
cs231n의 2강 내용은 image classification에 대한 내용이다. 강의 내용을 바탕으로 내가 이해한 바를 추가로 적어보았다.
1. Image Classification
(1) Image Classification: A core task in Computer Vision
컴퓨터는 Image Classification을 위해 우선 입력 이미지를 받는다. 예를 들어, 고양이 사진이 한 장 있고 시스템에는 미리 정해놓은 카테고리 집합이 있다. 카테고리에는 개, 고양이, 트럭, 비행기 등이 있다고 한다면 컴퓨터는 이미지를 보고 어떤 카테고리에 속할지 골라야 한다.
(2) The Problem: Semantic Gap

컴퓨터에 있어 고양이는 800x600 이미지이며, 각 픽셀은 red, green, blue로 이루어진 세 개의 숫자로 표현된다. 결국 컴퓨터에게 이미지는 거대한 숫자 집합에 불과할 뿐, 컴퓨터는 이미지가 고양이 카테고리에 속한다고 고를 수 없다.
이것을 바로 의미론적인 차이(semantic gap) 라고 한다. ‘고양이’라는 레이블은 우리가 이 이미지에 붙힌 의미상의 레이블(semantic label)이며, 이미지가 고양이라는 사실과 컴퓨터가 보는 픽셀 값과는 차이가 있다.
(3) Challenges
semantic gap 외에 컴퓨터가 이미지를 분류할 때 발생하는 문제들은 다음과 같다. 그러한 문제들이 발생하더라도 이미지 분류 알고리즘은 강인(robust)해야 한다.
1) Viewpoint variation

문제 1: 고양이 이미지에 조금의 변화만 주어도 픽셀 값들이 모조리 변하게 된다. 고양이가 움직이지 않고 가만히 있는 경우가 아닌 이상 카메라를 아주 조금만 옆으로 옮기거나 고양이가 아주 살짝 움직여도 모든 픽셀 값들이 전부 달라지게 된다.
2) Illumination

문제 2: 바라보는 방향이나 조명이 문제가 될 수 있다. 장면마다 조명이 달라지면서 고양이가 어두워지기도 하고 밝아지기도 하기 때문이다.
3) Deformation

문제 3: 객체 자체에 변형이 있을 수 있다. 고양이는 다양한 자세를 취할 수 있는 만큼 다양한 변형이 있을 수 있다.
4) Occlusion

문제 4: 가려짐(occlusion)도 문제가 될 수 있다. 고양이의 얼굴 밖에 볼 수 없다던가, 소파에 숨어 있는 고양이의 꼬리 밖에 볼 수 없는 등 고양이의 일부만 보여지는 상황이 있다. 사람이 아닌 컴퓨터에게는 고양이를 구분해내는 것이 힘들 수 있다.
5) Background Clutter

문제 5: Background clutter(배경과 비슷한 경우)라는 문제도 있다. 고양이가 배경과 거의 비슷하게 생긴 경우도 있다.
6) Intraclass variation

문제 6: 하나의 클래스 내에도 다양성이 존재한다. 고양이에 따라 생김새, 크기, 색, 나이 등이 다양하기 때문에 '고양이'라는 하나의 클래스 내에도 다양한 고양이의 모습들을 다룰 수 있어야 한다.
컴퓨터에게 있어 위의 문제들은 굉장히 다루기 어려운 문제들이지만, 만약 일부 제한된 상황이라면 잘 동작 할 뿐만 아니라 정확도도 높고 수행 시간도 별로 걸리지 않는 프로그램이 존재할 수 있다. 그러한 프로그램이 어떻게 가능한지 살펴보도록 한다.
2. Data-Driven Approach
(1) 이전의 시도들

고양이를 인식해야하는 상황에서 객체를 직관적이고 명시적으로 나타내는 알고리즘은 존재하지 않는다. 지금까지는 동물들을 인식하기 위해 고급 coded rules를 만들고자 하는 시도를 해왔다. 고양이를 인식하고자 할 때 고양이는 두 개의 귀와 하나의 코가 있다. 이를 통해 우선 이미지에서 edges를 계산하고 다양한 corners와 edges를 각 카테고리로 분류한다. 세 개의 선이 만나는 지점을 corner라고 했을 때, 귀는 여러 개의 corner들이 있고, 이런 방식으로 고양이에 대한 “명시적인 규칙 집합”을 만든다.
하지만 이런 방식은 다음과 같은 문제가 있다. 첫째, 이런 알고리즘은 super brittle(잘 깨진다)하다. 둘째, 객체마다 명시적인 규칙 집합을 만들어야 하므로 확장성이 전혀 없다. 다양한 객체들에 유연하게 적용 가능한 확장성 있는 알고리즘이 필요하다.
(2) Data-Driven Approach

이를 해결하는 방법 중 하나로 데이터 중심 접근 방법(Data-Driven Approach)이 있다. 이 방법은 각 객체(카테고리)마다 방대한 데이터를 수집하고, 각각의 규칙을 만드는 것이다. 각 객체마다 다양한 많은 데이터들을 모으기 위해 Google Image Search 와 같은 도구를 이용할 수도 있고, 고퀄의 데이터셋들을 이용할 수도 있다. 이 데이터셋들을 이용해서 Machine Learning Classifier를 학습시킬 수 있다. ML 알고리즘은 어떤 식으로든 데이터를 잘 요약해서 다양한 객체들을 인식할 수 있는 모델을 만들어내고 학습 모델로 새로운 이미지를 테스트 해보면 고양이나 개를 잘 인식해 낸다.
입력 이미지를 고양이로 인식하기 위해서는 train 함수와 predict 함수 두 개가 필요하다. Train 함수의 입력은 이미지와 레이블이고, 출력은 모델이며, Predict 함수의 입력은 모델이고, 출력은 이미지의 예측값이다.
(3) Nearest Neighbor (NN classifier)

Neural Network, CNN, Deep Learning도 중요하지만 Data-driven approach는 Deep Learning 보다 아주 일반적인 개념이다. 복잡한 알고리즘을 배우기 전에 조금 더 심플한 Classifier를 먼저 살펴보면 Nearest neighbor라는 아주 단순한 Classifier가 있다.
NN 알고리즘은 상당히 단순하다. Train Step 에서는 모든 학습 데이터를 기억하기만 한다. 그리고 Predict Step에서는 새로운 이미지가 들어오면 새로운 이미지와 기존의 학습데이터를 비교해서 가장 유사한 이미지로 레이블을 예측한다.
(4) Dataset(CIFAR-10)

