그동안은 TIL을 쓰면서 배운 일자마다 글을 썼었다.
그런데 일자별로 쓰니까 같은 주제여도 너무 파편화 되어 앞으로는 주제마다 글을 써야겠다.
아래 내용은 TIL로 이미 올라온 CSAPP의 내용들을 하나로 합친 것으로 빠진 챕터들이 꽤 있다.
책을 내가 이해한 내용으로 적은 것들도 꽤 많으므로 오류가 있을 수 있다.
옵시디언에 작성해 둔 것을 복사해와서 벨로그에서는 표현이 다를 수 있다.
...내가 썼지만 기억 안나는 것들이 많다.
1. 컴퓨터 시스템으로의 여행
1-1. 정보는 비트와 컨텍스트로 이루어진다
여기서 비트는 2진법으로 표현된 숫자(데이터) 그 자체이다.
즉 컨텍스트 없이는 프로그램, 데이터, 네트워크 데이터, 파일, 명령어, 문자열, 숫자 모두 비트 덩어리일 뿐이라는 것이다.
이들을 구분하는 유일한 방법은 컨텍스트 뿐이다.
1-2. 프로그램은 다른 프로그램에 의해 다른 형태로 번역된다
컴파일러를 말한다.
C소스코드는
- 전처리기로 헤더파일이 삽입되고
- 컴파일러로 어셈블리어로 번역되며
- 어셈블러로 재배치가능 목적프로그램으로 번역되며(여기서부터 바이너리 파일)
- 링커에 의해 목적파일과 연결되어 최종 실행가능 목적파일이 된다.
여기서 어셈블리어는 기계어 인스트럭션의 집합
1-3. 컴파일 시스템이 어떻게 동작하는지 이해하는 것은 중요하다
- 성능 최적화를 위해
- 보안 취약점을 막기 위해
1-4. 프로세서는 메모리에 저장된 인스트럭션을 읽고 해석한다.
현재 모든 컴퓨터는 폰노이만 구조를 따른다.
폰노이만 구조에서는 변수도 프로그램도 메모리에 저장된다.
프로세서는 메모리에 저장된 명령어(인스트럭션)을 읽어 실행할 뿐이다.
1-5. 캐시가 중요하다
프로그램을 실행하면 프로그램을 메모리에 저장해야 한다.
이런 복사/읽기 작업들이 작업을 느리게 한다.(오버헤드)
그렇다고 모든 저장장치들에 비싼 SRAM을 사용할 수는 없다.
하지만 프로그램은 보통 코드와 데이터의 일부분에만 접근하기 때문에(지역성)
접근할 내용들을 미리 (작고 비싸지만)빠른 저장장치에 로드해 사용하는 것을 캐시라고 한다.
즉 캐시도 구체적인 실체라기보다는 추상화된 개념이다.
1-6. 저장장치들은 계층구조를 이룬다
1-7. 운영체제는 하드웨어를 관리한다
추상화는 복잡한 시스템에서 중요한 사항만을 강조하고, 불필요한 세부 구현을 감추어 단순화하는 것
어려운 개념인 추상화가 등장한다.
프로세서, 메인 메모리, 입출력장치들은 모두 구분 가능한 실체를 지칭한다.
프로세스, 가상메모리, 파일은 실체에 대한 추상화(된 개념이)다.
-
프로세스:
독립적으로 실행되는 프로그램의 인스턴스(인스턴스는 개념으로부터 구현된 실체를 의미한다)
프로세서, 메인 메모리, 입출력장치를 아우르는 추상화다.
실행 중인 프로그램에 대한 운영체제의(에 의한) 추상화다.
프로그램은 프로세서, 메인 메모리 등 자원을 점유하고 입출력장치들과 상호작용할 뿐, 그렇다고 이들 그 자체인 것은 아니다.
프로그램이 작업을 수행하고, 프로그램이 메모리를 차지하는 것 같지만, 현실에서는 모두 하드웨어가 한다.
자원 점유와 상호작용, 명령을 실행하고 동작하는 주체를 추상적인 개념으로 표현한 것이라고 보면 되겠다.(그런 주체가 물리적으로 실존하는 것이 아니므로)
이런 프로세스들이 모두 동시에 실행되는 것처럼 보이는 이유는 운영체제가 문맥 전환을 통해서 교차실행하기 때문이다. -
스레드:
프로세스 내부의 실행 흐름 단위
프로세스와 비슷한 개념으로 한 프로세스에서 실행되는 다른 프로그램이라고 대강 이해할 수 있다.
스레드는 동일한 프로세스 내에서 구분된다.(두 개 이상의 프로세스에 걸친 스레드는 있을 수 없다.)
같은 프로세스 내에서 코드, 데이터, 힙 영역을 공유하나 스택은 공유하지 않는다.
스택은 입출력 순서가 중요하기 때문에 반드시 순서에 따라 실행되는 단위(스레드, 프로세스)가 독립적으로 가지고 있어야 한다. -
스레드를 구분하는 이유
프로세스를 두고 스레드라는 개념을 별도로 정의한 이유는:
스레드간 문맥전환은 프로세스 간 문맥 전환보다 빠르다.(메모리와 자원을 공유하기 때문에 교체해야 하는 정보가 적다.)
데이터 공유가 용이하다. 그러므로 같은 프로세스 내에서 병렬처리가 필요할 때 유용하다. -
문맥전환이란
프로세서가 현재 실행 중인 프로세스/스레드의 상태(레지스터 값, 프로그램 카운터 등)를 저장하고, 다음에 실행할 프로세스/스레드의 상태를 복원하는 과정 -
가상메모리:
가상메모리는 각 프로세스들이 각자의 메인 메모리를 사용하고 있는 것 같은 환경을 제공하는 추상화이다.
각 프로세스는 실제 메모리의 주소를 통해 접근하지 않고 가상주소를 통해 메모리에 접근한다.
모든 프로세스가 실제로 메모리 공간을 일정부분씩 점유를 한다고 하면 메모리 공간이 매우 많이 필요할 것이다.
프로세스가 할당된 메모리 공간을 모두 사용하는 경우는 적으니 일단 가상메모리 주소로 넉넉하게 할당해주고, 실제 데이터를 운영체제가 메모리에 알맞게 정리해서 관리한다.
그래서 가상 메모리 공간의 합은 실제 메모리 공간보다 클 수 있고, 이 경우 보조 저장장치에 기록하여 관리한다.
아래 사진에서 보듯 프로세스는 메모리 공간을 유동적으로 사용한다.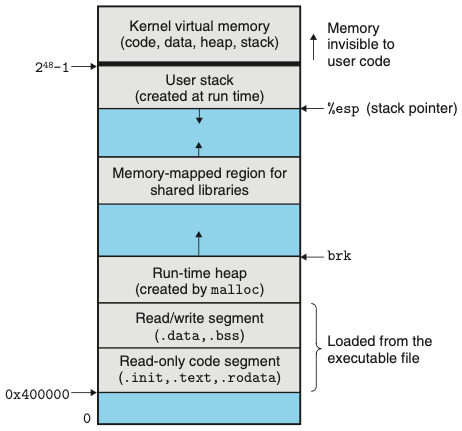
-
파일:
파일이 추상화라는 것이 잘 감이 안 오지만
디스크, 키보드, 네트워크 등 모든 입출력장치들은 파일로 모델링한다. -
시스템은 네트워크를 사용하여 다른 시스템과 통신한다
네트워크는 또 다른 입출력장치일 뿐이라고도 볼 수 있다.
2. 정보의 표현과 처리
헷갈리는 부동소수점만 정리
2-4. 부동소수점
2-4-1. 비율 이진수
이진수를 로 표기한 것.
책에서 이진소수 중 소수부가 모두 1인 수를 약식으로 , 은 음의 정수로 표기한다.
그러나 컴퓨터에서 비율 이진수로 소수를 저장하고 표현하려면 자리수에 비례한 메모리 공간이 필요해진다.
2-4-2. IEEE 부동소수점 표시
유효숫자 표시와 유사하다.
, 또는 , 는 정수
0
단일정밀도 부동소수점은 총 32비트(4바이트)로 구성되며 부호 1비트, 지수 8비트, 가수 23비트
이중정밀도 부동소수점은 총 64비트(8바이트)로 구성되며 부호 1비트, 지수 11비트, 가수 52비트(가수부가 4바이트를 넘는다.)
편의를 위해 단일정밀도 부동소수점을 기준으로 설명
2-4-2-1. 부호 표시
부호는 가 이면 양수, 이면 음수.
2-4-2-2. 지수 표시
부호와 지수를 합쳐서 부호있는 정수형처럼 2의 보수로 표현할 것 같지만 아니다.
9비트 정수형에서 은 , 은 으로 표현되지만
IEEE 부동소수점의 지수에서는 (는 지수 비트수. 이 숫자를 라고 한다.)를 으로 삼아 선형적으로 표현된다.
(는 지수표시)
단일정밀도에서 이고 은 을, 은 을, 은 을 가리킨다.
과 은 각각 과 무한대(가수가 인 경우)를 나타낸다.
이 이 아니라 과 같이 을 가리키는 이유는 가수부가 미만인 수(특히 )를 표현할 때 사용하기 위함으로 아래에서 서술한다.
이 이 아닌 무한대를 가리키는 이유는 매우 큰 수를 으로 근사할 수 밖에 없는 경우를 피하기 위해서일 듯 하다.
2-4-2-3. 가수 표시
- 지수가 인 경우(정규화 값)
가수를 가 되도록() 표시한다.
다만 비트에는 소수부만 표시한다.
가수가 인 경우 만 저장한다.(암시적 선두 1표시, hidden bit)
이런 구성은 가수표현에 1비트를 절약하여 정밀도를 높인다.
하지만 미만의 가수를 표시할 수 없다.
따라서 지수가 일 때에 다른 표시법을 사용한다. - 지수가 인 경우(비정규화 값)
가수를 가 되도록() 표시한다.
비트에는 소수부만 표시한다.
0을 표시할 수 있으나 이 경우 표현할 수 있는 최댓값은 지수가 (부동소수점에서 )인 경우이므로 지수를 로 해석하는 경우 표현할 수 없는 부분이 생긴다.
따라서 지수도 으로 해석하는 것이다. - 지수가 인 경우(특수 값)
가수가 0인 경우 무한대를 가리킨다.(부호는 에 따라 달라진다)
가수가 0이 아닌 경우 잘못 표현된 숫자(NaN)을 가리킨다.
2-4-3. 예시
-
정규화 값
1 01111110 00000100000000000000000
-
비정규화 값
0 00000000 10000000000000000000000
-
특수 값
1 11111111 00000000000000000000000
1 11111111 11100000000000000000000
2-4-4. 근사법(rounding 반올림)
소수를 근사하려는 자리수 아래가 10000...의 형태인 경우 어느 쪽 숫자로 근사할 것인지가 문제가 된다.
10진법에서 xx.xxxx50000인 경우의 문제와 동일하다.
IEEE에서는 네 가지 근사 모드를 정의한다.
1. 짝수근사법(round-to-even) 기본
짝수와 가까운 곳으로 근사하는 방법.
는 로, 도 로 근사한다.
은 으로, 도 로 근사한다.
수가 많은 경우 통계적 편향을 방지하기 위해 사용한다.
2. 영방향 근사(round toward-zero)
0과 가까운 곳으로 근사한다.
3. 하향근사(round-down)
작은 쪽으로 근사한다.
4. 상향근사(round-up)
큰 쪽으로 근사한다.
양수에서 반올림하려는 자리수만으로 처리할 수 있다는 특징을 갖는다.
일상에서 자주 사용하는 방식
2-4-5. 부동소수점 연산
책에서는 연산과정을 자세히 소개하기보다는 부동소수점 연산에 적용되지 않는 수학적 특성들만을 설명하고 있다.
기본적으로 부동소수점은 근사치로 저장되기 때문에 연산 또한 근사한 결과만 보장할 수 있는 정도의 정밀도만 갖도록 만들어졌다.
2-4-5-1. 부동소수점 덧셈()
-
교환법칙이 성립한다.
-
결합법칙은 성립하지 않는다.
인 가 존재한다.예:
round(1e10) = 0 10100000 00101010000001011111001()
round(3.14) = 0 10000000 10010001111010111000011()
3.14의 지수부를 33로 두게 되면
round(3.14) = =
이 되므로 이 된다.
반면, 이므로
-
연산에 대한 단조성을 갖는다.
이면 가 항상 성립한다. 즉, 이지만 인 경우는 존재할 수 있다.
2-4-5-2. 부동소수점 곱셈()
- 교환법칙이 성립한다.
- 항등원(1.0)을 갖는다.
- 결합법칙은 성립하지 않는다.
예:
- 덧셈에 대한 분배법칙이 성립하지 않는다.
인 가 존재한다.
예:
- 연산에 대한 단조성을 갖는다.
3. 프로그램의 기계수준 표현
x86-64에 기초해 어셈블리어를 배우고, 이것이 컴퓨터를 어떻게 조작하는지를 배운다.
어셈블리어는 ATT표기법을 따른다.
