K. Yang, X. Zheng, J. Xiong, L. Liu and H. Ma, "WiImg: Pushing the Limit of WiFi Sensing with Low Transmission Rates," IEEE International Conference on Sensing, Communication, and Networking (SECON), pp. 1-9, 25 Oct. 2022
Abstract
Wi-Fi 신호를 이용해 gesture recognition이나 localization등을 해결할 수 있었다. 하지만 기존의 Wi-Fi signal 기반 연구들은 모두 실제 통신 상황을 고려한 연구들이 아니었다. 실제 Wi-Fi AP가 통신 서비스르 제공하게 되면 낮은 sampling rate의 CSI 신호만을 얻을 수 밖에 없다. 이 낮은 sampling rate의 신호는 앞서 말한 application에서 performance degredation을 야기한다. WiImg는 GAN을 이용하여 낮은 sampling rate의 신호에서 performance degredation이 나타나는 것을 막고자 한다.
Introduction
기존 Wi-Fi sensing 기반 선행 연구들을 보면 상당히 높은 sampling rate의 CSI 신호를 통해 실험한 경우가 많다. (e.g. 1000 Hz) 실제 Wi-Fi 통신 환경에서는 이렇게 높은 sampling rate의 신호 데이터를 얻는 것이 불가능하다. 하지만 그렇다고 낮은 sampling rate의 신호 데이터를 application에 적용하게 되면 그 성능이 낮아지게 된다. 이를 해결하기 위해 WiImg는 GAN을 이용해 낮은 sampling rate의 데이터를 높은 sampling rate의 데이터로 재생성해서 이를 application에 적용하였다.
Proposed Method
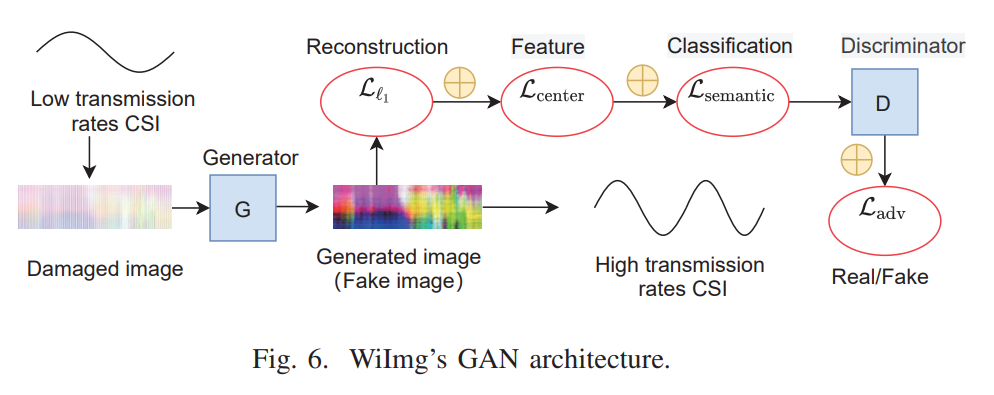
Generative Adversarial Network (GAN) [1] 은 image inpainting(손상된 이미지를 복구하는 것) 분야에서 널리 쓰인다. WiImg는 이를 통해 낮은 sampling rate 데이터를 손상된 이미지로 간주하여 높은 sampling rate의 데이터로 복구시키는 것이 목적이다.
CSI Preprocessing
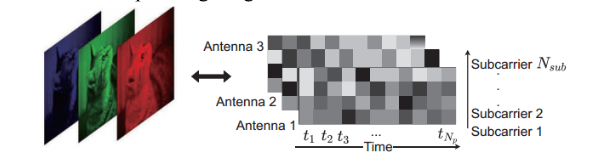
Wi-Fi CSI(Channel State Information) 신호는 3차원의 형태(안테나 쌍 x packet 개수 x subcarrier 개수)로 얻어지는데, 이를 이미지 형태로 바꾼다. 즉 안테나 쌍 3개를 RGB로 간주한 후 packet 개수와 subcarrier 개수는 이미지의 width와 height에 대응하여 CSI 신호 데이터를 이미지 형태로 나타낼 수 있다. 이 때, Raw CSI 신호에 DWT(Discrete Wavelet Transform) denoising 기법을 적용하여 어느 정도 noise를 제거한 후에 이미지로 변환한다.