CIFAR-10은 Machine Learning에서 자주 쓰는 연습용 데이터셋이다. CIFAR-10에는 10가지 클래스가 있으며, 총 50,000개의 training 이미지가 있으며 testing 이미지로는 10,000개가 있다. 각 세트는 클래스 별로 균일하게 존재한다.
오른쪽 칸을 보면 CIFAR-10 데이터셋을 이용한 NN 예제가 있다. 맨 왼쪽 열은 CIFAR-10 테스트 이미지이고 오른쪽 방향으로 학습 이미지 중 테스트 이미지와 유사한 순으로 정렬되어 있다. 테스트 이미지와 학습 이미지를 비교해 보면, 항상 맞는 것은 아니지만 비슷한 경우가 많다. 예를 들어, 두 번째 이미지를 보면 테스트 이미지는 '개'인데, 오른쪽으로 정렬되어 있는 이미지들을 보면 '개'인 경우도 있고 개가 아니라도 비슷하게 생긴 경우가 있다. 테스트 이미지에 NN알고리즘을 적용하면 학습 이미지에서 가장 유사한 샘플을 찾게 되고 그 샘플들(학습 데이터이므로 샘플의 레이블을 알 수 있음)은 '개'이므로 두 번째 행의 테스트 이미지도 ‘개’라고 할 것이다.
(5) Distance Metric - L1 Distance
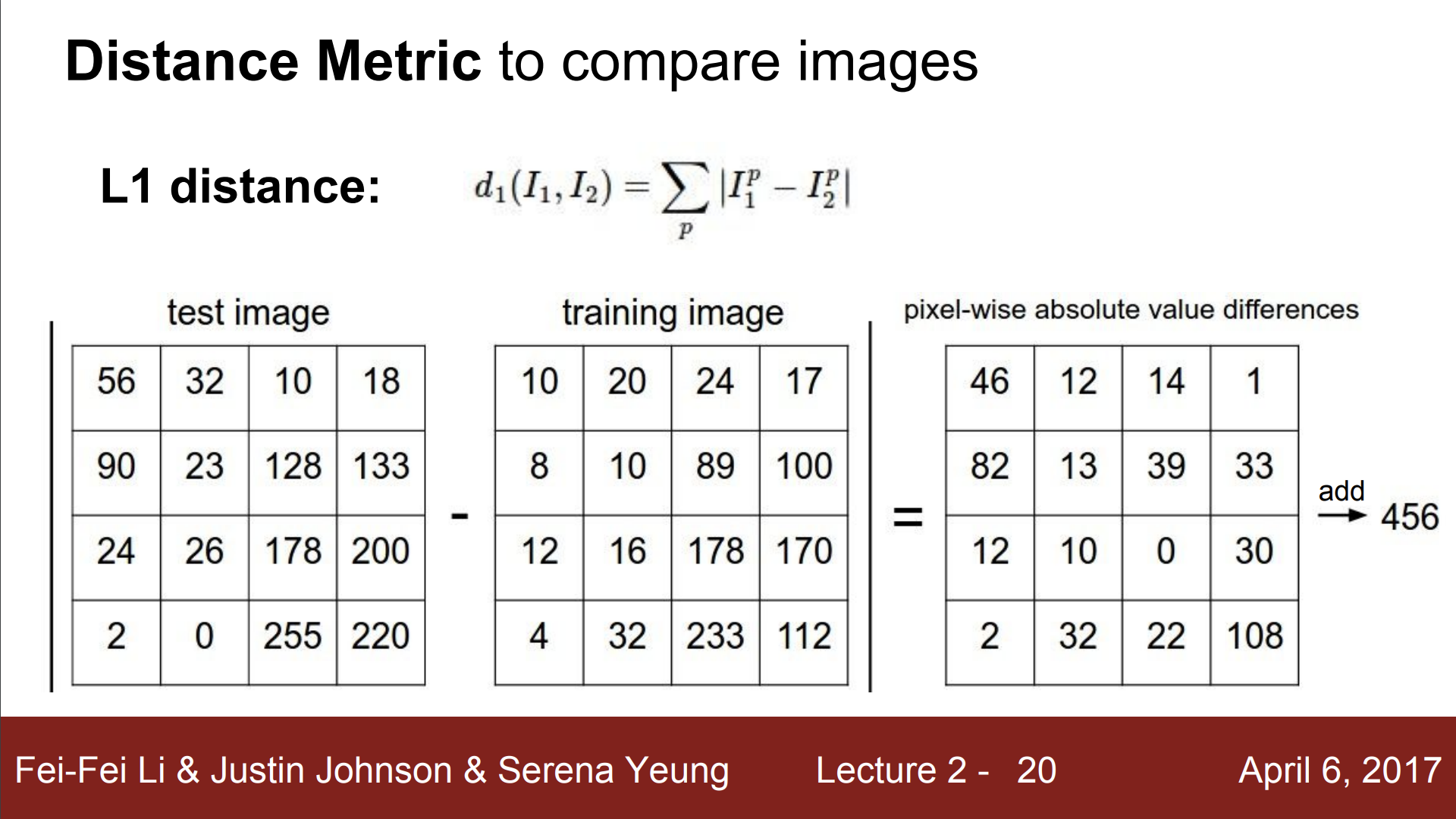
테스트 이미지 하나를 모든 학습 이미지들과 비교할 때 여러가지 비교 방법들이 있다. 다시 말해, “어떤 비교 함수를 사용할지” 결정해야 한다. 앞선 예제에서는 L1 Distance(= Manhattan distance)를 사용했다.
L1 Dist는 "두 이미지간의 차이를 어떻게 측정 할 것인가?"에 구체적인 방법을 제시한다. L1 Dist는 이미지를 Pixel-wise로 비교하므로, 4x4 테스트 이미지가 있을 때, 테스트 이미지에서 학습 이미지의 같은 자리의 픽셀을 뺀 후 절댓값을 취하고 그 절댓값들을 모두 더한다.
3. NN Classifier
NN Classifier를 파이썬 코드로 표현하면 다음과 같다.
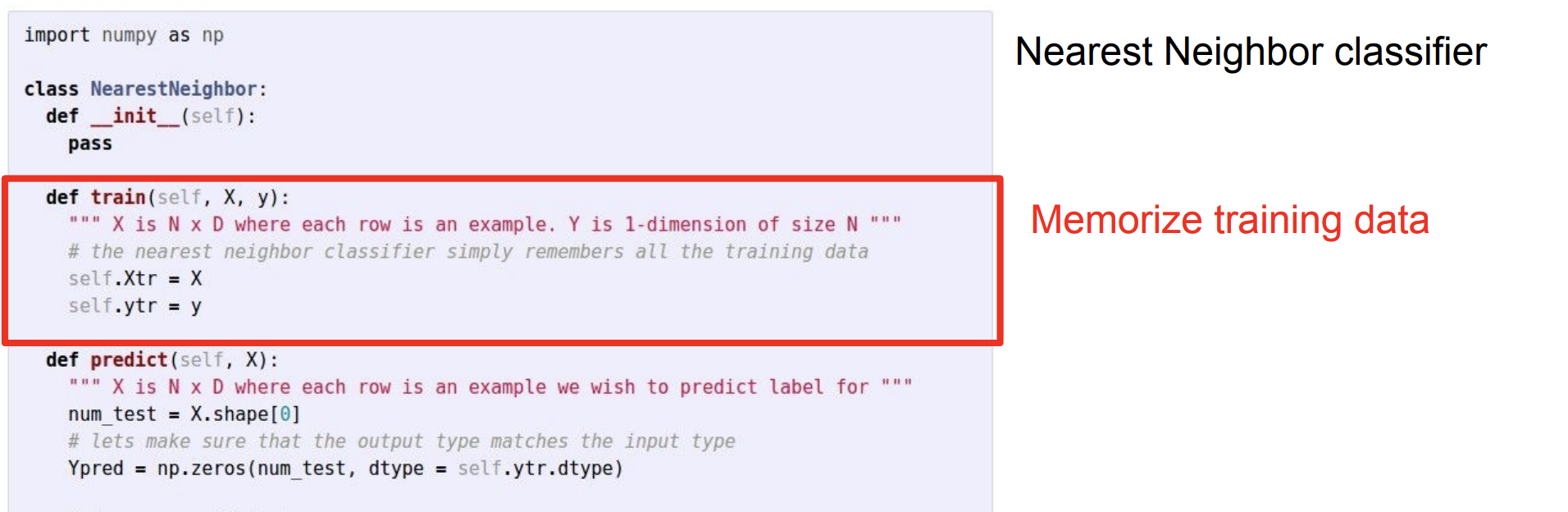

NN Classifier를 구현한 Python 코드는 NumPy의 Vectorized operations을 이용하여 짧고 간결하다.
NN의 Train 함수를 보면, 학습 데이터를 모두 기억하기만 하면 되므로 단순하다.
Test 함수에서는 이미지를 입력으로 받고 L1 Distance로 비교하여 학습 데이터들 중 테스트 이미지와 가장 유사한 이미지들을 찾아낸다.

이 때, NN Classifier에서 Train set의 이미지가 총 N개라면 Train/Test 함수의 속도는 어떻게 되는가? 우선 Train time은 모든 데이터를 기억만 하면 되기 때문에 데이터 크기와 상관없이 상수시간 O(1)이 된다. 하지만 Test time에서는 N개의 학습 데이터 전부를 테스트 이미지와 비교해야하기 때문에 시간이 상당히 오래 걸린다.
보통 Train Time은 조금 느려도 Test Time에서는 빠르다. 어떤 Classifier를 학습시길 때, 성능이 좋은 Classifier를 만들기 위해 Train Time에 많은 시간을 쏟지만 이 모델이 핸드폰이나, 브라우저와 등 Low Power Device에서 동작할 것을 고려해, Classifier가 Test Time에서 빠른 것을 기대한다. 그런 관점에서 NN 알고리즘은 이것은 ‘뒤집어진’(backwards) 결과를 낸다(Train Time < Test Time).
cf. CNN 같은 parametic model들은 NN과 반대이다. Train Time은 오래 걸려도 Test Time은 엄청 빠르다.