3-1. 역사적 관점
32비트 아키텍처까지 이어오던 인텔의 x86구조를 따라 만들던 AMD가 64비트 전환에서는 치고 나왔다는 그런 이야기.
고대부터 호환성을 64비트까지 끌고 오면서 역사적 관점에서만 이해가 가능한 부분도 있다는 언급도 있다.
인텔의 IA64가 어떻게 망했는지 찾아보는 것도 재미있다.
3-2. 프로그램의 인코딩
C코드는 어셈블리어를 거쳐 실행파일로 만들어진다.
3-2-1. 기계수준 코드
컴퓨터 시스템은 세부구현을 감추기 위해 여러가지 추상화를 사용하고 있다.
1. 기계수준 프로그램의 형식과 동작은 인스트럭션 집합구조(ISA. 흔히 명령어 셋, CPU 아키텍처라고 부르는)에 의해 정의된다.
2. 기계수준 프로그램(기계어 코드)이 사용하는 메모리 주소는 가상주소이다. 메모리매우 큰 바이트 배열인 것 처럼 주소를 넓게 사용하고, 운영체제가 실제 메모리에 입력과 출력을 관리한다.
어셈블리 코드는 기계어 코드와 함께 저수준 언어로 분류된다.
기계어 코드는 바이너리라 그대로 읽기에는 의미를 파악하기 힘들기 때문에, 바이너리인 기계어 코드를 문자로 구현한 것이 어셈블리 코드라고 이해할 수 있다.
3-3. 데이터의 형식
- x86-64에서 자료형의 길이 별 접미사
Byte(1byte): b
Word(2bytes): w
Double word(4bytes): l
Quad word(8bytes): q
Single precision(4bytes): s
Double precision(8bytes): l
3-4. 정보 접근하기
레지스터는 프로그램 카운터, 정수 레지스터, 조건코드 레지스터, 벡터 레지스터가 있다.
정수 레지스터의 종류:

3-4-1. 오퍼랜드 식별자
어셈블리어 명령어 대부분은 오퍼랜드(피연산자)가 필요하다.
오퍼랜드는 연산을 수행할 소스 오퍼랜드 와 결과를 저장할 목적지 오퍼랜드 가 있다.
소스 오퍼랜드로는 1. 상수, 2. 레지스터, 3. 메모리를 지정할 수 있다.
목적지 오퍼랜드로는 1. 레지스터, 2. 메모리를 지정할 수 있다.
오퍼랜드의 지정 대상에 따른 종류와 표시법:
- 즉시값(immediate)
현재 참조 중인 프로그램 데이터 자체를 지정한다.(상수를 지정한다는 뜻)
상수 앞에 $를 붙여 표시한다.- 표기법: $
- 오퍼랜드 값: (상수 자체가 오퍼랜드 값이 된다.)
- 예시: $-577, $0x1F
- 레지스터(register)
레지스터의 값을 지정한다.- 표기법:
- 오퍼랜드 값: (은 레지스터 에 담겨있는 값에 접근)
- 예시: %rax, %eax
- 유효주소(effective address)
메모리 주소를 전달하여 그 주소에 접근하는 방식.
주소를 계산하도록 할 수도 있다.- 표기법: ,
- 오퍼랜드 값: , (은 메모리 주소 에 담겨있는 값에 접근)
- 예시: 0x104, (%rax, $rdx, 4)
3-4-2. 데이터 이동 인스트럭션
3-4-2-1. MOV클래스
데이터를 복사하는 명령어인 MOV클래스에 대해 배운다.
MOV클래스는 접미사에 따라 네 개로 구성된다.
네 인스트럭션은 다른 크기의 데이터에 대해 계산한다는 점만 다르다.
MOV클래스의 종류:
- movb
- movw
- movl
- movq
- 사용 예:
movb $0xAF, %al
오퍼랜드로 레지스터를 지정하는 경우, 레지스터의 크기는 접미사가 의미하는 크기와 동일해야 한다.
x86-64에서는 메모리에서 메모리로 값을 복사할 수 없다.(두 오퍼랜드를 모두 메모리로 지정할 수 없다.)
명령어 별 예외
- movl명령어는 목적지 오퍼랜드로 레지스터를 지정하는 경우 지정된 레지스터 상위 4바이트의 값을 0으로 변경한다.
movl명령어를 제외한 나머지는 지정된 레지스터의 값만 변경한다.
예시:
%al 레지스터에 값을 쓰도록 movb명령어를 사용한 경우 %al레지스터 공간을 제외한 (동일한 레지스터 공간을 공유하는) %ax레지스터의 값은 유지된다.이렇게 설계한 이유는 32비트 호환성을 위해서라고 추측된다.
0확장을 하지 않는 경우 movl로 레지스터에 기록한 데이터는 앞 32비트만 의미가 있고 사용할 수 있다.
그로 인한 호환성 충돌의 경우는 지금은 쉽게 떠오르지 않는다.
마찬가지로 8비트, 16비트에서 확장된 x86의 역사를 생각하면 movw과 movb에는 적용되지 않는 것이 의문이지만, 어차피 소급하여 변경할 수 없었을 것이다.
x86-64는 이전과 다르게 AMD가 개발하였다는 점도 원인일 수 있을 것 같다. - movq명령어는 소스 오퍼랜드로 상수를, 목적지 오퍼랜드로 레지스터를 지정하는 경우 32비트인 2의 보수 숫자로 나타낼 수 있는 상수만을 소스 오퍼랜드로 갖는다.
- movabsq는 소스로 64비트 상수 목적지로 레지스터를 갖는 경우에 사용한다.
3-4-2-2. MOVZ, MOVS 클래스
MOV 클래스와 유사하나 소스를 확장하여 이동한다.
MOVZ 클래스의 명령어들은 목적지의 남은 바이트를 모두 0으로 채워 확장한다.
MOVS 클래스의 명령어들은 부호확장을 통해 목적지의 남은 바이트를 채워 확장한다.
뒤에 소스와 목적지의 바이트 길이 접미사를 붙여 사용한다. 목적지가 소스보다 길이가 길어야 한다.
unsigned 자료형을 확장할 때 MOVZ 클래스를 사용한다.
signed 자료형을 확장할 때 MOVS 클래스를 사용한다.
MOVZ 클래스의 종류(movzlq는 movl과 동일한 기능을 수행하므로 존재하지 않는다.)
- movzbw
- movzbl
- movzwl
- movzbq
- movzwq
MOVS 클래스의 종류
- movsbw
- movsbl
- movswl
- movsbq
- movswq
- movslq
3-4-3. 데이터 이동 예제
// C코드
void casting(char *sp, int *dp) {
*dp = (int) *sp
}
void casting2(int *sp, unsigned char *dp) {
*dp = (unsigned char) *sp
}이 코드를 어셈블리로 표현하면 다음과 같다.
(sp의 값은 %rdi에 dp의 값은 %rsi에 저장되어 있다)
casting:
movsbl (%rdi), %eax
movl %eax, (%rsi)
casting2:
movl (%rdi), %eax
movb %al, (%rsi)3-4-4. 스택 데이터의 저장과 추출(push, pop)
pushq 명령어와 popq 명령어를 사용한다.
pushq %rbp 명령어는 먼저 스택 포인터를 감소시키고 메모리에 %rbp값을 저장한다.
subq $8, %rsp
movq %rbp, (%rsp)위 코드와 완전히 동일한 작업을 수행하나 pushq %rbp 명령어가 더 인코딩 효율적이다.
popq %rax 명령어는 반대로 스택에서 값을 읽은 후 스택 포인터를 증가시킨다.
movq (%rsp), %rax
addq $8, %rsp와 동일하다.
3-7. 프로시저
프로시저는 다른 언어에서의 함수와 유사한 개념으로, 특정 작업을 수행하기 위해 작성된 코드 블록이다.
각 프로시저는 고유한 이름을 가지며, 프로그램의 다른 부분에서 호출할 수 있다.
프로그램에서 주요한 추상화이며, 함수처럼 구체적인 구현을 감춰주는 추상화 메커니즘으로도 이용한다.
3-7-1. 런타임 스택
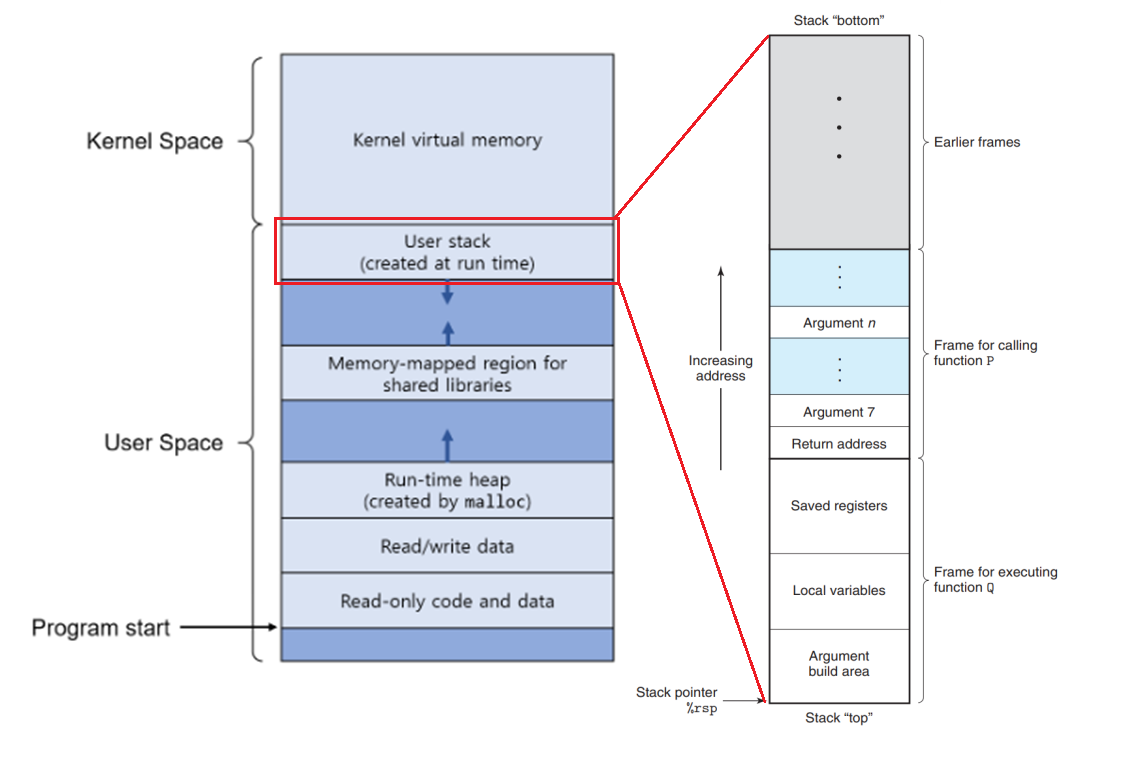
프로시저는 데이터를 스택에 저장한다.
다른 프로시저를 호출하기 위해서는 필요한 스택 프레임의 공간만큼 스택을 늘려야 한다.
saved registers, local variables, argument build area에 무엇이 저장되는지는 뒤에서 언급
3-7-2. 제어의 이동
프로시저를 호출하면 프로그램 제어를 호출된 프로시저로 전달한다.
제어를 프로시저P에서 프로시저Q로 전달하는 것은, 단순히 프로그램 카운터를 프로시저 Q의 시작 코드 주소로 설정하는 것이다.
나중에 프로시저가 리턴(종료)해야할 때에 프로시저 P의 실행을 재개해야 하므로, 프로시저 P는 프로시저 Q를 호출하기 직전에 리턴 후 실행할 명령어(바로 다음 명령어)를 스택에 푸시한다. 이것이 [[#3-7. 프로시저#3-7-1. 런타임 스택|3-7-1.]] 그림의 Return address이다.
프로시저 Q는 ret 명령어를 통해서 리턴할 때 Return address를 스택에서 팝해와 PC를 설정한다.
3-7-3. 데이터 전송
프로시저가 호출될 때와 리턴할 때, 프로시저는 제어를 전달할 뿐 아니라 데이터를 인자(아규먼트)와 리턴값으로 전달한다.
보통 이런 인자 전달은 레지스터를 통해 일어난다.
x86-64에서 인자 전달을 위해 최대 6개의 인자들을 레지스터를 통해 전달할 수 있다.
전달할 인자가 6개를 넘는 경우 스택을 통해 전달된다.
인자가 6개를 넘으면 프로시저를 호출하기 전 그 넘는 양만큼 스택 프레임에 할당하고 (현재 프로시저의)스택 탑에 넣는다.([[#3-7. 프로시저#3-7-1. 런타임 스택|3-7-1.]] 그림의 호출하는 프로시저 P의 스택프레임-Argument n부터 Argument 7부분)
인자들이 모두 배치되고 나면 프로시저를 호출할 수 있다.
만약 호출된 프로시저가 또 다시 인자가 6개를 넘는 다른 프로시저를 호출할 경우에는, 자신의 스택 프레임에 "Argument build area"라고 이름 붙인 영역([[#3-7. 프로시저#3-7-1. 런타임 스택|3-7-1.]] 그림 Q 스택 프레임)으로 공간을 할당할 수 있다.
