
지난 1편에서는 DeepSeek-VL의 등장 배경과 기존 시각-언어 모델(VLM)들이 직면했던 한계점(해상도 제약 및 언어 능력 저하 등)을 분석했습니다. 이번 2편에서는 이러한 한계를 극복하기 위해 DeepSeek 연구팀이 도입한 내부 아키텍처와 단계별 학습 파이프라인(Training Pipeline)을 심층적으로 다룹니다.
DeepSeek-VL의 아키텍처 설계 철학은 다음 세 가지 핵심 목표를 달성하는 데 맞춰져 있습니다.
1. 고해상도 이미지 처리 효율성 극대화
2. 기반 모델의 강력한 언어 추론 능력 보존
3. 실세계(Real-world) 복잡한 데이터의 실용적 인지
1. DeepSeek-VL의 핵심 아키텍처: 3단 모듈 구조의 고도화
DeepSeek-VL의 전반적인 아키텍처는 LLaVA 등에서 사실상 표준(De facto standard)으로 자리 잡은 접근법을 따라 이미지 인코더(Vision Encoder), 비전-언어 어댑터(VL Adaptor), 대규모 언어 모델(LLM)의 세 가지 주요 모듈로 구성됩니다. 그러나 '실세계의 고해상도 정보 처리'라는 특수한 목적을 달성하기 위해 각 모듈 내부의 공학적 메커니즘을 철저히 고도화했습니다.
1.1. 하이브리드 비전 인코더 (Hybrid Vision Encoder)
단일 저해상도 인코더에 의존하던 기존 모델과 달리, DeepSeek-VL은 의 고해상도 이미지를 처리하기 위해 SigLIP-L과 SAM-B라는 이기종 인코더를 병렬로 결합(Hybrid)하여 사용합니다.
-
SigLIP-L (저해상도, ):
- 역할: 이미지의 전반적인 의미(Coarse semantic meaning)를 빠르게 추출합니다. CLIP 계열의 인코더 특성상 이미지-텍스트 간 정렬(Alignment) 성능이 우수하여 전역적 맥락을 파악하는 데 유리합니다.
- 한계 보완: 논문에서는 CLIP 계열 모델이 시각적으로 다른 이미지라도 의미가 비슷하면 유사한 임베딩으로 매핑해버리는 이른바 "CLIP-blind pairs" 문제가 존재한다고 지적합니다. 이를 보완하기 위해 아래의 고해상도 인코더를 병행합니다.
-
SAM-B (고해상도, ):
- 역할: SigLIP의 한계를 극복하고 픽셀 수준의 시각적 그라운딩(Visual grounding) 능력을 향상시키기 위해 도입되었습니다. Segment Anything Model(SAM) 기반으로 설계되어 복잡한 문서나 다이어그램의 미세한 디테일을 포착합니다.
- 한계 보완: 고해상도 이미지를 단독으로 처리할 경우 연산량이 기하급수적으로 증가하여 추론 효율성이 떨어집니다. 이 원시 피처(Raw feature)들은 이어지는 어댑터를 통해 효율적으로 압축됩니다.
1.2. 비전-언어 어댑터 (Vision-Language Adaptor)
시각 인코더에서 추출된 피처(Feature) 행렬을 LLM의 텍스트 임베딩 공간으로 매핑하며, 동시에 LLM으로 전달되는 토큰 수를 압축하여 연산 부하를 줄이는 역할을 수행합니다. 이를 위해 2-Layer Hybrid MLP 구조를 채택했습니다.
구체적인 차원(Dimension) 변환 과정은 다음과 같이 설계되었습니다.
- 고해상도 피처 맵 압축: SAM-B가 이미지로부터 생성한 차원의 고해상도 피처 맵을 차원으로 보간(Interpolation)합니다. 이후 Stride가 2인 컨볼루션(Convolution) 레이어 2개를 통과시켜 차원으로 축소하고, 이를 최종적으로 형태로 리셰이프(Reshape)합니다.
