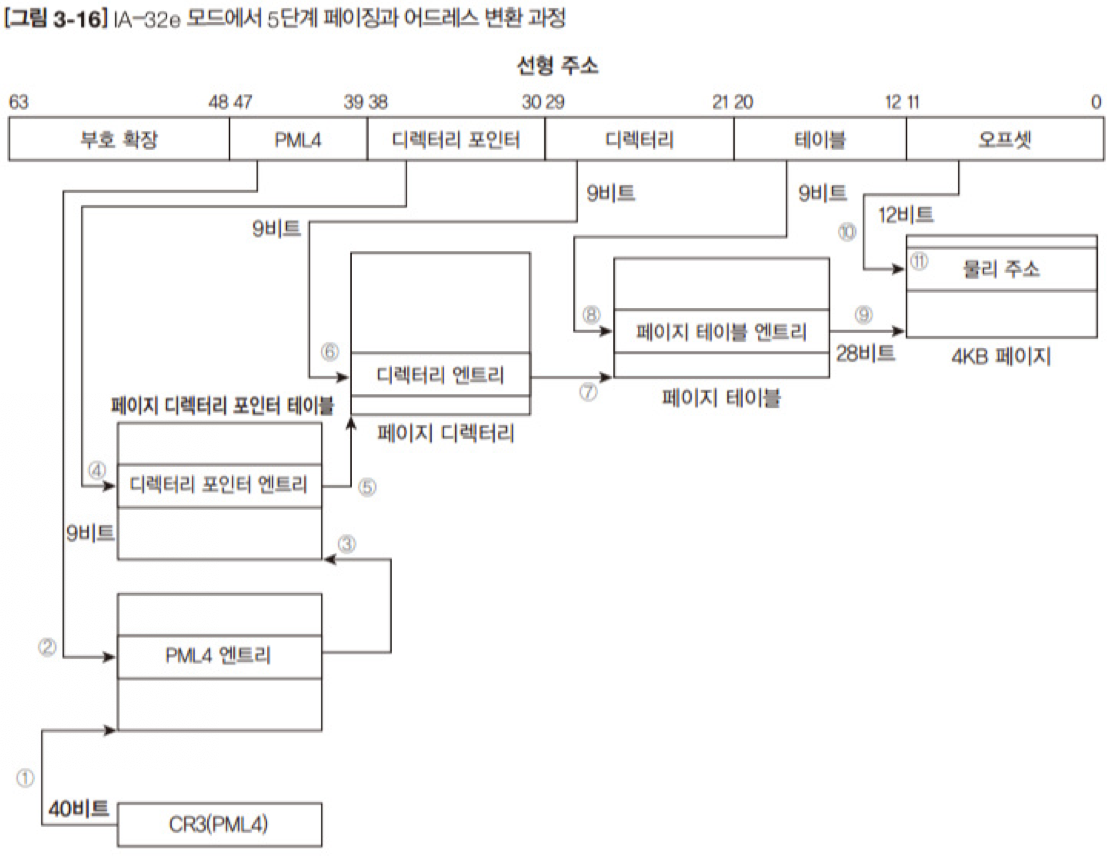
[^IA-32e][^IA-32e]: IA-32의 64비트 주소 공간 확장 모드
2. 페이지 교체 알고리즘
지금까지 핀토스에서는 모든 메모리 페이지를 물리 메모리에 할당하여 사용하였다.
하지만 실제 운영체제에서는 프로세스들이 사용하는 메모리의 합이 머신의 실제 물리 메모리 공간보다 큰 경우가 생길 수 있다.(프로세스가 하나인 경우에도 발생할 수 있다. 일반적으로 가상주소공간은 물리 메모리 크기보다 훨씬 더 크기 때문에..)
운영체제는 이런 상황에 대비하기 위해 페이지의 일부만 물리 메모리에 적재한다.
따라서 적재되지 않은 페이지에 접근해 page fault가 발생한 경우 페이지를 적재하게 되고, 필요한 경우 적재된 페이지 중 일부를 적재해제(교체)해야 할 수 있다.
이 교체할 페이지(victim 페이지)를 선택하는 알고리즘을 페이지 교체 알고리즘이라고 한다.
가장 기본적인 일부 알고리즘만 살펴보자면:
- FIFO
가장 먼저 적재된 페이지를 victim페이지로 한다.
구현이 간단하고, 한 번만 사용하는 코드의 경우 유리하다.
적재 가능한 프레임(물리 메모리에서의 블록. 가상메모리의 페이지와 거의 같은 개념)의 수가 늘어날 수록 page fault의 수가 단조적으로 감소할 것 같지만 FIFO알고리즘에서는 그렇지 않은 경우가 간혹 발생한다.
이를 Belady's Anomaly라고 부른다.
예제는 검색하면 많이 나오지만 요약하자면 victim페이지로 해제되었다가 다시 적재되면 교체 대상순위에서 밀려나므로 결과론적으로 미리 해제되었더라면 page fault가 나지 않았을 상황이 종종 있다는 것이다.(개인적으로 이게 이름이 붙을 정도로 중요한 내용인지 모르겠다.) - LRU
Least Recently Used.
마지막으로 사용한 시점이 가장 오래된 페이지를 victim페이지로 한다.
프로그램의 시간적 지역성을 이용한 방식이다.
구현은 카운터 방식(마지막 사용 시점 기록), 스택 방식(참조된 페이지를 스택에 저장)이 있다.
하지만 메모리에 접근할 때마다 카운터 또는 스택 방식으로 정보를 기록해야 하므로 오버헤드 크다는 단점이 있다.
성능을 개선하기 위한 근사 알고리즘이 많이 등장하였다. - Clock
LRU의 성능을 개선하기 위해 LRU를 근사한 알고리즘 중 하나.
참조 여부만을 표시하여 오버헤드를 줄였다.
victim페이지를 결정해야할 때에는 포인터(clock hand)가 프레임을 순회하며 결정한다.
참조 비트가 1(참조됨)인 페이지는 참조 비트를 다시 0으로 바꾸고 넘어간다.
참조 비트가 0(참조안됨)인 페이지를 발견하면 순회를 멈추고 victim 페이지로 결정한다.
다음 순회 때에는 이전 포인터의 위치에서부터 시작한다.
즉, 포인터가 한 바퀴 돌아서 다시 같은 프레임을 가리킬 때까지 한 번이라도 참조되었다면 살려놓고 그렇지 않았다면 교체하는 방식이다.
