
이번 포스팅은 NoSQL의 일종인 redis에 대해 다루고 있습니다.

[Cache]
[개념]
redis에 대해서 이해하기 위해서는 먼저 cache의 개념에 대한 이해가 먼저 필요합니다.

먼저 cache란 자주 사용하는 데이터나 요청 값을 미리 복사해 놓는 임시 공간을 의미합니다.
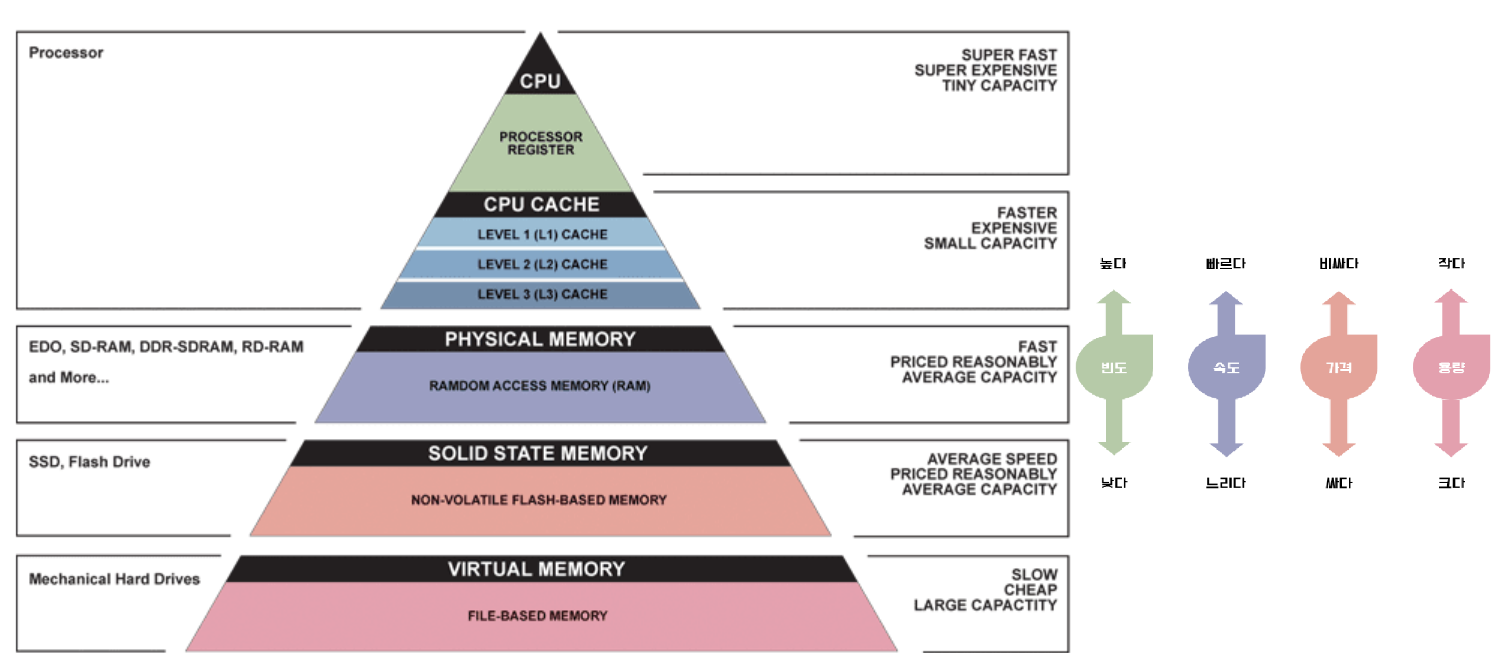
아래의 저장공간 계층 구조에서 확인 하실 수 있듯이,cache는 저장공간이 작고 비용이 비싼
대신 빠른 성능을 제공하는 것이 특징이죠.
[필요성]
혹시 롱테일법칙, 파레토법칙, 20:80법칙을 들어보신 적 있나요? 다양한 학문에서 등장하지만,
경영학에서의 롱테일 법칙과 파레토 법칙은 상위 20%의 고객이 매출의 80%를 차지한다는
이론입니다. 컴퓨터 공학에서는 20%의 요구사항이 80%의 리소스를 잡아먹는 의미로
사용됩니다. 이러한 법칙을 이용하여 우리는 cache를 활용할 수 있습니다.
EX>
가령 1교시부터 6교시까지 6과목에 6가지 책이 필요한데 가방에 책을 한 권만 넣을 수 있다면
해당 학생은 수업 중간마다 책을 가지러 집까지 다녀와야 책을 볼 수 있을 것입니다.
여기서 사물함에 미리 책들을 넣어두었다면, 책들이 필요할때 소요시간을 줄일 수 있을 껍니다.
사물함이 캐시의 역할을 해주는 것이죠!자주 사용하는 자원들을 접근성이 더 낮은 저장공간에 저장하는 것은 성능의 부하를 발생시킬
수 있습니다. 따라서 실제 서비스를 할 때 많이 사용되는 20%만 캐싱함으로써 전체적으로
효율을 끌어올릴 수 있습니다.
[언제 사용하나?]
서비스를 처음 운영하게되면 일반적으로 WEB-WAS-DB 정도로 작게 인프라를 구축합니다.
하지만 사용자가 늘어나고 트래픽이 점차 증가함에 따라 DB에 무리가 가게됩니다.
DB는 데이터를 물리 디스크에 직접쓰기때문에 서버에 문제가 발생해도 데이터가 손실되지는
않지만, 매 트랜잭션마다 디스크에 접근해야하므로 부하가 많아지면 성능이 떨어지게 됩니다.