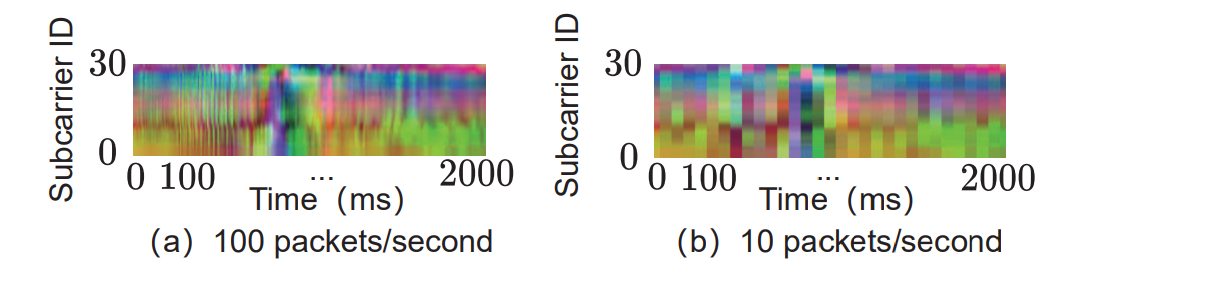
위 그림을 보면 10Hz로 sampling한 CSI 데이터보다 100Hz로 sampling한 CSI 데이터가 이미지로 변환했을 시 해상도가 더 높은 것을 확인할 수 있다.
Image Inpainting
앞서 변환한 이미지를 통해 GAN을 학습시킨다. 이 GAN은 낮은 sampling rate 데이터를 높은 sampling rate의 데이터로 복구시키는 것이 목적이다. 따라서 학습시킬 시에는 낮은 sampling rate 데이터와 높은 sampling rate의 데이터를 모두 이용한다.
이를 실제 application 상황으로 생각하면, Wi-Fi 통신을 하기 전 Wi-Fi AP로부터 낮은 sampling rate 데이터와 높은 sampling rate의 데이터를 모두 얻은 후 GAN을 학습시킨다. 이 후 실제 통신 상황에서는 낮은 sampling rate 데이터만 얻을 수 있는데 앞서 학습시킨 GAN을 이용하여 높은 sampling rate 데이터를 얻을 수 있게 된다.
하지만 기존 GAN을 이용한 image inpainting 방법은 이 CSI를 복구시킬 때 다소 성능이 안 나오는 결과를 야기했다. 따라서 본 저자들은 기존 기존 GAN을 이용한 image inpainting 방법과 다른 loss 함수를 제안하였다.
기존 기존 GAN을 이용한 image inpainting 방법에서의 loss 함수는 다음과 같다.
여기서 은 각각 loss, adversarial loss, perceptual loss, style loss를 의미하고 는 각 loss에 대응하는 hyper-parameter다.
본 논문에서는 뒤 두 가지 loss는 오히려 성능을 저하한다고 하여 앞서 두 가지 만 사용하였다.
Center Loss
Center Loss [2] 는 이미지 분야에서 많이 사용되는 Loss 함수이다. 이미지 데이터에서 각 class 데이터들끼리 모아서 center값을 구한 후, GAN이 생성한 이미지와 이 center의 픽셀 간 거리(차이)를 loss로 두게 된다. 이를 통해 GAN이 생성한 이미지가 보다 높은 sampling rate CSI 이미지와 비슷하게 생성하도록 유도한다.
여기서 은 데이터의 수, 는 GAN이 생성한 이미지, 는 실제 이미지의 class label, 는 번째 class 데이터들의 center값이 된다.
Semantic Loss
GAN의 성능을 보다 향상시키기 위하여 저자들은 semantic loss를 제안하였다. Wi-Fi CSI 기반의 gesture recognition 연구인 THAT [3] 과 WiFinger [4] 에서 제안한 모델을 이용한다.
THAT과 WiFinger 모델에 GAN이 생성한 CSI 이미지를 input으로 넣는다. 이 후 THAT과 WiFinger 모델이 gesture를 제대로 판단하였으면 loss를 줄이고, 오판하였으면 loss를 커지게 한다.
THAT은 softmax 함수를 통해 마지막에 해당 CSI 데이터가 어떤 gesture인지 확률로 나오게 되므로 loss함수를 위와 같이 정의하였다. 은 전체 class의 수이다.
WiFinger는 kNN을 통해 단순히 어떤 클래스인지만 나오게 된다. 따라서 올바르게 분류했으면 0, 아니면 어떤 양의 상수를 두어서 loss를 커지게 한다. Semantic Loss는 이 두 가지 loss를 합한 것이 된다.
최종적으로 WiImg에서 GAN 학습시 사용한 loss 함수는 다음과 같다. center loss의 경우에는 그 값이 다소 커서 log함수를 취해 해당 loss에 편향되지 않도록 하였다.
