따사로운 5월 수현이의 성장 일기입니당 :)
하루하루 코딩을 하며 어떤 멍청한 일과 잘한 일이 있었는지 회고해보는 시간을 가져보아요 ...~
⭐ 5월 9일 금요일
오늘 한 일
-
api/에image_generation.py파일을 두었다고 생각했는데,, 알고보니api/__pycache__/에 파일을 저장해둔 것이었다..from api.image_generation import __했을 때 자꾸 import 에러가 떠서 개짜증난 상태였는데, 내 실수였다. 허허 -
전날 번역 라이브러리 잘못 설치했다가 버전 호환 문제로 이전에 백업해둔 코드를 다시 가져와서 수정하였지만 여전히 해결되지 않았고, 여러 차례 이것저것 실행해본 결과 얻어낸 원인은 PowerShell이 내부적으로 경로를 바꾸지 않아 가상 환경 안의 Python이 아니라 시스템 전역의 Python이 실행된다는 것이었다. uvicorn 또한 사용되는 위치가 가상환경인지, 시스템 전역 환경인지 알아야 한다.
-
openai와 httpx 버전 충돌이 잦았는데 openai는 1.3.9를, httpx는 0.27.0을 사용해야 충돌이 없었다.
-
기본 제공 단어장에서 이미지 프롬프팅할 때 한국어가 아닌 영어로 번역된 문장이 필요하여 데이터베이스의
basic_word테이블에association_kor칼럼을 추가하였다. -
샘플 데이터 50개를 통한 이미지 생성 테스트 → 샘플 데이터 5개만 진행 ..
⭐ 5월 12일 월요일
오늘 한 일
-
메인 서버의 기본 제공 단어장 기능을 만들었다. 네 개의 API를 생성하였으며, 구성은 다음과 같다.
① 메인 화면에서 기본 제공 단어장 버튼을 클릭했을 때 뜨는 단어장 목록 조회
② 기본 단어장의 목록을 클릭했을 때 뜨는 day 목록 조회
③ day에 들어갔을 때 해당 day에 저장된 단어들 간단히 조회
④ "학습 시작"을 눌렀을 때 차례로 단어들의 상세 정보 (발음, 연상 예문, 이미지, 영어 예문, 한글 번역 예문 등)를 출력
이렇게 네 가지 기능을 한다. -
①에서는 단어장 목록에 해당 목록에 저장돼있는 day 리스트의 목록 개수를 출력해야 했다. 이때 Spring Data JPA의 쿼리 메서드 방식을 사용했다. JPA가 메서드 이름을 분석하여 자동으로 쿼리를 만들어주는 방식이다.
By뒤에 테이블명과 칼럼명을 적어주면 된다.
int countByBasicBasicId(Long basicId);
=SELECT COUNT(*) FROM daylist WHERE basic.basic_id = :basicId
(②에서 daylist에 저장된 단어 개수를 출력하는 과정도 동일하게 진행하였다.) -
④에서 필요한 데이터는 단어, 의미, 발음, 연상 예문 등이었는데, 여기서 단어와 발음 칼럼은 단어의 공통 정보를 저장하는
word_info테이블에 있어,dayword에서 참조하고 있는basic_word_id와daylist_id외래키를 통해 접근하였다. -
③에서 daylist에 해당하는 단어 목록을 조회할 때 쓴
findAllByDaylistDaylistId()메서드를 ④에서도 사용하였고, 이 메서드를 통해daylist_id에 해당하는 단어 목록을List<Daylist>형태로 받아왔고, 이Daylist타입 리스트를 통해basic_word와word_info테이블에 접근하여, 단어의 상세 데이터들을 반환하였다. -
단어 공통 정보 테이블엔 세 개 국가의 발음 기호(미국, 영국, 호주)가 저장되어 있으며, 사용자로부터 API로
country를 전달 받아 해당하는 국가에 발음 기호를 반환하도록 구현하였다. 이 때는switch-case문을 사용하였다.
다음에 해야 할 것
클라이언트로부터 단어장 접속 시간을 받아왔을 때daylist테이블의latest_accessed_at칼럼을 UPDATE 해야 한다.
