Django ORM을 이해하기 위해 아래 영상의 도움을 받았습니다.
Django ORM (QuerySet)구조와 원리 그리고 최적화전략 - 김성렬 - PyCon Korea 2020
Django ORM의 특성
Lazy Loading
QuerySet의 선언 시점과 SQL 호출 시점은 다르다.

Django ORM은 데이터가 정말로 필요한 시점(evaluation)에만 DB에 접근 한다.

Caching
Django ORM은 한번 DB로부터 불러온 데이터(인스턴스)를 _result_cache 속성에 리스트 형태로 저장한다.
users = User.objects.all()
print(users._result_cache)
# None
len(users) # Evaluation 발생! ★SQL 호출 + Caching 동작★
# (0.001) SELECT `users`.`id`, `users`.`nickname`, `users`.`kakao_id`, `users`.`kakao_email` FROM `users`; args=()
# len(users) ==> 41
print(users._result_cache)
# [<User: User object (1)>, <User: User object (2)>, <User: User object (3)>, <User: User object (4)>, <User: User object (5)>, <User: User object (6)>, <User: User object (7)>, <User: User object (8)>, ...]이렇게 쿼리셋의 데이터(인스턴스)들이 메모리에 저장되면, SQL 호출을 통해 DB에 다시 접근하는 일 없이 _result_cache 내부의 데이터를 사용하게 된다.
users[0].nickname
# 'Jun01'경우에 따라서는 코드의 순서를 바꾸는 것만으로도 미리 캐싱한 데이터를 활용하여 SQL 호출을 줄이는 효과를 낼 수도 있다.
하지만... N+1 Problem
Django ORM의 이런 특성은 DB에 접근하지 않고도 여러 쿼리 조건을 쌓을 수 있다는 장점이 있지만, 개발자의 의도와 어긋나 SQL 호출이 불필요하게 여러 번 일어나는 문제가 발생할 수도 있다.
아래와 같이 쿼리셋에 반복문을 걸어 정참조 관계 테이블의 정보를 불러오는 경우를 알아보자.
bookmarks = Bookmark.objects.all() # SQL 호출 X
print(bookmarks._query) # evaluation 때 캐싱할 데이터의 SQL
# SELECT `bookmarks`.`id`, `bookmarks`.`posting_id`, `bookmarks`.`user_id` FROM `bookmarks`
for bookmark in bookmarks:
print(bookmark.user.nickname)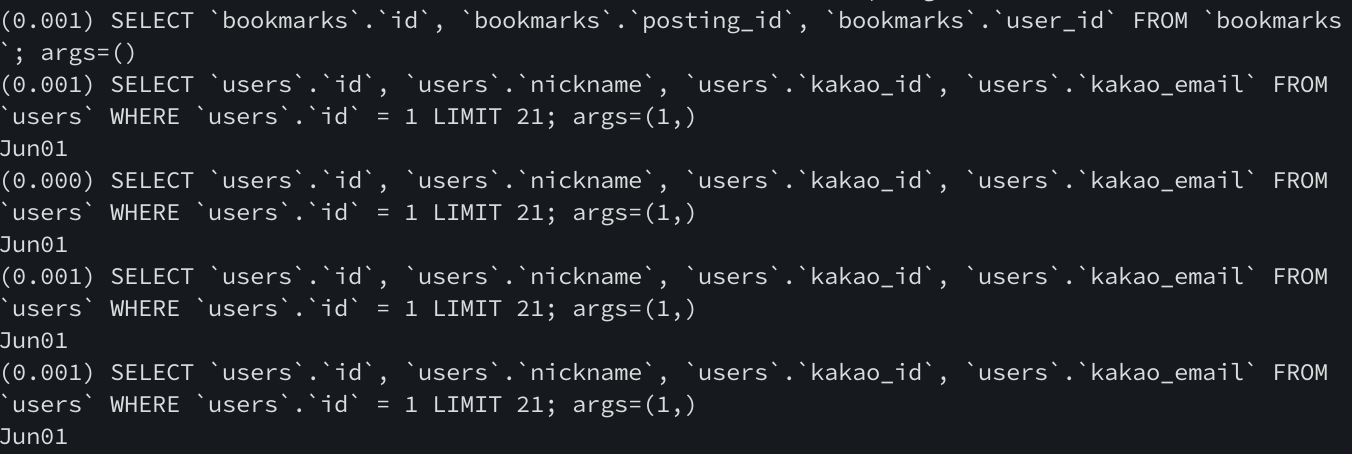
위처럼 반복문이 돌 때마다 SQL을 호출하는 비효율적인 동작을 목격할 수 있다..
for문에 bookmarks가 들어가 iterator가 생성될 때, bookmarks._query에 저장된 SQL을 호출하여 DB로부터 해당 데이터를 받고 이를 _result_cache에 저장한다.
==> SQL 1번
그리고 각각의 반복에서 ForeignKey 필드인 user_id를 통해 user 테이블로부터 데이터를 가져오고자 하지만(bookmark.user.nickname), 이 데이터는 _result_cache에 캐싱되는 단계에서 같이 저장되지 않았다.
ORM은 bookmarks SQL 호출 시점에서는 그 이후의 시점(user.nickname 정보를 필요로 하는 시점)을 미리 판단할 수 없다. 따라서, 그 정보가 필요한 시점인 각각의 반복에서 SQL 호출(Lazy Loading)이 되기 때문에 매번 호출이 발생할 수밖에 없는 것이다!
==> SQL N번
이렇게 총 N+1번의 SQL 호출이 발생하는 비효율적인 동작을 ORM의 N+1 문제라고 한다.
Eager Loading 전략
