
최근 LLM 연구의 가장 뜨거운 화두 중 하나는 '장기 문맥(Long Context)' 처리 능력입니다. 이전 시리즈에서 다룬 RAG(검색 증강 생성)가 외부 지식을 가져오는 효율적인 '검색 시스템'이라면, 이번 시리즈에서 다룰 기술들은 LLM이 한 번에 읽고 사고할 수 있는 '작업 기억 공간(Working Memory)' 자체를 물리적으로 넓히는 시도들입니다.
그 첫 번째 파트로, 모델의 아키텍처를 대대적으로 수정하지 않고도 수학적인 위치 인코딩 조작만으로 문맥 창을 확장하는 YaRN(Yet another RoPE extensioN method)을 분석합니다. 본격적인 메커니즘 분석에 앞서, 왜 기존 모델들이 긴 문맥 앞에서 무너지는지 그 배경과 핵심 원리를 짚어보겠습니다.
1. 배경: 사전 학습된 컨텍스트의 물리적 제약
LLaMA, GPT-NeoX와 같은 현대적인 LLM들은 토큰의 순서 정보를 모델에 주입하기 위해 RoPE(Rotary Position Embeddings)라는 상대적 위치 인코딩 방식을 사용합니다. RoPE는 각 토큰의 위치 인덱스를 복소수 평면상의 '회전하는 각도'로 변환하여 모델이 거리감을 인식하게 만듭니다.
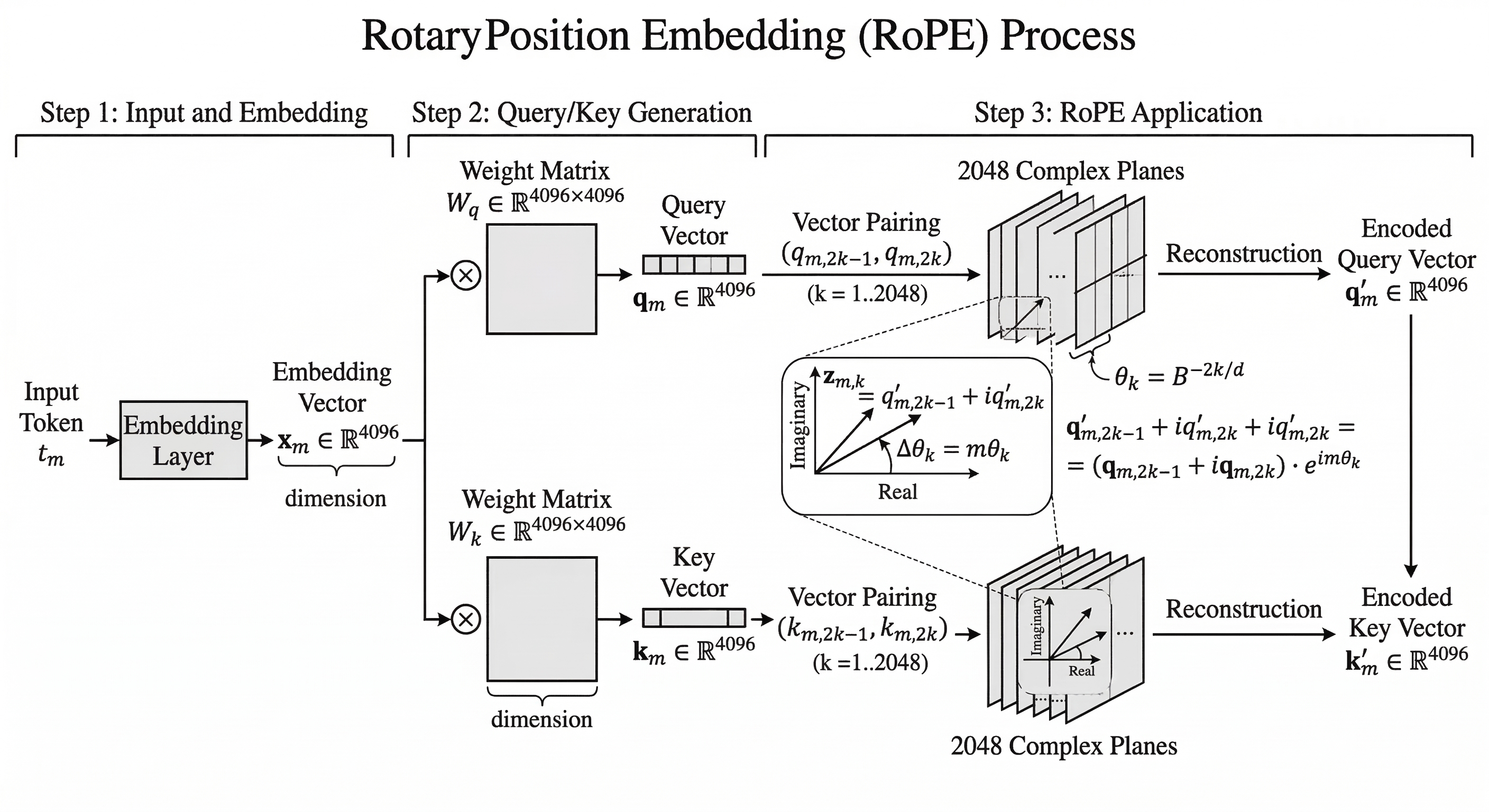
문제는 모델이 사전 학습(Pre-training) 단계에서 정해진 시퀀스 길이(예: 4,096 토큰) 내의 각도 변화만을 경험한다는 점입니다. 이 범위를 초과하는 데이터가 들어오면 모델은 학습 데이터 분포를 벗어난(Out-of-Distribution, OOD) 생소한 각도 값에 직면하게 됩니다. 이 경우 모델은 논리적 일관성을 잃고 퍼플렉서티(Perplexity)가 급격히 상승하며 추론 능력을 상실합니다.