- 독립적 MLP 연산 (Layer 1): 위 과정을 거친 차원의 SAM-B 피처와, 동일하게 차원을 갖는 SigLIP-L 피처를 준비합니다. 두 피처의 특성이 다르므로, 각각 독립적인 단일 레이어 MLP(Multi-Layer Perceptron)를 먼저 통과시킵니다.
- 결합 및 사상 (Layer 2): 첫 번째 레이어를 통과한 두 피처를 차원(Dimension) 방향으로 결합(Concatenation)합니다. 이후 결합된 피처를 두 번째 MLP 레이어에 한 번 더 통과시켜, 최종적으로 언어 모델(LLM)의 입력 공간(Input space)에 완벽히 호환되도록 매핑합니다.
결과적으로 모델은 해상도의 방대한 시각 정보를 '2048 차원을 가진 576개의 시각 토큰(Visual token)'으로 압축해 냅니다. 이는 실세계의 복잡한 디테일을 보존하면서도 LLM의 연산 부하를 가중시키지 않는 최적화된 설계입니다.
1.3. 언어 모델 (Language Model)
멀티모달 모델의 최종 추론과 답변 생성은 결국 언어 모델(LLM)의 몫입니다. DeepSeek-VL은 멀티모달 데이터를 처리하면서도 텍스트 본연의 추론 능력을 극대화하도록 구성되었습니다.
- 기반 모델: 방대한 텍스트 코퍼스로 자체 사전 학습된 DeepSeek-LLM (1.3B, 7B)을 베이스 모델로 활용합니다.
- 아키텍처 특성: LLaMA 계열에서 검증된 최신 아키텍처 원칙(Pre-Norm 구조, RMSNorm, SwiGLU 활성화 함수, RoPE)을 그대로 채택하여 대규모 멀티모달 학습 과정에서의 수학적 안정성을 확보했습니다.
- 토크나이저: 텍스트 처리의 일관성과 호환성을 유지하기 위해 DeepSeek-LLM과 완전히 동일한 토크나이저를 사용합니다.
2. DeepSeek-VL의 학습 파이프라인: 3단계 학습 전략 (3-Stage Training Pipeline)
우수한 아키텍처를 갖추었더라도, 멀티모달 모델은 시각 정보(Vision)를 새롭게 학습하는 과정에서 기존에 획득한 언어 능력(Language)이 훼손되는 '파국적 망각(Catastrophic Forgetting)' 현상이 빈번하게 발생합니다.
DeepSeek-VL은 이 딜레마를 극복하고 '강력한 언어 추론 능력'과 '고해상도 시각 인지 능력'을 동시에 확보하기 위해, 모달리티 간의 간섭을 최소화하는 3단계 학습 파이프라인(3-Stage Training Pipeline)을 도입했습니다.
2.1. Stage 1: 비전-언어 어댑터 웜업 (VL Adaptor Warm-up)
시각적 특징(Visual Features)을 LLM의 텍스트 임베딩 공간에 초기 정렬(Alignment)하는 단계입니다. 대규모 파라미터의 급격한 변화를 방지하기 위해 기초적인 의미론적 연결(Semantic Alignment)에 집중합니다.
- 학습 방식:
- Vision Encoder & LLM: 가중치를 고정(Frozen)시켜 사전 학습된 강력한 인지 및 추론 능력을 보존합니다.
- VL Adaptor: 오직 어댑터 모듈의 파라미터만 학습(Trainable)시킵니다.
- 데이터 및 손실 함수: 약 125만 개의 이미지-텍스트 쌍(ShareGPT4V 등)과 250만 개의 문서 OCR 데이터를 활용합니다. 대조 학습(Contrastive Loss)은 배제하고, 입력된 이미지 픽셀을 설명하는 텍스트 영역에 대한 '다음 토큰 예측(Next Token Prediction)' 방식만으로 손실(Loss)을 계산합니다.