CSI reconstruction
모든 sampling rate에 대해서 250Hz로 복구시키는 것은 너무 labor intensive하므로 WiImg는 CSI 이미지를 25 Hz 에서 250 Hz / 50 Hz 에서 250 Hz / 100 Hz 에서 250 Hz의 sampling rate로 복구하도록 학습하였다. 이 때, 25, 50, 100 이외의 다른 Hz의 데이터들은 linear interpolation과 downsampling을 통해 위 3 가지 Hz에 맞추어 GAN을 학습시켰다. (e.g. 27Hz to 25Hz, 40Hz to 50 Hz)
이후 evaluation에서 다음의 3 가지 기법들과 WiImg를 비교하였다.
- Conventional GAN : 앞서 언급한 loss 함수를 사용하지 않고 기존 image inpainting 기법을 적용한 GAN으로 이미지를 생성하였을 때 결과
- Full sampling GAN : 앞서 언급한 3가지 Hz에 맞추어 복구시키는 것이 아닌, 모든 Hz의 데이터를 250Hz로 복구하도록 학습한 GAN으로 이미지를 생성하였을 때 결과
- Discrete sampling GAN : linear interpolation이나 downsampling으로 데이터를 맞추는 것이 아닌 오직 25 Hz, 50 Hz and 100 Hz의 데이터만을 이용하여 학습한 GAN로 이미지를 생성하였을 때 결과
Experiment Set-up
Experiment set-up은 다음과 같다.
- Mini PC with one antenna as the transmitter and another mini PC with three antennas as the receiver
- Intel 5300 NIC is adopted in each mini PC and use CSI Tool Monitor mode
- CSI is measured on 5 GHz Wi-Fi spectrum
실험 환경은 다음과 같다.
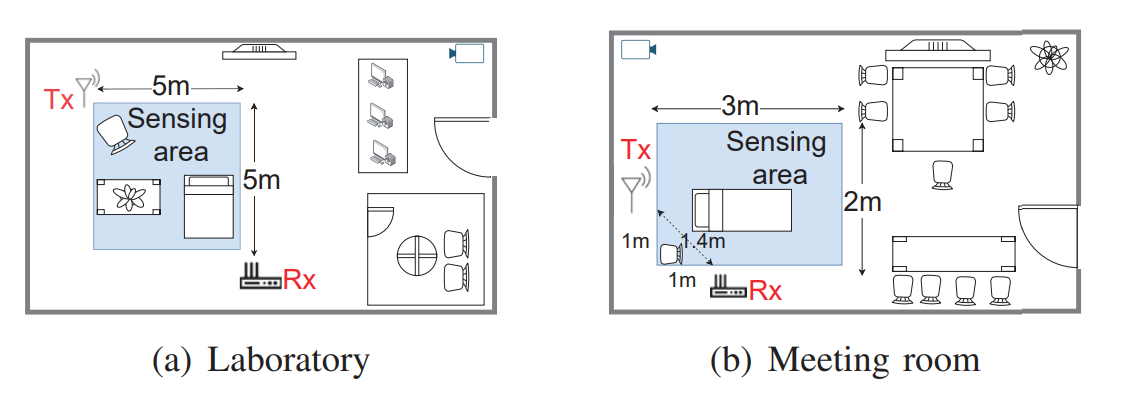
Data Collection
5 명의 사람들이 3 가지 application에 해당하는 CSI 데이터를 모았다.
- Daily activity recognition : Walk, Squat, Sit, Lay, Fall
- Hand gesture recognition : Push, Up, Down, Left, Right
- Person Identification : Walk 2 to 3 meters in the sensing area
각 데이터는 2초간 모아졌고 최종적으로 다음과 같이 행동들을 반복해서 수집하였다.
- Daily activity recognition : laboratory에서 40 번 & meeting room에서 20 번 (5 x 5 x 40 + 5 x 5 x 20 = 1500 data)
- Hand gesture recognition : laboratory에서 40 번 & meeting room에서 20 번 (5 x 5 x 40 + 5 x 5 x 20 = 1500 data)
- Person Identification : laboratory에서 Walk 200 번 & meeting room에서 walk 100 번 (5 x 200 + 5 x 100 = 1500 data)
우선 1000Hz에서 CSI 데이터를 수집한 후 downsampling을 통하여 각 Hz에 대응하는 데이터로 만들었다.
이 부분이 다소 이해가 가지 않았다. 그냥 각 sampling rate에 대응하는 데이터를 수집하는 것은 너무 labor intensive 했던 것일까...?