3-7-4. 스택에서의 지역저장공간
프로시저가 지역 데이터를 메모리에 저장해야 하는 경우가 있다:
1. 지역 데이터를 모두 저장하기에는 레지스터의 수가 부족한 경우
2. (C언어에서)지역변수에 연산자 '&'가 사용되었으며, 이 변수의 주소를 생성할 수 있어야 하는 경우
3. 일부 지역변수들이 배열 또는 구조체여서 이들이 배열이나 구조체 참조로 접근되어야 하는 경우
특히 2, 3번의 경우에는 데이터가 적더라도 반드시 메모리 공간을 사용해야 한다.
일반적으로 프로시저는 위와 같은 경우 스택 포인터를 감소시켜서 스택 프레임의 "Local variables"라고 이름 붙인 영역([[#3-7. 프로시저#3-7-1. 런타임 스택|3-7-1.]] 그림 Q 스택 프레임)에 공간을 할당한다.
3-7-5. 레지스터를 이용하는 지역저장소
스택과 달리 레지스터들은 모든 프로시저들이 공유한다.
하나의 프로시저(호출자)가 다른 프로시저(피호출자)를 호출할 때, 피호출자가 호출자가 나중에 사용할 레지스터 값을 덮어쓰지 않기 위해서 프로시저들이 준수해야 할 레지스터 사용관습들을 소개하는 장이다.
3-7-5-1. 피호출자-저장 레지스터
%rbx, %rbp, %r12-%r15([[#3-4. 정보 접근하기|3-4.]] 그림에서 Callee saved로 표시된 레지스터)는 피호출자-저장 레지스터로 구분한다.
피호출자 프로시저는 리턴될 때 호출된 시점과 동일한 레지스터 값들을 보장해야 한다.
그럴 수 있도록 피호출자 프로시저는 이 값들을 변경하지 않거나, 스택에 푸시해 두었다가 리턴하기 전에 팝해오는 방식으로 레지스터를 보존해야 한다.
레지스터 값들을 푸시하면 "Saved registers"라고 이름 붙인 영역([[#3-7. 프로시저#3-7-1. 런타임 스택|3-7-1.]] 그림 Q 스택 프레임)을 생성한다.
3-7-5-2. 호출자-저장 레지스터
피호출자-저장 레지스터와 스택 포인터(%rsp)를 제외한 모든 레지스터들은 호출자-저장 레지스터로 구분한다.
호출자-저장 레지스터는 피호출자 프로시저로부터 변경될 수 있다는 것을 의미한다.
따라서 호출자 프로시저는 피호출자가 변경해도 되는(의도적으로 변경하도록 하는)레지스터들을 제외하고는, 호출하기 전 이 레지스터들을 저장해야 할 의무가 있다.
3-7-6. 재귀 프로시저
함수와 마찬가지로 재귀적인 방식으로 프로시저를 정의할 수도 있다.
이런 재귀 방식은 별도의 호출들이 서로 간섭하지 않도록 구성된다.
프로시저의 스택운영방식은, 이런 정책을 자연스럽게 제공한다.
3-8. 배열의 할당과 접근
3-8-1. 기본 원리
C언어 에서의 배열 선언 T A[N](T는 자료형, N은 정수 길이)은 두 가지 효과를 갖는다.
1. 바이트(은 자료형T의 크기) 만큼의 공간을 하나의 블록(연속적인 메모리 공간)으로 메모리에 할당한다.
2. 식별자 A를 배열 시작 주소() 포인터로 사용한다.
따라서 배열의 번 원소(A[i])는 주소 에 저장된다.
3-8-2. 포인터 연산
포인터 변수도 결국에는 주소 값을 가지는 변수이기 때문에 연산을 사용할 수 있다.
정수 연산과 다른 점이 있다면 만큼을 1로 하여 연산한다.
즉 &A[3] - &A[2]은 이 아니라 1이다.
3-8-3. 다중 배열
T A[N][M]은 바이트 만큼의 공간을 할당한다.
A[i][j]는 에 접근한다.
A[i]는 주소를 가리킨다.
3-8-4. 고정크기의 배열
C 컴파일러는 고정크기의 다차원 배열을 사용하는 코드에 대해 다양한 최적화를 수행할 수 있다.
// 고정 크기 배열
#define N 16
typedef int fix_matrix[N][N];fix_matrix[i][j]의 주소는 로 구할 수 있다.
하지만 연속적인 인덱스에 접근해야 할 때 매 번 곱셈과 덧셈을 반복하는 것은 비효율적이다.
컴파일러는 이런 경우에 이전 인덱스를 기억해두었다가 씩 더하는 방식으로 순회를 진행하도록 최적화한다.
특히 고정크기의 배열인 경우에는 그 크기 또한 컴파일 단계에서 확정할 수 있으므로 인덱스를 저장할 변수도 사용하지 않도록 최적화할 수도 있다.
3-8-5. 가변크기 배열
C는 이제 아래와 같은 가변크기 배열 할당을 허용한다.
int A[i][j];
int *A = (int *)malloc(sizeof(int)*i*j)6. 메모리 계층구조
6-2. 지역성
잘 작성한 컴퓨터 프로그램은 좋은 지역성 locality을 보여준다.
1. 시간 지역성 temporal locality
한번 참조된 메모리 위치는 가까운 미래에 다시 여러 번 참조될 가능성이 높은 것
반복문을 사용한 프로그램은 같은 인스트럭션과 변수들에 반복적으로 접근하는 경향이 있다.
2. 공간 지역성 spatial locality
어떤 메모리 위치가 참조되면, 가까운 미래에 근처의 메모리 위치를 참조할 가능성이 높은 것
배열을 사용한 프로그램은 (특히 순회하는 경우) 근처의 메모리를 참조하는 경향이 있다.
하드웨어는 지역성을 활용하여 캐시메모리 등 작업을 빠르게 하기 위한 설계가 적용되어 있으므로, 지역성을 이해하고 좋은 지역성을 갖도록 프로그램을 작성하는 것은 성능에서 중요하다.
6-2-1. 프로그램 데이터 참조의 지역성
int sumvec(int v[N]) {
int i, sum = 0;
for (i = 0; i < N; i++)
sum += v[i];
return sum;
}배열의 합을 계산하는 함수를 생각하자.
위 코드에서 sum은 반복적으로 참조되므로 좋은 시간 지역성을 가지고 있다.
반면 스칼라 변수로서 인접한 메모리 공간과 연관이 없으므로 공간 지역성이 존재하지 않는다.
v의 원소들은 순차적으로 읽히므로 v에 대해서는 좋은 공간 지역성을 가지고 있다.
그러나 각 원소들은 한 번만 접근되므로 나쁜 시간 지역성을 가지고 있다.
그러므로 함수 sumvec은 좋은 시간 또는 공간 지역성을 지니므로 전체적으로 좋은 지역성을 지녔다고 볼 수 있다.
이렇게 벡터의 매 k번째 원소를 방문하는 것을 stride-k 참조 패턴이라고 부른다.
sumvec함수는 stride-1 참조 패턴을 가진다.
일반적으로 k가 증가하면 공간 지역성은 감소한다.
int sumarrayrows(int a[M][N]) {
int i, j, sum = 0;
for (i = 0; i < M; i++)
for (j = 0; j < N; j++)
sum += a[i][j];
return sum
}이차원 배열의 합을 계산하는 함수를 생각하자.
위 함수는 stride-1 참조 패턴을 갖는다.
int sumarraycols(int a[M][N]) {
int i, j, sum = 0;
for (j = 0; j < N; j++)
for (i = 0; i < M; i++)
sum += a[i][j];
return sum
}똑같은 동작을 하지만 열우선 참조를 하는 다른 함수를 생각하자.
이제 stride-N 참조 패턴을 갖는다.
이렇게 같은 역할을 하더라도 공간 지역성에서 차이가 커질 수 있다.
6-2-2. 인스트럭션 선입의 지역성
프로그램의 인스트럭션 역시 메모리에 저장되고 CPU가 읽어들여야 하므로 인스트럭션 선입(읽기)에 대한 지역성도 평가할 수 있다.
예를 들어 sumvec 함수에서 사용한 for루프 내의 인스트럭션들은 순차적인 메모리 순서대로 반복해 실행되며, 좋은 공간 지역성을 갖게 된다.
8. 예외적인 제어흐름
시스템은 프로그램의 실행과는 관련 없는 시스템 상태 변화에도 반응할 수 있어야 한다.
시스템은 제어흐름의 갑작스런 변화를 만드는 방법(예외적인 제어흐름 exceptional control flow (ECF))으로 이러한 상황에 반응한다.
8-1. 예외상황
예외상황은 하드웨어 또는 운영체제에 의해 구현된 예외적인 제어흐름의 한 형태이다.
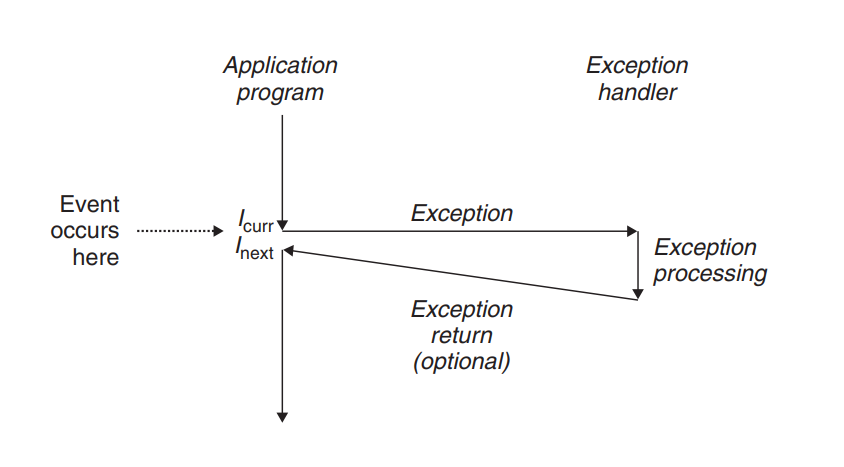 예외상황에 대한 처리 방식을 간단히 나타낸 그림이다.
예외상황에 대한 처리 방식을 간단히 나타낸 그림이다.
명령어 를 실행하고 있을 때 프로세서 상태에 중요한 변화(이벤트)가 일어난다면,
상태는 예외처리 핸들러로 보내지고 보내진 상태에 따라 예외를 처리한 뒤 프로그램을 종료시키거나 다시 프로그램의 실행 흐름으로 되돌아 간다.
8-1-1. 예외처리
예외상황은 하드웨어와 소프트웨어가 긴밀하게 협력해야한다.
하드웨어와 소프트웨어 사이에 작업이 분배되는 모습을 자세히 살펴본다.
시스템은 가능한 예외상황마다 예외번호를 할당하고 있다.
일부는 프로세서(하드웨어) 설계자가, 나머지는 운영체제 커널(소프트웨어) 설계자가 할당한다.
프로세서 설계가 할당한 예외번호의 예: divide by zero, 페이지 오류, 메모리 접근 위반, breakpoint, 산술연산 오버플로우
커널 설계자가 할당한 예외번호의 예: 시스템 콜, 외부 I/O 디바이스로부터의 시그널
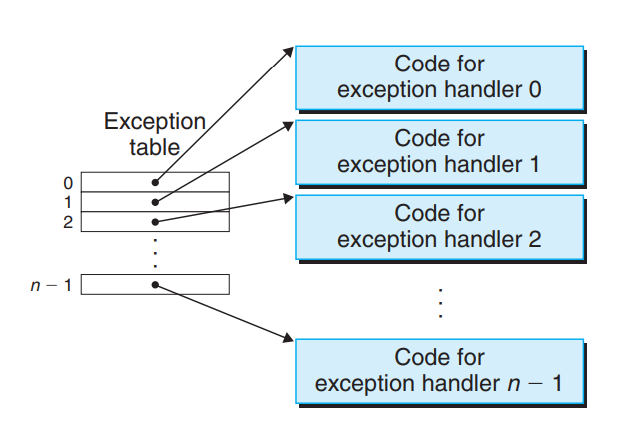
시스템 부팅 시 운영체제는 예외 테이블[^8-1]을 할당하고 예외번호별 처리 핸들러로 할당한다.
즉, 예외 테이블의 엔트리(배열 인덱스) k가 예외상황 k에 대한 핸들러의 주소를 갖는다.
프로세서가 이벤트 발생을 감지하면 해당되는 예외번호 k를 결정하고, 예외 테이블의 k를 참조해 핸들러를 호출한다.
[^8-1]: 예외 테이블의 주소는 예외 테이블 베이스 레지스터라는 특별한 레지스터에 저장한다.
예외상황은 프로시저 콜과 유사하지만 중요한 차이점이 있다:
- 핸들러를 호출하기 전에 스택에 리턴주소를 푸시하는 것은 같지만, 예외의 종류에 따라 현재(이벤트가 발생했을 때 실행 중이던) 인스트럭션 또는 다음 인스트럭션을 푸시한다.