이 제약을 해결하기 위해 모델을 처음부터 다시 학습시키는 것은 천문학적인 자원이 소모되므로, 최소한의 파인튜닝만으로 기존 모델의 문맥 수용 능력을 확장하는 기술이 연구의 핵심 과제가 되었습니다.
2. 💡 [Deep Dive] YaRN 이해를 위한 핵심 배경지식
YaRN의 혁신적인 설계를 이해하기 위해서는 위치 인코딩의 물리적 특성과 신경망의 정보 학습 원리를 명확히 파악해야 합니다.
① RoPE에서의 '파장(Wavelength, )' 개념
RoPE는 여러 은닉 차원(Dimension)에 걸쳐 위치 정보를 인코딩하는데, 차원마다 회전하는 속도가 다릅니다. 이를 시계의 바늘에 비유할 수 있습니다.
- 고주파 차원 (짧은 파장): 시계의 '초침'과 같습니다. 아주 빠르게 회전하여 바로 옆 토큰과의 각도 차이가 매우 큽니다. 이는 "내 바로 옆에 어떤 단어가 있는지"와 같은 세밀한 문법적 디테일과 로컬 맥락을 파악하는 핵심 역할을 합니다.
- 저주파 차원 (긴 파장): 시계의 '시침'과 같습니다. 아주 천천히 회전하여 시퀀스 전체를 한 바퀴 도는 데 수만 개의 토큰이 필요합니다. 이는 "이 토큰이 문서의 전반부인지 후반부인지"와 같은 거시적인 위치 정보를 제공합니다.
② 고주파 정보의 손실과 '해상도 붕괴'
기존의 위치 보간법(Position Interpolation, PI)은 문맥을 늘리기 위해 모든 차원의 파장을 동일한 비율로 잡아 늘립니다. 예를 들어 4,000칸의 정보를 8,000칸으로 늘리기 위해 모든 회전 각도를 절반으로 줄여버리는 식입니다.