⭐ 5월 13일 화요일
오늘 한 일
-
클라이언트로부터 단어장 접속 시간을 받아와
daylist테이블의latest_accessed_at칼럼을 UPDATE 후daylist테이블 목록을 조회한다. 컨트롤러에서 RestAPI 메서드를GET대신PATCH로 변경하였다.daylist객체 전체를 수정하는게 아니라, 필드 하나만 수정하기 때문에PATCH를 사용하였다. 엔드포인트에서 주소를 통해 전달받는 방식이 아니기 때문에 JSON 형태로 받아온다. -
AI 서버의 이미지 생성 파트를 진행하려 했다. Stable Diffusion WebUI를 로컬에 설치하던 중 로컬 API 키를 발급받아도 클라우드 환경과 마찬가지로 WebUI 실행 시에만 API 키가 활성화된다는 사실을 뒤늦게 알아버렸다. 멘탈이 쿠쿠다스가 되던 중 ... DALLE3 API는 아직도 사용 못하는지 찾아봤다. 구글에 검색해보기로는 DALLE3 API를 사용해서 이미지 생성하는 코드가 분명히 나와있음에도 챗 GPT는 아직 DALLE2 API만 사용 가능하다고 했다. 한 달 전에도 모델명만
dall-e-3으로 변경하여 시도해보았지만 계속되는 실패에 2를 사용해 프로젝트를 진행하였다. -
유튜브에 검색해보니 DALLE3 API를 통한 이미지 생성 영상들이 있었다. 하나 들어가서 속는 셈 치고 한 번 더 시도해보았다. 아니 근데 웬걸 !!!! 이번엔 생성이 됐다 !!! 이미지 크기 때문이었는지 뭔지 (내 실수였겠지만) 아무튼 DALLE3을 쓸 수 있다니 감격스러웠다. 왜냐믄 DALLE2는 이미지 생성을 그지 같이 하거덩요 .. 개못쌩기게 !!
-
아무튼 내일은 DALLE2 + SD 흐름으로 흘러가던 AI 서버 쪽을 DALLE3만을 사용해서 최종 이미지를 저장하도록 수정해야겠다.
⭐ 5월 14일 수요일
- 오늘은 DALLE3 API를 사용한 AI 서버 수정 작업을 진행하였다. 생성된 이미지를 보완하기 위해 스타일 프롬프트와 네거티브 프롬프트를 살짝 수정하였다. 샘플 데이터 50개를 완성해보려했지만, 프롬프팅 시 검열되는 예문들이 있어서 실패했다. 내일은 예문이 검열에 걸릴 경우 일반 영어 예문으로 프롬프팅 되도록 코드를 추가해봐야겠다.
⭐ 5월 15일 목요일
-
샘플 데이터 마저 완성했다. 이미지 생성도 다 돈이라서 200장만 만들었다. 코딩보다는 샘플 데이터 만드는 데 시간을 많이 썼다.
-
엉덩 언니랑 잡담하다가 문득 생각난 사업 아이템에 대해 떠들었다. 실현 가능성은 없지만 ㅋㅋㅎ 공부 중에 나누는 뻘소리 잡담은 재미있었다. 일명 DTA라고 Digital-To-Analog의 준말이다. STT(Speech-to-Text) & TTS(Text-to-Speech)에서 따왔다. 자세한건 다 언니 머리에서 나온거라 기억이 안 난다. 아무튼 언젠가 실현할 수 있기를 . . . . .
⭐ 5월 20일 화요일
-
영단어장의 발음 교정 기능에 활용할 MS Azure STT를 사용해보았다. 엘사 스픽처럼 사용자의 발음을 운소 단위로 잘라 어느 부분이 부족한지, 어떻게 발음하면 더 좋은지 피드백을 출력하고 싶지만 MS Azure STT에는 운소 단위의 발음 점수는 제공해도 피드백까지는 제공하지 않았다.
-
STT 사용 시 반환 받는 데이터는 아래와 같다.