- 중단됐던 프로그램으로 돌아가기 위해 필요한 프로세서 상태를 푸시한다.
- 이것들은 사용자 스택이 아니라 커널 스택 상에 푸시된다.
- 예외 핸들러는 커널 모드에서 돌아가므로 모든 시스템 자원에 완전히 접근할 수 있다.
핸들러가 이벤트를 처리한 후 다시 사용자 프로그램으로 돌아갈 때에는 원래 프로세서의 제어상태와 레지스터 상태를 돌려놓는다.
8-1-2. 예외의 종류 Exception Class
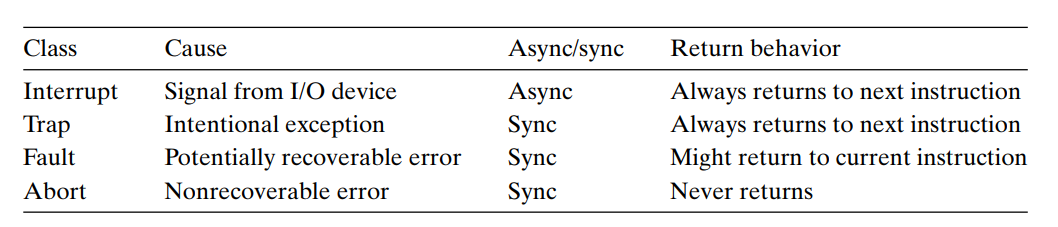
8-1-2-1. 인터럽트 Interrupt
입출력 디바이스로부터 신호를 받아 발생하는 예외이다.
특정 인스트럭션의 실행 여부와 관련이 없기 때문에 비동기적(Async)이다.[^8-2]
프로세서가 인스트럭션 실행을 완료하고 인터럽트 시그널을 감지하게 되면, 시스템 버스에서 예외번호를 읽어 해당 인터럽트 핸들러를 호출한다.
핸들러가 리턴할 때엔 항상 제어를 다음 인스트럭션으로 돌려준다. 즉, 프로그램은 인터럽트가 발생하지 않은 상황과 같이 계속 실행된다.
[^8-2]: 다른 예외의 종류들은 오류 인스트럭션 faulting instruction의 실행에 의해 동기적으로 일어난다. 비동기적 예외를 외부 인터럽트 External Interrupt 또는 하드웨어 인터럽트 Hardware Interrupt, 동기적 예외를 내부 인터럽트 Internal Interrupt 또는 소프트웨어 인터럽트 Software Interrupt라고 부르기도 한다.
8-1-2-2. 트랩 Trap과 시스템 콜 System Call
트랩은 의도적인 예외상황이며 어떤 인스트럭션을 실행한 결과로 발생한다(Sync).
프로그램이 시스템 콜을 호출하였을 때나 예외 상황이 발생하여 시스템으로 제어를 넘기기 위해 발생시키는 예외상황이다.
시스템 콜은 사용자 프로그램에서 커널의 동작을 요청할 때 사용하는 프로시저와 유사한 인터페이스이다.
시스템 콜은 커널 모드에서 돌아가며, 이로 인해 커널 내에서 정의된 스택에 접근하며, 시스템을 제어하는 모든 인스트럭션을 실행할 수 있다.
x86-64에서 시스템 콜은 syscall이라는 트랩 인스트럭션을 통해서 제공된다.
리눅스 시스템 콜에 전달되는 모든 인자들은 범용 레지스터를 통해서 이루어진다.
%rax 레지스터에 시스템 콜 번호를 보관하고, argument용 레지스터에 최대 여섯 개의 인자들을 보관한 후 호출하게 된다.
8-1-2-3. 오류 Fault
핸들러가 정정할 수 있을 가능성이 있는 에러 조건일 때 발생한다.
오류가 발생하면 프로세서는 오류 핸들러로 제어를 이동한다.
핸들러가 에러 조건을 정정할 수 있다면, 오류를 발생시킨 인스트럭션(현재 인스트럭션)으로 제어를 돌려주어 프로그램 실행을 계속한다.
정정할 수 없다면, 핸들러는 커널 내부의 abort 루틴으로 리턴하여 프로그램을 종료한다.
대표적인 예시로 페이지 오류 예외가 있다.
인스트럭션이 참조하는 메모리가 물리 메모리에 페이지되어 있지 않은 상황에 발생한다.
핸들러는 디스크에 있는 페이지를 물리 메모리로 로드하고 다시 오류를 일으킨 인스트럭션으로 돌아가게 해준다.
8-1-2-4. 중단 Abort
하듸웨어 같은 치명적인 에러에서 발생한다. 중단 핸들러는 무조건 응용프로그램을 중단하는 abort 루틴으로 제어를 넘겨준다.
9. 가상메모리
프로세스는 직접 물리 메모리 주소에 접근하는 것이 아니라 프로세스 각각이 갖는 가상 주소 공간을 통해서 메모리에 접근하게 된다.
단순히 부족한 메모리 공간을 확장하기 위한 수단을 넘어 효율적인 메모리 관리, 멀티태스킹, 메모리 보호, 프로세스 격리 등 다양한 기능을 한다.
따라서 가상메모리를 이해하는 것은 시스템이 어떻게 동작하는지 이해하고, 프로그램의 성능을 향상시키고 에러를 피하는데 도움을 준다.
9-1. 물리 및 가상주소 방식
초기의 PC, 디지털 신호 처리 프로세서, 임베디드 컨트롤러 등은 물리 주소 방식을 사용한다.
하지만 대부분의 현대 프로세스들은 가상주소방식을 사용한다.
CPU는 가상주소지정으로 가상주소(VA)를 생성해서 메인 메모리에 접근한다.
물리 메모리에 접근하기 전에 메모리로 보내지기 전에 메모리 관리 유닛(MMU)가 적절한 물리주소로 번역한다.
9-3. 캐싱 도구로서의 VM
가상메모리는 디스크에 저장되며 1바이트 크기 배열로 구성된다.
디스크 안의 배열 정보는 메인 메모리로 캐시된다.
캐시는 블록 단위로 분할되어 디스크과 메인 메모리 사이를 잇는 역할을 하며 가상페이지라고 불린다.
물리메모리 또한 물리페이지(물리 프레임)로 분할되어 사용된다.
가상페이지는 언제나 셋 중 하나로 분류할 수 있다.
1. Unallocated: 할당되지 않은 페이지들. 데이터를 전혀 가지고 있지 않은 블록으로 디스크 공간을 차지하지 않는다.
2. Cached: 할당된 페이지 중 물리 메모리에 캐시된 페이지들.
3. Uncached: 할당된 페이지 중 물리 메모리에 캐시되지 않은 페이지들
9-3-1. DRAM 캐시의 구성
DRAM 캐시: 메인 메모리로 캐시하는 가상페이지 캐시
SRAM 캐시: L1, L2, L3 캐시 메모리로 캐시하는 메인 메모리 캐시
DRAM과 SRAM의 차이보다 디스크과 DRAM의 차이가 훨씬 더 크다.
따라서 DRAM 캐시의 미스를 줄이는 것은 중요하다.
9-3-2. 페이지 테이블
VM 시스템은 가상페이지가 DRAM 어디에 있는지, 어떤 물리 페이지를 캐싱했는지, 없다면 디스크 어디에 가상 페이지가 있고 어떤 페이지를 물리 메모리에서 제거할 것인지를 결정해야 한다.
이런 VM 시스템의 기능들은 운영체제, MMU의 주소 번역 하드웨어, 페이지테이블(가상페이지를 물리페이지로 매핑하는 자료구조. 물리메모리에 저장)의 조합으로 제공된다.
- 페이지 테이블: 페이지 테이블 엔트리(PTE)의 배열
- 페이지 테이블 엔트리: 할당 여부와 캐시된 위치(DRAM 또는 디스크) 등의 정보를 저장한다.
9-4. 메모리 관리를 위한 도구로서의 VM
VM은 메모리 관리를 단순하게 하는 목적으로도 사용된다.
1. 링킹을 단순화한다.
프로세스들이 실제 물리 메모리 어디에 저장할지와 관계없이 동일한 기본 메모리 포맷을 사용하도록 해준다. [[#3-7-1. 런타임 스택|예시]]
2. 로딩을 단순화한다.
리눅스 로더는 실행파일과 공유 목적파일들을 메모리에 로드하기 위해, 실제로 파일들을 읽어들이고 메모리에 적치하는 것이 아닌, 단순히 PTE가 이 파일들의 위치를 가리키게 한다.(메모리 매핑, 리눅스의 mmap)
3. 공유를 단순화한다.
운영체제는 C프로그램에서 커널과 표준 라이브러리 코드를 각 프로세스에서 별도로 포함시키지 않고, 동일한 물리페이지들로 매핑해 한 페이지를 공유하게 한다.
4. 메모리 할당을 단순화한다.
프로그램이 추가 힙 공간을 요구할 때, 물리 메모리에서 주소가 연속된 페이지를 찾을 필요 없이 연속적인 가상메모리 페이지를 할당하고 임의의 물리 페이지로 각각 매핑한다.
9-5. 메모리 보호를 위한 도구로서의 VM
사용자 프로세스는 읽기 전용 코드를 수정할 수 없어야 하며,
커널 코드나 데이터 역시 읽거나 수정할 수 없어야 한다.
또한 다른 프로세스의 사적 메모리에 접근할 수 없어야 한다.
VM을 통해 별도의 가상 주소공간을 제공하면 이런 분리가 쉬워진다.
PTE에 허가 비트를 추가해서 접근을 제어하는 방식이 가능해진다.
9-6. 주소의 번역
9-7. 사례 연구: 인텔 코어 i7/리눅스 메모리 시스템
리눅스를 실행하는 인텔 cpu의 맥락에서 실제 가상메모리의 사례를 알아본다.
x86-64에서는 64비트 가상/물리 주소공간이 가능함에도 현재에는 48비트 가상 주소공간과 52비트 물리 주소공간을 지원하고있다. (32비트 주소공간도 호환으로 지원한다.)
9-7-2. 리눅스 가상메모리 시스템
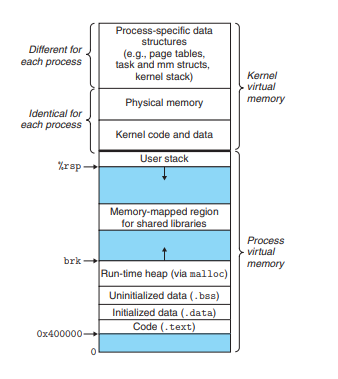
- 코드(텍스트) 영역:
- 기계어 코드가 저장
- 읽기 전용
- 데이터 영역:
- 초기화된 전역 변수와 정적 변수가 저장
- BSS 영역:
- 초기화되지 않은 전역 변수와 정적 변수가 저장
- 프로그램 시작 시 0으로 초기화됨
- 힙 영역:
- 동적 메모리 할당 시 사용
- 런타임 중 크기가 확장될 수 있음
- 스택 영역:
- 함수 호출 시 스택 프레임으로 영역이 확장되고, 함수 종료 시 해제됨
- 스택 프레임에는 레지스터 저장 값, 지역 변수, 함수 인자, 리턴 주소를 저장
3번까지는 컴파일 단계에서 크기가 결정된다.
9-8. 메모리 매핑
9-9. 동적 메모리 할당
동적 메모리 할당기는 가상메모리의 힙(heap) 영역을 관리한다.
할당기는 힙을 다양한 크기의 블록들로 나누어 관리한다.
각 블록은 할당되었거나 가용한(free) 가상메모리의 연속적 묶음이다.
할당기는 크게 두 종류가 있다.
1. 명시적인 할당기
프로그램이 명시적으로 할당된 블록을 반환(free)해 줄 것을 요구한다.
예를 들어, C에서는 블록을 반환하기 위해 free함수를 사용한다.
2. 묵시적 할당기
할당된 블록이 더 이상 프로그램에 의해 사용되지 않은지를 할당기가 검출하고 반환한다.
가비지 컬렉터라고도 불리며, 사용하지 않는 블록들을 반환하는 작업을 가비지 컬렉션이라고 부른다.
9-9-1. malloc과 free함수
C 프로그램은 malloc함수를 호출해서 힙으로부터 블록들을 할당받는다.
malloc함수는 요청된 size 이상의 메모리 블록의 포인터를 리턴한다.
32비트 모드(gcc -m32)에서 항상 8의 배수인 주소를 리턴하며, 64비트 모드에서는 16의 배수인 주소를 리턴한다.(정렬 제한사항)
32비트 모드 기준으로 주소를 2진법으로 표현했을 때 마지막 세 자리가 000이라는 의미이다.
free함수는 블록의 시작 주소를 인자로 받아 블록을 반환하며, 인자가 블록의 시작 주소가 아닌 경우 아무런 동작도 하지 않는다.
9-9-2. 왜 동적 메모리 할당인가?
가장 중요한 이유는 프로그램을 실제 실행시키기 전에는 자료 구조의 크기를 알 수 없는 경우들이 있기 때문이다.