위 그림은 NN 알고리즘을 실제로 적용했을 때의 결과인 NN의 "decision regions" 이다. 2차원 평면 상의 각 점은 학습 데이터이고, 클래스 레이블(카테고리)마다 색이 다르다. 2차원 평면 내의 모든 좌표에서 각 좌표가 어떤 학습 데이터와 가장 가까운지 계산한 후, 각 좌표를 해당 클래스로 칠한다.
하지만 이 NN Classifier는 문제점을 가지고 있다. 위의 그림을 보면, 초록색 영역 사이에 하나의 노란색 점 때문에 노란색 영역이 생겨버린다거나, 파란색 영역을 초록색 영역이나 빨간색 영역이 침범하는 경우가 있다. 이는 잡음(noise)이거나 가짜(spurious)인 점으로 인해 생겨난 것이다.
4. K-Nearest Neighbors
(1) 과거의 문제 해결
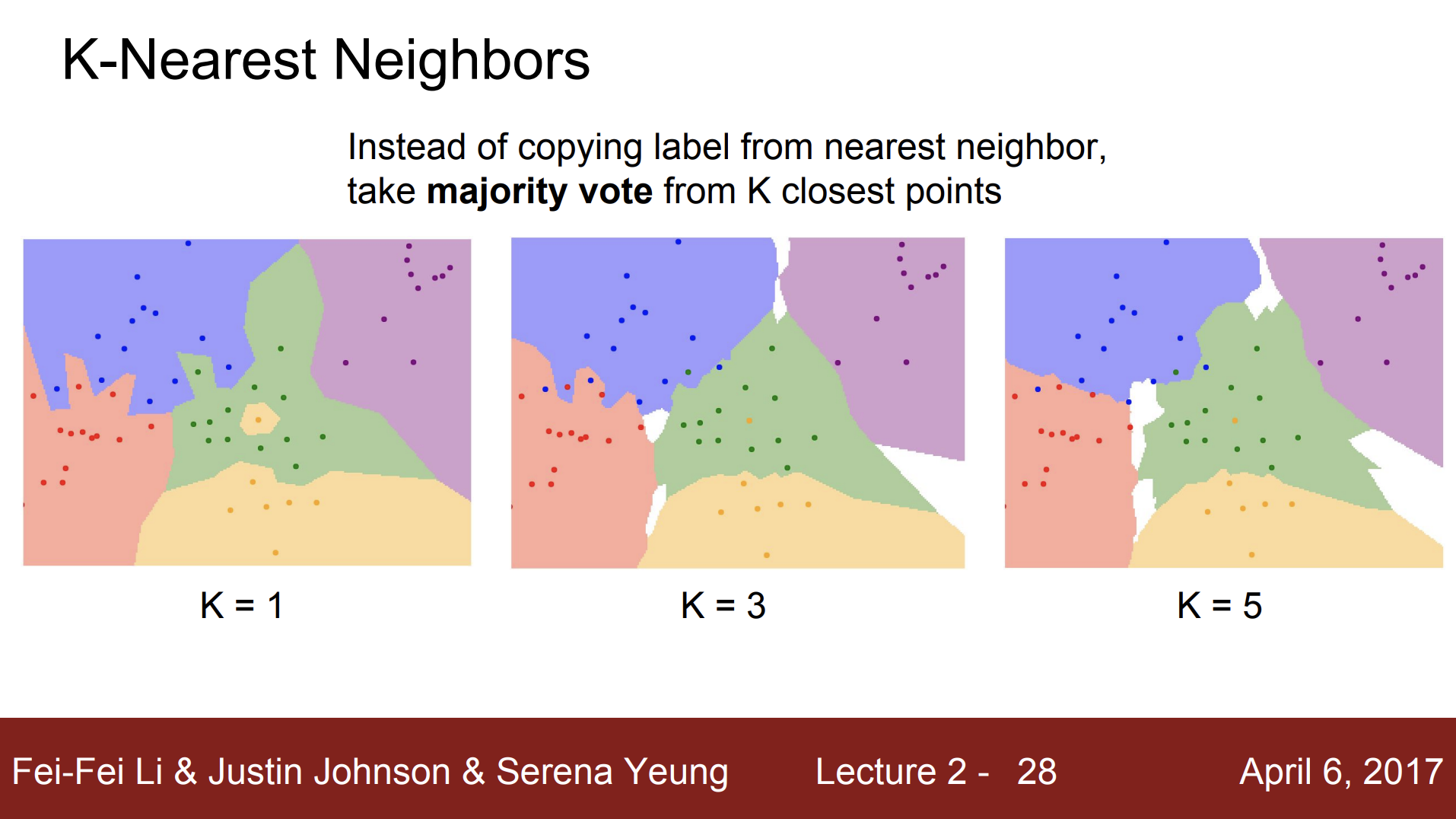
NN 알고리즘의 문제를 해결하기 위해 k-NN 알고리즘이 고안되었다. k-NN 알고리즘은 단순하게 가장 가까운 이웃만 찾는 것이 아닌 Distance metric을 이용해서 가까운 이웃을 K개의 만큼찾고, 이웃끼리 투표를 하는 방법이다. 그리고 가장 많은 투표수를 획득한 레이블로 예측한다. 투표 방법은 득표수만 고려하기도 하고, 거리별 가중치를 고려하기도 하는 등 다양하다.
위의 그림은 동일한 데이터를 사용한 k-nn Classifier들이다. K=3인 경우를 보면 K=1인 경우 초록색 영역에 있었던 노란색 점 때문에 생긴 노란색 영역이 없어졌다. 그리고 빨강/파랑 사이와 초록/파랑 사이의 경계가 점차 부드러워지고 있다. K=5의 경우를 보면 파란/빨간 영역의 경계가 많이 부드러워졌다.
위 그림들처럼 K가 1보다 커야 경계가 더 부드러워지고 더 좋은 결과를 보이기 때문에 NN classifier를 사용할 때, K는 1보다 큰 값으로 사용한다.
참고 : 레이블링이 되지 않은 흰색 영역은 k-nn이 "대다수"를 결정할 수 없는 지역이다. 어떻게 추론을 해보거나, 임의로 정하는 등으로 흰색 영역을 메꿀 수 있는 방법도 있다.
참고 : Computer Vision에서는 다양한 관점을 유연하게 다루는 능력이 매우 유용하다. 이미지를 고차원 공간에 존재하는 하나의 점이라고 생각하는 관점과 이미지의 픽셀들을 하나의 고차원 벡터로 생각하는 관점, 이 두 관점을 자유롭게 오가는 것이 좋겠다.

