RDS 오버뷰
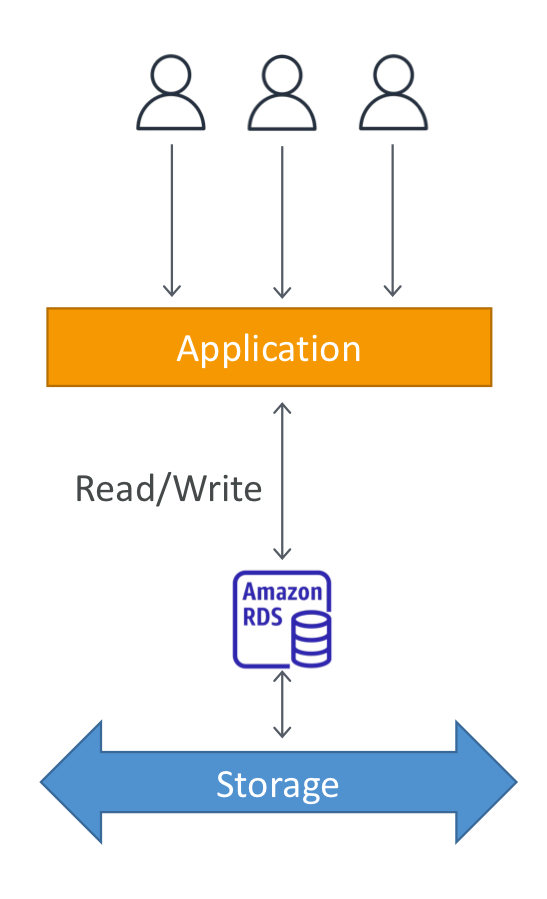
- RDS: 관계형 데이터베이스 서비스
- RDS 서비스를 통해 클라우드에서 데이터베이스를 만들 수 있게 하고, AWS가 이것을 관리함.
- 단점: RDS 인스턴스에 SSH 접속할 수 없음.
EC2 인스턴스에 DB 서비스 배포 VS RDS 사용
- RDS는 인스턴스에 SSH 할 수 없고, AWS가 관리하는 서비스라서 내부 EC2에 접근 불가하다는 단점이 있음.
RDS 특징 및 장점
1. 저장소 자동 크기 조정
- 응용 프로그램이 RDS DB에 읽고 쓰기를 많이 하면 자동으로 임계값과 함께 저장소가 배율을 조정함.
- 최대 저장소 임계값 설정이 필요함.
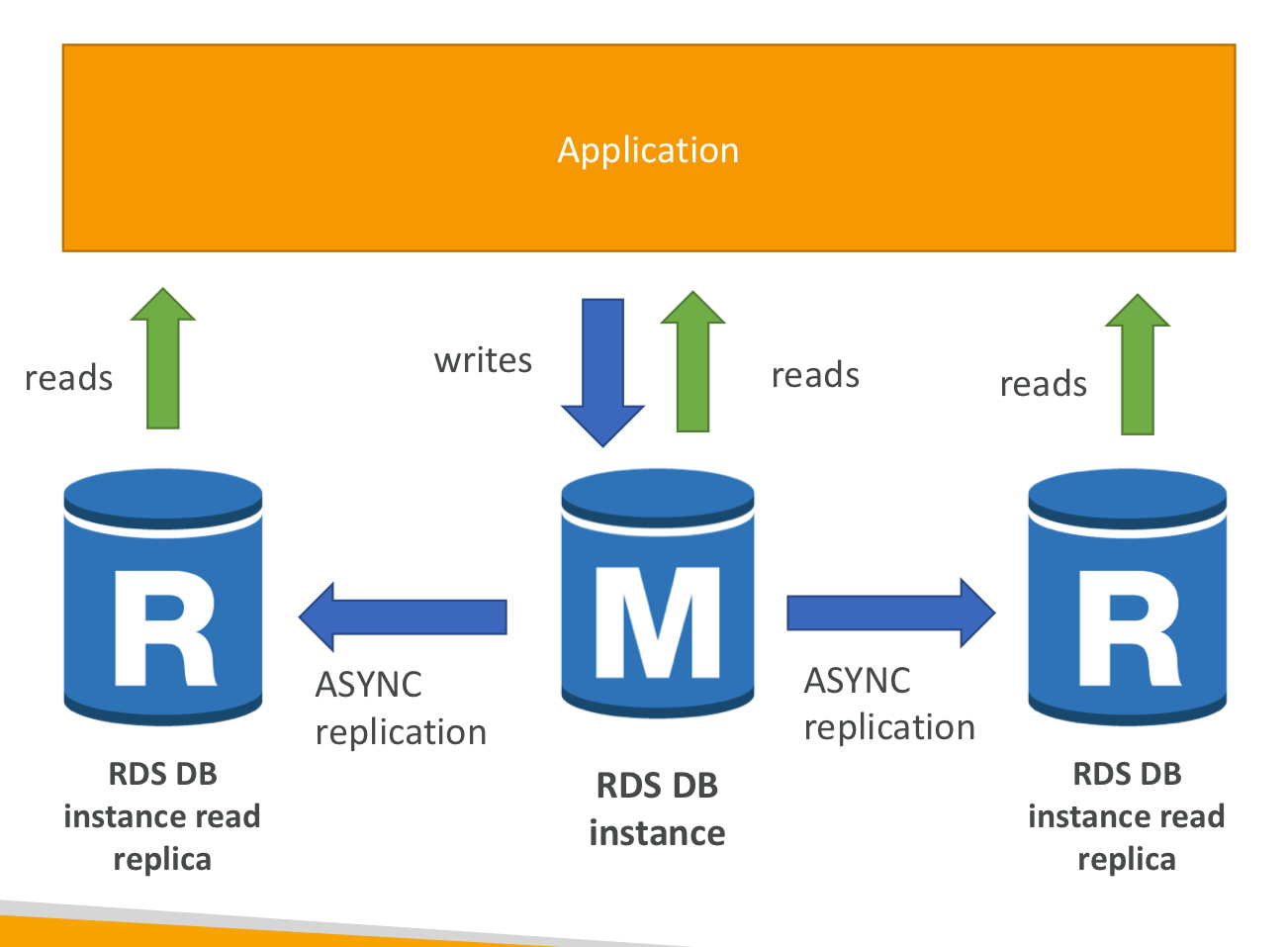
2. 읽기 복제본
- 15개까지 읽기 복제본을 만들 수 있음.
