프로젝트
1.[FastAPI] FastAPI와 DB 연결

나는 BERT 감성분석 프로젝트를 진행하며, fast api를 활용하여 DB,백을 구축하였다. 지금 DB 실시간 연동을 위해 다시 코드를 뜯어보는 중인데, Fast API와 DB를 연결하는 방법에 대해 작성해보겠다. 객체와 관계형 데이터베이스의 자동으로 매핑(연결)해주
2.[ERROR] SentensePieceTokenizer 에러

Fast Api 코드를 돌리는데 토크나이징 부분에서 지속적으로 같은 에러가 발생한다. 에러 내용은 다음과 같다. 어제부터 하루종일 에러 해결 시도중인데, 아까는 alpha 값은 인자로 설정할 수없다고 하더니 이번엔 설정하라고 한다. ㅠㅠ 오늘 안으로 끝내고 싶다...
3.[ERROR] SentencePieceTokenizer 에러 해결

TypeError: init() got an unexpected keyword argument 'enable_sampling'이런 에러가 발생하였는데, chatgpt에 물어보니 아래와 같은 답변을 주었다. gluonnlp.data.transforms.Sentencepi
4.[MYSQL] 프로젝트 진행 상황과 문제 발생

요새 계속 크롤링 코드 고치고DB에 데이터가 자꾸 중복으로 들어가서 ㅠㅠㅠㅠ 이거땜에 며칠동안 머리가 아팠다. DELETE JOIN을 활용해서 중복된 데이터 값을 하나만 남기고 모두 지우려고 시도하다가 기존 데이터가 다 삭제되어 버려서 멘붕이 왔었지만 백업해둔 데이터가
5.[프로젝트] 해결해야 할 문제들

주식 상승 / 하락 데이터 크롤링해서 db에 넣기 1-1) 크롤링 코드 만들기 1-2) 크롤링하기 1-3 크롤링 한 데이터 db에 넣기 1-4) 테이블 조인하기 : 종목명 or 종목 코드 or id값으로 1-5) 머신러닝/ 통계 분석 기법 중 선택하여 분석하기 ORG
6.[프로젝트] 갑자기 문제 해결

알고보니.. 내가 조인할 때 잘못해서 생긴 문제였다. ㅋㅋㅋㅋㅋㅋ ㅠㅠㅠㅠㅠ 그래도 이 문제 해결하려면 갈 길이 멀었는데 지금이라도 알아서 너무 다행이다..도움을 준 바덕이에게 감사 ❤️🔥히히 이제 결과 잘 나온당 중복 데이터만 없애면 된다\~~!!! 농담곰님 감사
7.[MySQL] 중복 데이터 제거
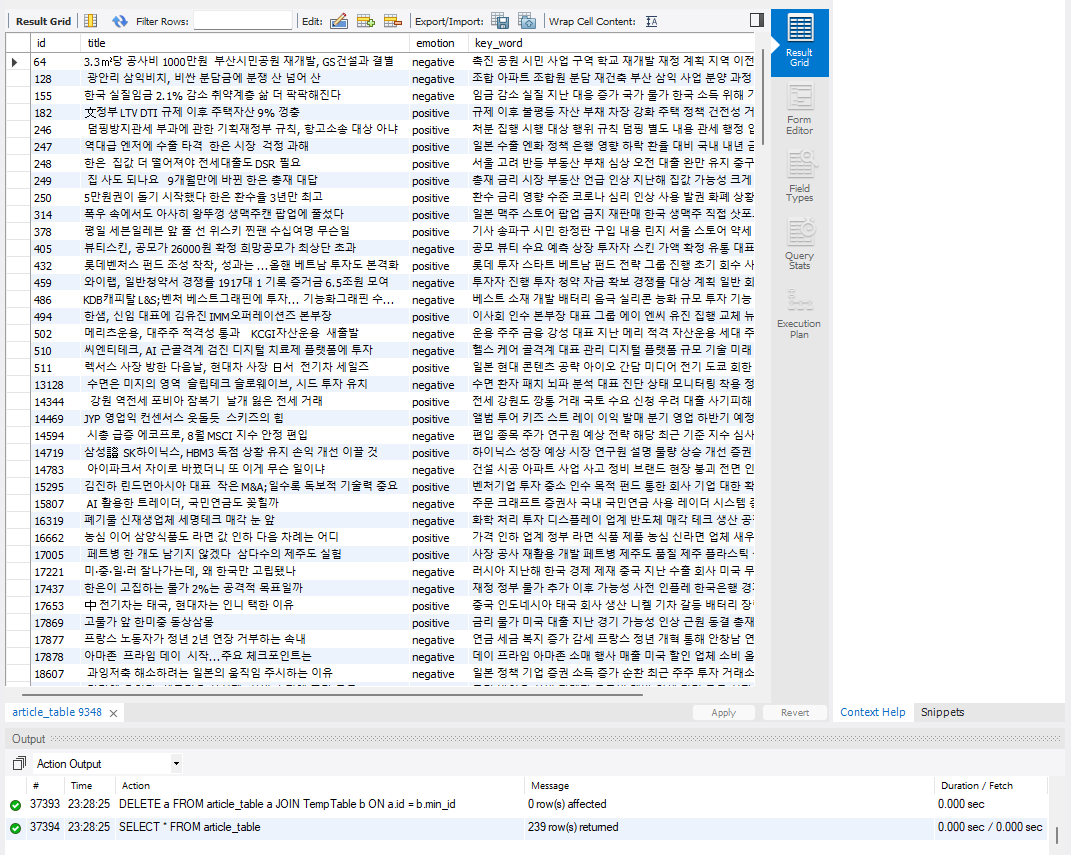
지난 글 : https://velog.io/@jsyun0412/MYSQL-%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-%EC%A7%84%ED%96%89-%EC%83%81%ED%99%A9%EA%B3%BC-%EB%AC%B8%EC%A0%9C-%
8.[프로젝트] 진행 상황

: 중복 데이터 처리하는 코드를 추가하였으나, 여전히 중복 데이터가 들어옴 : db에 21개의 기사가 추가되었음 4\. 감성분석 테이블과의 상관관계 분석을 통한 가설 검증
9.[프로젝트] 현재 진행 상황과 문제점

중복 데이터 삭제하고 다시 기사 크롤링 하며 데이터 수집하는 중 ORG 코드의 성능 문제 -> 코드 개선이 필요 긍/부정 분류 모델의 성능 문제 -> 정확도 향상이 필요 -> 다른 모델을 사용해야 하나 ?크롤링 할 때 지속적으로 중복 기사가 db에 들어가는 문제 ->