9-9-3. 할당기 요구사항과 목표
명시적 할당기에 요구되는 사항:
1. 임의의 요청 순서 처리하기
응용프로그램은 임의의 순서로 할당/반환을 요청하기 때문에 할당기는 어떤 순서의 요청이든 대응할 수 있어야 한다.
2. 요청에 즉시 응답하기
따라서 처리 속도를 위해 요청의 처리 순서를 바꾸거나 버퍼로 처리를 지연시킬 수 없다.
3. 힙만 사용하기
4. 블록 정렬하기
블록들을 어떤 종류의 데이터 객체라도 저장할 수 있는 방식으로 정렬해야 한다.
5. 할당된 블록을 수정하지 않기
가용 블록만 조작하거나 변경할 수 있으며, 할당 블록들은 수정하거나 이동시켜서는 안된다.
따라서 할당 블록들을 압축하는 기법들은 허용되지 않는다.
성능 좋은 할당기는 처리량과 메모리 이용도를 최대화한다.
1. 처리량
단위 시간당 완료되는 요청의 수
2. 메모리 이용도
메모리는 유한하므로 효율적으로 이용해야 한다.
가상 메모리라고 할지라도 프로세스들의 가상메모리의 총 합은 디스크 내의 스왑 크기를 넘을 수 없다.
이용도를 측정할 단위 중 하나로 최고 이용도가 있다.
할당/반환 요청을 순서대로
라고 할 때 최고 이용도는 현재 힙의 크기 대비 최고 데이터의 양의 비율로 나타낸다.
는 요청 가 완료된 후의 최고이용도
는 요청 가 완료된 후의 힙의 크기[^1]
는 요청 가 완료된 후의 데이터의 총 크기
할당기의 목적은 를 최대화하는 것이다.
처리량과 이용도는 서로 상충관계에 있으므로 할당기 설계에서 적절한 균형을 찾는 것이 중요하다.
[^1]: 단조 증가 가정. 를 힙의 최대 크기로 정의하면 단조 증가 가정을 완화할 수 있다.
9-9-4. 단편화
가용 메모리가 할당 요청을 수행할 수 없는 상황을 단편화라고 한다.
단편화는 두 가지 종류로 분류된다.
1. 내부 단편화
여러가지 이유로 할당된 블록이 데이터 크기보다 더 큰 경우를 말한다.
내부 단편화가 발생한 부분은 데이터를 저장하지 않음에도 할당을 위해 사용할 수 없다.
할당기의 최소 블록 크기보다 더 작은 데이터 블록을 요청했을 때 등에 일어날 수 있다.
할당기는 [[#9-9-1. malloc과 free함수|정렬 제한사항]]을 만족시키기 위해 데이터보다 블록 크기를 증가시킬 수 있기 때문이다.
내부 단편화는 (할당된 블록들의 크기)-(데이터들의 크기)로 구할 수 있어 정량화가 간단하다.
또한 내부 단편화의 크기는 이전 요청들과 할당기의 구현 방식에만 의존한다.
2. 외부 단편화
외부 단편화는 전체 가용 공간은 할당에 충분한 크기이지만, 이 요청을 처리할 수 있는 하나의 가용 블록은 없는 경우를 말한다.
외부 단편화가 발생하면 필요한 크기 이상의 가용 블록이 존재하지 않으므로 추가 힙 공간을 요청(힙 경계brk 확장)해야 한다.
이전에 할당받았던 블록을 반환하는 때 등에 일어날 수 있다.
외부 단편화는 측정하기 어려우며 미래 요청들에도 의존한다.
예를 들어, 현재 가용 블록들이 모두 4워드[^2] 크기를 가진다고 하면 외부 단편화의 발생 여부는 미래에 4워드보다 큰 블록을 요청하는지에 따라 달라질 수 있다.
외부 단편화는 예측하기 어렵기 때문에 할당기들은 보통 가용 블록들의 크기를 크게 유지하려는 방법을 사용한다.
[^2]: 가상 메모리에서 워드는 4바이트, 더블 워드는 8바이트
9-9-5. 구현 이슈
항상 요청한 크기만큼 힙을 증가시키고 그 이전 힙 경계 주소를 반환하는 간단한 할당기를 생각해볼 수 있다.
이 할당기는 처리량은 매우 좋지만 이용도는 매우 나쁠 것이다.
처리량과 이용도 사이에 좋은 균형을 유지하는 할당기는 다음 이슈들을 고려해야 한다:
1. 가용 블록 구성: 어떻게 가용 블록들을 지속적으로 파악하는가
2. 배치: 새로 할당할 블록을 배치할 가용 블록을 어떻게 선택하는가
3. 분할: 배치 후 가용 블록의 남는 부분들을 어떻게 처리하는가
4. 연결: 막 반환된 블록으로 어떤 작업을 할 것인가(주로 인접한 가용 블록과)
아래에서는 위의 이슈들의 간단한 구현인 묵시적 가용 리스트를 중심으로 설명한다.
9-9-6. 묵시적 가용 리스트
가용 블록 구성을 구현하기 위해
1. 블록 경계를 구분하고
2. 할당된 블록과 가용 블록을 구분하기 위한 자료 구조가 필요하다.
이를 가용 리스트라고 한다. 대부분의 할당기는 이 정보를 블록 내에 저장한다.
그 중에서도 간단한 구현인 묵시적 가용 리스트는 메모리 블록을 데이터, 패딩에 덧붙여 1워드 길이의 헤더를 포함한다.
헤더는 블록의 크기(헤더와 패딩을 포함한 전체 블록)와 가용 여부에 대한 정보 등을 담게된다.
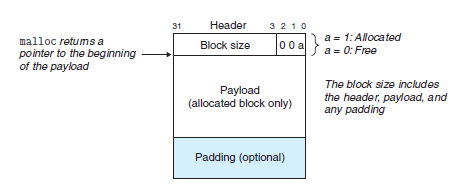
헤더의 한 가지 간단한 예로 위와 같은 구조를 생각할 수 있다.
32비트 모드를 가정할 때 블록의 크기는 최대 1워드이다.
그러나 정렬 제한사항을 고려하면 할당기는 블록의 크기를 8의 배수로 유지[^3]하므로 블록 크기(2진법)의 하위 3비트는 항상 0이다.
그러므로 하위 3비트는 다른 정보를 위해 사용한다.
이 예시에서는 하위 1비트에 할당/가용 여부를 표시하는 비트로 사용하였다.
[^3]: 데이터를 보관하는 payload의 시작 주소는 8의 배수여야 한다. 헤더의 크기가 4바이트임을 감안하면, 헤더를 포함한 블록의 시작주소(=이전 블록의 끝 주소)는 8n-4여야 한다. 따라서 할당기는 블록의 크기가 8의 배수가 되도록 패딩한다.
가용 리스트도 이름처럼 추상적 자료형인 리스트의 일종이다.
묵시적 가용 리스트는 리스트를 구현하는데 있어 배열이나 연결리스트와 다르게 블록 자신의 크기와 가용 부를 표시함으로써 다음 가용 블록의 위치를 묵시적으로 알린다.
최소 블록 크기는 시스템의 정렬 요구사항과 할당기의 블록 포맷 선택에 의존한다.
예시: 정렬 요구사항을 더블 워드(8바이트), 블록 포맷을 묵시적 가용 리스트라고 하면 최소 블록 크기는 데이터 4바이트, 헤더 1바이트, 패딩 3바이트로 8바이트가 된다.
9-9-7. 할당한 블록의 배치
할당기가 요청받은 블록을 저장하기 위해 가용 블록을 검색하는 방법을 배치 정책이라고 한다.
- First Fit: 가용 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택
+ 장점: 큰 가용 블록을 뒷쪽에 두는 경향이 있어 자연스레 작은 가용 블록을 선택할 가능성이 높아진다. (이용도)
+ 단점: 작은 가용 블록이 앞쪽에 있으므로 검색 횟수가 늘어난다. (처리량) - Next Fit: 리스트의 처음이 아닌 이전 검색 종료 지점에서 검색을 시작
- 장점: 이전 검색 지점 이후에서 조건에 맞는 블록을 선택할 가능성이 높아 First Fit에 비해 빠르다. (처리량)
- 단점: 메모리 이용도가 First Fit보다 낮아질 수 있다. (이용도) - Best Fit: 모든 가용 블록을 검색해 크기가 맞는 가장 작은 가용 블록을 선택
- 장점: 메모리 이용도가 좋다. (이용도)
- 단점: 묵시적 가용 리스트에서는 힙의 모든 블록(가용/할당 블록 모두)을 검색해야 한다. (처리량)
아래에서는 할당 블록까지 검색하지 않을 수 있도록 단순화한 best-fit 정책인 다단 가용 리스트 조직 segregated free list organizations에 대해서 설명한다.
9-9-8. 가용 블록의 분할
할당기가 블록을 배치할 가용 블록을 찾은 후에는 가용 블록의 어느 정도를 할당할 것인지 결정해야 한다.
- 충분히 작은(good fit) 가용 블록을 선택한 경우
가용 블록 전체를 사용할 수 있다.
내부 단편화가 생기지만 수용할 수 있다. - 크기가 큰 경우(fit is not good)
가용 블록을 나누어 할당한다.
전체를 할당하는 경우 내부 단편화가 생긴다.
9-9-9. 추가적인 힙 메모리 획득하기
배치할 블록을 찾을 수 없다면, 우선 인접한 가용블록들을 합쳐서(연결) 더 큰 가용 블록들을 만들어 본다.
이미 모두 연결돼있거나 충분히 큰 블록이 만들어지지 않으면 sork함수를 호출해서 추가적인 힙 메모리를 요청한다.
9-9-10. 가용 블록 연결하기
블록을 반환했을 때, 인접한 가용 블록이 있다면 하나의 연결된 가용블록으로 볼 수 있다.
하지만 실제로는 가용블록이 나누어져 있어 배치에 실패하는 경우가 생길 수 있고 이를 가성 단편화(false fragmetation)라고 한다.
가성 단편화를 극복하기 위해 할당기는 가용블록들을 합칠 수 있다(연결 coalescing).
- 즉시 연결
블록이 반환될 때마다 인접 가용 블록들을 연결 - 지연 연결
반환 후 적절한 때에 가용 블록들을 연결
예시: 할당 요청이 실패하는 경우 모든 가용블록들을 검색하여 연결
즉시 연결은 간단하며 상수 시간()에 수행할 수 있는 장점이 있지만
할당-반환을 반복하는 프로그램에서는 연결과 분할을 반복하는 등 일부 요청 패턴에서 쓰래싱이 발생할 수 있다.
빠른 할당기들은 지연 연결을 주로 사용하지만 아래에서는 설명을 위해 즉시 연결을 가정한다.
9-9-11. 경계 태그로 연결하기
반환하는 블록(현재 블록)의 다음 블록이 가용 블록인지 확인하려면 헤더에서 블록 크기만큼 이동하면 된다.
하지만 이전 블록이 가용 블록인지 확인하기 위해서는 헤더만 있는 묵시적 가용 리스트라면 처음부터 블록들을 검색해보는 방법밖에 없다.[^4]
이를 위해 경계 태그라는 기법이 등장하였다.
경계 태그는 헤더와 동일한 내용을 블록 끝에 풋터로 추가하는 것으로, 블록 앞 1워드만을 읽어 이전 블록이 가용 블록인지 확인할 수 있다.
다만 각 블록마다 헤더와 풋터를 유지해야 하므로 메모리 오버헤드가 심해진다.
풋터는 이전 블록이 가용 블록일 경우 크기를 알려주는 목적으로 사용되므로, 이전 블록이 가용 블록인지 여부를 헤더에 저장하고, 가용 블록이 아닌 경우(할당 블록인 경우)에는 풋터를 사용하지 않는 방식으로 최적화할 수 있다.
[^4]: 이전으로 워드 크기씩 헤더를 찾아가는 방법을 떠올릴 수 있지만, 헤더를 통해 블록 크기만큼 이동하는 컨텍스트가 없다면 헤더를 찾더라도 헤더인지 데이터인지를 판단할 수 없다.
9-9-12. 종합 설계: 간단한 할당기의 구현
9-9-13. 명시적 가용 리스트
지금까지 묵시적 가용 리스트를 통해 할당기의 개념을 소개하였다.
그러나 묵시적 가용 리스트는 블록 할당 시간이 전체 힙 블록의 수에 비례하기 때문에[^5] 범용 할당기에 적합하지 않다.
보통 명시적 자료구조로 가용 리스트를 만드는 것이 좋은 방법이다.
