✅ 논문 링크 : [Time-Series Anomaly Detection Service at Microsoft](https://arxiv.org/pdf/1906.03821.pdf)
논문을 소개하고자 하는 이유
- 앞으로 Anomaly Detection 스터디에서 내가 발표한 내용을 꾸준히 정리할 예정
- 회사에 Deep Learning 관련한 End-to-end 시스템이 아직 없어서, 좋은 벤치마킹 사례인 Microsoft의 시계열 이상탐지 모델과 서빙 과정을 배우기 위함
- Spectral Graph Convolution에서 FFT 관련해서 공부중이었는데, 시계열 이상탐지에 FFT 관련한 모델을 적용해본 사례여서, 구현체를 보면서 학습해야지!
Abstract
- 해당 논문에서는, 시계열 비정상 탐지 Pipeline과 비정상 탐지를 위한 알고리즘을 소개
- Microsoft에서 서빙하는 시계열 이상탐지 Pipeline은 크게 3가지로 모듈로 구성
- Data Ingestion
- Experiment Platform
- Online Computing
- 시계열 이상탐지 모델 서빙을 위해, Spectral Residual & CNN 결합한 알고리즘 제안
- 해당 논문은 Visaul Saliency 도메인에서 활용하는 SR을 시계열 이상탐지에 처음으로 적용
- MS에서 제공하는 시계열 탐지 접근은 Public Datasets과 MS Data에서도 좋은 성능을 보여줌

Introduction
- 시계열 이상탐지를 위한 서비스를 설계하는 것은 많은 Challenges가 있음
-
(1) 레이블된 데이터의 부족
- 시스템은 수백만개의 시계열을 동시에 처리해야하는데, 사용자가 매시간 시계열의 비정상 데이터를 레이블링 할 수 없음
- 시계열 데이터의 분포는 지속적으로 변함
- 따라서, Supervised model을 실제 서비스 환경에서 사용하기는 불충분함
-
(2) 일반화
- 시계열 패턴에 대한 정형적인 카테고리는 존재
- 하지만, 현재 존재하는 패턴이 다른 시계열 패턴을 일반화하는데 충분하지 않음
- 따라서, 더 나은 일반화를 보여주는 방법을 찾아야함

-
(3) 효율성
- Business applications에서 거의 실시간으로 Large Scale Data를 처리해야 함
- 특히, 분단위의 시계열에서는 이상탐지과정이 제한된 시간내에 마무리 되어야 함
- 따라서, 시간 효율성은 실시간 시계열 이상탐지에 있어서 필수 전제조건임
-
- 본 논문에서는 효율적인 Unsupervised 알고리즘인 SR model을 시계열 도메인에 접목시켜 사용
- 위 논문의 Contribution
- Visual Saliency Domain의 SR 모델을 시계열 이상탐지에 적용 (F1-score 기존 대비 20% 향상)
- 이상탐지에 SR + CNN 결합한 모델을 사용함
- SR 모델에서 나온 ouput (synthetic을 CNN에 적용하는 방식)
- SR 모델의 ouput에 따라, 이상탐지(판별)이 더 쉬워져, 자동으로 생성된 이상치를 통해 CNN을 학습
→ 단순히 SR모델을 적용했을 때보다, 더 나은 성능
→ 수동으로 레이블링한 데이터가 없을 때도 SOTA의 성능을 보여줌
- 앞서 소개한, 일반화 & 효율성 측면에서도 더 실용적인 Solution
System Overview
- Data Ingestion
- 여러가지 Data Sources로 부터 Ingestion (Azure storage, DB, streaming data 등)
- Ingestion Worker : 정해진 Granularity (day, hour, minute)에 따라, 시계열을 업데이트 (얼마나 주기적으로 Data를 Feeding 시킬 건지를 담당하며 Kafka, fluxDB에 저장)
- Online Compute
- Anomaly Detection Processor : 각 시계열 마다 비정상을 탐지
- Smart Alert Processor : 비정상 데이터를 다른 시계열 데이터로 부터 연관시키며, 이에 따른 incident report를 생성함
- Experimentation Platform
- Anomaly Detection Performance 측정을 위한 온/오프라인 AB testing 환경 배포
- Labeled Data는 시계열 이상탐지 모델을 Evaluation하는데 사용
- 실험환경은 Azure Machine learning 서비스에 만들어졌음
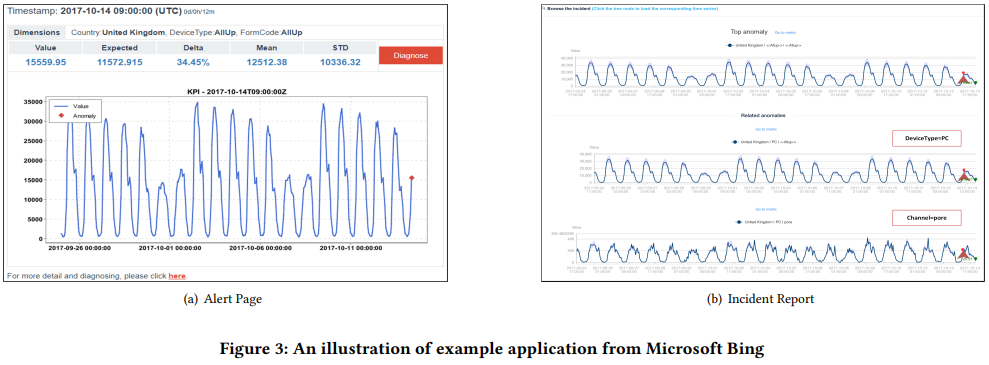
Applications
- (a) : Email Alert / (b) : Incident Reports / 기타 : Outlook anti-spam
Methodology
- 시계열 이상탐지에서 우리가 해결하고자 하는 목표