하지만 위의 결과를 보면 K-nn을 통해 이미지를 분류했을 때 성능이 좋지 않은 것을 알 수 있다. (잘 분류된 것은 초록색/ 잘 분류되지 않은 것은 빨간색으로 표기) K값을 높여 더 많은 이웃들이 투표에 참여하면 각종 잡음들에 더 강인하여 성능이 더 올라갈 것이다.
(2) Distance Metric

k-nn을 사용할 때 서로 다른 점들을 어떻게 비교할 것인지도 결정해야 한다. L1 Distance는 "픽셀 간 차이 절대값의 합"을 거리로 이용하는 방법인 반면, L2(Euclidean) distance는 "제곱 합의 제곱근"을 거리로 이용하는 방법이다. metric 마다 기하학적 구조가 다르기 때문에 어떤 distance metric을 선택할지는 중요한 문제이다.
L1의 관점에서는 사각형 위의 점들이 모두 원점으로부터 동일한 거리만큼 떨어져 있어 원이라고 생각된다. 하지만 좌표상에는 사각형이므로 L1은 어떤 좌표 시스템이냐에 따라 많은 영향을 받아 기존의 좌표계를 회전시키면 L1 distance가 변한다.
L2의 관점에서도 원이라고 생각되는데, 좌표상에도 원으로 나타나므로 L2의 경우에는 좌표계와 아무 연관이 없어 좌표계에 영향을 받지 않는다.
만약 특징 벡터의 각각 요소들이 개별적인 의미를 가지고 있다면(e.g. 키, 몸무게) L1 Distance가 더 유용하게 쓰인다. (좌표계를 회전시키면 L1 distance가 변하기 때문에 개별적인 특징이 더 잘 드러나기 때문인 거 같다.) 하지만 특징 벡터가 일반적인 벡터이고, 요소들간의 실질적인 의미를 잘 모르는경우라면, L2 Distance가 더 유용하게 쓰인다.
k-nn에 다양한 거리 척도를 적용하면 k-nn으로 벡터나 이미지 외에도 문장 분류와 같은 다양한 종류의 데이터를 다룰 수 있다.
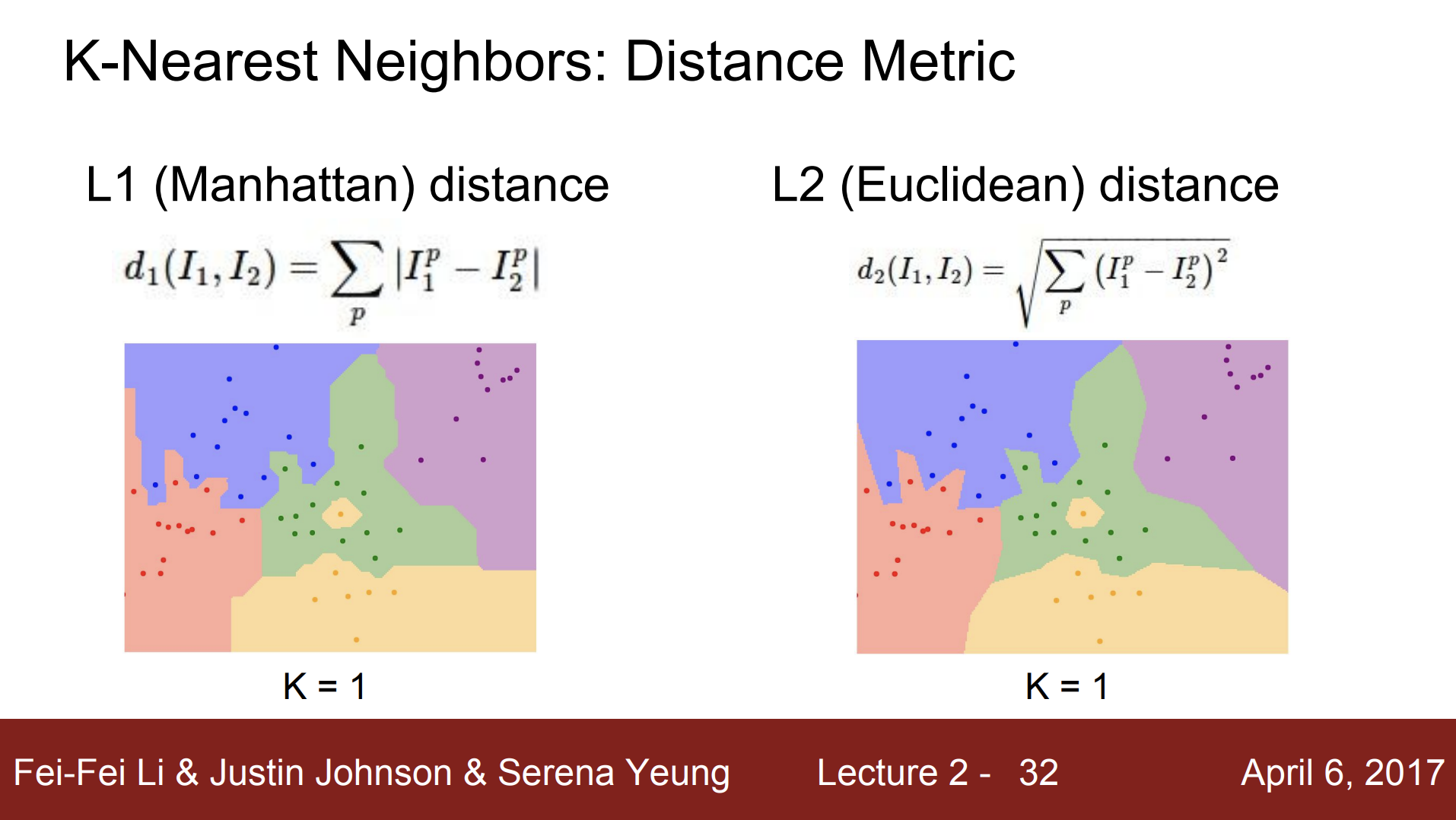
위 그림을 통해 distance metric에 따라 실제 기하학적으로 어떻게 변하는지 알 수 있다. 동일한 데이터를 기준으로 왼쪽은 L1 Distance, 오른쪽은 L2 Distance를 사용했는데, 경계의 모양이 달라졌다. L1 Distance는 결정 경계가 좌표 축에 영향을 받는 경향이 보인다. 반면, L2 Distance는 좌표 축의 영향을 받지 않고 경계를 만들기 때문에 조금 더 자연스럽다.
데모사이트 : K와 distance metric을 바꿔보면서 경계 확인해보기
→ http://vision.stanford.edu/teaching/cs231n-demos/knn/
(3) Hyperparameters