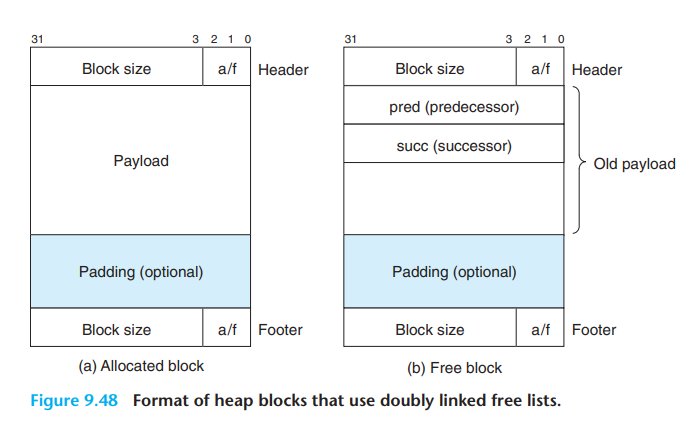
가용 블록은 프로그램에서 사용하지 않기 때문에 가용 블록의 리스트를 구현하기 위해 가용 블록 내의 공간을 사용할 수 있다.
그림은 명시적 가용 리스트의 간단한 예시로, 가용 블록 안에 이전/다음 가용 블록의 주소를 저장해 이중 연결 리스트로 구성했다.
명시적 가용 리스트를 사용하면
- 장점: first fit 할당 시간을 전체 힙 블록 수에 비례했던 것에서 가용 블록의 수에 비례하는 것^6으로 줄일 수 있다.
- 단점: 최소 블록 크기가 커지므로 내부 단편화 가능성이 높아진다. 가용 블록들이 포인터, 헤더, 풋터를 저장할 수 있을만큼 커져야 하므로 그 보다 작은 공간은 패딩에 포함시키기 때문이다.
다만 first fit 배치 정책을 사용할 때의 반환 시간과 이용도는 블록 정렬 정책에 의해 달라진다.
- 후입선출로 정렬하기
이중 리스트를 스택처럼 후입선출 식으로 유지한다.
즉, 새롭게 반환되는 블록을 리스트의 시작 부분에 삽입한다.
first fit 배치 정책을 같이 사용하면, 최근에 반환된 블록 순으로 검색하게 된다.
반환이 상수 시간에 수행되며 [[#9-9-10. 가용 블록 연결하기|연결]]도 상수 시간에 수행할 수 있다. - 주소 순으로 정렬하기
이중 리스트를 가장 가까운 가용 블록의 주소를 가리키도록 구성한다.
반환을 위해서는 반환 위치를 우선 탐색해야 하므로 반환시간이 가용 블록에 비례한다.
대신 first fit 배치 정책에서 후입선출로 정렬한 경우보다 더 좋은 메모리 이용도를 가진다.[^7]
[^5]: 가용 블록의 수를 N, 할당 블록의 수를 M이라고 한다면 묵시적 가용 리스트의 블록 할당 시간은 이다.
[^7]: [[#9-9-7. 할당한 블록의 배치]]에서 알 수 있듯 first fit의 장점은 뒷 부분에 크기가 큰 가용 블록이 배치된다는 점에서 발생한다. 후입 선출로 정렬하였을 때에는 크기와 관계 없이 반환된 순으로 정렬되므로 이런 장점이 사라진다.
9-9-14. 분리 가용 리스트
앞서 알아본 모든 가용 블록들을 하나의 연결 리스트로 사용하는 방법을 단일 연결 가용 블록 리스트라고 한다.
이는 할당 시간이 비례^6하므로 할당 시간을 줄이기 위해 분리 저장장치 segregated storage를 사용하는 경우가 많다.
분리 저장장치 방식은 가용 리스트를 비슷한 크기(크기 클래스size class) 별로 여러 개로 나누어 사용한다.
크기 클래스를 나누는 방식 예시로는 2의 제곱 단위로 나누는 방법 또는 더 세분하여 크기가 작은 블록들은 각자의 크기 클래스에, 큰 블록들은 2의 제곱으로 나누는 방법등이 있다.
각 크기 클래스마다 크기 순으로 정렬된 가용 리스트를 가지게 된다.
9-9-14-1. 간단한 분리 저장장치
분리 저장장치의 예시로 간단한 분리 저장장치를 들 수 있다.
각 크기 클래스의 가용 블록 크기는 모두 클래스의 최대 크기이다.
예를 들어 2의 제곱으로 클래스를 구분하면 가용 블록은 1, 2, 4, 8, 16...의 크기만을 갖는다.
- 할당: 적절한 가용 리스트를 찾아 블록을 분할하지 않고 전체를 할당한다.
리스트가 비어있으면 (다음 크기를 검색하는 것이 아니라)힙 공간을 추가로 요구해 해당 클래스 만큼의 블록으로 분할해 리스트를 채워넣는다. - 반환: 해당 크기 가용 리스트의 맨 앞에 채워넣는다.
- 장점
- 할당과 반환이 상수시간에 이루어진다.
- 리스트 마다 블록들의 사이즈가 같아 분할/연결이 필요 없기 때문에 오버헤드가 거의 없다.
- 메모리 블록이 동일한 크기로 나눠져 있으므로 블록의 주소만 알면 크기를 알 수 있다.
- 연결이 없으므로 헤더, 풋터가 필요하지 않다.
- 할당과 반환이 모두 리스트의 헤드에만 삽입하므로 이중 연결 리스트가 필요 없다.
- 블록 내에 필요한 정보는 후임자를 가리키는 포인터 뿐이므로 최소 블록 크기가 1워드이다. - 단점
- 블록을 분할하지 않으므로 내부 단편화에 취약하다.
- 극단적인 외부 단편화가 발생할 가능성이 있다.[^8]
[^8]: 할당과 반환을 반복하는 프로그램이 요청하는 블록의 크기를 점점 키워가는 경우, 작은 크기 클래스의 블록들은 가용상태로 남아있으나 연결되지 않으므로 사용할 수 없다. 즉, 외부 단편화가 유발된다.
9-9-14-2. 분리 맞춤 Segregated Fits
분리 맞춤은 리스트들이 다양한 크기의 블록을 가질 수 있다.
분리 맞춤 방식의 분리 저장장치는 묵시적 가용 리스트에도 적용될 수 있다.
다음은 분리 맞춤의 간단한 예시이다.
- 할당: 크기에 맞는 가용 리스트를 first-fit 방식으로 검색한다.
찾을 수 없으면 다음 크기의 가용 리스트를 검색한다.
블록을 찾으면 블록을 분할하고 나머지를 크기에 맞는 가용 리스트에 넣는다.
적절한 크기의 가용 블록이 없으면 추가 힙 공간을 요청한다. - 반환: 블록을 연결하고 연결된 블록을 해당 크기의 가용 리스트에 넣는다.
- 장점
- 힙의 특정 부분(해당 크기 클래스)만 검색하므로 검색 시간이 줄어든다. (처리량)
- 분리 가용 리스트에서 first-fit 검색 방식은 best-fit 검색 방식과 유사하므로 이용도가 개선된다. (이용도)
9-9-14-3. 버디 시스템
버디 시스템은 크기 클래스가 2의 제곱인 경우에 사용할 수 있는 분리 맞춤(segregated fits) 방식이다.
- 할당: 해당 크기 클래스의 리스트에서 가용 블록을 찾아 할당한다. 만약 비어있다면 더 큰 클래스에서 찾아 해당 크기가 될 때까지 이분할한다. 분할할 때마다 나머지 절반(버디 buddy)을 해당 가용 리스트에 넣는다. 최초의 블록의 크기는 힙 공간 전체일 것이다.
- 반환: 할당과 반대로, 반환할 블록과 버디들을 할당된 버디를 만날 때까지 연결한다. 버디는 현재 블록의 크기만큼을 주소에 더해 찾을 수 있다.
- 장점
- 빠른 검색과 연결
블록의 주소와 크기를 알면 버디의 주소를 계산하기 쉽기 때문이다.(주소+크기 = 버디의 주소) - 단점
- 블록 크기가 2의 제곱으로 고정되어 있으므로 내부 단편화에 취약하다.
그러므로 어떤 프로그램의 블록 크기가 2의 제곱으로 고정되어 있을 때 사용하면 효과를 얻을 수 있다.
11. 네트워크 프로그래밍
11-1. 클라이언트-서버 프로그래밍 모델
모든 네트워크 응용 프로그램은 클라이언트-서버 모델에 기초한다.
이 모델에서 응용(Application)은 한 개의 서버 프로세스와 여러 개의 클라이언트 프로세스로 구성된다.[^11-1]
클라이언트-서버 모델에서 근본적인 작업은 트랜잭션 transaction이다.
트랜잭션은 클라이언트-서버 간 요청을 주고 받거나 작업을 처리하는 것으로 네 단계로 구성된다:
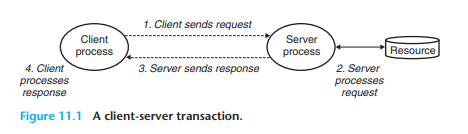
- 클라이언트가 서비스를 요구하기 위해, 요청 request을 서버에 보낸다.
- 서버는 요청을 받아 해석하고, 서버의 자원(resource)을 조작한다.
- 서버는 응답 response을 클라이언트로 보내고 다음 요청을 기다린다.
- 클라이언트는 응답을 받아 처리한다.
클라이언트-서버 모델 구분 이점
[^11-1]: 클라이언트-서버 모델에서의 클라이언트와 서버는 프로세스이다. 머신, 호스트가 아니므로 하나의 호스트 내에 클라이언트 프로세스와 서버 프로세스를 모두 갖는 것이 가능하다.
11-2. 네트워크
네트워크란 여러 컴퓨터들을 그물망처럼 연결한 통신 형태를 뜻한다.
많은 서비스들이 네트워크를 이용하여 제공되고 있다.
11-2-1. 네트워크 계층
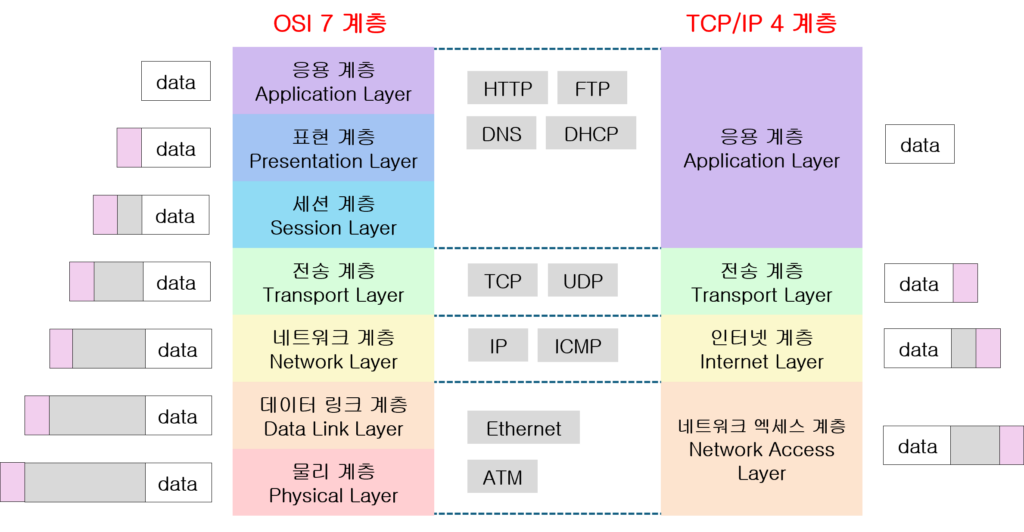
네트워크는 각기 다른 위계 Hierarchy를 갖는 계층구조 시스템으로 이해할 수 있다.
계층으로 나누어 설명하는 이유는:
- 모듈화: 각 계층이 독립적으로 역할만 수행하게 한다. 유지보수와 확장이 쉬워진다.
- 호환성: 다양한 기술을 사용하는 기기들 간 통신을 가능하게 한다. 각 계층에서 표준 인터페이스를 제공한다.
OSI 모델은 이론적인 목적으로 ISO에서 제안한 반면, TCP/IP 모델은 ARPANET(인터넷의 전신)과 함께 발전한 실용적인 모델이다.
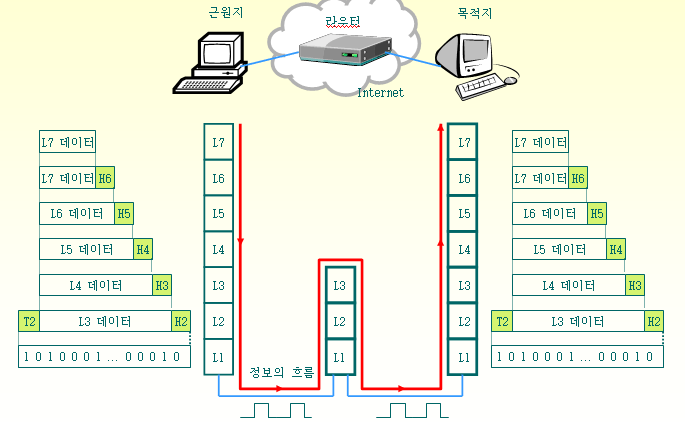
서로 다른 기술을 사용하는 네트워크와 통신하기 위해서, 각 계층에서는 데이터에 하위 계층에서 요구되는 형식으로 헤더를 추가하여 패킷으로 변환한다.