- Large Scale Data에서 레이블된 데이터를 온라인으로 수집하는 것은 상당히 어려운 영역
- Labeled Data 수집에 대한 Trade-off로, 본 논문에서는 SR-CNN 방식을 제안
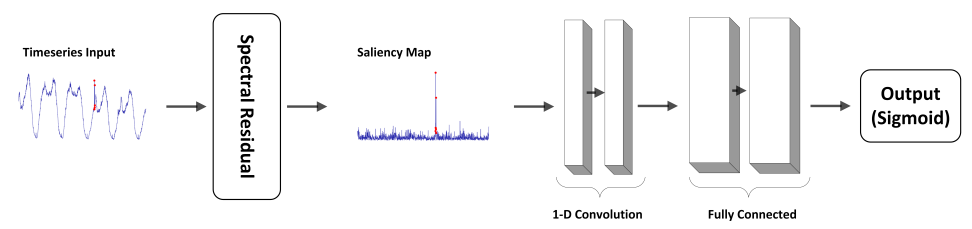
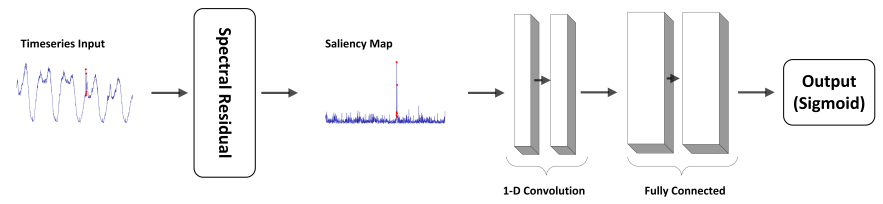
1) SR(Spectral Residual)
- SR 알고리즘은 크게 3가지 방법으로 구성됨 (개인적으로는 Encoder-Decoder 구조 느낌)
- (1) Spatial Domain Data를 퓨리에 변환을 이용해서, 로그 크기의 Spectral Domain으로 변환
- (2) Spectral Residual을 계산
- (3) 역퓨리에 변환을 통해, 시퀀스를 다시 Spatial Domain으로 변환
- Spectral Residual은 input data에 대한 Compressed representation
- 마지막 Inverse Fourier Transform을 통해, 결과 시퀀스는 Saliency Map

- 아래 그림의 경우, 원래 시계열 데이터를 SR 알고리즘을 통해, Saliency Map으로 변환
- Saliency Map을 통해, 더 쉽고 정교하게 Anomalous point에 대해 Annotation 가능
- Threshold를 도입해, Anomaly points를 annotation하는 방법을 사용