K와 distance metric을 "하이퍼파라미터" 라고 하는데, 하이퍼파라미터는 데이터로 학습시키는 것이 아닌 학습 전에 선택하여야 한다.
하이퍼파라미터를 정하는 것은 문제의존적(problem-dependent)이므로 다양한 하이퍼파라미터 값을 넣어 보고 최적의 값을 찾아내어야 한다.
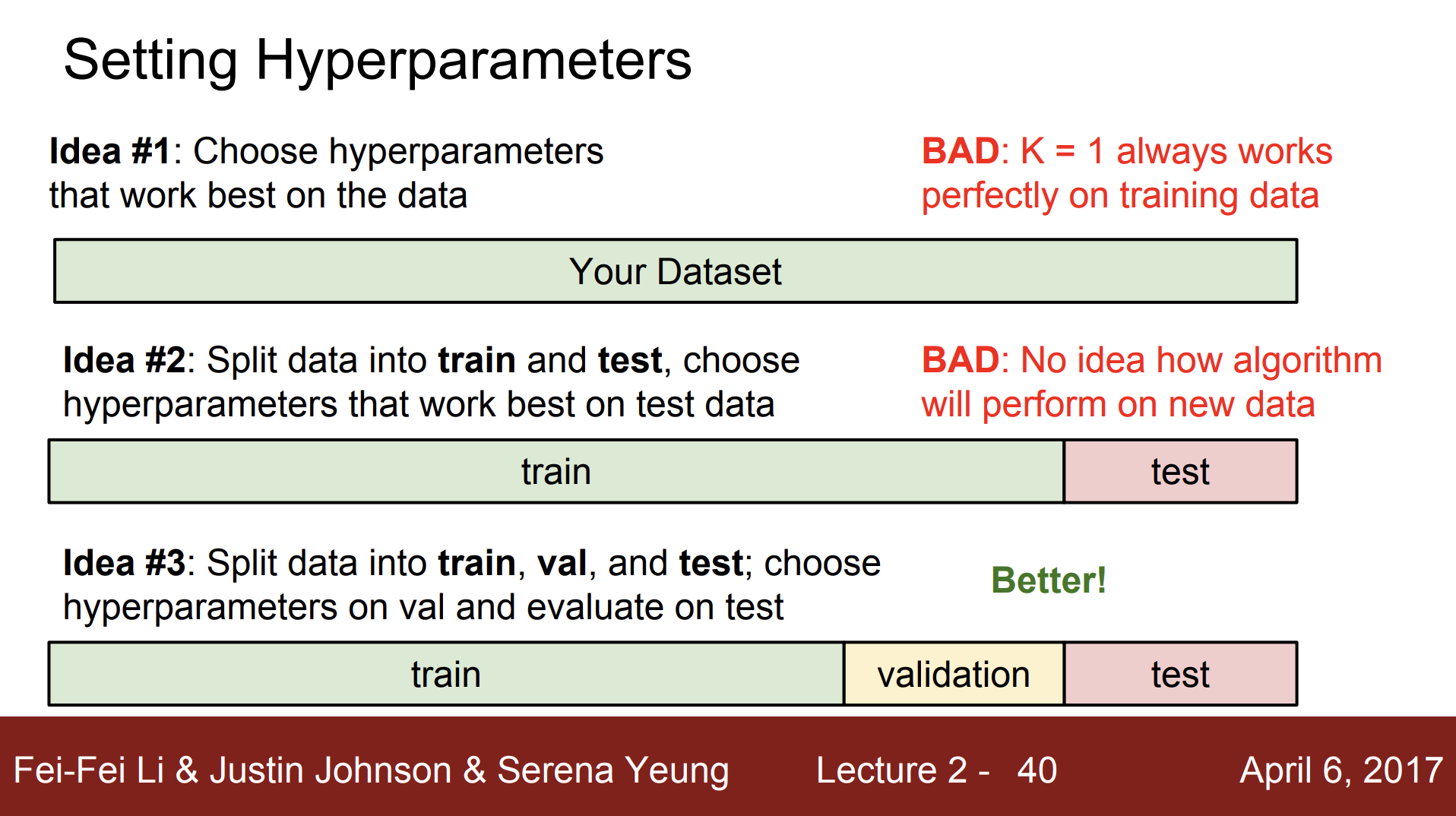
하이퍼파라미터 값을 얻기 위해 다양한 시도를 할 수 있다.
Idea #1 : 학습 데이터에만 신경을 써서 학습데이터의 정확도와 성능를 최대화하는 하이퍼 파라미터를 선택하는 것이다. NN 분류기는 K = 1 일 때 학습 데이터를 가장 완벽하게 분류하므로 학습데이터의 정확도와 성능을 최대화하기 위해 K는 항상 1이 된다. 하지만 기계학습에서는 학습 데이터를 얼마나 잘 맞추는지보다 학습시킨 분류기가 한번도 보지 못한 데이터를 얼마나 잘 예측하는지가 더 중요하므로 이는 좋지 않은 방법이다. 위의 내용을 보면, 실제로는 K를 더 큰 값으로 선택했을 때, 학습 데이터에서는 잘못 분류하는 경우가 종종 있지만 예측에 있어서는 더 좋은 성능을 보였다.
Idea #2 : 전체 데이터셋 중 일부는 학습 데이터로, 다른 일부를 테스트 데이터로 사용하는 것이다. 학습 데이터로 다양한 하이퍼파라미터 값들을 학습을 시키고 테스트 데이터에 적용시켜 본 다음, 하이퍼파라미터를 선택하는 방법이다. 이 방법 또한 기계학습의 목적인 예측을 잘 해야한다는 점에 있어서 좋지 않다. 학습시킨 모델들 중 테스트 데이터에 가장 잘 맞는 모델을 선택한다면 테스트 셋에서만 잘 동작하는 하이퍼파라미터를 고를 수 있기 때문이다. 결국 테스트셋에서의 성능이 한번도 보지못한 데이터에서의 성능을 대표할 수는 없게 된다.
Idea #3 : 데이터의 학습 데이터, 검증 데이터, 테스트 데이터로 세 개로 나누는 것이다. 다양한 하이퍼파라미터로 학습 데이터를 학습시킨 후 검증 데이터로 검증하여 검증 데이터에서의 최적의 하이퍼파라미터를 선택한다. 그 외의 다른 모든 일들을 마친 후 검증 데이터에서 가장 좋았던 분류기로 테스트 데이터에서 단 한 번만 수행하여 한번도 보지 못한 데이터에 얼마나 잘 동작하는지 확인한다. 따라서 검증 데이터와 테스트 데이터를 엄격하게 나눠 놓아야 한다.
- 학습 데이터와 검증 데이터의 차이가 무엇인가?
학습 데이터의 이미지는 레이블이 기억되므로, 어떤 이미지를 분류할 때 학습 데이터와 비교하여 가장 유사한 레이블을 선택한다. 반면, 검증 데이터는 레이블을 알 수 없는 상태에서 얼마나 잘 분류하는지(정확도)를 확인하는 용도이다. - 테스트 데이터가 한번도 보지 못한 데이터를 대표할 수 있는가?
데이터는 독립적이며, 하나의 유일한 분포에서 나온다는 기본적인 통계학적 가정(i.i.d assumption)이 전제되어야 한다. 즉, 모든 데이터는 동일한 분포를 따른다는 의미이다.
실제로는 그렇지 않은 경우가 많아 테스트 데이터가 한번도 보지 못한 데이터를 제대로 나타내지 못하는 경우가 많다. 따라서 데이터 셋을 만들 때 일관된 방법으로 대량의 데이터를 한번에 수집한 후 무작위로 학습 데이터와 테스트 데이터를 나줘주는 것이 좋다. 데이터를 지속적으로 모으고 있는 경우에는 먼저 수집한 데이터들을 학습 데이터로 쓰고, 이후에 모은 데이터를 테스트 데이터로 사용한다면 문제가 생길 수 있으므로, 데이터셋 전체를 무작위로 섞어 데이터셋을 나누어야 한다. - 최적의 하이퍼파라미터를 찾을 때까지 계속해서 학습을 다시 시키는가?
다시 학습시킬 시간이 있고 1%의 성능이라도 올리기 위해서라면 다시 학습시키는 것이 하나의 방법이 될 수 있다.
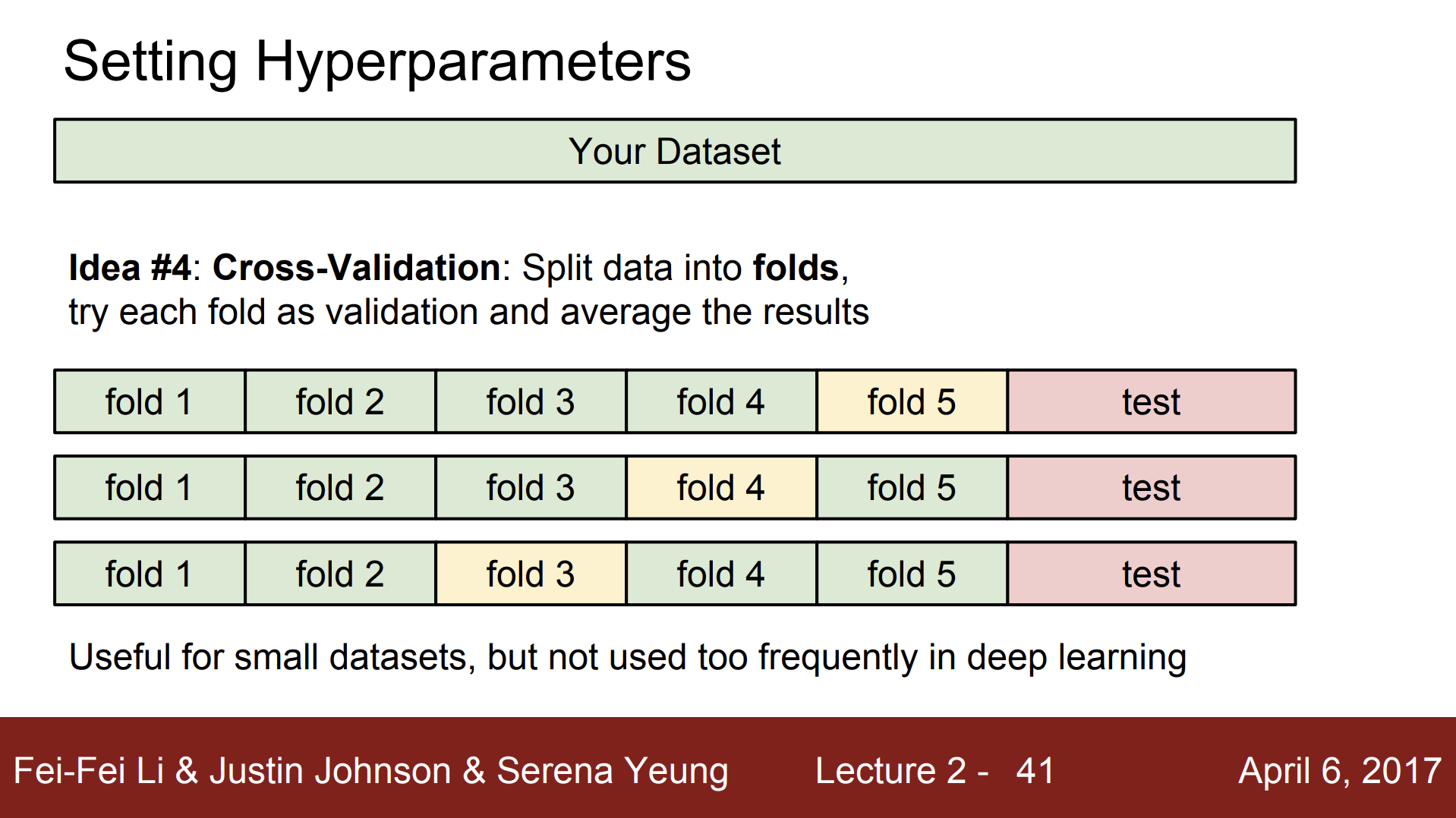
하이퍼파라미터를 선택하기 위해 cross validation(교차 검증) 방법을 사용하기도 한다. 이 방법은 먼저 테스트 데이터를 분리해놓고 나머지 데이터는 학습 데이터로 여러 부분으로 나눈다. 그리고 나눈 데이터들을 돌아가면서 검증 데이터로 사용한다. 위의 예제를 바탕으로 보면, 4개의 fold에서 학습시키고 남은 한 fold에서 알고리즘을 평가하며, 돌아가면서 한 fold 씩 평가하여 최적의 하이퍼파라미터를 확인하는 것이다.
하지만 이 방법은 데이터셋이 작을 때 주로 사용되고, 딥러닝에서는 많이 사용되지 않는다. 표준방식이기는 해도 딥러닝같은 큰 모델을 학습 시킬 때 학습 자체의 계산량이 많기 때문이다.