N+1 문제를 해결하기 위한 방법으로 Django ORM은 select_related(), prefetch_related() 메서드를 통해 필요한 데이터를 미리 캐싱(Eager Loading)할 수 있도록 지원한다.
요약
-
select_related() : JOIN을 통해 한 개의 쿼리로 데이터 즉시 로딩. 정참조 관계에서만 사용 가능
-
prefetch_related() : 추가 쿼리를 수행하여 데이터 즉시 로딩. Prefetch 클래스 queryset 옵션을 통해 쿼리 조건 customization 가능. 정참조/역참조 다 사용 가능하나, 웬만하면 정참조는 select_related()를 사용할 것
select_related()
위 N+1 문제를 일으키는 사례에 select_related를 적용해보자.
bookmarks_2 = Bookmark.objects.all().select_related('user')
print(bookmarks_2._query)
# SELECT `bookmarks`.`id`, `bookmarks`.`posting_id`, `bookmarks`.`user_id`,
# `users`.`id`, `users`.`nickname`, `users`.`kakao_id`, `users`.`kakao_email` FROM `bookmarks`
# INNER JOIN `users` ON (`bookmarks`.`user_id` = `users`.`id`)FK 필드를 통해 'user' 모델의 테이블을 JOIN하여 두 테이블의 정보를 모두 불러온다는 것을 SQL을 통해 확인할 수 있다.
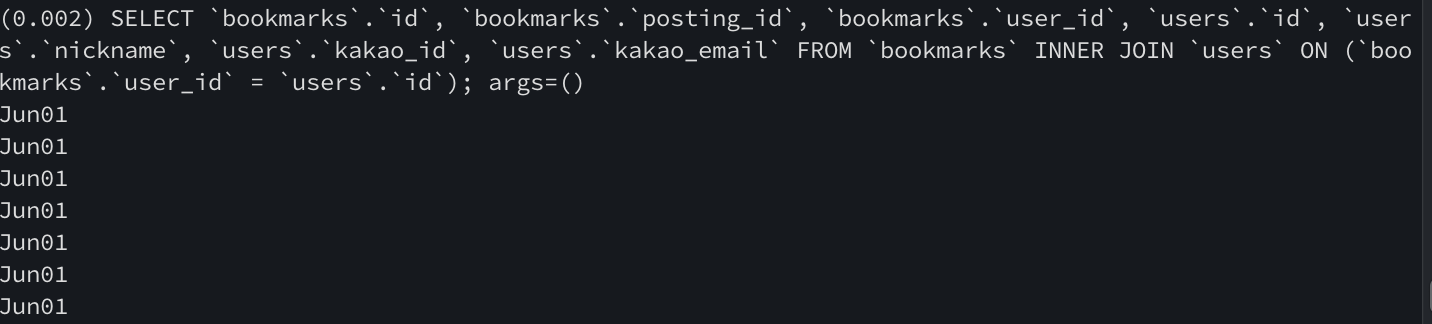
반복문을 실행할 때에도, 처음으로 bookmarks_2에 캐싱이 되는 SQL 호출 이후에는 SQL 호출이 일어나지 않는다는 것을 확인할 수 있다.
prefetch_related()
안타깝게도 select_related() 메서드로는 'XXX_set' 를 통해 접근할 수 있는 역참조 모델 테이블에 접근할 수 없다. 대신 prefetch_related()를 통해 추가 쿼리를 실행해야만 한다.
이렇게 지정한 추가 쿼리는 _prefetch_related_lookups에 타겟으로 저장되는데, _result_cache에 찾고자 하는 데이터가 없을 경우, 여기에 있는 추가 쿼리셋을 수행한다.
users = User.objects.all().prefetch_related('bookmark_set')
print(users._query)
# SELECT `users`.`id`, `users`.`nickname`, `users`.`kakao_id`, `users`.`kakao_email` FROM `users`
print(users._prefetch_related_lookups)
# ('bookmark_set',)
len(users) # evaluation 발생!
위와 같이 _query에 저장된 user SQL문 하나, 이후 _result_cache에 저장된 데이터의 역참조 관계를 따라 _prefetch_related_lookups에 저장된 bookmark SQL문 하나, 총 2개의 쿼리가 실행된 것을 확인할 수 있다.
prefetch_related() 메서드는 Prefetch 객체를 통해 조금 더 섬세하게 다룰 수도 있다.
q = Bookmark.objects.filter(user_id__lt=19)
users = User.objects.prefetch_related(Prefetch('bookmark_set',to_attr='oldbie_bookmarks', queryset=q))
len(users) # evaluation 발생!
위 추가 쿼리 SQL문을 보면, queryset 옵션으로 q라는 변수를 통해 미리 필터링한 쿼리가 적용된 것을 볼 수 있다.
to_attr 옵션은 지정한 이름으로 이렇게 prefetch한 추가 쿼리셋을 메인 쿼리의 각 인스턴스의 속성으로 부여한다.


추가 쿼리의 조건에 해당하지 않은 데이터는 캐싱되지 않은 것을 확인할 수 있다.

👍🏼👍🏼👍🏼👍🏼👍🏼