{
"word": "danger",
"answerPhonetic": "/ˈdeɪndʒər/",
"userPhonetic": "Danger.",
"overallScore": {
"accuracy": 93.0,
"fluency": 100.0,
"completeness": 100.0,
"total": 95.8
},
"phonemes": [
{
"symbol": "d",
"score": 87.0,
"feedback": "Good"
},
{
"symbol": "ey",
"score": 100.0,
"feedback": "Excellent"
},
{
"symbol": "n",
"score": 100.0,
"feedback": "Excellent"
},
{
"symbol": "jh",
"score": 100.0,
"feedback": "Excellent"
},
{
"symbol": "ax",
"score": 100.0,
"feedback": "Excellent"
},
{
"symbol": "r",
"score": 77.0,
"feedback": "혀를 말아올려 부드럽게 굴리는 ‘으르’ 소리를 내세요."
}
]
}- 일단 위와 같이 데이터를 반환하고, 피드백 부분을 80점 미만일 때
Retry.. 발음이 아쉽네용;같은 메시지를 띄우도록 하고,{사용자 발음} 대신 {정답 발음}으로 시도해보세요로 출력되도록 .. 해봐야겠당
⭐ 5월 21일 수요일
-
클라이언트랑 주고 받는 데이터가 달라서 메인 서버의 기본 제공 단어장 부분 API를 수정했다. 기존에는 daylist_id를 통해 daylist를 조회하고 마지막 접근 시간을 UPDATE 하는 방식으로 한번에 갔다면, basic_id를 통해 해당 daylist에 접근하여 daylist 목록을 조회한 후, 클라이언트에서 목록에 접근했을 때
latestAccessedAt를 업데이트 하도록 구현하였다.
⇒ 그러니까 기존 구조에서/{basic_id}/daylist/단순히 daylist 목록을 조회하는 API가 빠져있었다. -
클라이언트에서 List로 dayword_id를 전달하면 해당 아이디에 속하는 단어 상세 데이터를 불러와야 하는데, 기존 구조에서는 daylist_id에 해당하는 단어 목록의 전체 정보를 반환하도록 구현되어 있었다. 이 부분 또한 RequestBody를 추가하여
GET이 아니라POST하도록 매핑 방식을 바꾸었다.
⭐ 5월 22일 목요일
-
STT 기능을 AI 서버에 구현하였다. 클라이언트로부터 발음할 영단어와 평가할 발음의 국가를 받아오기 위해 요청 DTO 클래스를
PronunciationRequest설정하였다. -
evaluate_pronunciation에서 MS Azure STT로 발음 평가를 진행한다. 평가를 마치면dict형태로 결과를 저장한다. 그렇게 저장된dict타입 데이터를 원하는 정보만 추출하여 반환할 수 있도록 파싱하는 작업을extract_pronunciation_data에서 진행한다. -
extract_pronunciation_data에서는dict결과를 파싱하여 반복문을 통해 음소 개수만큼 반복을 진행하여symbol에 해당하는score와feedback을 저장하도록 하였다. -
score >= 90일 때는Excellent를,80 <= score < 90일 때는Good을, 70 미만일 때는 미리 정의해둔PHONEME_FEEDBACK을 출력하도록 하였다. -
응답 DTO 클래스
PronunciationResponse를 구현하였다. 반환 형태는전체 점수(정확도, 유창성, 완성도, 종합 점수)와음소 단위 발음 점수(symbol, score, feedback)로 구성되어 있다. 이 두 개에 대한 클래스를 구현하여 반환할 때 가독성 있고 효율적이도록 처리하였다. -
사용자가 원하는 국가명을 보냈을 때 STT가 처리할 수 있는 국가 코드로 파싱하였다. 아래와 같이
if-else를 사용하려 했는데,
if request.country == "en":
country = "en-US"
elif request.country == "uk":
country = "en-GB"
elif request.country == "aus":
country = "en-AU"- 국가 코드가 늘어났을 때 유지보수를 위해서는
dict방식이 낫다는 조언을 받아 아래와 같이 수정하였다.