- 실제, FFT (Forward Fourier Transformation) 계산은 시계열의 sliding window으로 수행됨
- 해당 연구에서는 SR 알고리즘이 낮은 잠재성을 (low latency) 가지는 이상 포인트를 찾기 위해, input sequence를 SR model에 넣기전, 몇개의 estimated points를 추가함 → SR 알고리즘은 anomaly point가 sliding window 중앙에 위치한다면, 더 잘 작동함
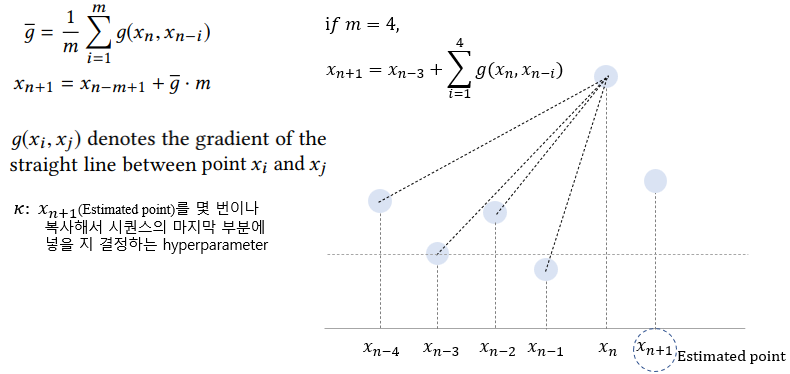
- 필요한 Hyperparameter → Empirical하게 설정하며, 해당 결과는 논문에서 진행한 실험에서 Robustness를 가짐
- Sliding window size (ω) = 1-D CNN filter size
- Estimated points number (κ)
- Anomaly detection threshold (𝜏)
2) SR-CNN
-
앞서 소개한, SR 모델만 단순하게 적용한다면, 정교함이 떨어지며 naive하다는 단점이 존재
-
SR Model 보완 → 잘 만들어진 Synthetic data를 바탕으로 Discriminative model (CNN) 학습
-
Synthetic data 생성 방법
- Saliency maps에 anomaly points를 주입하며(Injection) 생성할 수 있음 (Injection value)
- 인위로 생성된 데이터는 Evaluation data에 포함되지 않아야 함
- Injection된 비정상 데이터는 비정상으로 레이블하며, 나머지는 정상 데이터로 레이블함
-
해당 논문에서는 Synthetic 데이터를 생성하기 위해, 아래 과정을 거치게 됨
- (1) 시계열 데이터에서, 랜덤하게 data points를 선정
- (2) 기존 data point를 대체하기 위해 injection value를 계산
- (3) Injection value로 대체된 Saliency map를 얻음
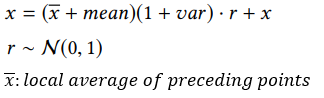
- 해당 논문은 Saliency detection에서 보편적인 Supervised learning으로 사용되는 CNN을 선택
- SR-CNN Architecture