- 같은 AZ 이내, 다른 AZ 밖에서, 다른 리전 밖에서 만들 수 있음.
- 고유 DB로 승격될 수 있음.
- 예를 들어, 앱이 데이터를 복제하기 전에 읽기 복제본에서 읽는다면 모든 데이터를 얻을 수 있음. -> 비동기적(ASYNC) 복제 지속
비동기(ASYNC): 병렬적으로 테스트를 수행, 요청 보낸 후 응답 수락 여부와 관계없이 다음 테스크 동작. 수락 대기 시간 동안 또다른 요청을 처리하는 장점 있음.
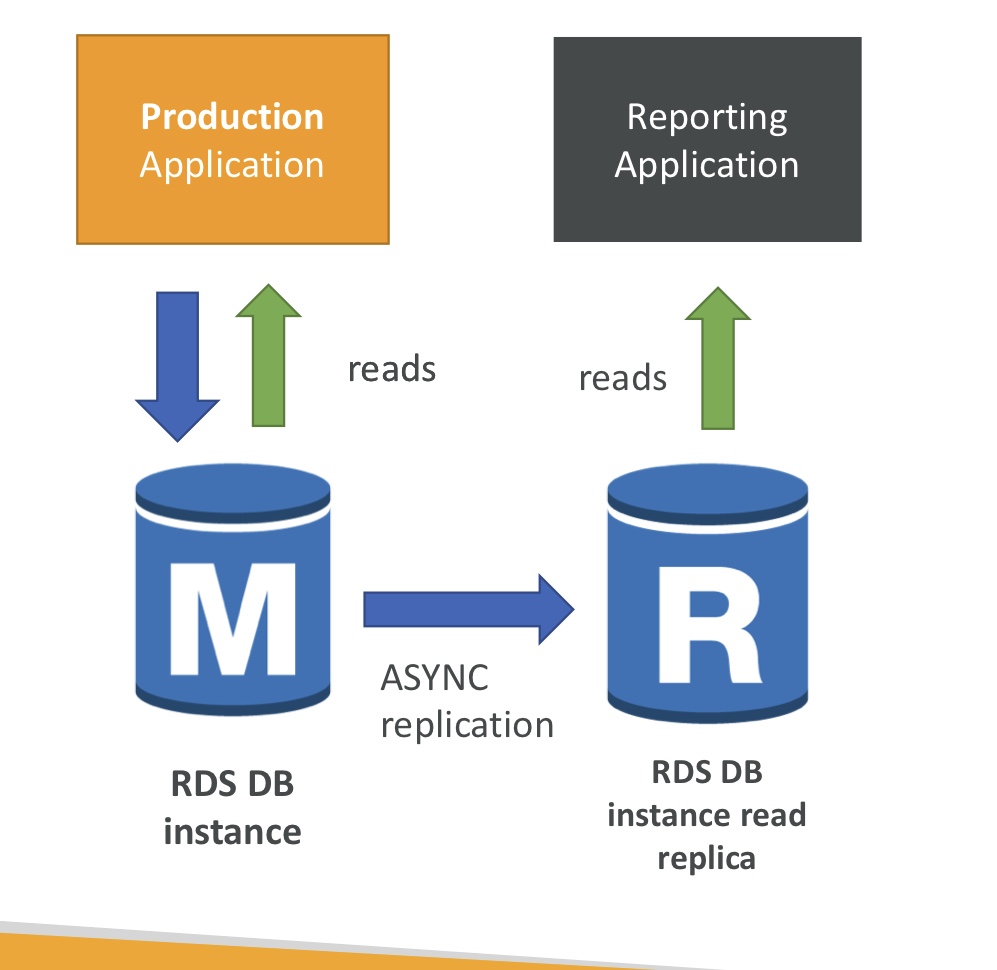
3. 복제본 사용 케이스
- 프로덕션 DB를 분석하고 싶을 때, RDS DB 인스턴스에 해당 리포팅 프로그램을 플러그인하면 오버로드 가능(속도 느려짐) -> 따라서 새 작업을 실행할 리드 복제본을 만들기
- 프로덕션 DB는 RDS DB의 인스턴스를 읽고 쓰기
- RDS DB 인스턴스를 비동기 복제하여 리드 복제본을 만듦.
- 리포팅 응용프로그램은 복제본에서 읽기를 함.
4. 네트워크 비용
- 리드 복제본을 비동기 복제할 때 같은 지역, 다른 AZ에서 비용은 무료임.
- 하지만 다른 지역이라면 비용 발생함.
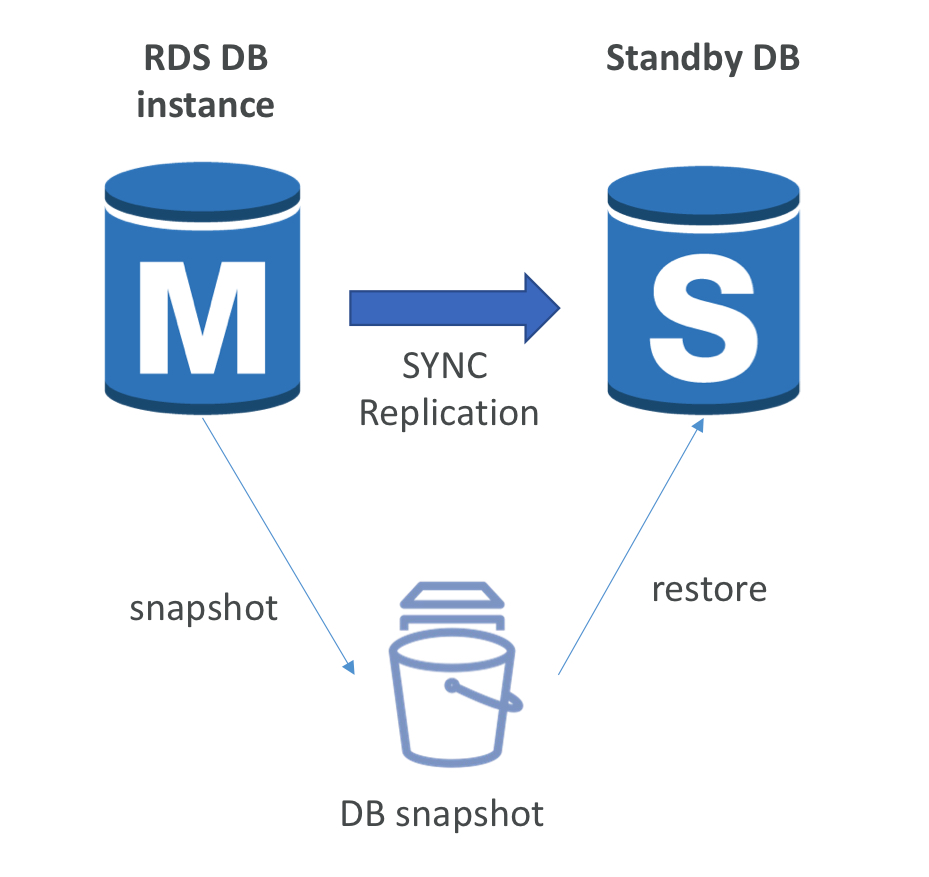
5. 멀티 AZ
- 마스터의 모든 변화를 동기 복제함. 응용 프로그램이 마스터 DB를 읽고 쓸 때, 그 변화도 대기 상태에서 만들어짐.
