
실시간 다중 채팅 서비스 프로젝트를 진행하며 겪었던 문제와 해결과정을 기록합니다.
성능 벤치마크에 관한 포스팅을 참조해주세요.
1. 문제 상황과 원인 분석
샤딩으로 RDB가 분산되는 환경을 대비해 레코드별 식별자 할당 전략을 고민했습니다.Auto Increment전략의 경우 현재 프로젝트처럼 단일 DB환경에서는 큰 문제가 없지만 DB가 분산될 경우 PK 중복 문제와 식별자 할당 전략이 DB 시스템에 의존적인 문제로 새로운 전략을 수립해야 합니다.
2. 문제 해결
2.1 해결 방안 1 - UUID
UUID는 32자리의 16진수로 중복될 여지가 거의 없는 고유성을 제공합니다.- 자바에서 지원하는
UUID는version 4로 32개 필드 모두 무작위의 16진수로 생성됩니다. 따라서 생성 시점에 따른 시간 순 정렬이 불가능합니다. MySQL innoDB엔진은 프라이머리 인덱스를B-Tree기반 자료구조로 각 레코드를 저장합니다. 새로운 레코드가 생성되고 PK값이 시간순으로 정렬할 수 없을 때 인덱스 트리 구조가 크게 바뀌면서 작업 수행 시간이 증가합니다.MySQL에서 생성하는UUID는version 1으로 타임스탬프 값과 MAC주소를 사용해 식별자 값을 생성합니다. 시간 순 정렬이 가능하지만 MAC주소 노출로 인한 보안 문제를 일으킬 여지가 있고 식별자 생성을 DBMS에 의존하게 됩니다.UUID는 버전에 관계없이 128비트 공간을 차지합니다. 정수형 자료형에 비해 I/O 작업과 저장공간 효율성이 떨어집니다.
2.2 해결 방안 2 - TSID
- 64비트 정수 자료형을 사용하는
TSID를 적용할 수 있습니다.TSID는 42비트의 밀리 초 단위 타임스탬프와 분산환경에서 머신 노드 ID 지정을 위한 가변 0 ~ 20비트, 카운터 2 ~ 22비트로 구성됩니다.

- 정수 자료형을 사용해 바이너리 자료형이나 문자열 자료형보다 간단한 비교, 범위 연산 처리를 수행할 수 있어 조회 쿼리에서 더 나은 성능을 기대할 수 있습니다.
- 또한 식별자가 시간순으로 정렬가능한 값으로 생성되기때문에
MySQL Index의 삽입 연산에 있어 더 나은 성능을 기대할 수 있습니다.
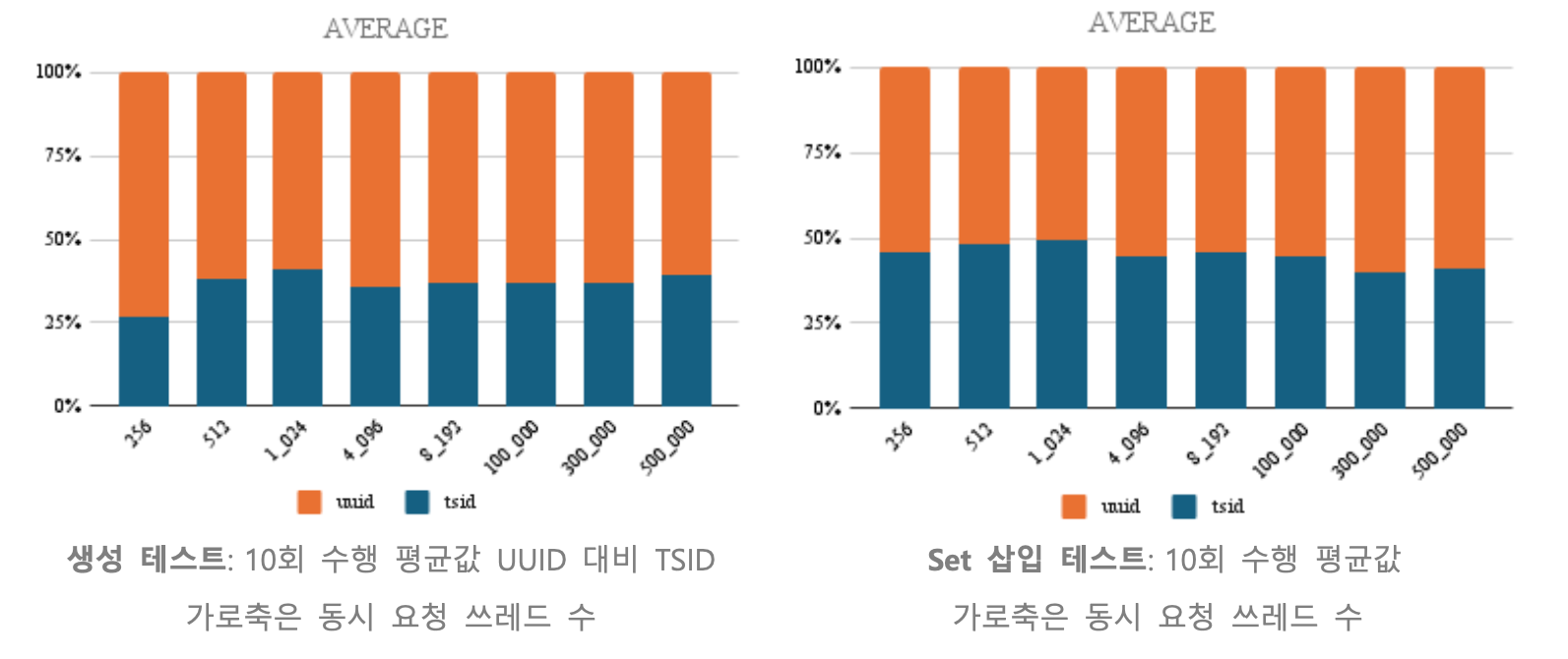
벤치마크 테스트
동시 요청이 집중되는 상황을 가정하고 256회 ~ 500,000회 까지 동시 요청 수를 늘려가며 테스트를 수행하고 결과를 차트로 구성했습니다. UUID의 생성은 Java의 util 패키지에서 지원하는 기능을 사용했습니다.
벤치마크 테스트 환경
- Lang: Java17
- TSID Library: f4b6a3 TSID
- 테스트 결과 데이터 및 차트: 생성 테스트, Set 삽입 테스트
- 테스트 레포지토리: GitHub
- 테스트 과정 포스팅: Velog
식별자 인스턴스 생성 테스트 결과
3. 적용한 방법
- 벤치마크 성능에서 더 나은 지표를 보여주는 TSID를 적용했습니다.
- 64비트 자료형 크기로 TSID도 과거 Y2K 문제처럼 69년(또는 부호가 없는 자료형이라면 139년) 동안 사용할 수 있고 시간 순 정렬이 가능한 UUID version 7가 대안이 될 수 있지만 저장공간을 절반으로 줄일 수 있는 이점을 고려해 TSID를 적용했습니다.

Hi. I'm Neo