그림을 예시로 들면 TCP/IP 4계층에서 전송 계층은 응용 계층에서 받은 데이터가 텍스트이든 이미지이든 헤더를 붙여 변환한다. 인터넷 계층에서도 마찬가지로 전송 계층에서 TCP/UDP 어떤 프로토콜을 사용하든 헤더를 붙여 전송 가능한 데이터그램으로 만든다. 네트워크 엑세스 계층에서도 헤더를 붙여 프레임으로 만들고 비트로 변환하여 전송된다.
이런 변환 방식을 반복하면 최종적으로는 통일된 형식의 비트(데이터의 가장 미시적 단위)로 변환할 수 있으며 이런 상위 계층의 데이터를 감싸는 변환 방식을 캡슐화 encapsulation라고 한다.
캡슐화를 사용하면 각 계층에서 어떤 프로토콜을 사용하든 동일한 형식으로 전송할 수 있으며 인터넷 통신 방식의 핵심이다.
요약하자면, 계층화가 필요한 주된 이유는 계층 내 서로 호환되지 않는 기술을 하위 계층의 동일한 기술로 변환할 수 있도록 만들기 위해서이다.
OSI 7계층:
1. 물리 계층 (Physical Layer, L1): 비트를 전기 신호, 빛, 또는 무선 신호로 바꿔 물리적 매체를 통해 전달
2. 데이터 링크 계층 (Data Link Layer, L2): 프레임을 사용해 물리 계층에서 안전한 전송(오류 검사 등)을 도움, MAC 주소를 통해 데이터 전송 경로를 관리
3. 네트워크 계층 (Network Layer, L3): 패킷을 생성하고 IP 주소를 기반으로 네트워크 간의 경로를 결정
4. 전송 계층 (Transport Layer, L4): 세그먼트(TCP/UDP)를 사용해 연결을 설정
5. 세션 계층 (Session Layer, L5): 세션을 설정하고 관리하며, 데이터 교환의 시작과 종료를 제어
6. 표현 계층 (Presentation Layer, L6): 데이터 형식과 인코딩을 처리하며, 암호화, 압축 등을 통해 데이터 표현을 통일
7. 응용 계층 (Application Layer, L7): 사용자가 직접 접하는 응용 프로그램과 네트워크 간의 인터페이스를 제공, 다양한 네트워크 서비스를 지원
11-2-2. 일반 개념으로서 인터넷
일반적인 개념으로서의 인터넷 internet을 우리가 실제로 사용하고 있는 Internet, global IP Internet의 맥락(컨텍스트)에서 저수준 계층부터 설명한다.
인터넷은 (로컬)네트워크들 간의 연결을 구현한 것이다.
앞으로 사용하는 용어 중 개념을 가리키는 일반적인 용어(LAN, 네트워크 세그먼트, 인터넷 주소, 전송 프로토콜 등)와 개념을 구현한 기술을 가리키는 용어(주로 TCP/IP 컨텍스트에서. 이더넷/802.11, 이더넷 세그먼트, IP 주소, TCP/UDP 등)를 구분해야 한다.
11-2-2-1. 이더넷
가장 작은 단위의 네트워크는 LAN Local Area Network이며 사무실 내의 내부망을 떠올릴 수 있다.
이더넷 Ethernet은 이런 LAN을 구현한 기술로 1970년대 이래 진화를 거쳐 속도와 안정성이 높아졌다.
11-2-2-1-1. 이더넷 세그먼트(L1)
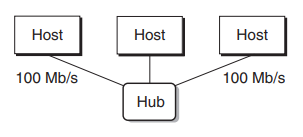
이더넷 세그먼트(이더넷 기술 외의 일반적인 표현은 네트워크 세그먼트)는 호스트와 허브로 구성된다.[^11-2]
- 호스트: 네트워크에 연결된 컴퓨터나 기타 장치
- 허브: 물리포트로 들어온 데이터를 다른 물리포트로 복사하는 장치. 물리 계층(L1)에서 동작한다.
허브에 연결된 모든 호스트가 동일한 신호를 공유하게 된다.
따라서 허브에 연결되어 있는 호스트들은 하나의 세그먼트 안에 있게 된다.
호스트는 프레임(물리 계층에서의 데이터 단위)이라고 부르는 비트들을 다른 호스트로 보낼 수 있다.
같은 신호를 공유하는 호스트들이 선택적으로(특정 호스트를 지정해서) 통신하기 위해서 각 호스트마다 주소를 사용하며 이를 MAC 주소라고 한다.
각 이더넷 어댑터(호스트가 이더넷으로 전송하기 위해 사용하는)는 고유한 주소인 MAC 주소를 가진다.
프레임은 프레임의 발송지 MAC 주소와 목적지 MAC 주소, 프레임의 길이를 보낼 데이터 앞에 헤더로 추가하여 발송한다.
세그먼트 내의 모든 호스트가 프레임을 수신[^11-7]하지만 프레임 헤더의 목적지 주소와 일치하는 목적지 호스트만이 읽어들인다.
허브는 모든 신호를 모든 포트로 복사하기 때문에 호스트들이 동시에 발송을 시도하는 경우 충돌이 발생한다.
이를 이더넷 세그먼트 내의 호스트들이 하나의 충돌 도메인 Collision domain에 있다고 한다.
[^11-2]: 허브를 이용하지 않고 단일 호스트로만 세그먼트를 구성할 수도 있다.
[^11-7]: 의도한 것이 아니라 자연스럽게 모든 호스트가 프레임을 수신하도록 하게 된다. 호스트들은 같은 통신 기술을 공유하고 신호(이더넷 같은 유선 통신에서는 전기신호)를 주고 받을 수 있는 상황에 놓여지기 때문이다. 후술할 인터넷 프로토콜이 필요한 이유, 브로드캐스트 도메인이 각 네트워크 세그먼트로 한정되는 이유로 연결되는 중요한 아이디어이다.
11-2-2-1-2. 브릿지로 연결된 이더넷 세그먼트(L2)
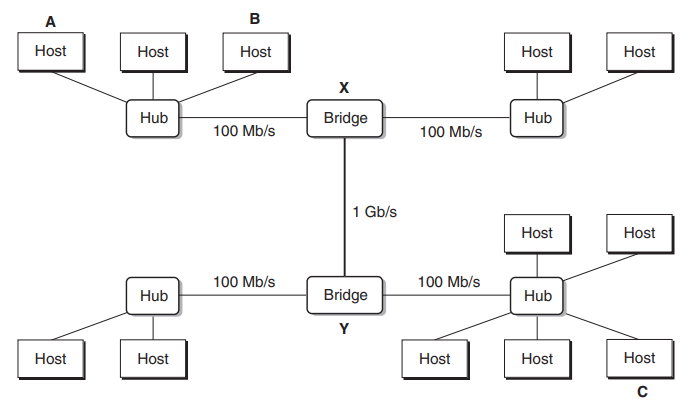
브릿지를 사용하여 충돌 도메인을 분리하고 둘 이상의 이더넷 세그먼트를 연결할 수 있다.
이를 브릿지형 이더넷 세그먼트 *Bridged Ethernet Segments**이라고 한다.
- 브릿지: 이더넷 세그먼트를 연결하는 장치. 허브와 달리 브릿지는 프레임을 수신하면 목적지 MAC 주소를 확인하고 해당 주소가 위치한 세그먼트로만 복사(포워딩 forwarding 또는 스위칭 switching)하여 충돌을 방지한다. 헤더를 읽어들이므로 데이터 링크 계층(L2)에서 동작한다.
브릿지는 프레임 헤더의 발신자 MAC 주소를 확인해 장치들의 물리포트 위치를 학습하여 프레임을 포워딩한다.
학습되지 않은 MAC 주소를 도착지로 하는 프레임은 모든 포트로 보내게 된다.
스위치[^11-3] 역시 헤더를 조회해 브릿지처럼 이더넷 세그먼트를 연결하며 충돌 도메인을 분리한다.
그러나 브릿지는 소프트웨어를 기반으로 CPU와 소프트웨어가 MAC 주소 테이블을 관리하고 프레임 포워딩하는 반면, 스위치는 전용으로 설계된 ASIC와 TCAM을 이용하여 하드웨어적으로 처리한다.
따라서 브릿지에 비해 처리 속도가 매우 빠르므로 대규모 네트워크 환경에 유리하며 포트 수도 보통 수십개이다.
[^11-3]: 스위치는 프레임을 받고 적절한 경로를 결정해 발송(포워딩)해주는 네트워킹 장비를 말한다. 하지만 일반적으로 '스위치'라고만 하면 L2에서 작동하는 스위치를 의미하며, 다른 계층에서 작동하는 스위치는 L3 스위치, L4 스위치 등으로 구분해 부른다. 허브는 항상 모든 포트로 발송하므로 스위치가 아니다.
11-2-2-2. IP(L3)
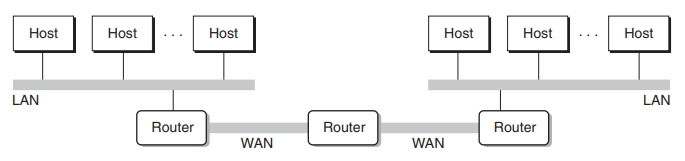
internet은 둘 이상의 network(예를 들어 이더넷)들을 연결한 것(inter-network)이다.
주로 라우터[^11-4]를 이용해 네트워크들을 연결하게 된다. 즉, 라우터는 네트워크(또는 브로드캐스트 도메인[^11-5])을 구분한다.
하나의 라우터로 연결된 네트워크들을 가장 작은 internet이라고 생각할 수 있다.
- 라우터: 다른 네트워크 간 데이터를 전달하는 컴퓨터. 최종 목적지 호스트가 아닌 프레임 어느 네트워크로 보낼 지만을 결정하므로 네트워크 계층(L3)에서 동작한다.
[^11-4]: 라우터는 일반 컴퓨터로도 구성할 수 있으나 주로 라우터 전용으로 나온 컴퓨터 단말을 사용한다.
[^11-5]: 브로드캐스트란 목적지 호스트를 정하지 않고 네트워크의 모든 호스트에 발송하는 것을 말한다. 라우터는 브로드캐스트를 수신해도 다른 물리포트로 포워드하지 않으므로 각 물리포트들은 다른 브로드캐스트 도메인에 있게 된다. 브로드캐스트는 한 번의 신호 발송으로 네트워크 내의 모든 호스트들에 전달하는 것이므로 라우터가 복사하여 전달할 필요도 없으며 해서도 안 된다.
MAC 주소를 이용한 통신은 같은 기술을 사용하는 호스트 간에 사용했다.
되짚어 보자면, 이더넷이나 와이파이와 같이 서로 같은 방식의 물리 신호를 주고받을 수 있는 상황에서 호스트를 선택적으로 통신하기 위해서 MAC 주소를 사용했다.
다르게 말하면 MAC 주소로는 다른 종류의 네트워크와 통신할 수 없다.
LAN 내부에서 통신했던 것과 달리 LAN들은 서로 호환되지 않는 기술들을 사용할 수 있다.
따라서 다른 네트워크로는 직접 통신이 불가능할 수 있다.
예를 들어 이더넷은 유선 통신으로 구현된 LAN이지만 WLAN은 무선통신으로 구현되었으므로 이더넷에서 WLAN으로는 직접 통신할 수 없다.
이렇게 비호환 네트워크일 수 있는 다른 LAN과 통신하기 위해서는 새로운 규약(인터넷 프로토콜)이 필요하다.
인터넷 프로토콜은 호스트들과 라우터들이 데이터를 전송하는 방법을 규정한 것이며 우리가 사용하는 인터넷(Global IP Internet)은 IP Internet Protocol를 사용한다.
IP를 포함한 인터넷 프로토콜은 아래 두 가지 기본 기능을 가지고 있다.
1. 명명법 Naming scheme
호스트의 주소로 사용할 통일된 형식을 정의한다.
각 호스트는 internet 주소를 한 개 이상 가지고 있다.
IP에서는 IP 주소와 포트를 사용한다.
[[#11-3-1. IP 주소|IP주소에 대한 자세한 설명]]은 뒤에서 하기로 하고 일단은 IP에서 사용하는 주소라고만 하겠다.
1. 전달기법 Delivery mechanism
서로 다른 길이와 인코딩 방식의 데이터를 통일된 방식으로 묶기 위해서, 데이터 비트를 패킷(IP에서는 데이터그램으로도 부름)이라는 단위로 묶는 방법을 정의한다.
패킷은 패킷 크기, 소스 호스트 주소(IP 주소), 목적지 호스트 주소(IP 주소)를 포함하는 헤더를 데이터 앞에 붙여 구성한다.
![[Pasted image 20240817213654.png]]
(IP에서 데이터그램의 예)
IP를 통해 통신하는 모든 호스트들은 고유한 IP주소를 가지고 있다.
네트워크가 하나의 외부 IP를 공유하는 경우에는 네트워크 내 호스트들은 고유한 내부 IP를 가지고 있다.
