
0. 환경설정
1) miniconda 설치 + 가상환경 생성
- https://docs.anaconda.com/free/miniconda/index.html 에서 운영체제 선택하고 설치
- Anaconda Prompt(Miniconda3) 실행
# 아래 명령어들로 정상 작동 확인 conda --version # 버전 확인 conda update conda # 최신 버전 업데이트 conda env list # conda 환경(가상환경) 확인# conda 환경 생성 conda create -n <가상환경이름> python=3.8 # env(가상환경) 생성 conda activate <가상환경이름> # env 활성화 conda deactivate <가상환경이름> # env 비활성화 conda env remove -n <가상환경이름> # env 삭제
2) Jupyter Notebook (위에서 생성한 가상환경에서 진행)
# Jupyter Notebook 설치 conda install -y jupyter# 패키지 설치 conda install -y ipython conda install -y matplotlib conda install -y seaborn conda install -y pandas conda install -y sklearn conda install -y xlrd# Jupyter Notebook 실행 jupyter notebook # 기본 브라우저에서 웹 jupyter 열림
- New-> notebook ->
import this-> 실행 으로 설치 확인
3) matplotlib 한글 설정
import matplotlib.pyplot as plt from matplotlib import rc %matplotlib inline rc("font", family='Malgun Gothic')plt.title("데이터분석")
4) VS Code
- 워크스페이스에서 새파일을
파일명.ipynb로 만들고, 오른쪽 상단 커널을 앞서 만든 가상환경(env)로 설정- 만약 env가 나타나지 않는다면,
Ctrl + Shift + P를 누르고인터프리터 선택에서 직접 선택# Python 에서 MySQL 사용하기 위한 Driver 설치 (터미널) conda activate <가상환경이름> pip install mysql-connector-python# 새로운 쉘에서 설치 확인 import mysql.connector# MySQL 에 연결 mydb = mysql.connector.connect( host = "<hostname>", # AWS 연결시 엔드포인트 입력 port = <port>, # AWS 연결시 user = "<username>", password = "<password>", database = "<databasename>" # 특정 DB 접속 )# 사용 후에는 꼭 연결 끊어주기!!! mydb.close()
1. Python 에서 SQL 쿼리 실행
# 위 mysql.connector.connect(...)
mydb = mysql.connector.connect(
host = "database-1.crsuccoo4wem.ap-southeast-2.rds.amazonaws.com", # AWS 연결시 엔드포인트 입력
port = 3306, # AWS 연결시
user = "admin",
password = "********",
database = "zerobase" # 특정 DB 접속
)
# 1. 쿼리문 자체를 실행하는 방법
cur = mydb.cursor()
cur.execute(<실행할 query>);
# 2. 쿼리문 파일을 읽어 실행하는 방법
cur = mydb.cursor()
sql = open("<SQL파일이름>.sql").read()
cur.execute(sql)
# 3. 쿼리문 파일 내 쿼리가 여러 줄 존재하는 경우
cur = mydb.cursor(buffered=True) # 읽어올 데이터 많다면
sql = open("test04.sql").read()
# 여러 쿼리를 수행할 때 multi 옵션
for result in cur.execute(sql, multi=True):
# 결과 행(SELECT)을 가지고 있는지
if result.with_rows:
# 모든 결과 행(SELECT)을 반환
print(result.fetchall())
else:
# 마지막으로 실행된 쿼리를 문자열로 반환
print(result.statement)
mydb.commit()2. Python 으로 CSV 파일 INSERT 하기
# 1) Pandas로 csv 읽어오기
import pandas as pd
df = pd.read_csv("police_station.csv", encoding='euc-kr')
df.head()# 2) AWS DB에 연결
mydb = mysql.connector.connect(