- 엔지니어링 근거: 논문의 실험 결과(아래 표 참조)에 따르면, 1단계에서 데이터 규모(Training Step)를 무작정 늘리는 것이 성능 향상으로 직결되지 않거나 오히려 악화됨을 확인했습니다. 이는 파라미터 용량이 적은 어댑터 단독 학습만으로는 한계가 명확하며, 이후 LLM의 가중치 동결을 해제하는 2단계 공동 학습이 필수적임을 시사합니다.
[표 1: Stage 1 데이터 규모에 따른 멀티모달 벤치마크 성능 변화]
| Stage 1, Training Step | MMB | MMC | SEED | POPE | MMMU | Average |
|---|---|---|---|---|---|---|
| 2K | 59.0 | 54.0 | 61.8 | 82.3 | 30.3 | 57.5 |
| 80K | 58.1 | 55.0 | 58.6 | 78.6 | 27.9 | 55.6 |
2.2. Stage 2: 공동 비전-언어 사전 학습 (Joint VL Pre-training)
DeepSeek-VL의 멀티모달 추론 능력을 결정짓는 가장 핵심적인 단계입니다. 어댑터를 통한 초기 정렬 이후, LLM의 파라미터 동결을 해제하여 시각 정보와 텍스트를 복합적으로 추론하도록 본격적인 훈련을 진행합니다.
- 학습 방식: Vision Encoder는 고정(Frozen) 유지하되, LLM과 VL Adaptor는 동시에 학습(Trainable)시킵니다.
- 최적의 데이터 믹싱 비율 (Modality Mixing Ratio):
수차례의 실험(Ablation study)을 거쳐 '언어 데이터 70% : 멀티모달 데이터 30%'라는 최적의 구성비를 도출했습니다. 순수 텍스트(Text-only) 코퍼스를 70% 비중으로 유지함으로써 언어 능력의 손실을 방지하고, 30%의 멀티모달 데이터를 통해 시각 이해도를 효과적으로 끌어올렸습니다. - 모달리티 웜업 (Modality Warm-up):
학습 초기부터 이미지를 대량 투입하지 않고, 언어 데이터 비율 100%에서 시작해 점진적으로 70%까지 낮추는(멀티모달 비율을 0% 30%로 상향) 기법을 적용했습니다. 이는 급격한 데이터 분포 변화로 인해 모델이 받는 수학적 충격(손실 함수 불안정)을 완화합니다.
(참고 자료)
- w/o modality warmup (비교군): 모달리티 웜업 없이 이미지/텍스트를 고정 비율(60:40)로 혼합하여 학습.
- w/ modality warmup (실험군): 언어 100%에서 시작해 이미지 비중을 점진적으로 증가.
- 결과 해석: Y축인 Perplexity(PPL)는 낮을수록 언어 모델의 예측이 정확함을 의미합니다. 모달리티 웜업을 적용한 실험군이 텍스트 벤치마크(Pile-test)에서 낮은 PPL을 유지하여 언어 능력이 훼손되지 않았음을 증명합니다.