이때 발생하는 치명적인 문제가 '해상도 저하'입니다. 미세한 각도 차이로 옆 단어와의 순서를 구분하던 고주파 차원들이 PI를 거치면 그 차이가 너무 미미해집니다. 비유하자면, 정밀한 지도를 고무줄처럼 잡아 늘려 골목길(디테일)이 흐릿하게 뭉개져 보이는 것과 같습니다. 모델은 결국 단어 사이의 정교한 선후 관계를 구분하지 못하게 되어 성능이 급락합니다.
③ NTK(Neural Tangent Kernel) 이론과 스펙트럼 편향
NTK 이론은 심층 신경망이 정보를 어떻게 학습하는지 설명하는 도구입니다. 여기서 주목할 개념은 '스펙트럼 편향(Spectral Bias)'입니다.
💡 스펙트럼 편향이란?
신경망이 학습 시 단순하고 큼직한 패턴(저주파)은 쉽게 배우지만, 복잡하고 미세한 패턴(고주파)은 학습하기 어려워하는 본능적인 특성을 의미합니다.
모델이 늘어난 문맥에서도 디테일을 유지하려면 입력 신호에 날카로운 고주파 성분이 반드시 보존되어야 합니다. 하지만 PI처럼 신호를 일괄적으로 부드럽게(Blurry) 만들어버리면, 신경망은 본능적으로 디테일한 위치 정보를 학습하는 데 실패하게 됩니다.
④ 외삽(Extrapolation)과 OOD(Out-of-Distribution) 문제
외삽이란 모델이 학습할 때 경험했던 데이터 범위를 벗어난 영역의 값을 처리하려 할 때 발생합니다. 특정 수치(Base)를 조정해 억지로 문맥을 늘리다 보면, 어떤 차원의 회전 각도가 사전 학습 때 한 번도 본 적 없는 범위에 도달하게 됩니다. 모델에게 이는 '듣도 보도 못한 외계어'와 같습니다. 이 경우 모델의 내부 연산이 요동치며 퍼플렉서티가 무한대로 발산하게 됩니다.
3. 기존 방법론의 한계: '디테일'과 '안정성'의 트레이드오프
YaRN이 등장하기 전, 컨텍스트 확장의 양대 산맥이었던 위치 보간법(PI)과 NTK-aware 보간법은 각각 해결하기 어려운 기술적 결함을 안고 있었습니다.
- 위치 보간법(Position Interpolation, PI)의 한계: 모든 차원의 파장을 동일한 비율()로 잡아 늘립니다. 이 경우 '초침' 역할을 하는 고주파 차원들의 각도 차이가 너무 좁아집니다. 신경망은 이 정도로 미세한 차이를 처리하도록 학습되지 않았기에, 인접 토큰의 순서를 구분하지 못하는 '해상도 붕괴'를 겪게 됩니다.
- NTK-aware 보간법의 한계: PI의 정보 소실을 막기 위해 주파수별로 스케일링을 다르게 적용했습니다. 하지만 이 방식은 '시침' 역할을 하는 저주파 차원들을 모델이 학습 시 경험하지 못한 범위 밖의 각도로 밀어냅니다(외삽, Extrapolation). 이는 모델 내부 연산을 요동치게 만들며, 특히 파인튜닝 시 성능이 불안정해지는 결과를 초래했습니다.
4. YaRN의 핵심 메커니즘: 세 가지 혁신의 기둥
YaRN은 "모든 RoPE 차원이 하는 역할이 다르다면, 보간 공식도 차원별로 달라야 한다"는 철학 아래 다음 세 가지 기법을 결합합니다.