host = "database-1.crsuccoo4wem.ap-southeast-2.rds.amazonaws.com", # AWS 연결시 엔드포인트 입력
port = 3306, # AWS 연결시
user = "admin",
password = "********",
database = "zerobase" # 특정 DB 접속
)
# 3) 커서와 쿼리(INSERT문) 작성
cur = mydb.cursor(buffered=True)
sql = "INSERT INTO police_station VALUES (%s, %s)"
for i, row in df.iterrows(): # 데이터프레임의 행(인덱스, 데이터)을 반복
cur.execute(sql, tuple(row)) # 튜플형태로 변환한 데이터를 '%s' 에 넣어주기
print(tuple(row))
mydb.commit()# 4) 결과 행(SELECT문) 확인하기
cur.execute("SELECT * FROM police_station")
result = cur.fetchall()
for row in result:
print(row)# 5) DataFrame 형태로 변환해보기
df = pd.DataFrame(result)
df.head()참고) 파이썬 자료구조
| 자료구조 | 설명 | 예시 |
|---|---|---|
| 리스트(List) | 다양한 타입의 아이템을 포함할 수 있는 변경 가능한(mutable) 데이터 구조. 아이템 순서가 유지됨. | my_list = [1, 'hello', 3.14] |
| 튜플(Tuple) | 다양한 타입의 아이템을 포함할 수 있지만, 생성 후에는 변경할 수 없는(immutable) 데이터 구조. 아이템 순서가 유지됨. | my_tuple = (1, 'hello', 3.14) |
| 딕셔너리(Dictionary) | 키와 값의 쌍으로 이루어진 데이터 구조. 아이템 순서가 유지되지 않음. | my_dict = {'name': 'John', 'age': 28} |
| 셋(Set) | 중복을 허용하지 않는 아이템의 집합을 나타내는 데이터 구조. 아이템 순서가 유지되지 않음. | my_set = {1, 2, 3} |
| Pandas Series | 1차원 배열 형태의 데이터 구조. 각 아이템에 연결된 인덱스에 의해 정의됨. | s = pd.Series([1, 3, 5, np.nan, 6, 8]) |
| Pandas DataFrame | 2차원 배열 형태의 데이터 구조. 열과 행으로 이루어져 있으며, 다른 타입의 열을 가질 수 있음. | df = pd.DataFrame({'A': np.random.rand(4), 'B': pd.Timestamp('20230102'), 'C': pd.Series(1, index=list(range(4)), dtype='float32')}) |
3. PRIMARY KEY, FOREIGN KEY
- PRIMARY KEY(기본키) : 테이블마다 꼭 가지고 있으며,
각 레코드를 식별하게 해주는 NULL이나 중복 아닌 고유값
# 기본키 생성(테이블 생성과 동시에)
CREATE TABLE person(
pid INT NOT NULL,
name VARCHAR(16),
age INT,
sex CHAR,
PRIMARY KEY (pid)
);# 기본키 삭제(단 하나니까, 지정X)
ALTER TABLE person
DROP PRIMARY KEY;# 기본키 지정(테이블 생성 이후)
ALTER TABLE person
# CONSTRAINT 를 사용하면 제약조건 참조,수정,삭제 등 용이!
ADD CONSTRAINT PK_person PRIMARY KEY (pid); - FOREIGN KEY (외래키) : 한 테이블을 다른 테이블과 연결해주는 역할을 하며,
참조되는 테이블의 '기.본.키' 여야만 함!
# 외래키 지정(테이블 생성과 동시에)
CREATE TABLE orders(
oid INT NOT NULL,
order_no VARCHAR(16),
pid INT,
PRIMARY KEY (oid),
# CONSTRAINT FK_person # 생략가능하나, 참조,수정,삭제 시 따로 이름을 확인해야함
FOREIGN KEY (pid) REFERENCES person(pid)
);(Key 항목에 'MUL' 로 표시되어 있음!)
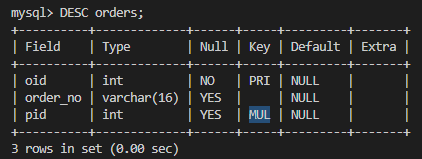
# 이렇게 자동 생성된 CONSTRAINT 이름 확인 후 참조,수정,삭제 해야함
SHOW CREATE TABLE orders# 외래키 삭제(지.정.!)
ALTER TABLE orders
DROP FOREIGN KEY <CONSTRAINT 이름>;# 외래키 지정(테이블 생성 이후)
ALTER TABLE orders
ADD FOREIGN KEY (pid) REFERENCES person(pid);
🖐