
들어가기에 앞서..
이번 프로젝트 티켓팅 플랫폼 Ticket 에서 저는 공연관련 도메인을 맡았습니다.
보통 조회 관련한 기능들이 구현했는데요, 홈화면에 있는 인기공연 top10 이나 예매 예정과 같은 경우 빠른 속도의 응답이 중요합니다.
처음 local 에서 개발했을 때는 데이터가 6000건이었기 때문에 응답 속도 관련해서 문제가 나타나지 않았습니다.
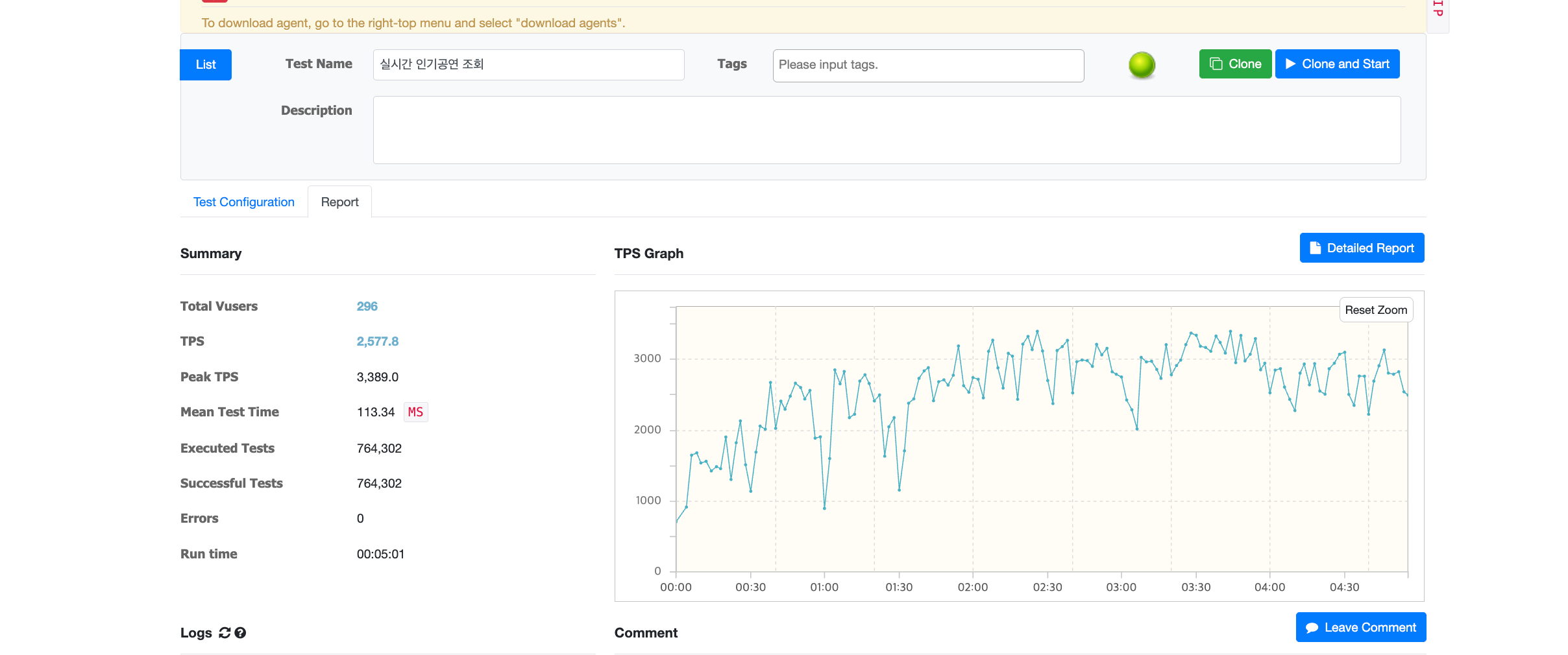
위 사진은 간단하게 300 vuser 를 5분간 보낸 결과입니다.
TPS 는 2000건 이상에 1초 이내, 에러율 0 퍼센트로 아주 안정적인 환경으로 확인될 수 있었습니다.