위의 그래프는 5-fold 교차 검증을 수행하였을 때 나오는 그래프(X축은 K-NN의 K, Y축은 분류 정확도)이다. K마다 5번의 교차 검증을 통해 알고리즘이 얼마나 잘 동작하는지를 나타낸다. 하이퍼파라미터에 따라 모델의 정확도와 성능을 평가하여 최적의 하이퍼파라미터를 구하고, 분산을 함께 계산하여 그 성능의 분산도 알 수 있다. 여기서는 K = 7 일 경우에 가장 좋은 성능을 나타내고 있다.
(4) K-nn의 문제점

하지만 이미지 분류에서는 k-NN 분류기가 사용되지 않는다.
문제점 1: 테스트 시간에 있어 너무 느리다.
문제점 2: distance metrics(L1/L2 Distance)가 이미지 간의 거리(지각적 유사성)를 측정하기에 적절하지 않다. 위의 예시를 보면 왼쪽의 원본 이미지와 오른쪽의 세 개의 왜곡된 이미지가 있다. 이미지 간의 차이를 알기 위해 세 개의 이미지와 원본의 사이의 Euclidean Distance를 각각 측정해보면 세 이미지는 모두 다르지만 모두 동일한 L2 Distance를 가진다.
- 세 개의 이미지들의 L2 Distance가 같은 이유?
세 이미지들이 같은 L2 Distance를 가지도록 임의로 설정한 것이다. Distance metric이 이미지간의 유사도를 측정하는데 좋지 않다는 점을 알려주기 위해 동일하게 만든 것이다. - 이미지들이 모두 같은 사람이므로 distance가 같으면 오히려 좋은 거 아닌가?
위의 예시에서는 좋을 수도 있지만 그렇지 않은 경우가 있다. 다른 두 개의 원본 이미지가 있고, 그 위에 위치에 박스를 놓거나, 색을 더하는 등으로 두 이미지의 Distance를 가깝게 만든다면, 서로 다른 이미지들이 같은 Distance를 가지게 되어 문제가 생길 수 있다.

문제점 3: 차원의 저주. K-NN은 학습 데이터를 이용해 공간을 분할한다. 따라서 전체 공간을 커버할 만큼의 충분한 학습 데이터가 있어야 K-NN이 잘 동작할 수 있다. 학습 데이터가 충분하지 않으면 이웃 간 거리가 멀어 테스트 이미지와 그렇게 유사하지 않게 되고 결국 테스트 이미지를 제대로 분류할 수 없게 된다. 학습 데이터가 충분하기 위해 필요한 데이터 양은 차원이 증가함에 따라 기하급수적으로 증가한다.
- 그림의 초록 점과 파란 점은 무엇을 의미하는가?
각 점은 학습 샘플 하나 하나이고, 각 점의 색은 학습 샘플이 속한 카테고리이다. 1차원에서는 전체 공간을 커버하기 위해 학습 샘플이 4개면 충분하다. 2차원 공간에서는 16개가 필요하다. 고차원이 될수록 필요한 학습 샘플의 수는 기하급수적으로 증가한다.
차원의 저주 문제를 해결하기 위해 manifold learning을 할 수 있는데, K-NN 알고리즘은 샘플들의 manifolds를 가정하지 않기 때문에 K-NN이 제대로 동작하기 위해서는 전체 공간을 커버할 수 있는 충분히 많은 학습 샘플들이 있어야 한다.
- 참고 : manifold learning
(5) Summary

다만, k-NN 알고리즘은 성능이 좋지 않아 이미지에는 잘 사용하지 않는다.
5. Linear Classification
(1) Linear classifier란?

Nerural Network는 레고블럭과 특성이 비슷하다. NN을 구축하기 위해 다양한 컴포넌트들(블럭들)을 쌓아올리는데, 이때 가장 기본이 되는 블럭 중 하나가 Linear classifier이다.