- 마스터 DB 인스턴스는 AZ-A에 위치하고, 대기 DB 인스턴스는 AZ-B에 위치하여 멀티 AZ임.
DNS(Domain Name System): 도메인 이름을 IP주소로 변환. 응용 프로그램이 하나의 DNS 이름에 반응하고 마스터에 문제 생기면 대기 DB에 자동으로 장애 조치를 함.
중요: 리드 복제본은 피해 복구를 위해 다중 AZ로 설정될 수 있다 (O)
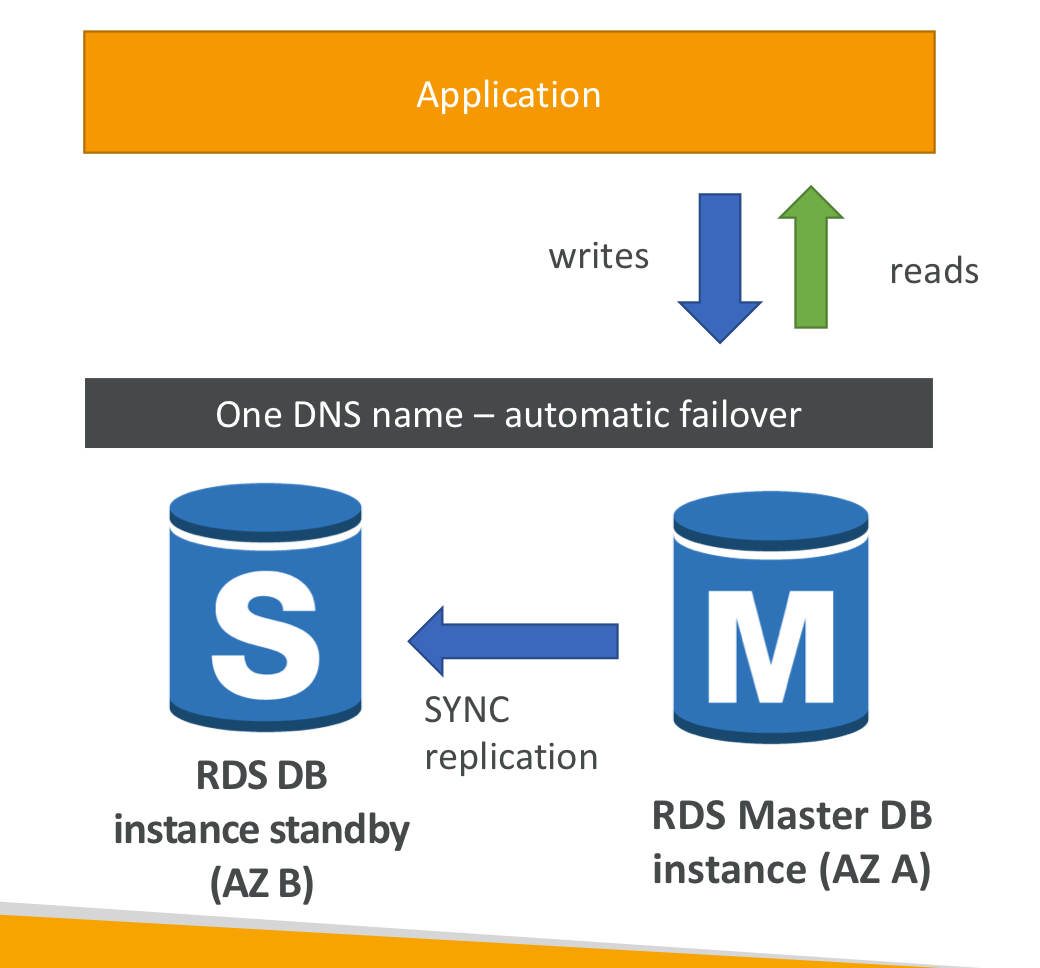
6. 하나의 AZ를 다중 AZ로 만드는 방법
- 가동 중지 시간이 0. DB를 중단해서 만들 필요 없음.
- 1) 인스턴스가 마스터를 갖게 됨.
- 2) 메인 DB의 RDS가 자동으로 찍은 스냅샷은 새로운 대기 DB로 복원됨.
- 3) 대기 DB가 복구되면 두 DB 사이 동기화(SYNC)가 설정됨. 대기 DB가 메인 RDS DB를 따라잡음.