GAN학습 시에는 laboratory 데이터의 70%를 학습 데이터로 사용하였고, 30%를 테스팅에 사용하였다. meeting room 데이터는 이 후 환경에 robust하다는 것을 보여줄 때 사용하였다.
Evaluation
낮은 sampling rate의 이미지로부터 WiImg가 생성한 가짜의 높은 frequency 이미지를 THAT 모델에 넣어 classification 결과를 내었다. 다른 방법들을 비교하여 evaluation을 진행하였다.
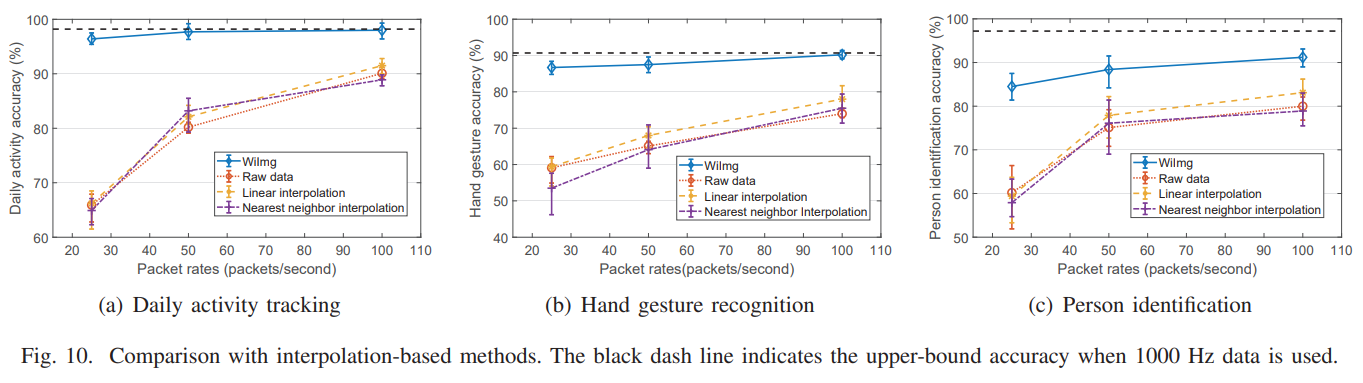
WiImg를 통해 생성한 높은 sampling rate의 데이터로 performance를 낸 결과와 다른 interpolation method를 비교한 결과이다. 검정색 점선은 1000Hz 데이터의 성능으로 검정색 점선과 가까울수록 재생성한 결과가 좋다고 볼 수 있다. 단순한 interpolation을 이용한 결과에 비해 확실히 좋은 결과를 보인다.
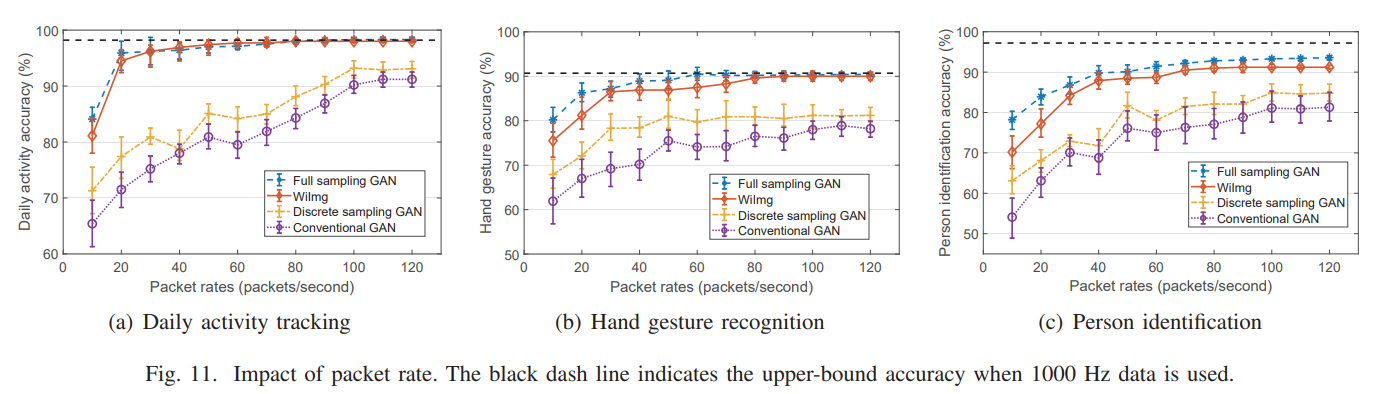
packet rate(sampling rate)에 따른 결과이다. 앞서 언급했던 3가지 방법들과 WiImg를 비교하였다. full sampling GAN을 제외하고는 모두 WiImg의 결과가 더 좋다. Full sampling GAN의 경우에는 모든 sampling rate로부터 250Hz를 복구하도록 GAN을 학습시켰기에 WiImg보다 근소하게 성능이 좋은 것을 확인할 수 있었다.