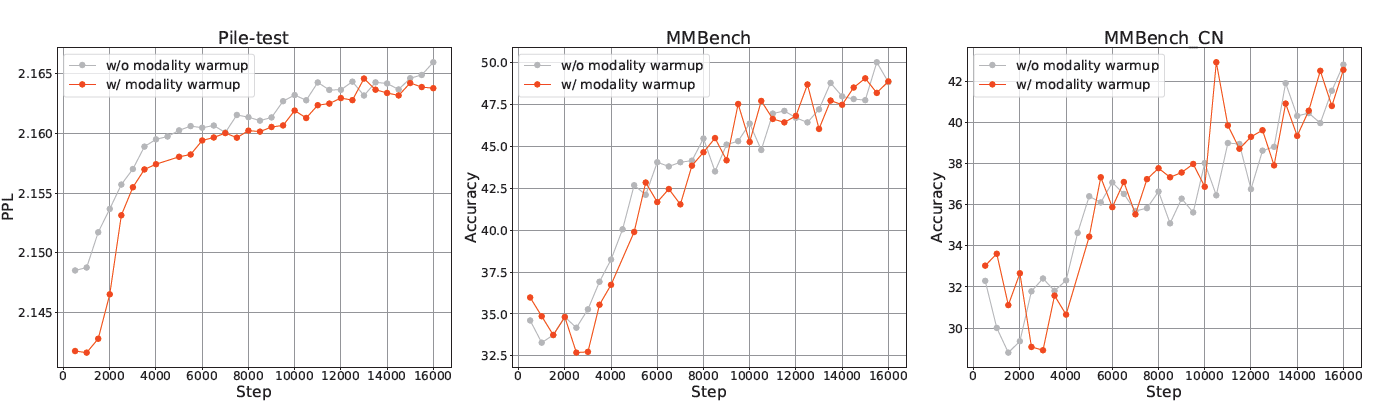
- 모달리티 그룹핑 (Modality Grouping):
GPU 연산 효율 최적화 기법입니다. 하나의 배치(Batch) 내에 텍스트와 멀티모달 데이터를 무작위로 섞을 경우, 연산이 빠른 텍스트 데이터가 연산이 느린 멀티모달 데이터의 처리를 기다려야 하는 동기화 병목(Waits for the slowest sample)이 발생합니다. 이를 해결하기 위해 순수 텍스트 그룹과 멀티모달 그룹을 분리하여 연산하도록 설계함으로써, 전체 학습 속도를 약 20% 향상시켰습니다.
2.3. Stage 3: 지도 미세 조정 (Supervised Fine-tuning, SFT)
사전 학습을 통해 지식을 축적한 모델을, 실제 사용자의 지시(Instruction)를 충실히 따르는 유용한 '대화형 어시스턴트(AI Assistant)'로 정렬(Alignment)하는 최종 단계입니다.
- 학습 방식:
GPU 메모리의 물리적 한계를 고려하여 무거운 고해상도 인코더인 SAM-B는 고정(Frozen)합니다. 반면, 저해상도 인코더인 SigLIP-L은 잠금을 해제(Trainable)하여 LLM 및 어댑터와 함께 전면적인 미세 조정을 수행합니다. - 학습 데이터:
단순 캡셔닝을 넘어, 인식(Recognition), 변환(Conversion), 논리적 추론(Logical Reasoning) 등 실세계 응용 시나리오를 8가지 범주로 세분화했습니다. 이에 맞춰 철저히 검수된 고품질 인하우스(In-house) SFT 데이터를 대량 투입하여, 복잡한 표 분석이나 문맥 추론 등 모델의 실무적인 태스크 수행 능력을 최적화했습니다.
3. 데이터 구성 및 전처리 파이프라인: 실세계 환경의 포괄
아키텍처의 고도화와 더불어, 멀티모달 모델의 성능을 결정짓는 핵심 요소는 학습 데이터의 품질과 구성입니다. DeepSeek-VL의 데이터 파이프라인은 다양성(Diversity), 확장성(Scalability), 실세계 시나리오 포괄성(Real-world Coverage)이라는 세 가지 원칙을 기반으로 설계되었습니다.
이는 통제된 벤치마크 환경을 넘어, 영수증, 웹페이지 캡처, 복잡한 구조의 PDF 문서 등 실제 사용자가 마주하는 비정형 데이터를 모델이 정확히 인지하고 처리할 수 있도록 전처리 과정을 최적화했음을 의미합니다.
3.1. 공동 사전 학습(Joint Pre-training) 데이터 구성
2단계 사전 학습(Joint VL Pre-training)에서는 모델이 다양한 모달리티의 기본 개념을 융합할 수 있도록 철저하게 구성비가 계산된 방대한 데이터를 주입합니다. 논문에 명시된 전체 데이터 믹스(Data Mix)의 세부 구성은 다음과 같습니다.