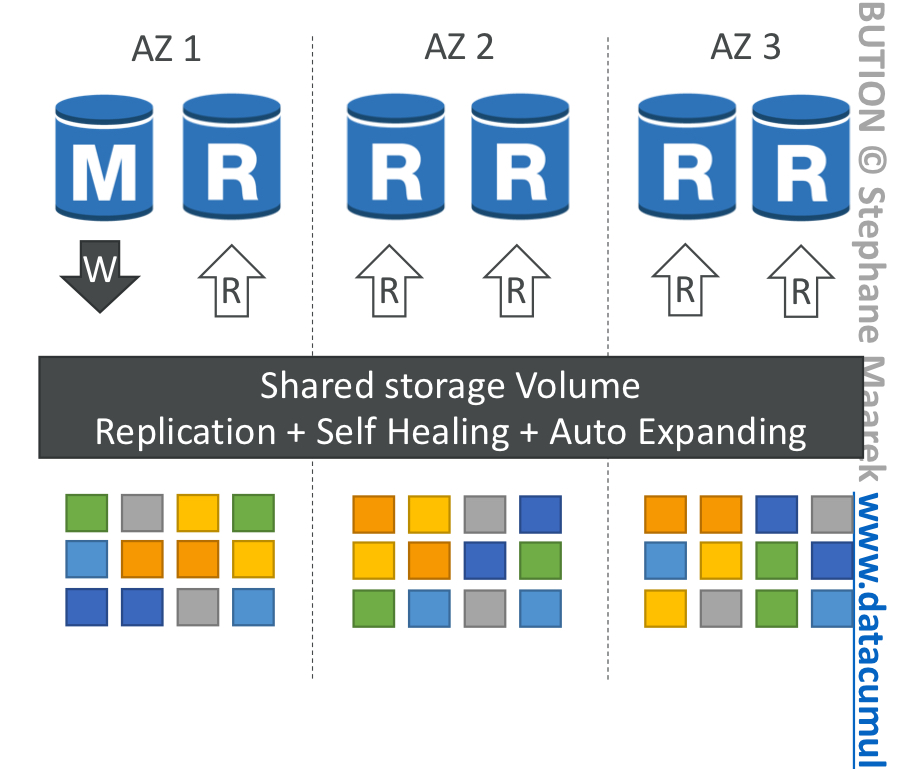
Amazon Aurora
고가용성과 읽기 스케일링
- 데이터를 작성하면 3개의 AZ에 6개의 데이터 카피를 만들 수 있음.
- 공유 저장소 볼륨은 복제, 자가치유, 자동 확장 기능을 가짐.
- 쓰기 인스턴스(마스터 인스턴스)는 1개이고, 읽기 복제본 15개까지 만들어 읽기 작업 스케일링 할 수 있음.
- 장점: 교차지역 복제 지원 -> 마스터 하나에 다중 판독 복제품이 있는데, 저장소 볼륨이 자동 확장 기능을 통해 복제한 것임.
오로라 디비 클러스터
- Writer Endpoint: 마스터는 Writer Endpoint를 가지는데, DNS 이름과 Writer Endpoint는 항상 마스터를 가리킴. 마스터가 실패해도 클라이언트는 여전히 Writer Endpoint에 말할 수 있고 자동으로 인스턴스로 리디렉션됨.
- Reader Endpoint: 모든 읽기 복제본에 자동 연결함. 클라이언트가 Reader Endpoint에 연결하면 읽기 복제본 중 하나에 연결되고, 이렇게 부하 분산을 함.
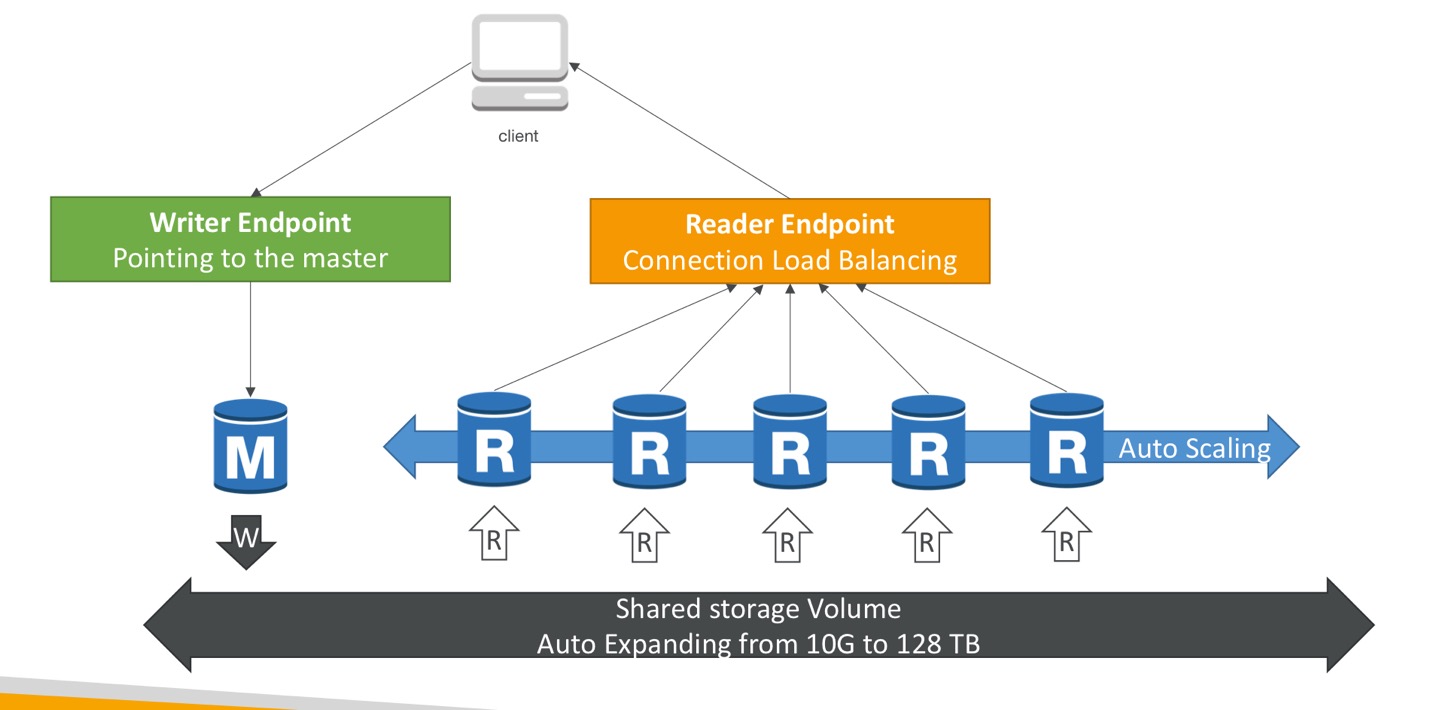
복제 자동 배율
- 리더 엔드포인트에서 읽기 요청이 많다면, 오로라 db의 CPU 사용이 증가함.
- 이때, 복제본 자동 배율 설정, 복제본 추가됨. -> 자동으로 엔드포인트 확장돼 새로운 복제본을 다룸. 이 새로운 복제본은 어떤 트래픽을 받기 시작하고, 읽기는 더 분산된 방식으로 발생해 CPU 사용을 분산함.