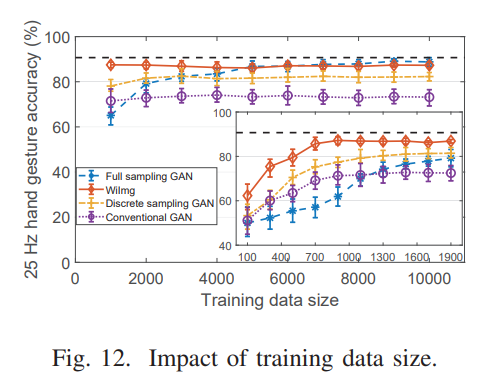
하지만 다음을 보면 Full sampling GAN의 경우에는 training data size가 상당히 많아야지만 성능이 나오는 것을 알 수 있다. 그에 비해 WiImg는 적은 training data에서도 높은 성능을 낼 수 있었다.
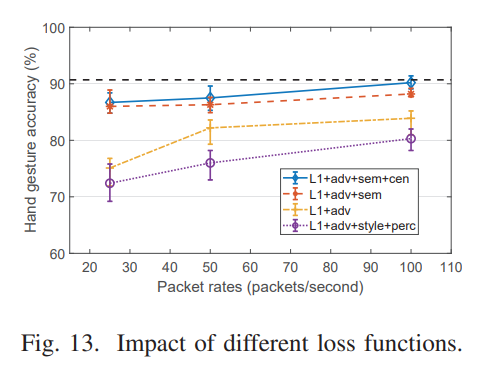
loss function에 따른 결과이다. WiImg에서 제안한 loss함수를 사용하는 것이 가장 결과가 좋았고, 과 을 사용하는 conventional GAN을 사용하는 것이 오히려 성능이 낮게 나왔다.
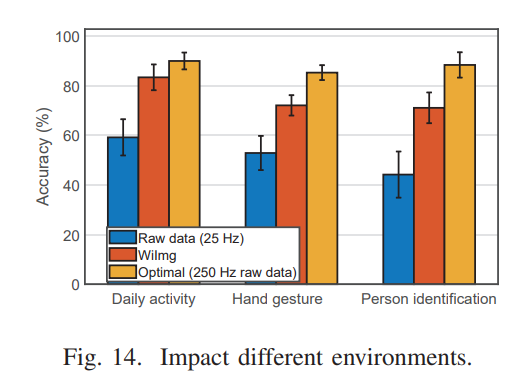
Laboratory 데이터로 GAN을 학습시키고 meeting room 데이터를 통해 재생성한 이미지로 성능을 나타낸 것이다. 환경에 robust함을 보이기 위함인데, 개인적으로 그렇게까지 성능이 좋다고 보기는 힘들 것 같다.
Conclusion
- Wi-Fi sensing과 Wi-Fi 통신의 공존과 관련된 문제를 최초로 연구하였다(To be the best of our knowledge)
- WiImg는 GAN을 활용하여 낮은 sampling rate 데이터에서 높은 sampling rate 데이터를 복구하였다.
- labor intensive한 문제와 time consuming 문제를 데이터 augmentation을 통해 해결하였다.
하지만 WiImg는 250Hz의 sampling rate에서만 가짜 CSI 이미지를 생성할 수 있다.
저자들은 250Hz로도 충분하다고 하지만, 일부 Fall detection과 같은 응용 프로그램에는 높은 sampling rate 데이터가 필요할 수 있다.
[1] K. Nazeri, E. Ng, T. Joseph, F. Z. Qureshi, and M. Ebrahimi, “Edgeconnect: Generative image inpainting with adversarial edge learning,” CoRR, vol. abs/1901.00212, 11 Jan. 2019
[2] M. Iqbal, M. S. I. Sameem, N. Naqvi, S. Kanwal, and Z. Ye, “A deep learning approach for face recognition based on angularly discriminative features,” Pattern Recognit. Lett., vol. 128, pp. 414–419, 2019
[3] W. W. L. Z. Z. C. Bing Li, Wei Cui and M. Wu, “Two-stream convolution augmented transformer for human activity recognition,” in AAAI, 2021.
[4] H. Li, W. Yang, J. Wang, Y. Xu, and L. Huang, “Wifinger: talk to your smart devices with finger-grained gesture,” in Proceedings of ACM UbiComp, 2016.
