
이번 포스팅은 Database의 Index에 대한 내용을 담고 있습니다.
[Intro]
책을 구매하기 위해 서점에 가서 도서검색대를 이용해 본 경험은 다들 한번씩 있을겁니다.
수만권의 책들 속에서 내가 원하는 책을 찾고자 할때, 서점이 만일 책들을 무질서하게
쌓아만 두고 도서검색대 없이 내가 보려는 책을 찾는 다면 얼마나 오래 걸릴까요?
마찬가지로 책을 구매한 뒤에 펼처봤더니 내용에 순서가 없고 목차나 색인이 없다면,
내가 찾고자 하는 내용을 찾는데 얼마나 오래걸릴까요?
이는 데이터베이스에서도 마찬가지입니다. 내가 찾고자 하는 데이터에 자원을 효율적으로
사용하면서 가장 빠르게 접근하게 해줄 수 있는 것이 바로 INDEX 입니다.
이번 포스팅에서는 INDEX의 자료구조와 장단점 그리고 관리방법에 대하여 얘기해 보겠습니다.

[Purpose]
인덱스가 무엇인지 알기에 앞서 인덱스를 왜 사용해야하는지 부터 생각해보겠습니다.
DBMS에서 검색 속도를 높이기 위해 사용됩니다.
Intro에서 말씀드렸듯이 Index는 책의 목차나 색인에 비유되곤 합니다.
목차는 내용을 중심으로 타이틀 기준으로 정렬이 되어있지만, 책 뒷부분의 색인은
문자열 순으로 정리되어 있습니다. 색인과 같이 내용을 알지 못할때 가장 빠르게
데이터를 탐색하여 Cost를 줄이고 효율성을 높이는 것이 Index의 목적입니다.
[Definition]
인덱스의 정의는 다음과 같습니다.
추가적인 쓰기 작업과 저장공간을 활용하여 DB Table의 검색 속도를 향상시키기 위한 자료구조
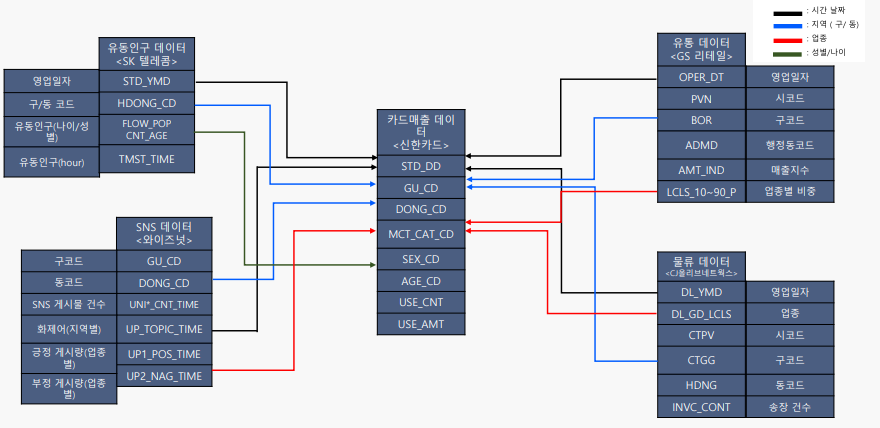
위 그림에서 보듯이 실제 데이터들은 하나의 레코드에 대하여 적게는 대여섯개에서 많게는
수십가지의 특성이 존재할 수 있습니다.
만일 위와같은 상황에서 특정 레코드를 찾고자 한다면 내가 찾고자하는 데이터의 모든 특성이
수백만건의 데이터에 대하여 각각 일치하는지 순회하며 비교하는 작업이 필요합니다.
따라서 특성이 늘어날수록 DB를 조회하는데 드는 Cost는 기하급수적으로 증가할 것입니다.
그럼 어떻게 해...😂
![]()
이러한 비용 문제에 대하여 Index는 오히려 칼럼을 하나 더 늘려
추가적인 저장공간을 사용하고,
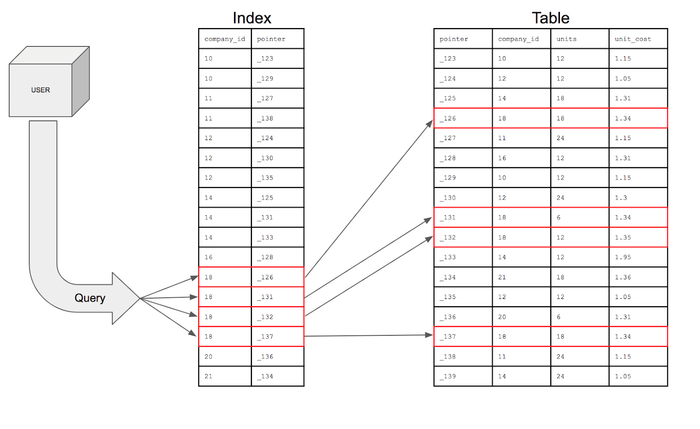
아래의 그림과 같이 Index 테이블을 생성하여 해당 문제를 완화시킵니다.
아래 테이블에서 보듯이 기존의 Table만 존재했다면 company_id가 18인
레코드들을 조회하기 위해서는 Raw_Table 전체를 순회하면서 company_id가
일치하는 데이터들을 찾아야했습니다.
하지만, Index table을 별도로 만들어주고 index의 value 값들에 대하여 해쉬태이블이나,
B+트리 구조를 이용하여 빠르게 접근 할 수 있습니다.
[Data Structure of Index]
그렇다면 위와 같은 문제를 Index를 통해 해결 했을때 사용된 자료구조들에 대하여 좀 더
구체적으로 알아보겠습니다.
[Hash Table]
해시 테이블은 (Key, value)로 데이터를 저장하는 자료구조 중 하나로,
Java의 HashMap이나 Python의 Dictionary 라이브러리를 사용해보신 경험이 있을 것입니다.
해시 테이블은 빠른 데이터 검색이 이 필요할 때 유용하며, Key값을 이용하여 고유한 index를
생성하여 그 index에 저장된 값을 꺼내오는 구조입니다.
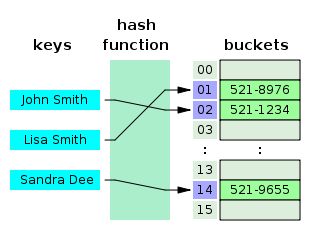
해시 함수는 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현하였으며, 시간복잡도는 O(1)
로 매우 빠른 검색 속도를 지닙니다. 하지만 해시함수는 값이 1이라도 달라지면 완전히
다른 해시 값을 생성하므로, 이런 특성으로 인해 부등호 연산이 자주 사용되는
데이터베이스 검색을 위해서는 해시 테이블이 적합하지 않습니다.
가령 SNS 데이터를 조회하는데 특정 해시태그로 시작하는 자연어 데이터만 탐색하고자 한다
와 같은 쿼리문은 Index가 해쉬 자료구조 기반일 경우 Index의 장점을 사용할 수 없게 됩니다.
따라서, 위와 같은 이유로 데이터베이스의 인덱스에서는 B+Tree가 일반적으로 사용됩니다.
[B+Tree]
B+Tree는 DB의 인덱싱을 위해 자식노드가 2개 이상인 B-Tree를 개선시킨 자료구조입니다.
우선 B-Tree는 Binary tree 에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 밸런스를 맞추는 트리입니다.
이러한 B-Tree를 다음과 같은 몇가지를 개선시킨 것이 B+Tree 입니다.
🟢 리프노드(데이터노드)만 인덱스와 함께 데이터(Value)를 가진다.
🟢 나머지 노드(인덱스노드)들은 데이터를 위한 인덱스(Key)만을 갖는다.
🟢 리프노드들은 LinkedList로 연결되어있다.
🟢 데이터노드 크기는 인덱스 노드의 크기와 같지 않아도 된다.
기존의 B-Tree와 다르게 같은 depth의 리프노드들을 LinkedList로 연결하여 순차검색을
용이하게 하는 등 Index에 맞게 최적화 해주었습니다.
그렇다면 이렇게 테이블 검색 속도와 성능을 향상 시켜주는 Index는 장점만 존재할까요?
[pros and cons]
인덱스의 장단점은 다음과 같습니다.
pros
🔵 테이블을 조회하는 속도와 그에 따른 성능을 향상 시킬 수 있다.
🔵 전반적인 시스템 부하를 막을 수 있다.
🔵 Where절 같은 조건 검색이나, ORDER BY에 의한 정렬 과정의 효율성을 높일 수 있다.
🔵 Min, Max의 효율적인 처리가 가능하다.
cons
🔴 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 별도로 필요하다.
🔴 인덱스를 관리하기 위해 추가 작업이 필요하다.
🔴 항상 정렬된 상태를 유지하기위해 COST가 발생한다.
🔴 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
[When, How to use]