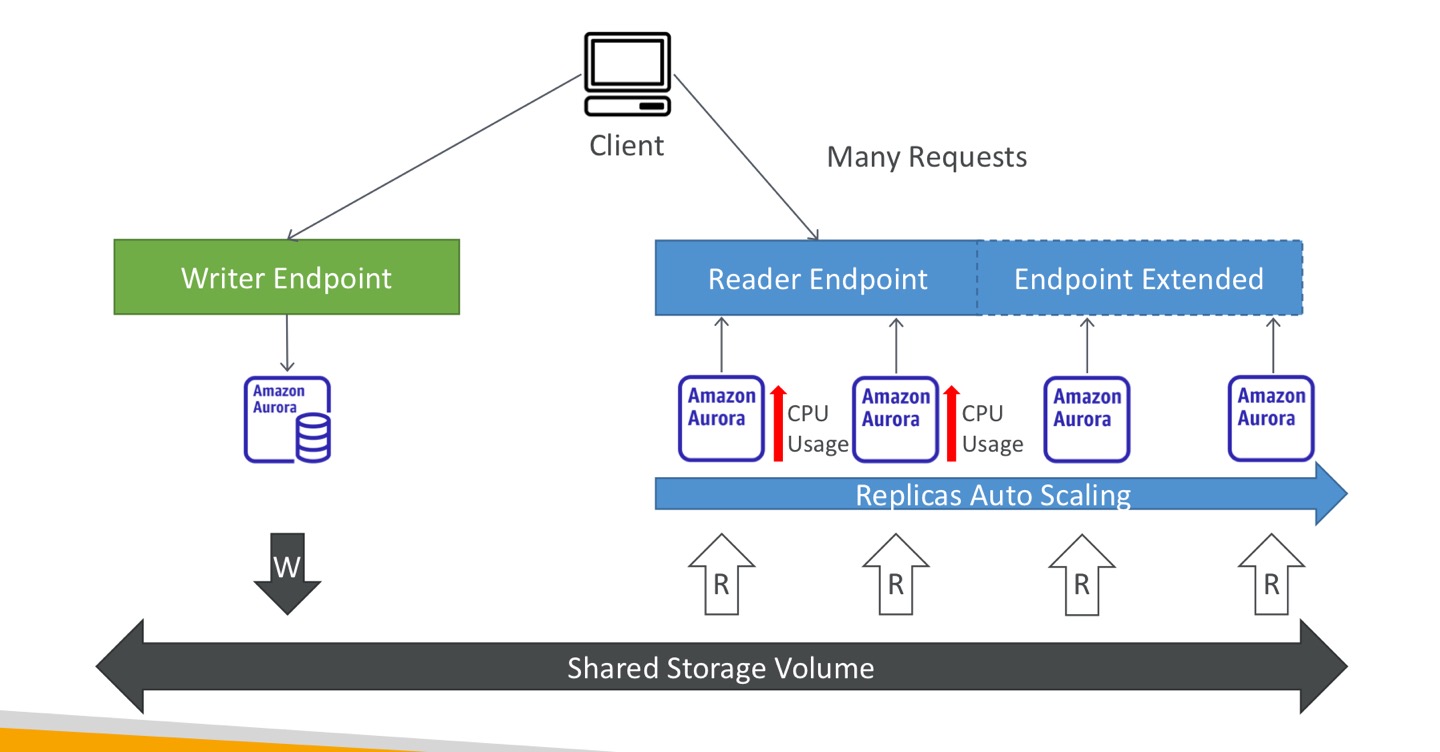
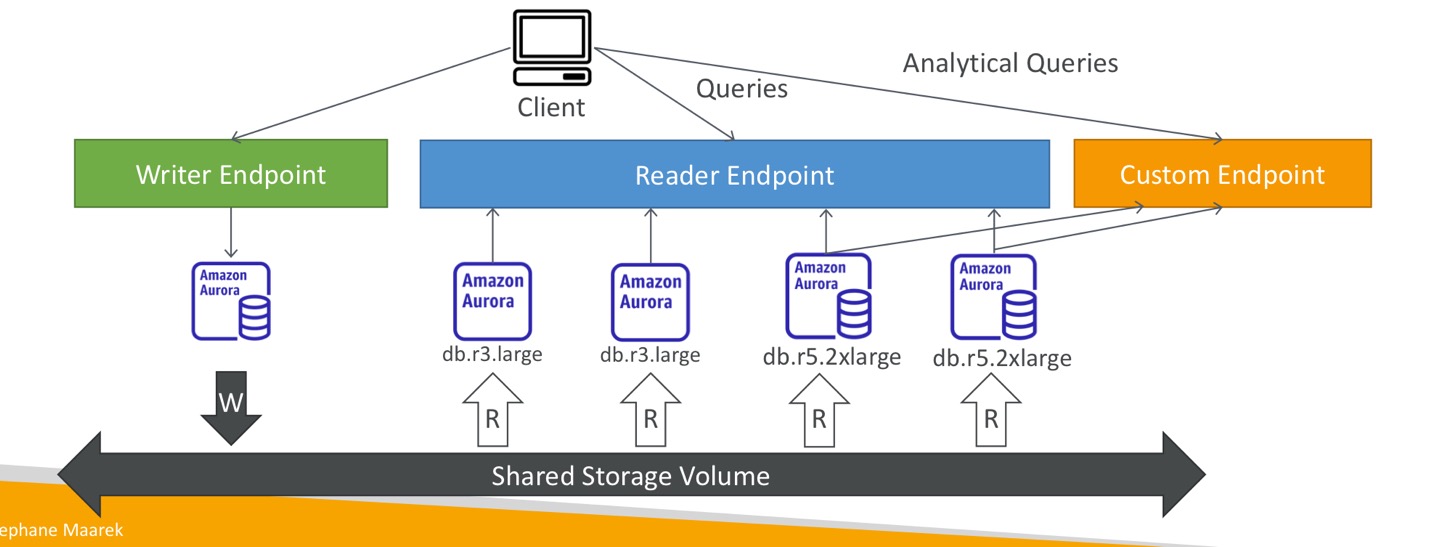
커스텀 엔드포인트
- 오로라 인스턴스의 하위집합을 커스텀 엔드포인트로 정의함. 그곳에서 분석적 쿼리를 실행함.
- 리더 엔드포인트는 커스텀 엔드포인트를 정의한 후에 사용되지 않음.
서버리스
- 클라이언트가 Proxy Fleet(프록시 플릿)에 연결됨.
- 백엔드에서 서버 없이 오로라 인스턴스가 만들어짐.