[Cache의 동작 Flow]
1️⃣ 클라이언트로부터 요청을 받는다.
2️⃣ 캐쉬에서 해당 내용을 찾아본다
3️⃣ 없다면 DB에서 내용을 찾아본다.
4️⃣ 다시 캐쉬에 해당 내용을 저장한다.Cache Hit : DB에 가지 않고 캐시에 데이터가 있어서 바로 클라이언트로 반환
Cache Miss : Cache에 데이터가 없어 DB에 데이터를 요청하여 조회 후 클라이언트로 반환
이러한 Flow에서 캐시를 어떻게 사용하는 지는 두가지 방법이 있습니다.
[Look Aside Cache (Lazy Loading)]
🟡 클라이언트로부터 요청을 받는다.
🟡 캐쉬를 통해 캐쉬에서 이미 들어왔던 작업인지 확인한다.
🟡 캐쉬에 내용이 있다면 리턴하고 없으면 DB에 접근한다.
🟡 DB에 접근했다가 한번 들어온 것이므로 캐쉬에 저장한다.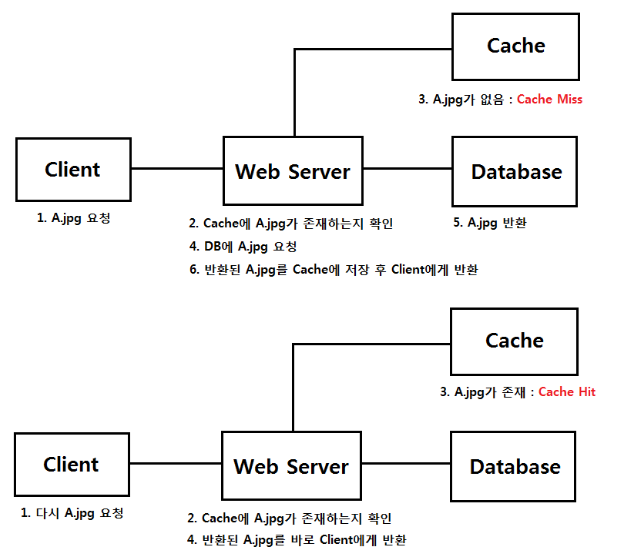
대부분의 캐시를 사용한 개발이 위와같은 Look Aside Cache 프로세스를 수행합니다.
[Write Back]
🟢 모든 데이터를 캐시에 저장합니다.
🟢 캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장 (배치)
🟢 DB에 저장한 데이터를 캐시에서 제거
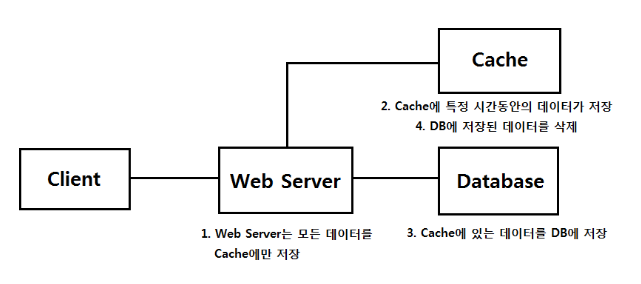
Write Back은 Insert문이 너무 많을때, 배치를 이용하여 많은 쓰기작업을 한꺼번에 처리하기위해 사용합니다.
만일 설문조사를 온라인으로 수행한 대상자들이 종료시간 직전에 한번에 설문조사 결과를 제출한다면, DB에 한번에 대량의 요청이 몰리게 되면서 DB 서버가 죽게 될 수 도 있습니다.
이때 Write Back기반의 캐시를 사용하면 캐시 메모리에 데이터를 저장해 놓고, 이후 DB 디스크에 업데이트 해주는 방식으로 안전하게 쓰기작업을 수행할 수 있습니다.
[redis]