NN의 레고블럭 특성은 다음에서도 확인할 수 있다. Image Captionig 에서는 입력으로 이미지를 넣고, 출력으로 이미지를 설명하는 문장을 받는다. 여기서 이미지를 인식하기 위해서는 CNN을 사용하고, 언어를 인식하기 위해서는 RNN을 사용하므로, CNN과 RNN을 레고 블럭처럼 붙혀 학습에 사용할 수 있다.
(2) Parametric Approach
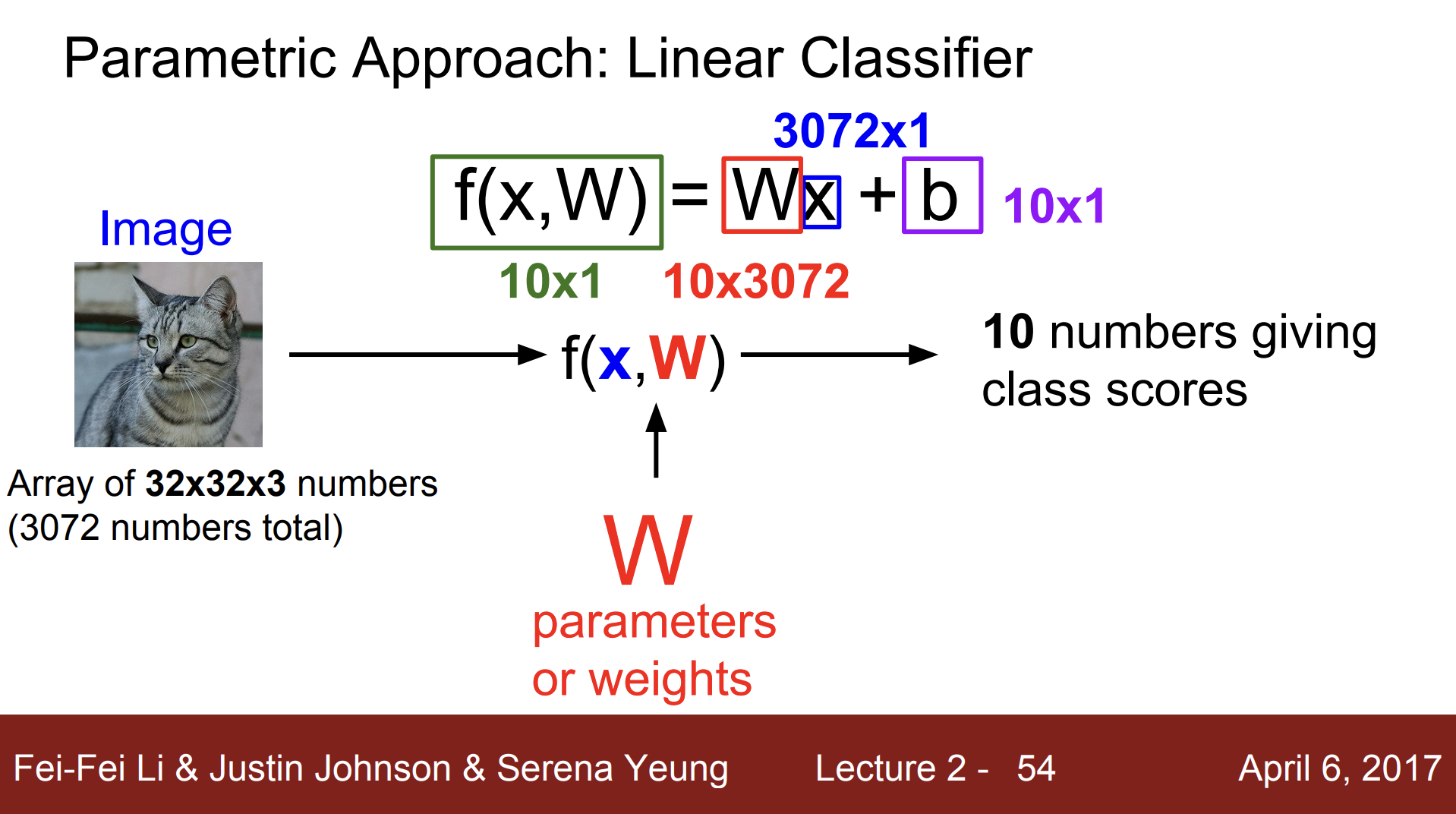
CIFAR-10은 50,000여개의 학습 데이터가 있고 각 이미지는 32x32 픽셀을 가진 3 채널 컬러 이미지(32x32x3)였다.
- 32x32x3에서 3은 Red, Green, Blue 3 채널을 의미한다.
입력 이미지(X) & 파라미터(W)
Linear classifier는 "parametric model”의 가장 단순한 형태이다. parametric model에는 입력 이미지와 파라미터라는 두 개의 요소(component)가 있다. 입력 이미지를 보통 "X" 로 쓰고, 파라미터(가중치)는 "W" 또는 "세타(theta)" 로 쓴다.
함수를 작성하여 data X와 parameter W를 가지고 CIFAR-10의 각 10개의 카테고리 스코어를 나타내는 10개의 숫자를 출력해야 하는데, "고양이"의 스코어가 높다는 건 입력 X가 "고양이"일 확률이 크다는 것을 의미한다.
parametric approach 에서는 학습 데이터의 정보를 요약하여 파라미터 W에 모아준다. 테스트에 있어 파라미터 W만 있으면 되므로, 전체 학습 데이터를 사용하지 않아도 되며, 휴대폰과 같은 작은 디바이스에서 모델을 동작시켜야 할 때 효율적이다.
cf. K-NN은 전체 학습 데이터를 테스트에 사용하여 파라미터가 존재하지 않았다.
파라미터 W와 데이터(X)를 조합하는 여러가지 방법 중 이 둘을 곱하는 방법이 바로 Linear classification 이다. 수식으로 F(x,W) = Wx 로 나타낼 수 있다.
차원
입력 이미지는 32 x 32 x 3 이다. 이를 flatten하여 열 벡터로 만들면 3,072-dim 벡터(3072 x 1)가 된다. 10개의 카테고리에 해당하는 각각의 스코어를 얻기 위해서 행렬 W는 10 x 3072가 되어야 한다. W와 x를 곱하면 10 classes 스코어를 의미하는 10 x 1 짜리 하나의 열 벡터를 얻게 된다.
Bias
데이터셋이 불균형한 상황 등에서 Bias term도 더해주는 경우가 있다. Bias term은 10-dim 열 벡터(10 x 1)이다. Bias term은 입력과 직접 연결되지 않지만 데이터와 무관하게 특정 클래스에 우선권을 부여한다. 예를 들어, 고양이 데이터가 개 데이터보다 훨씬 더 많은 상황에서 고양이 클래스에 상응하는 바이어스가 더 커지게 된다.
함수의 동작 원리

Linear classifier는 2x2 이미지를 입력으로 받고 이미지를 4-dim 열 벡터(4 x 1)로 펼친다. 고양이, 개, 배 세가지 클래스만 있다고 가정했으므로 가중치 행렬 W는 4x3 행렬이 된다. 여기에 추가적으로 3-dim bias 벡터가 있다. 이를 바탕으로 계산된 "고양이 스코어" 는 입력 이미지의 픽셀 값들과 가중치 행렬을 내적한 값에 고양이 bias를 더한 것이다. 여기에서 내적이란 클래스 간 탬플릿의 유사도를 측정하는 것과 비슷하다는 것을 알 수 있다.
(3) Interpreting a Linear Classifier