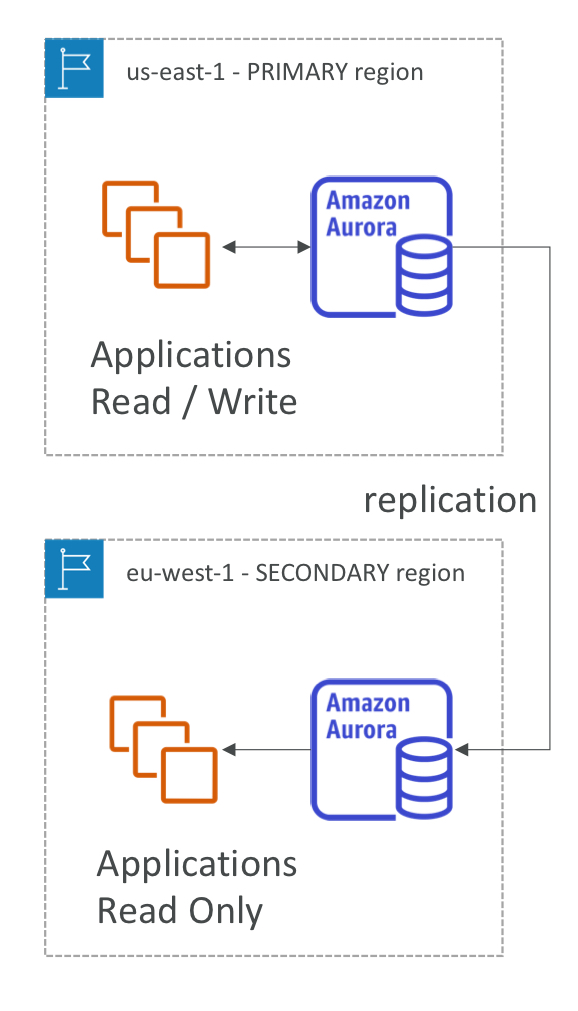
글로벌 오로라
- 오로라 전세계 db에 해당 지역 데이터를 복제하는데 1초도 안 걸림.
- primary 리전에서 응용 프로그램 읽기 쓰기를 하는데, 이때 아마존 오로라를 복제해 secondary 지역의 응용 프로그램은 오직 읽기만 가능하게 한다.
RDS 백업
- 자동 백업, 수동 스냅샷
- RDS 멈춰도 저장소 비용을 내야 하니, 비용적은 스냅샷을 찍고 나중에 사용할 때 복원하는 게 좋음.
Aurora DB Cloning
-
프로덕션 오로라에서 테스트를 실행하고 싶을 때 데이터를 복제하고 싶음.
-
Production Aurora db를 복제하고 새로운 db 클러스터인 Staging Aurora를 만들고자 함.
-
Production db에는 아무 영향 주지 않고 Staging db를 만들 수 있음.
-
복제(Cloning)는 복사 프로토콜 사용함.
- 처음엔 원본 db 클러스터와 같은 데이터 볼륨을 사용함.
- 새 db 클러스터에 데이터 업데이트되면 추가적인 저장소 할당되고 데이터는 복사되고 분리됨.
Aurora RDS Proxy
-
응용 프로그램에서 RDS db 인스턴스에 연결하는 대신 프록시에 연결.
-
프록시에 연결하면 람다 함수는 RDS 프록시를 오버로드 하겠지만, RDS db 인스턴스에 덜 연결된 연결을 풀어 오버로드 문제는 해결함.