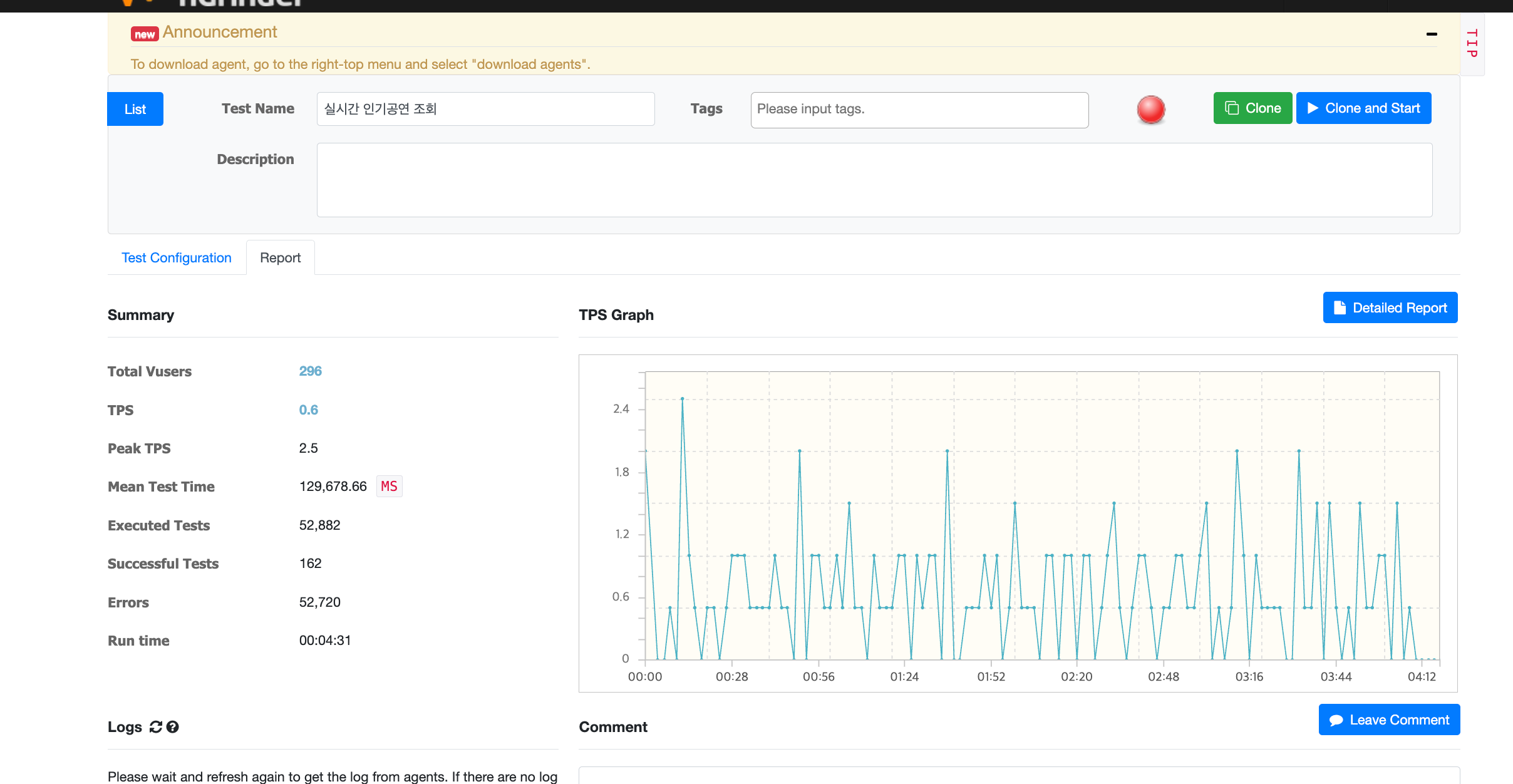
문제 상황은 이때부터 였습니다. 공연 데이터를 불려서 3000만건 데이터를 쌓은 이후, macbook m3 pro 에서 postgres 를 배포하여 사용하였습니다.
데이터도 늘어났을 뿐만아니라 네트워크를 한 번 타고 오는 속도라 그런지 TPS 가 1 이하로 나오는 처참한 결과가 나왔습니다.
문제해결(1)
어떻게 해결할지에 대해 고민 후, 쿼리 튜닝이 필요한 것 같아 mybatis 의 mapper 를 확인해 보았습니다.
<select id="findRelatedPerformances" resultType="PerformanceDto">
SELECT
p.performance_id AS performanceId,
p.performance_title AS title,
p.performance_date AS date,
p.performance_img AS img
FROM performance p
JOIN status s ON p.status_id = s.status_id
WHERE p.genre_id = #{genreId}
AND p.performance_id != #{performanceId}
AND p.performance_deleted_at IS NULL
AND s.status_code != 201
ORDER BY p.performance_look_count DESC, p.performance_date ASC
LIMIT 5
</select>⇒ 이미 fk 로 값을 상태 id 를 가져오기 때문에 join 으로 조회하지 않게 모든 mapper 수정하였습니다.