레디스에 대해 설명하기에 앞서 In-memory 방식의 오픈소스인 Memcached에 대해 먼저 알아 보겠습니다.

[Memcached]
Memcached 는 무료로 사용할 수 있는 오픈소스이며 분산 메모리 캐싱 시스템 입니다.
데이터베이스의 부하를 줄여 동적 웹 어플리케이션의 속도를 개선시키는데 사용됩니다.
DB나 API 호출 또는 렌더링등으로 받아오는 결과 데이터를 작은 단위의
Key-Value 형태로 메모리에 저장하는 방식으로 이루어진 In-memory 솔루션입니다.
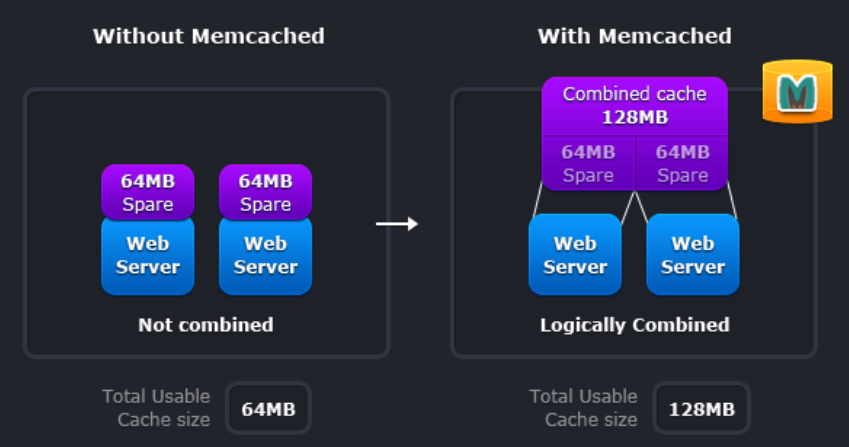
왼쪽과 같이 고전의 방식에서는 각각의 노드가 완전히 독립적으로 캐시 메모리를 할당 받으므로 하나의
서버가 실제 메모리 용량의 일부분만 사용가능 하다는 점에서 낭비가 매우 심했습니다.
하지만 오른쪽 그림과 같이 Memcached를 사용할 경우 모든 서버는 동일한 가상 메모리 풀을 공유하게 되고 ,
이를 통해 캐싱을 통해 DB나 API 호출에 대한 횟수를 줄일 수 있고 이로 인해 응용프로그램의 수요나
DB 데이터 접근에 대한 부하를 줄 일 수 있습니다.
[redis]