country_map = {
"us": "en-US",
"uk": "en-GB",
"aus": "en-AU"
}
country = country_map.get(request.country)
if country is None:
raise HTTPException(status_code=400, detail="지원하지 않는 국가 코드입니다.")- 여기까지 녹음된
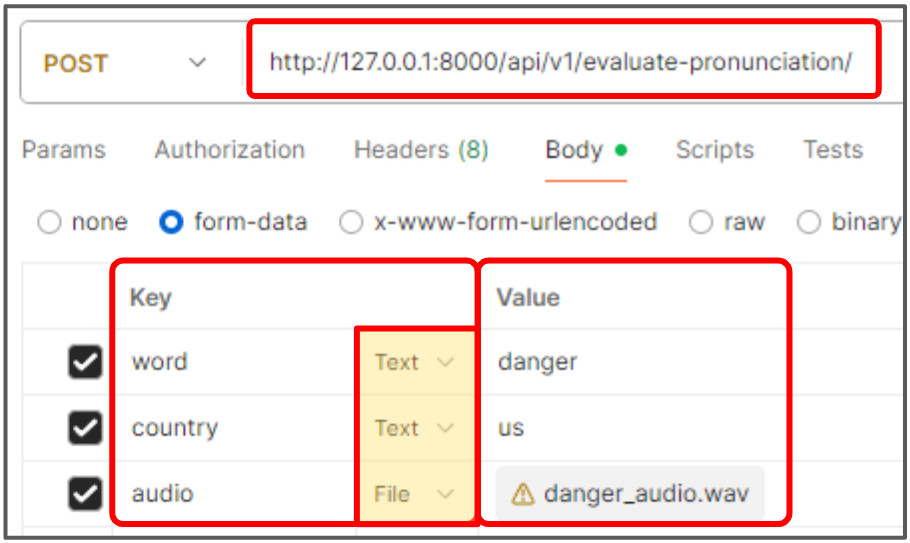
.wav파일로 진행하였다. 하지만 이 프로젝트에서는 로컬에 저장된 녹음 파일로 발음 평가를 진행하는 것이 아닌, 앱에서 사용자가 녹음 버튼을 통해 발음 테스트를 진행한 후, 해당 녹음 파일을 받아야 한다. 그러기 위해서 라우터 함수의 매개변수로 필요한 세 개의 데이터를 입력하였다.
async def fetch_word_pronunciation(
word: str = Form(...),
country: str = Form(...),
audio: UploadFile = File(...)):- 포스트맨에서도 동일하게 타입에 맞게
발음할 단어와평가할 발음 국가,사용자 발음 파일(.wav)를 전달하여 평가를 진행하도록 하였다. 사용자가 앱을 통해 녹음을 수행하면 결과가 서버로.wav형태로 오기 때문에 이렇게 처리한다고 한다... 스트림 형식을 받을 수 없는지 다시 한번 더 조사해봐야겠다.
⭐ 5월 28일 수요일
-
메인 서버의 기본 단어장 즐겨찾기 기능을 구현하였다. 크게 ① 목록 조회 ② 즐겨찾기 등록 ③ 즐겨찾기 해제 세개로 구성되어 있다.
-
사용자의 id를 통해 이루어지기 때문에 회원가입과 로그인을 통해 토큰을 받아야 했다.
가입에 필요한 회원 정보를 입력하고
가입한 정보를 통해 로그인을 진행하였다. 로그인을 하면accessToken과refreshToken을 받게 되는데 이 토큰이 필요한 이유는 인증된 사용자만이 어플 내의 API를 사용할 수 있기 때문이다. -
이렇게 발급받은
accessToken을 통해 즐겨찾기 API를 사용할 수 있게 되는데, 포스트맨에서 헤더에 인증키를 넣어GET(즐겨찾기 목록 조회),POST(즐겨찾기 등록),DELETE(즐겨찾기 해제)를 진행하면 된다. -
즐겨찾기 목록 조회, 등록, 해제는 클라이언트로부터 받은
basicWordId를 통해서favorite_word테이블에서SELECT&INSERT&DELETE를 진행할 수 있다. -
그리고 하나 알게 된 것 .. Repository에서 클래스에서 선언한 id 변수명과 상관 없이
@Id어노테이션을 사용했으면findById()메서드를 통해 기본키를 조회할 수 있었다.. 나는 그동안 웨 귀찮게 ... 함수명을 변수 이름에 맞추었는가 ...