- 순수 텍스트 코퍼스 (Text-only Corpus, 70.0%): DeepSeek-LLM 사전 학습에 사용된 2T(Trillion) 토큰 규모의 텍스트 데이터를 그대로 활용합니다. 이는 멀티모달 훈련 과정에서 모델의 기존 언어 추론 능력이 훼손(Catastrophic Forgetting)되는 것을 방지하는 강력한 베이스라인 역할을 합니다.
- 인터리브 데이터 (Interleaved Image-Text, 13.1%): 텍스트와 삽화가 혼재된 문서 데이터(MMC4 등)를 사용하여, 텍스트 문맥 내에서 이미지가 지니는 논리적 의미와 상호 참조(Cross-reference) 관계를 학습합니다.
- 이미지 캡션 (Image Caption, 11.1%): Capsfusion, TaiSu 등 고품질 이미지-텍스트 쌍 데이터를 통해 객체 인식 및 기본적인 교차 모달(Cross-modal) 정렬 능력을 확보합니다.
- 문서 및 씬 OCR (Document & Scene Text OCR, 3.3%): 자연 환경 내 텍스트(Scene Text) 및 고밀도 논문 문서(Document Text)의 문자를 정밀하게 인식하는 능력을 배양합니다.
- 표와 차트 (Table and Chart, 2.1%): 시각적 구조 정보를 논리적 텍스트 정보로 파싱(Parsing)하는 능력을 훈련합니다.
- 웹 코드 (Web Code, 0.4%): 그래픽 사용자 인터페이스(GUI) 스크린샷이나 시각적 플롯을 역렌더링(Inverse Rendering)하여 코드로 변환하는 능력을 학습합니다. 이를 위해 약 110만 개의 Jupyter Notebook 기반 이미지-코드 쌍을 구축 및 활용했습니다.
💡 렌더링(Rendering) 기반 데이터 전처리:
기존 오픈소스 생태계에 고품질의 다국어(영/중문) 문서 OCR 데이터셋이 부족한 점을 극복하기 위해, 연구팀은 140만 편의 학술 논문과 100만 권 이상의 전자책(E-books) 등을 활용하여 독자적인 OCR 데이터셋을 구축했습니다.
HTML이나 PDF 코드를 단순 텍스트로 파싱하는 데 그치지 않고, 렌더링 도구(Nougat, wkhtmltopdf 등)를 활용해 시각적 렌더링 결과물(이미지) 자체를 학습 데이터로 변환했습니다. 이를 통해 모델은 텍스트 내용뿐만 아니라 레이아웃, 단락 구조 등 문서의 기하학적, 위상학적(Topological) 특징까지 통합적으로 인지하게 됩니다.
3.2. 지도 미세 조정(SFT) 데이터 믹스
3단계 SFT(Supervised Fine-tuning)는 사전 학습된 모델을 사용자 지시어(Instruction)에 맞게 정렬(Alignment)하여 실질적인 대화형 AI 어시스턴트로 최적화하는 과정입니다. 데이터는 [Instruction] -> [Input Image/Text] -> [Output] 형식으로 구성되며, 실세계 응용 시나리오 수행 능력을 극대화하기 위해 다음과 같이 데이터 믹스를 세밀하게 조정했습니다.