레디스는 오픈소스로서 NoSQL로 분류됩니다.
또한 Memcached와 같이 In-memory 솔루션으로 분류되기도 합니다. 성능은 Memcached와 유사하지만 다양한 자료구조를 지원할 수 있습니다.
redis는 Remote Dictionary Server의 약자로 외부에서 사용가능한 Key-Value쌍의 해쉬 맵 형태의 서버라고 생각할 수 있습니다. 그래서 별도의 쿼리 없이 Key를 통해 빠르게 결과를 가져올 수 있습니다.
[특징]
🔴 영속성을 지원하는 인 메모리 데이터 저장소
🔴 다양한 자료 구조를 지원함.
🔴 싱글 스레드 방식으로 인해 연산을 원자적으로 수행이 가능함.
🔴 읽기 성능 증대를 위한 서버 측 리플리케이션을 지원
🔴 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
🔴 다양한 서비스에서 사용되며 검증된 기술
[redis의 영속성]
redis는 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있습니다. 서버가 중간에 다운되거나 중단되더라도 디스크에 저장된 데이터를 읽어서 메모리에 로딩합니다.
RDB (snapshotting) 방식
- 순간적으로 메모리에 있는 내용 전체를 디스크에 옮겨 담는 방식
AOF (Append On File) 방식
- redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태
쉽게 설명하자면,
RDB의 경우 마치 중간 중간 사진을 찍어두듯이,
메모리에 있는 내용 전체를 중간백업을 미리 해두는 방식입니다.
AOF는 해당 데이터를 저장할때 쓰여진 연산로그(쿼리문)을 저장해두었다가 필요할때 해당 로그를 다시 수행하여 백업하는 방식입니다.
[redis의 Collection]
자바의 Collection 자료구조나 , 파이썬의 딕셔너리,리스트,셋,튜플과 같이 redis는 다양한 데이터 구조체를 지원합니다.

위 그림과 같이 Key가 될수 있는 데이터 구조체가 다양하기 때문에 개발의 편의성이 좋아지고 난이도가 낮아지는 이점이 있습니다.
[어떻게 사용하나?]
Key-Value형태로 값을 저장하는 redis는 In-memory 상태에서 데이터를 처리하기 때문에,
RDS같은 관계형 DB나 MongoDB같은 문서형 DB보다 빠르고 가볍게 동작합니다.
1. 로컬환경에서 호출
AWS EC2를 예로 들면 인스턴스에 redis를 설치해 인스턴스 메모리를 사용해 redis를 사용할 수 있습니다.
인스턴스의 메모리 여유가 있다면 비용적인 측면이나 사용성 측면 모두에서 뛰어납니다.
2. 클라우드 서비스를 사용해 외부자원을 이용
레디스 랩 과 같은 서드파티 서비스를 사용해 레디스를 사용하게
되면 통신하는 웹 서버가 아무리 많아도 하나의 프레임 워크 바인딩을 사용할 수 있습니다.
이러한 경우, 레디스는 여러 웹서버들의 공유 메모리 역할을 할 수 있습니다.
[언제 사용하나?]
만일 어떤 동영상의 조회수를 저장하는데 실시간으로 RDS에 해당 조회수 값을 반영하도록
해두었다면 어떻게 될까요? 한시간에 100만의 조회수를 찍었다면 , 조회수라는 데이터를
변경하기 위해 조회수 만큼의 DB접근이 필요할 것입니다.
따라서 redis를 사용해 데이터를 캐싱 처리하고, 일정한 주기에 따라 RDS에 업데이트 한다면
DB에 가해지는 부담은 줄이고, 성능은 끌어올릴 수 있습니다.
또한 사용자의 세션 관리나, 메시지 큐잉에도 사용할 수 있습니다.
[유의해야할 점]
redis 는 한번 키를 생성하면 선택적으로 삭제하기 어렵습니다.
놀랍게도 redis의 key는 영원히 쌓이는 방식으로 운영됩니다.
심지어 서버를 종료했다켜도 상태가 유지됩니다.
때문에 일정 기간을 설정하여 기간이 지나면 일괄 삭제하거나 일부 삭제 하는 방식으로
관리해줘야하는 유의점이 있습니다.

5개의 댓글



You should consider your gear and party composition for a well-rounded build. Experiment and find what JJSploit works best for you!
https://jjsploit.org/
I kept getting confused by the terminology, but thanks to this I learned it again. Thank you!
https://hydralauncher.app/
NoSQL에 대해 잘 몰랐는데 너무 유용한 글이네요! 감사합니다.