- Input : Saliency map (기존 raw 시계열 데이터를 사용하지 않음) → Labeled 데이터 부족 문제를 해결 & Anomaly Annotation을 쉽게 만들 수 있음
- Loss function : Cross entropy
- Optimiser : SGD
- Input : Saliency map (기존 raw 시계열 데이터를 사용하지 않음) → Labeled 데이터 부족 문제를 해결 & Anomaly Annotation을 쉽게 만들 수 있음
Experiments
- Public Dataset (KPI, Yahoo)와 Microsoft 내부의 데이터 셋을 사용해 실험을 진행
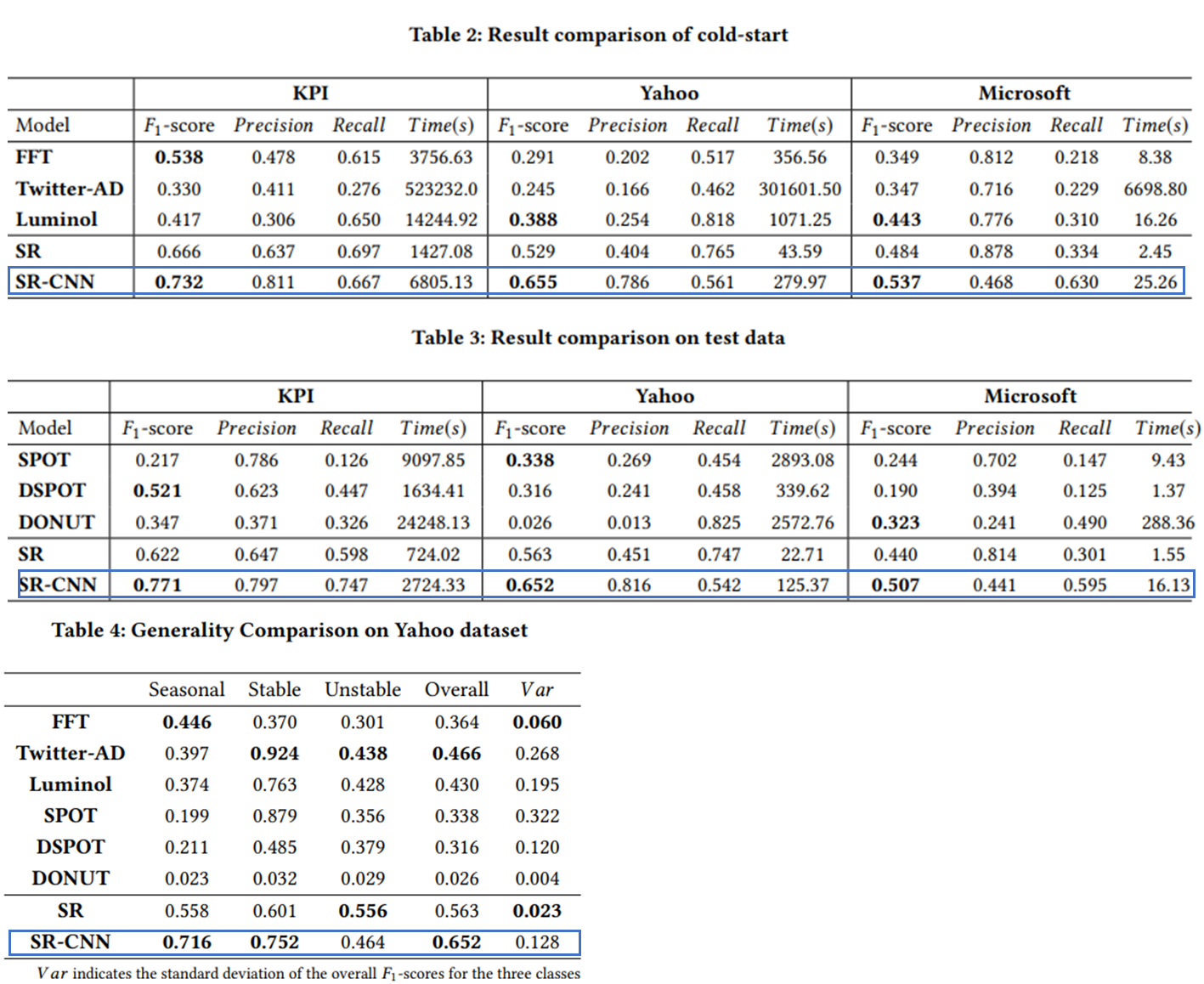
- Evaluation Metric : 크게 3가지 Accuracy, Efficiency, Generality를 고려함
- Accuracy : Precision, Recall, F1-score로 평가
- 실제 서비스 환경에서는, 운영자가 point-wise한 metrics을 신경쓰지 않음
- 따라서, 해당 논문에서는 좀 더 단순한 Evaluation Strategy를 도입 (Segment & Delay)
- Anomaly Segment에 있는 어떤 데이터가 알고리즘에 탐지 됨 & 해당 데이터의 delay가 Anomaly segment 시작점으로부터 k보다 작으면, Segment 올바르게 탐지된 것으로 봄

- True Positive Segment인 경우, alert delay는 segment안에서 첫번째 포인트와 첫 번째 감지 포인트의 시간 차이가 됨
- Efficiency : 시계열 이상탐지 모델 서빙 시, 중요한 요소
- 3개의 Datasets에 대해서, 각 모델별로 Execution time을 비교
- Generality : 이상탐지 모델은 다양한 타입의 시계열 패턴을 핸들링 할 수 있는 능력이 필요
- 시계열 데이터를 3가지 클래스로 나눈 후 (Seasonal, Stable, Unstable) 각 클래스에 대해 F1-score를 비교
- Accuracy : Precision, Recall, F1-score로 평가
- Results : SR-CNN을 다른 SOTA 시계열 이상탐지 알고리즘과 비교한 결과
참고한 Reference
1) Comprehensive Review of Visual Saliency

게임회사에서 데이터분석을 하고 있는 분석가의 블로그