<select id="findRelatedPerformances" resultType="PerformanceDto">
SELECT
p.performance_id AS performanceId,
p.performance_title AS title,
p.performance_date AS date,
p.performance_img AS img
FROM performance p
WHERE p.genre_id = #{genreId}
AND p.performance_id != #{performanceId}
AND p.performance_deleted_at IS NULL
AND p.status_id IN (1,2)
ORDER BY p.performance_look_count DESC, p.performance_date ASC
LIMIT 5
</select>⇒ 이후 4798ms 에서 최대 약 3222ms 정도로 줄어들었지만 아직도 느리다는 걸로 확인이 됩니다.
문제해결(2)
인덱스 적용 후 300 요청시에 약 319 TPS로 안정적이게 되었습니다.
-- 1) 장르별 목록/카운트/관련공연 (정렬: performance_date ASC)
CREATE INDEX CONCURRENTLY IF NOT EXISTS idx_perf_genre_active_date
ON performance (genre_id, performance_date)
WHERE performance_deleted_at IS NULL AND status_id IN (1,2);
-- 2) 전체 인기 Top10 (정렬: look_count DESC, start_date ASC)
CREATE INDEX CONCURRENTLY IF NOT EXISTS idx_perf_hot_global
ON performance (performance_look_count DESC, performance_start_date ASC)
WHERE performance_deleted_at IS NULL AND status_id IN (1,2);조건문에서 쓰이는 정렬 및 상태값 등을 인덱스를 타게하여 조회 속도를 빠르게 증가시켰습니다.
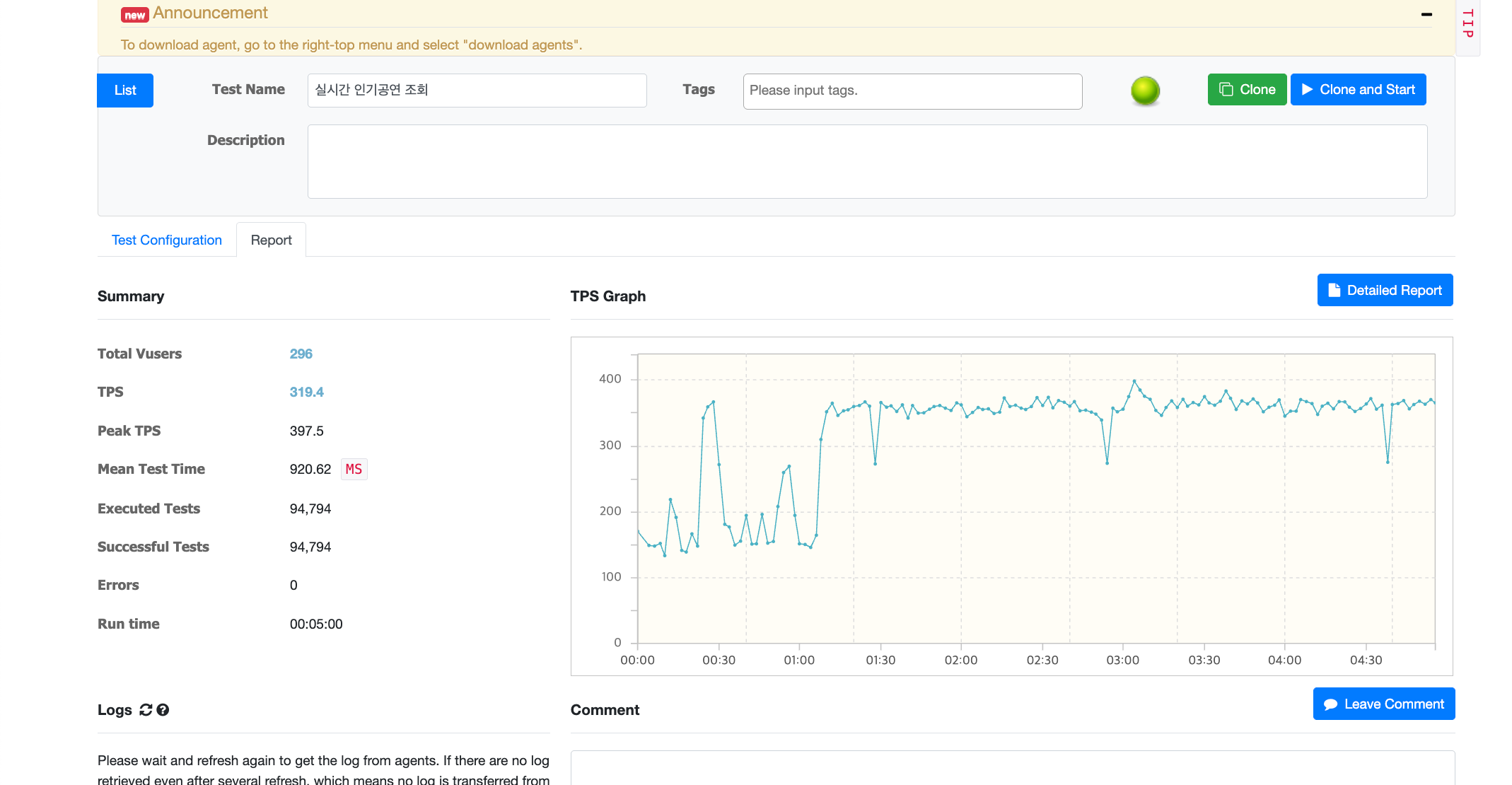
(워밍업 요청을 안해서 초반 그래프가 위태로운 점 양해 부탁드립니다.)