- 기본 추론 능력 보존 (Text-only 47.9% + General Multi-modality 35.5%):
언어 능력의 열화를 방지하기 위해 순수 텍스트 SFT 데이터를 전체의 절반 가까이 구성했습니다. 이에 더해 ShareGPT4V, LLaVA 등 검증된 멀티모달 오픈소스 데이터를 혼합하여 기본적인 명령어 추종(Instruction Following) 능력을 확보했습니다. - 시각 논리 및 실무 작업 강화 (Table & Chart 4.1% + Web Code 2.0%):
복잡한 표 데이터 분석 및 UI 스크린샷의 코드 변환 등 실무적 태스크 해결 능력을 높이기 위해 관련 특화 데이터를 편성했습니다. - 인하우스(In-house) 고품질 데이터 큐레이션 (10.5%):
모델의 실전 능력을 높인 결정적 요소입니다. 연구팀은 실제 사용자(GPT-4V, Gemini 등)가 경험하는 복잡한 시나리오를 철저히 분석하여, 모델이 수행해야 할 핵심 태스크를 인식(Recognition), 변환(Conversion), 분석(Analysis), 상식 추론(Commonsense Reasoning), 논리적 추론(Logical Reasoning), 평가(Evaluation), 다중 그래프 처리(Multi-graph), 안전성(Safety)의 8가지 영역으로 분류했습니다. 이후 전문가의 엄격한 검수를 거친 자체 구축 질문-답변(QA) 쌍을 투입하여 오픈소스 데이터가 포괄하지 못하는 한계점을 선제적으로 보완했습니다.
4. 멀티모달 융합 아키텍처 및 학습의 최적화
DeepSeek-VL은 기존 대규모 언어 모델(LLM)에 시각 처리 모듈을 단순 결합(Patching)하는 방식을 넘어, 실세계(Real-world)의 복잡한 다중 감각 정보를 통합적으로 처리하기 위해 아키텍처와 학습 파이프라인을 전면적으로 최적화한 연구입니다.
본 모델의 아키텍처 설계 및 학습 파이프라인 구축에 적용된 4가지 핵심 원칙은 다음과 같습니다.
- 실세계 중심 데이터 처리 (Real-world Centric): 통제된 학술 벤치마크 환경을 넘어, 실제 응용 시나리오에서 발생하는 비정형 데이터(고밀도 문서, 웹 UI 스크린샷 등)의 처리 성능을 최우선 목표로 설계되었습니다.
- 모달리티 간 성능 균형 (Modality Balance): 시각 정보 인지 능력을 확장하는 과정에서 기존 LLM의 언어 및 논리 추론 능력이 훼손(Catastrophic Forgetting)되지 않도록 데이터 믹싱 비율(7:3)을 엄격하게 제어했습니다.
- 연산 효율성 극대화 (Computational Efficiency): 고해상도() 시각 정보를 처리하면서도 2-Layer 하이브리드 어댑터 구조를 통해 이를 576개의 토큰으로 압축하여, 정보 손실을 최소화하는 동시에 추론 속도를 확보했습니다.
- 오픈소스 생태계 기여 (Open-source Contribution): 고도화된 아키텍처와 학습된 가중치를 1.3B 및 7B 파라미터 규모로 투명하게 공개하여, 후속 연구 및 산업적 활용의 진입 장벽을 낮추는 데 기여했습니다.
요약하자면, DeepSeek-VL은 사전 학습된 강력한 LLM을 기반으로 하이브리드 비전 인코더(SigLIP + SAM-B)를 결합하여 시각 정보 추출 성능을 높이고, 이를 비전-언어 어댑터(VL Adaptor)를 통해 LLM 공간에 사상(Mapping)했습니다.
이후 3단계의 점진적 학습 전략(Warm-up Joint Pre-training Fine-tuning)과 자체 구축한 인하우스(In-house) SFT 데이터를 통해 멀티모달 융합의 완성도를 달성했습니다. 이는 VLM(Vision-Language Model)이 직면한 해상도 한계 및 파국적 망각 문제를 해결하기 위한 시스템적 방법론을 제시합니다.
이것으로 DeepSeek-VL의 아키텍처와 학습 전략을 다룬 2편을 마무리합니다. 이어지는 [멀티모달 시리즈] 3편에서는 정량적 벤치마크 지표 분석, 정성적(Qualitative) 성능 평가, 그리고 향후 연구팀이 도입을 예고한 MoE(Mixture of Experts) 아키텍처 등 차세대 멀티모달 모델의 발전 방향에 대해 객관적인 데이터와 함께 분석하겠습니다.