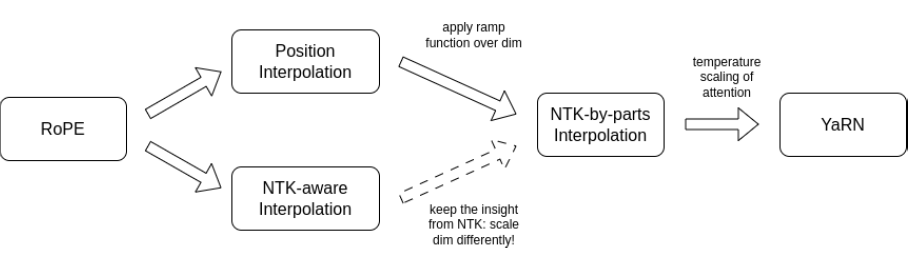
① NTK-by-parts 보간법: 차원별 맞춤형 대응
YaRN의 가장 독창적인 메커니즘으로, 문맥 길이()와 파장()의 비율()을 기준으로 전체 차원을 세 그룹으로 분리합니다.
- 고주파 영역 (): 옆 토큰과의 구분이 중요하므로 보간을 전혀 수행하지 않고 원본 값을 유지합니다.
- 저주파 영역 (): 외삽 문제를 방지하기 위해 안전하게 선형 보간(PI)을 적용하여 기존 범위 내로 값을 욱여넣습니다.
- 전이 영역 (): 두 방식 사이의 불연속성을 방지하기 위해 램프 함수(Ramp function)를 사용하여 부드럽게 혼합합니다.
② 어텐션 스케일링 (Temperature Scaling): 주의력의 엔트로피 교정
컨텍스트가 늘어나면 모델이 훑어봐야 할 후보지가 증가하여 주의력(Attention)이 분산되는 '산만한 상태(Entropy 증가)'가 됩니다. YaRN은 어텐션 로짓을 온도 파라미터 로 나누어 주의력을 다시 날카롭게 만듭니다.
(는 확장 배율). 이 수식은 확장 시 발생하는 정보의 분산을 수학적으로 상쇄하여 모델이 중요한 정보에 다시 집중하게 돕습니다.
③ 동적 스케일링 (Dynamic YaRN): 유연한 실전 적응
추론 시 입력 길이에 맞춰 스케일 팩터 를 실시간으로 업데이트()합니다. 덕분에 짧은 글을 읽을 때는 원래의 날카로운 성능을 유지하고, 긴 글이 들어올 때만 확장된 문맥 지도를 꺼내어 대응합니다.
5. 성능: 데이터와 지표로 증명된 효율성
YaRN은 실험을 통해 기존 기술을 압도하는 실무적 가치를 입증했습니다.
- 학습 효율 (Training Efficiency): PI 대비 10배 적은 토큰과 2.5배 적은 학습 단계만으로 모델을 수렴시켰습니다.
- 초장기 문맥 외삽 성공: 64k() 확장을 위해 400 스텝을 학습한 뒤, 64k 길이의 데이터로 단 200 스텝만 추가 학습(총 600 스텝)했음에도 불구하고, 모델은 128k() 영역까지 안정적으로 외삽해내며 낮은 퍼플렉서티를 유지했습니다.
- Passkey Retrieval 99.4% 달성: 128k의 거대한 텍스트 속에 숨겨진 숫자를 찾는 테스트에서 전 구간 99.4%의 정확도를 기록하며 실질적인 기억 능력을 증명했습니다.
6. 결론: 실무적 의의와 한계
YaRN은 "모델의 구조를 바꾸지 않고 위치를 알려주는 방식(Encoding)만 우아하게 교정하여 기억력을 32배 이상 늘릴 수 있다"는 것을 입증했습니다. 특히 64k 모델에서 128k 모델로 한 번 더 확장할 때 발생하는 성능 하락폭이 평균 0.49%에 불과하다는 점은 이 기술의 안정성을 보여줍니다.
하지만 YaRN 역시 해결하지 못한 숙제가 있습니다. 위치 정보를 최적화하더라도 시퀀스가 길어질수록 어텐션 연산에 필요한 메모리(VRAM) 점유율이 제곱()으로 폭발한다는 점입니다.
이어지는 [Part 2. 압축 메모리를 결합한 어텐션의 혁신 (Infini-attention)] 편에서는, 이 '책상 공간' 문제를 해결하기 위해 어텐션 메커니즘 자체를 어떻게 개조했는지 살펴보겠습니다.