-
장점
-
DB 효율 향상
- RDS DB 연결 감소해 DB 효율이 향상됨(CPU, RAM 사용 감소, DB 접속시간 최소화)
-
장애조치(failover) 시간 66%까지 줄임.
- RDS 프록시가 RDS DB의 장애조치를 처리.
-
DB를 위한 IAM 인증 시행
- IAM 이용해서 RDS DB 인스턴스에 연결. 자격증명이 AWS 비밀 관리자에 안전하게 저장.
-
공개적으로 액세스 불가
-
RDS 프록시는 VPC 내에서만 가능하고 인터넷으로 연결 불가.
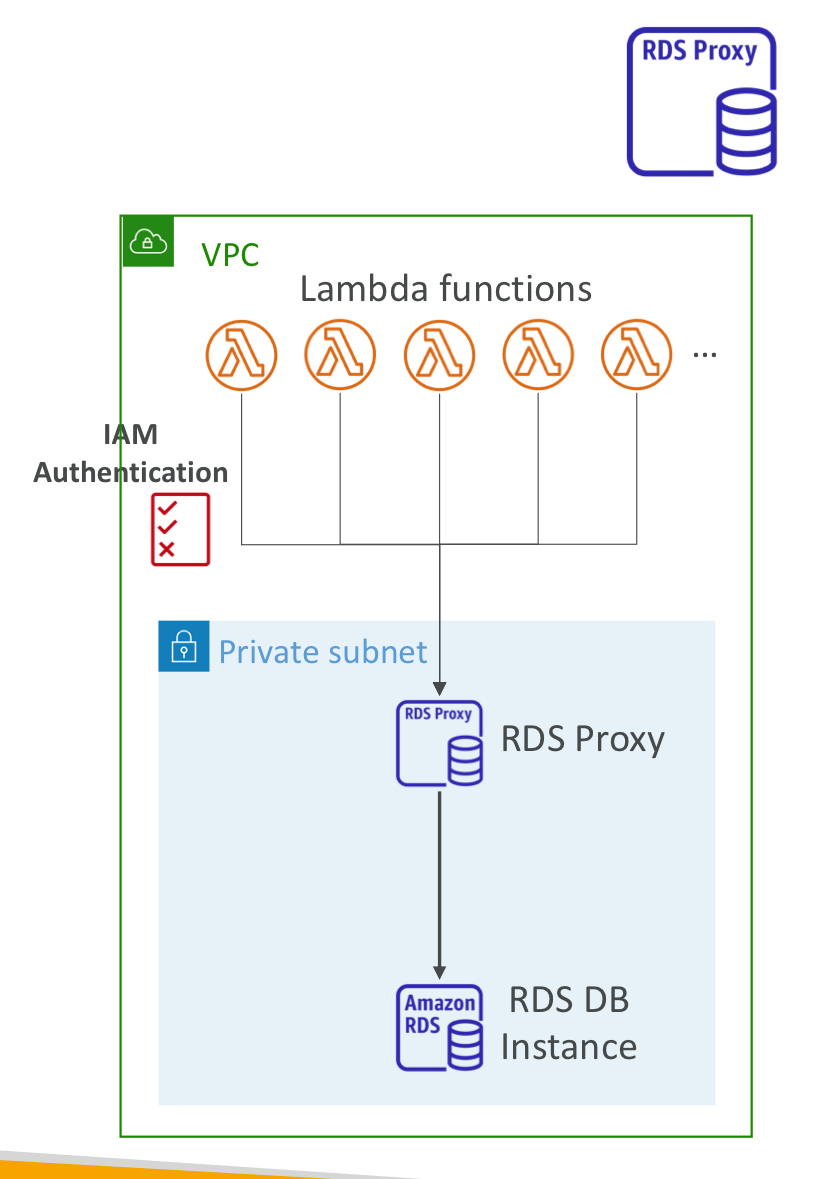
-
-
ElasticCache
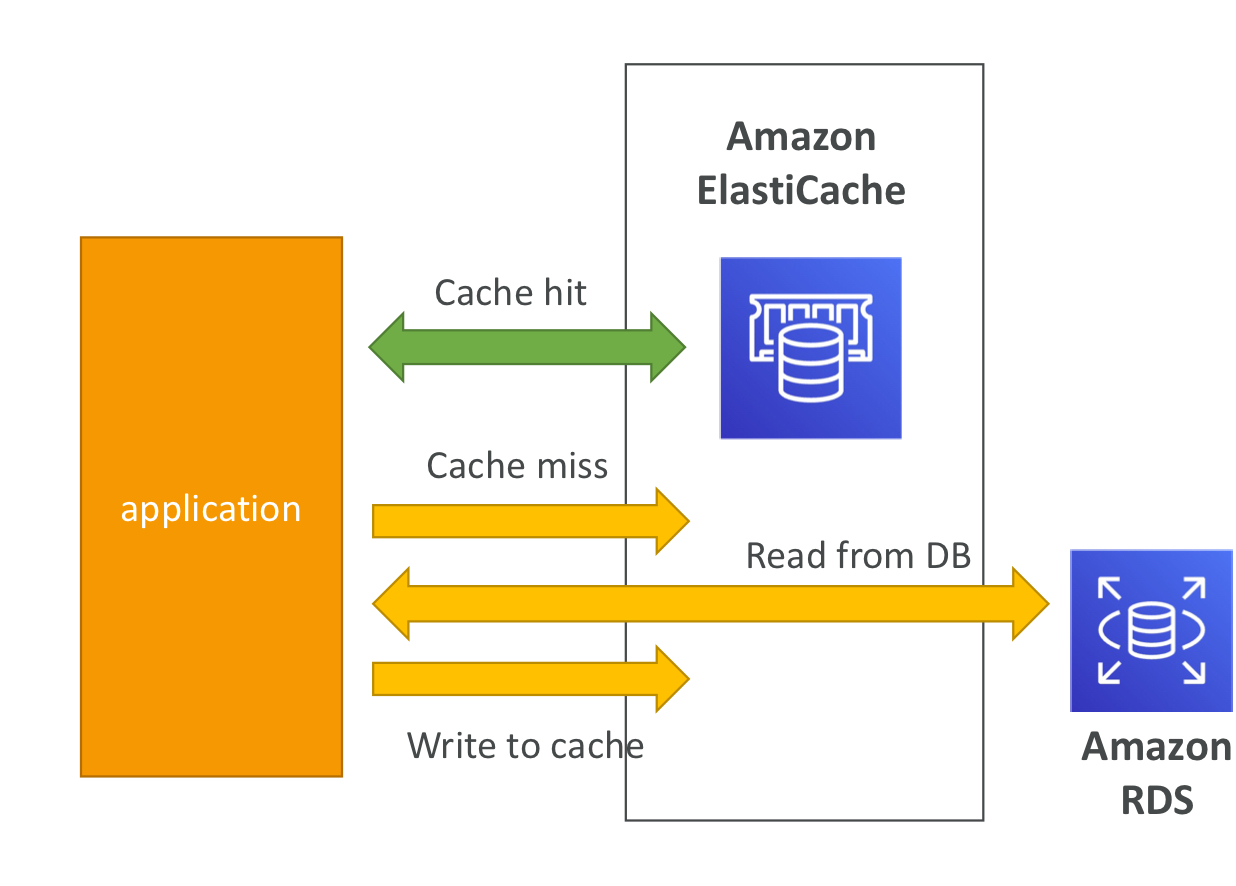
솔루션 아키텍처- DB Cache
- Cash hit: 응용 프로그램은 쿼리가 이미 생성되었는지 확인하기 위해 엘라스틱 캐시를 처리함. 쿼리가 이미 만들어져서 엘라스틱 캐시에 저장되어 있다면 그걸 캐시히트라고 함.
- Cash miss: 캐시 미스가 발생하면 db를 읽어서 데이터를 가져와야 함. 또다른 응용 프로그램이나 같은 쿼리가 발생하는 인스턴스에 데이터를 캐시로 다시 작성할 수 있음. 그래서 다음에 같은 쿼리를 했을 때 캐시 히트를 발생. -> RDS DB 부하 낮아지고, 캐시에 데이터를 저장했을 때 최근 데이터만 사용하도록 캐시 무효화 전략 필요.