nGrinder 를 보면, 1초 이내 300vuser 요청시 300 이상의 TPS 가 나오는 안정적인 응답 속도 결과로 3000만건의 대량 데이터 속에서도 빠른 응답 속도가 가능하도록 구축하였습니다.
왜 인덱스를 적용하면 응답 속도가 빨라지는 걸까요?
인덱스란?
- 데이터베이스에서 원하는 데이터를 빨리 찾기 위해 미리 만들어 둔 책갈피 같은 것
- 테이블 전체를 다 뒤지지 않고, 특정 값을 빠르게 조회할 수 있게 도와줌
- 성능 최적화의 핵심 도구
- 인덱스 없는 검색 (Full Table Scan)
- 책에서 단어를 찾는다고 가정해보면, 처음부터 끝까지 모든 페이지를 읽으면서 찾는 것
- 데이터가 적으면 괜찮지만 데이터가 수백만 수천만 건이면 너무 오래걸림
- 인덱스 있는 검색
- 책의 찾아보기 처럼, 단어가 어디 페이지에 있는지 미리 정리해둠
- 데이터 베이스도 특정 컬럼 값을 정렬하거나, 조각내서 별도 자료 구조(B-Tree, Hash, GIN 등)에 저장해둠
- 검색 시 테이블 전체를 안 보고, 인덱스만 빠르게 탐색 → 후보만 찾아서 접근
- 인덱스 종류
- B-Tree 인덱스(기본형)
- 정렬된 형태로 저장
- =,<,>,BETWEEN,ORDER BY 같은 검색에 빠름
- Hash 인덱스
- 해시 값으로 빠르게 찾음
- 동등 비교(=) 전용
- GIN 인덱스(Generalized Inverted Index)
- 텍스트 검색, 배열에 감함
- 트라이그램(pg_trgm) 같이 문자열 검색에도 사용
- GiST 인덱스
- 범위,공간 데이터,유사도 검색 등에 활용
- 인덱스의 장점과 단점
- 장점
- 검색 속도 비약적으로 향상(수십 배 ~ 수백 배)
- 큰 데이터셋에서도 실시간에 가까운 성능 가능
- 단점
- 인덱스 자체가 추가 저장공간 차지
- 데이터 삽입/수정/삭제 시 인덱스도 갱신해야 해서 쓰기 성능은 느려질 수 있음
⇒ 때문에 조회가 자주 일어나는 컬럼 위주로 신중히 만들어야 한다.
- 공연 검색에 대입하기
- 인덱스 없음
- 공연 1천만건이 있으면, 매번 1천만건을 전부 읽어야함(20초 소요)
- 인덱스 있음(pg_trgm GIN)
- 제목을 3글자 단위로 쪼개서 인덱스에 저장
- “스트리트” 검색시 “스트”,”트리”,”리트” 조각이 있는 것만 빠르게 찾음
- 실제 검색 대상은 수천 건으로 줄어들 것으로 예상
무엇을 배웠는가
앞으로는 자주 호출되는, 빠른 응답을 사용해야하는 경우 인덱스를 사용해야 겠다는 것을 배웠습니다. 하지만 많은 사용은 저장공간을 차지하기 때문에 오히려 더 많은 성능 저하를 일으킬 수 있다는 것도 깨닫게 되었습니다.