관점 1
하단의 이미지는 CIFAR-10의 각 10개의 카테고리에 가중치 행렬 W의 한 행을 뽑아서 이를 이미지로 시각화시킨 것이다. 이러한 템플릿 매칭의 관점을 통해 Linear classifier가 이미지 데이터를 인식하기 위해서 어떤 일을 하는지, 가중치 행렬이 어떻게 학습되는지 알 수 있다.
비행기 클래스에 대한 템플릿 이미지를 보면, 이미지가 전반적으로 파란 색이며, 가운데에는 어떤 물체가 있다. Linear classifier는 이러한 특징들을 통해 비행기를 찾는다.
하지만 Linear classifier는 각 클래스에 대해서 단 하나의 템플릿만을 학습한다는 문제가 있다. 동일한 클래스라도 다양한 특징들이 존재할 수 있는데 각 카테고리를 인식하기 위한 템플릿은 단 하나밖에 없어 다양한 특징들을 반영하기 힘들다.
말 클래스에 대한 템플릿 이미지를 자세히 보면 머리가 두 개인데, Linear classifier가 클래스 당 하나의 템플릿 밖에 허용하지 않아 그렇게 할 수밖에 없다.
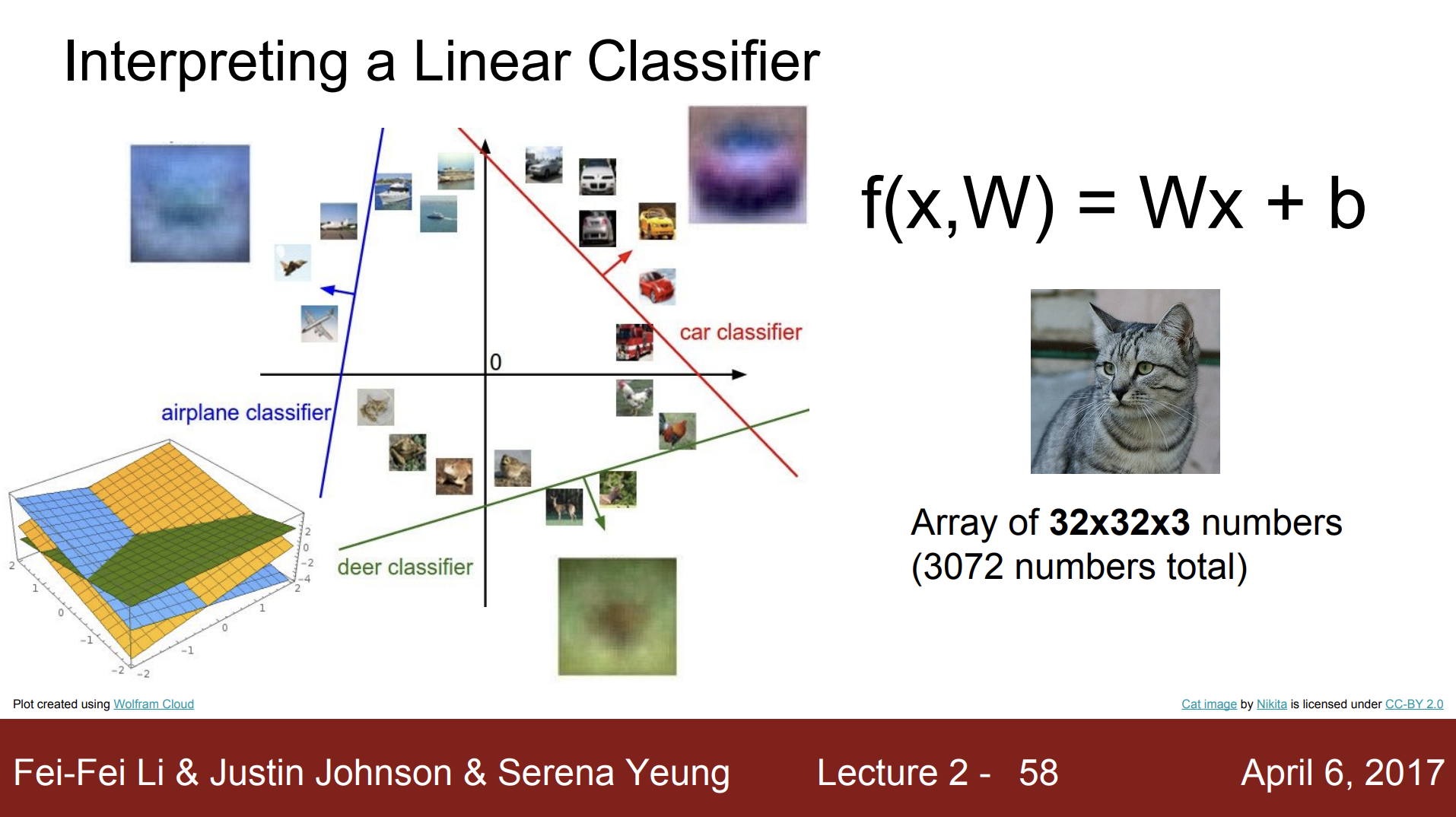
관점 2
각 이미지를 고차원 공간의 한 점이라는 관점에서는, Linear classifier는 각 클래스를 구분시켜 주는 선형 결정 경계의 역할을 한다. 예를 들어, 비행기의 경우, Linear classifier는 파란색 선을 학습해서 비행기와 다른 클래스를 구분할 수 있다.
(4) Hard cases for a linear classifier
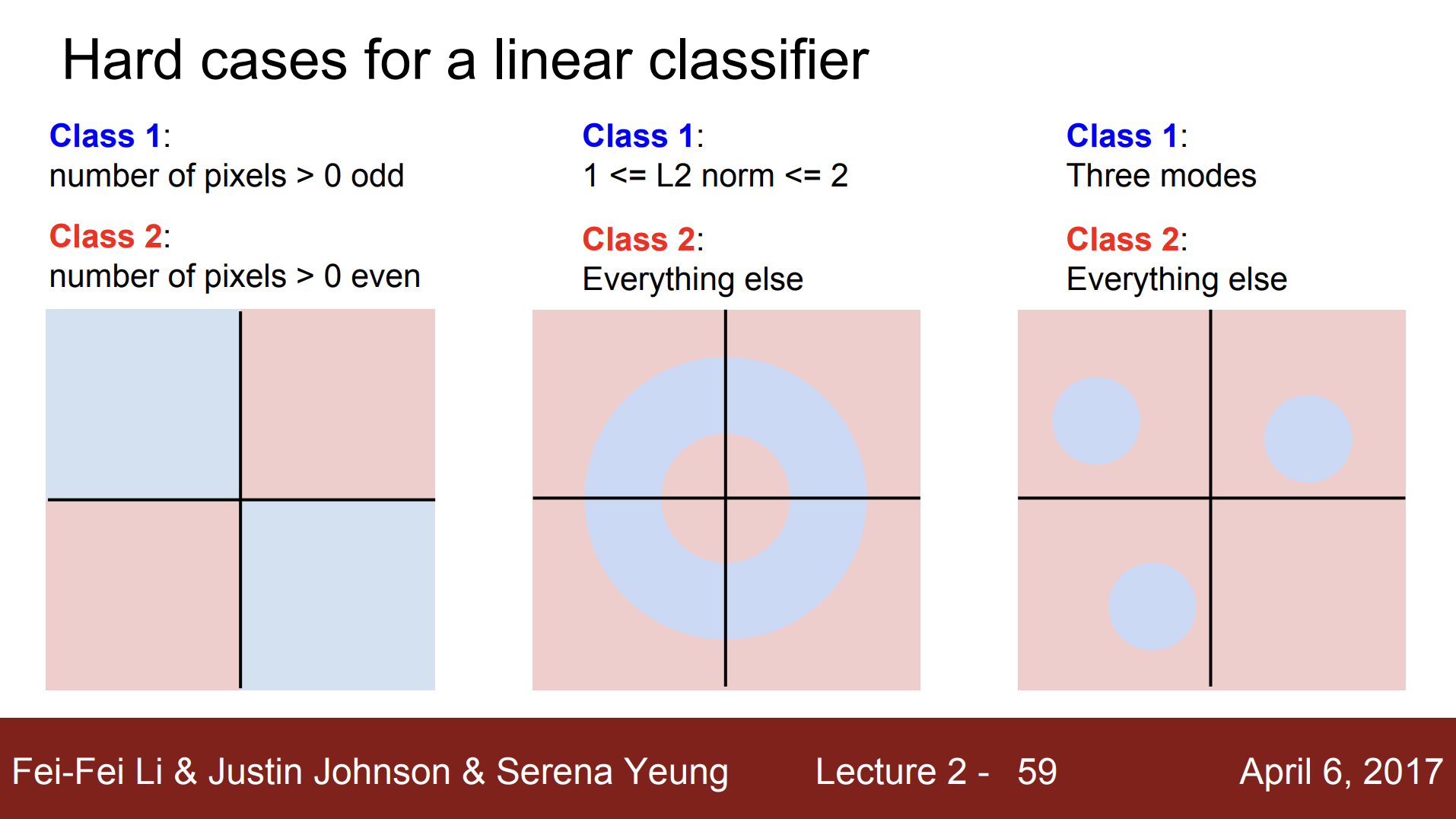
하지만 이미지가 고차원 공간의 하나의 점이라는 관점에서도 Linear classification에 나타나는 문제가 있다.
parity problem
맨 왼쪽 이미지는 두 개의 클래스를 가진 데이터 셋이다. 파랑색 카테고리는 0보다 큰 픽셀이 홀수 개인 경우를 나타내고, 빨간색 카테고리는 0보다 큰 픽셀이 짝수 개인 경우를 나타낸다. 이 데이터는 선 하나로 분류할 수 없기 때문에 Linear classifier로 풀 수 없다. 홀수, 짝수를 분류하는 것과 같은 반전성 문제(parity problem)는 일반적으로 Linear classification으로 풀기 힘든 문제이다.
Multimodal problem
맨 오른쪽 이미지를 보면 파란색 카테고리가 세 개의 점으로 분포되어 있다. Multimodal data의 경우, 한 클래스가 다양한 공간에 분포하게 되는데, 그렇게 되면 Linear classifier로는 풀기 힘들다.