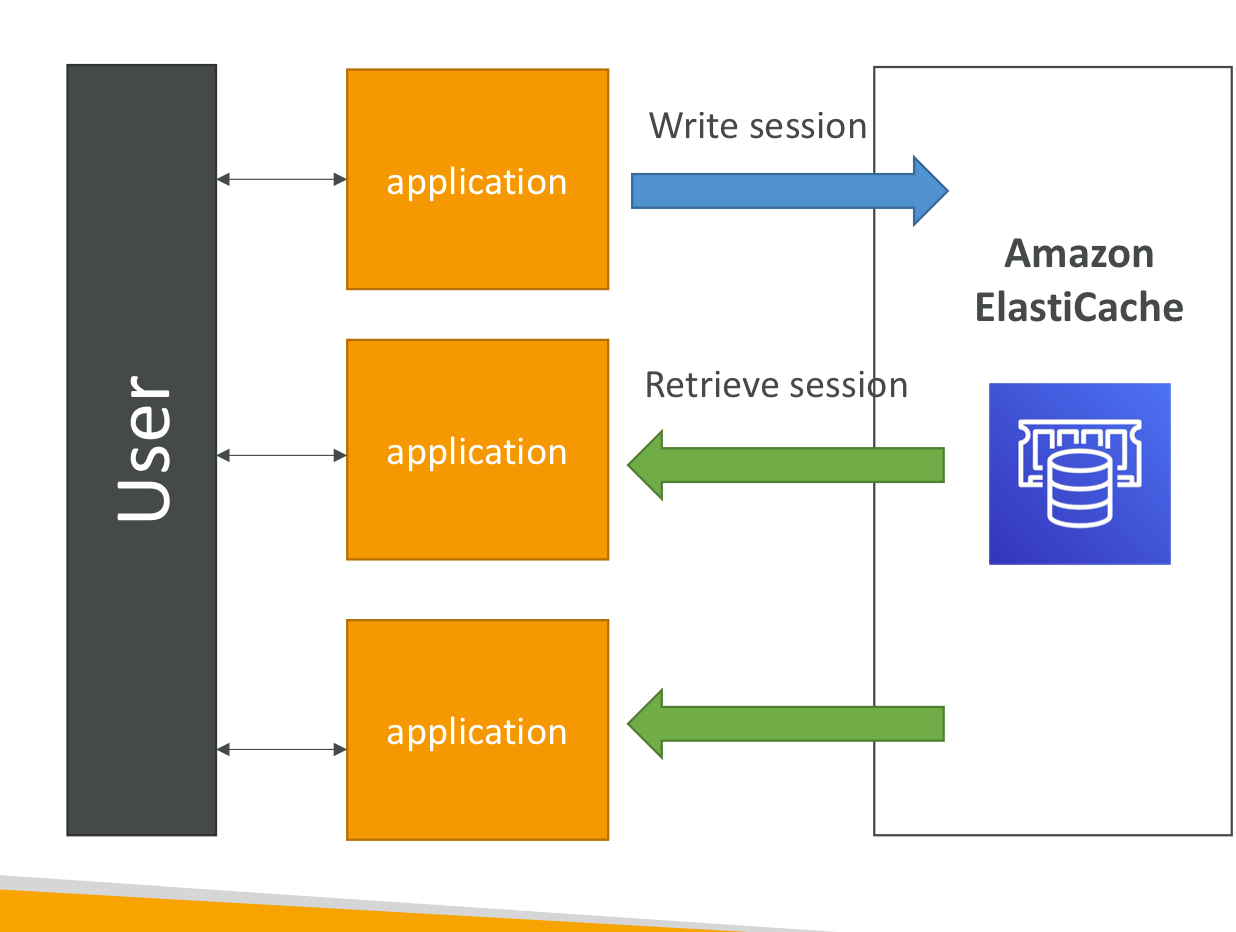
솔루션 아키텍처- 유저 세션 스토어
- 사용자 세션을 저장해 응용 프로그램을 비저장 상태로 만들기
- 1) 응용 프로그램이 엘라스틱 캐시에 세션 데이터를 씀.
- 2) 사용자가 다른 인스턴스로 리다이렉트되면 응용 프로그램은 세션 캐시를 검색할 수 있음.
Redis vs Memcached
Redis: 멀티 AZ, 읽기 복제본, 고가용성, 백업
Mencached: 데이터가 분산되어 있어서(sharding) 데이터 잃을 수도 있음. 고가용성 X, 지속 X, 백업 X
캐시 보안
- Redis에 대한 IAM 권한을 지원.
- 클라이언트에 EC2 인스턴스가 있을 때, Redis AUTH를 써서 Redis Cluster에 연결 가능한데 이것은 Redis security group이 보호하고 암호화를 위해 SSL 지원함.
데이터 로딩 패턴
- Lazy Loading: 읽었던 데이터가 캐시에 저장되고 캐시에서 데이터가 끊길 수 있음.
- Write Through: db에 쓰일 때마다 캐시에 데이터 추가, 업데이트됨. 오래된 데이터는 없음.
- Session Store: 일시적 세션 데이터를 저장.
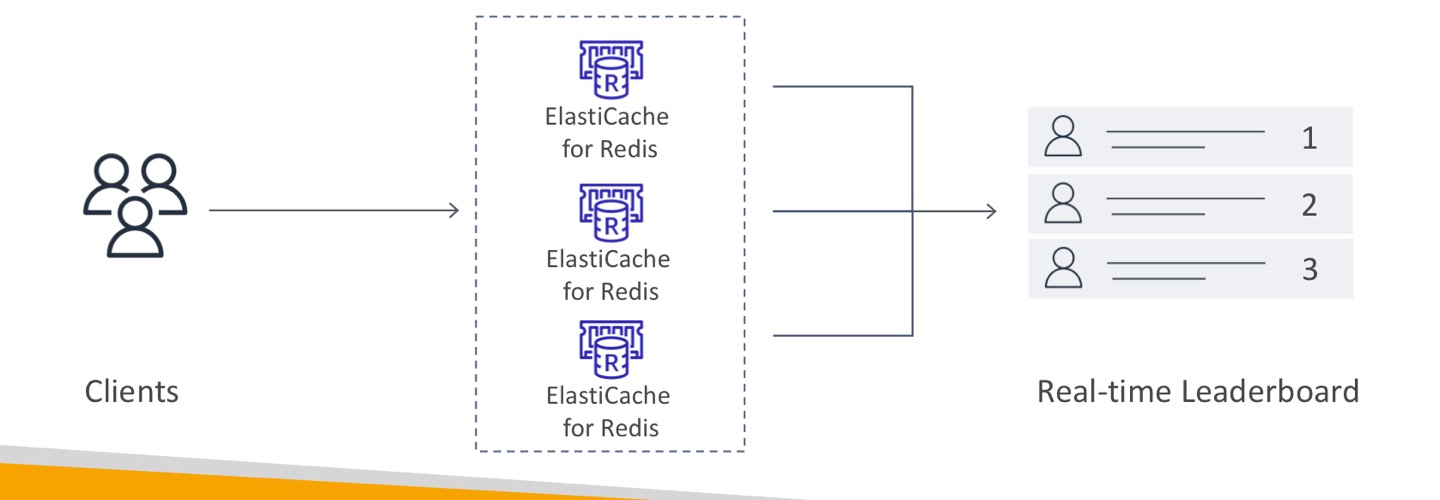
Redis Use Case
- 게임 리더보드 만들기
- 레디스 캐시는 같은 리더보드에 저장됨.
- 클라이언트가 레디스를 이용해 엘라스틱 캐시와 대화할 때 이 시리간 리더보드에 접속할 수 있음.
- 이러한 기능을 앱에서 프로그래밍하지 않아도 됨.