💡 이럴때 사용하면 좋아요!
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
🚨 Index를 남발하지 말아야 하는 이유
DB 서버에 성능 문제가 발생하면 가장 빨리 생각하는 해결책이 인덱스 추가 생성입니다.
하지만 문제가 발생할 때마다 인덱스를 생성하면서 인덱스가 쌓여가는 것은
하나의 쿼리문을 빠르게는 만들 수 있지만, 전체적인 데이터베이스의
성능 부하를 초래합니다.
조회 성능을 극대화하려 만든 객체인데 많은 인덱스가 쌓여서INSERT, UPDATE, DELETE 시에 부하가 발생해 전체적인
데이터베이스 성능을 저하시킵니다.
그렇기에 인덱스를 생성하는 것보다는 SQL문을 좀 더 효율적으로 짜는 방향으로 나가야 합니다.
인덱스 생성은 마지막 수단으로 강구해야 할 문제라고 할 수 있습니다.
[Conclusion]
-
인덱스는 데이터가 저장된 물리적 구조와 밀접한 관계가 있다.
-
인덱스는 레코드가 저장된 물리적 구조에 접근하는 방법을 제공한다.
-
레코드의 삽입과 삭제가 빈번하게 일어나는 경우, 인덱스의 개수를 최소로 하는 것이 효율적이다.
-
인덱스가 없으면 특정한 값을 찾기위해 모든 데이터 페이지를 확인하는 TABlE SCAN이 발생한다.
-
기본키를 위한 인덱스를 기본 인덱스라 하고, 기본 인덱스가 아닌 인덱스들을 보조 인덱스라고 한다.
-
대부분의 관계형 데이터베이스 관리 시스템에서는 모든 기본키에 대해서 자동적으로 기본 인덱스를 생성한다.
-
레코드의 물리적 순서가 인덱스의 엔트리 순서와 일치하게 유지되도록 구성하는 인덱스를 클러스터드 인덱스라고 한다.



데이터베이스에서 인덱스는 이렇게 쓰이는군요! 자세한 설명 감사합니다:)