네트워크 간 IP로 통신하는 방식:
다른 네트워크의 호스트와 데이터를 주고 받을 때엔 MAC 주소 대신 규약으로 정해진 주소(명명법, IP 주소)가 포함된 헤더를 데이터 앞에 추가하게 된다. 이를 데이터그램/패킷이라고 한다.
이 패킷을 네트워크 내에서 주고 받을 때에는, 하위 계층의 헤더(MAC 주소)가 추가로 붙게 되므로 실제 1계층에서 주고 받게 되는 데이터는 (프레임 헤더)+(패킷 헤더)+(패킷 데이터) 의 형태가 된다.
1. 호스트는 다른 네트워크로 데이터를 보내기 위해 목적지 IP주소를 기록한 패킷 헤더를 데이터에 추가하고, 라우터의 MAC 주소를 기록한 프레임 헤더를 더해 발송한다.
2. 라우터는 미리 다른 라우터들과 교신을 통해서 주변 네트워크들의 정보를 기록해둔 라우팅 테이블을 만들어 놓는다. 프레임을 수신하면 프레임 내 데이터그램 헤더에서 읽은 도착지 IP 주소를 라우터 테이블과 비교해 적절한 다음 경로의 MAC 주소로 발송한다(라우팅).
3. 이런 과정을 반복해 도착지 네트워크로 진입하게 되면, 라우터는 포트 번호[^11-8] 별로 할당된 내부 IP 테이블을 사용해 도착지 주소를 내부 IP로 변경한다(NAT[^11-6]).
4. 라우터가 내부 IP에 해당하는 MAC 주소로 프레임을 생성하고 적절한 물리포트를 결정하여 발송하면 네트워크 세그먼트로의 전달이 완료되고 이후에는 하위 계층(L2, L1)의 통신방식을 통해 호스트로 전달된다.
[^11-6]: 내부 네트워크의 호스트들은 사설(내부) IP 주소를 사용한다. 인터넷에 접속하기 위해서는 공인(외부) IP 주소가 필요하며, 하나의 공인 IP 주소를 사용하여 모든 내부 호스트가 외부 인터넷과 통신한다. NAT는 같은 공인 IP를 사용하더라도 포트 번호를 사용하여 내부 호스트들을 구분할 수 있게 하는 기술이다. 내부 호스트가 외부 인터넷에 패킷을 보내면, 라우터는 패킷의 출발지(내부 호스트) IP 주소를 공인 IP 주소로 변환한다. 이와 함께, 포트 번호도 변환하여 NAT 테이블에 기록한다(NAT 테이블). 라우터는 외부에서 오는 (공인 IP와 포트번호를 가진) 응답 패킷을, NAT 테이블을 참조하여 원래의 내부 IP 주소와 포트 번호로 변환하여 내부 호스트에 전달한다. 이 때 특정 포트 번호로 오는 패킷을 특정 내부 IP로 변환하여 보내도록(포워딩하도록) 변환하는 작업을 포트포워딩이라고 한다. 사용 중이거나 포트포워딩한 포트가 아닌 나머지 포트로 온 패킷을 모두 특정 내부 IP로 변환하여 보내도록 하는 것은 DMZ라고 한다.
[^11-8]: 포트 번호는 전송 계층(L4)에서 내부 호스트에 있는 애플리케이션이나 서비스를 식별하는 데 사용된다. 포트포워딩은 이런 전송 계층의 헤더를 조회하고 수정하여
네트워크 내에서 IP로 통신하는 방식
같은 기술을 사용하는 네트워크 안에서는 IP를 사용하지 않고도 통신할 수 있지만, 외부 네트워크와 같은 프로토콜로 통신하여야 하는 경우가 있을 수 있다.
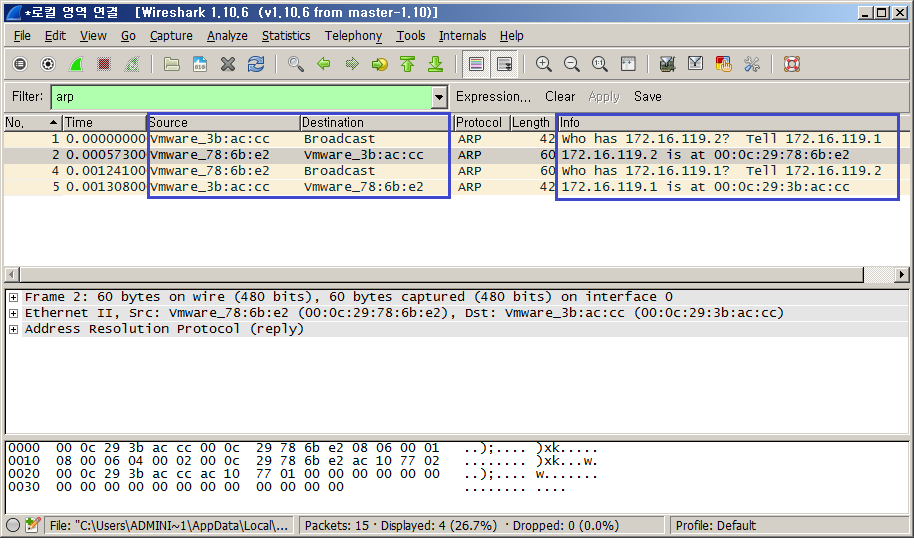
1. IP를 가진 호스트의 MAC 주소를 알아야하며, 이를 위해서 ARP 프로토콜을 사용한다. 발송하려는 호스트는 ARP 패킷으로 브로드캐스트[^11-5]로 IP주소를 가진 호스트의 MAC 주소를 요구한다. 해당 IP의 호스트가 패킷을 수신하면 자신의 MAC 주소를 회신한다. 이 정보는 ARP 테이블(캐시)에 저장되어 일정 시간동안은 ARP 요청을 다시 하지 않는다.
2. 하위 계층(L2, L1)의 통신방식과 같다. MAC 주소를 포함한 프레임 헤더를 붙여 물리 신호를 발송한다.
라우터 요약:
라우터는 IP 주소를 기반으로 패킷을 라우팅 테이블에 따라 최적의 경로로 전달한다. 즉, 네트워크 간의 경로를 결정(라우팅)한다.
브로드캐스트 도메인을 분리하고 각 브로드캐스트 도메인을 독립적으로 관리한다.
알아두기(게이트웨이)
게이트웨이는 일반적으로 다른 프로토콜의 두 네트워크 간에 프로토콜의 변환 기능을 수행하는 장치
즉, 이질적인 망을 연결시키는 개체(Entity)를 가리키는 일반적인 용어
TCP/IP에서 볼 때는 망간의 연결을 담당하는 '라우터'를 의미하기도 하나, 주로, 상위계층(L4-L7)에서 상이한 프로토콜들 간의 특수한 변환을 담당하는 서버를 의미함
11-2-2-3. UDP/TCP(L4)
UDP와 TCP는 모두 전송 계층에서의 프로토콜로, 전송 계층부터는 각 프로세스가 직접 통신할 수 있다.
하위 계층을 거쳐 호스트까지 도착한 데이터가 어떤 프로세스로 찾아가야 하는지 구분하기 위해서 포트 번호를 사용한다. 포트 번호는 16비트 길이의 부호 없는 정수이다.
예를 들어 웹서버가 80포트 번호를 할당했다고 할 때, 해당 호스트로 데이터를 보내면서 포트번호로 80을 입력하면 호스트까지 IP를 이용해 전송된 뒤, 웹서버가 있는 호스트는 포트번호를 확인해 웹서버 프로세스로 전달한다.
11-2-2-3-1. UDP
UDP User Datagram Protocol는 1980년에 정의된 전송 계층(L4)에서 동작하는 프로토콜이다.
IP는 호스트에서 호스트로 전송할 수 있었으므로 네트워크(L3) 계층에서 동작한다.
UDP는 프로세스에서 프로세스로 전달할 수 있으므로 전송 계층(L4)에서 동작한다.

UDP는 IP 데이터그램을 프로세스에서 프로세스로 전송하기 위해 IP 프로토콜에서 최소한의 기능만을 추가하였다.
UDP헤더에는 소스 포트번호, 도착지 포트번호, 데이터그램[^11-9] 길이, 체크섬만 존재한다.
IP에 호스트 자신의 주소를 목적지 IP를 사용하면, 도착지 포트번호를 가진 호스트 내의 다른 프로세스로 정보를 전송할 수도 있다.
상대편에서 메시지를 받을 준비가 되어있는지 확인하는 통신 과정을 정의하지 않았으므로 IP와 같이 단방향으로 정보를 전송한다.
전송 방식이 너무 단순해서 서비스의 신뢰성이 낮고, 데이터그램 도착 순서가 바뀌거나, 중복되거나, 심지어는 통보 없이 누락되기도 한다.
따라서 일반적으로 오류의 검사와 수정이 필요 없고 실시간성이 중요한 애플리케이션에서 사용한다.
[^11-9]: UDP도 단위로 데이터그램을 사용한다. IP 데이터그램과 구분이 필요한 경우에는 유저 데이터그램 user datagram이라고 표현한다.
11-2-2-3-2. TCP(L4)
TCP Transmission Control Protocol은 TCP/IP의 핵심 프로토콜 중 하나이다.
TCP는 UDP의 단점을 보완해 신뢰성, 순서 보장, 양방향성을 갖도록 설계되었다.
-
연결:
- 데이터 전송 전에 송신자와 수신자 간에 연결을 설정(3-way handshake)하고, 통신이 종료될 때 연결을 해제한다. 이 때의 연결은 물리적 실체가 아니라 서로 응답이 가능한 상황인를 확인하고 연결된 프로세스 간에만 통신이 이루어지는 논리적 연결이다.
- 3-way handshake: 연결 설정을 위해 세 단계의 과정을 거친다:
SYN: 클라이언트가 서버에 연결을 요청
SYN-ACK: 서버가 클라이언트의 요청을 확인하고 응답
ACK: 클라이언트가 서버의 응답을 확인
-
신뢰성:
데이터 전송 중 손실되거나 손상된 패킷은 재전송되며, 중복된 패킷은 제거되고, 수신된 데이터는 올바른 순서로 재조립된다.
데이터의 신뢰성을 보장하기 위해 응답 확인(Acknowledgment) 메커니즘과 타이머를 사용한다. -
흐름 제어 및 혼잡 제어:
TCP는 송신자와 수신자의 데이터 처리 속도에 맞추어 데이터 전송 속도를 조절한다.
네트워크 혼잡을 방지하기 위해 혼잡 제어 메커니즘을 사용한다. -
헤더 구조:
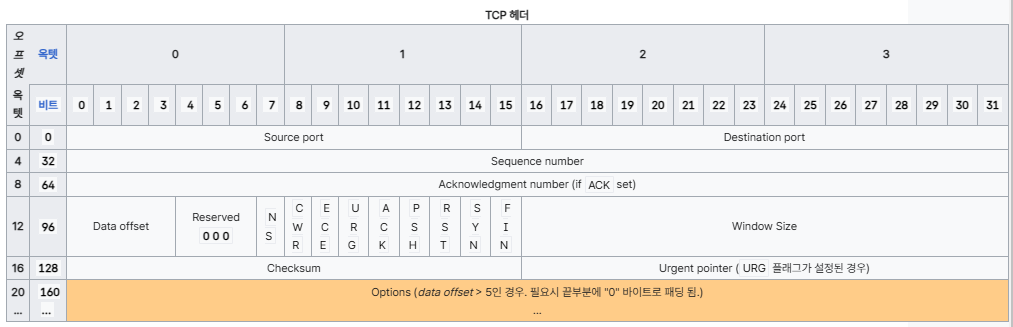
TCP 헤더는 최소 20바이트에서 최대 60바이트로, 다양한 제어 필드를 포함한다.
-
사용 사례:
웹 브라우징(HTTP/HTTPS): 웹 페이지를 로드할 때, 데이터가 손실 없이 순서대로 도착해야 하므로
이메일 전송(SMTP): 이메일의 신뢰성 있는 전송을 보장하기 위해
파일 전송(FTP): 파일이 손상되지 않도록
11-3. 글로벌 IP 인터넷
글로벌 IP 인터넷 Global IP Internet은 internet의 가장 유명한 구현체이다.
(이 절에서 인터넷은 글로벌 IP 인터넷을 가리킨다.)
각 인터넷 호스트는 TCP/IP 프로토콜을 통해 통신한다.
TCP/IP는 TCP와 IP라는 프로토콜을 중심으로 구성되는 여러 프로토콜의 집합(군, suite)으로 속하는 프로토콜의 수가 100개가 넘는다.
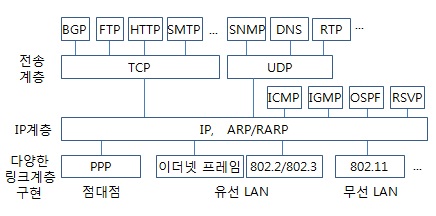 (TCP/IP 주요 프로토콜)
(TCP/IP 주요 프로토콜)
TCP/IP는 또한 인터넷(Internet)에서 사용되는 기본 통신 프로토콜로 특정 운영체제에 국한되지 않는다.
11-3-1. IP 주소
