
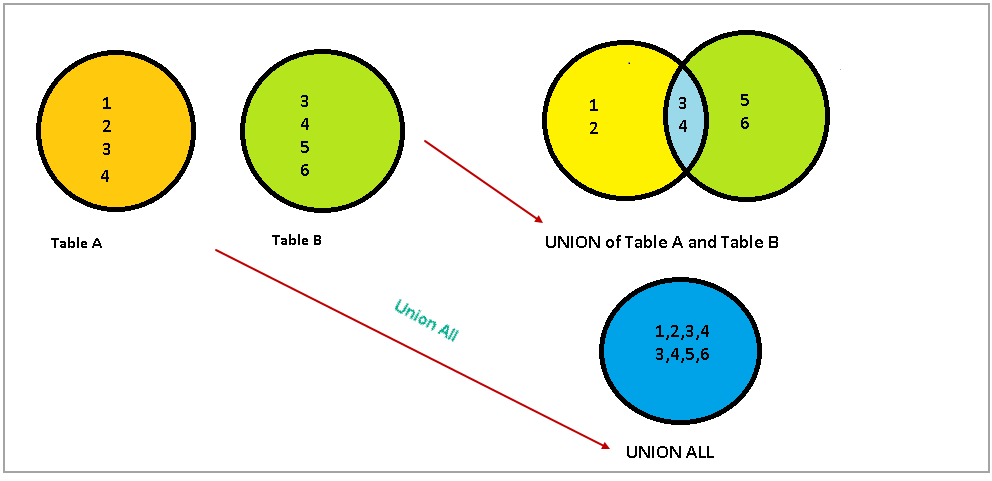
UNION [DISTINCT]
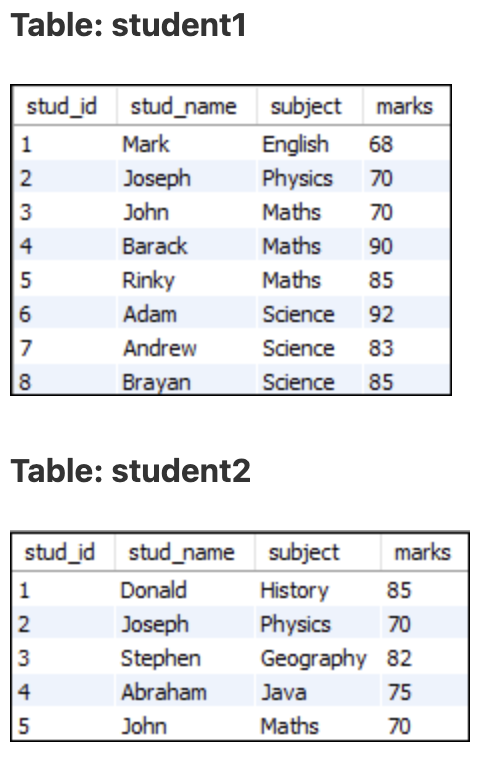
UNION과 UNION DISTICT는 동일하다.
UNION은 중복을 제거한 결과
SELECT stud_name, subject FROM student1
UNION
SELECT stud_name, subject FROM student2; 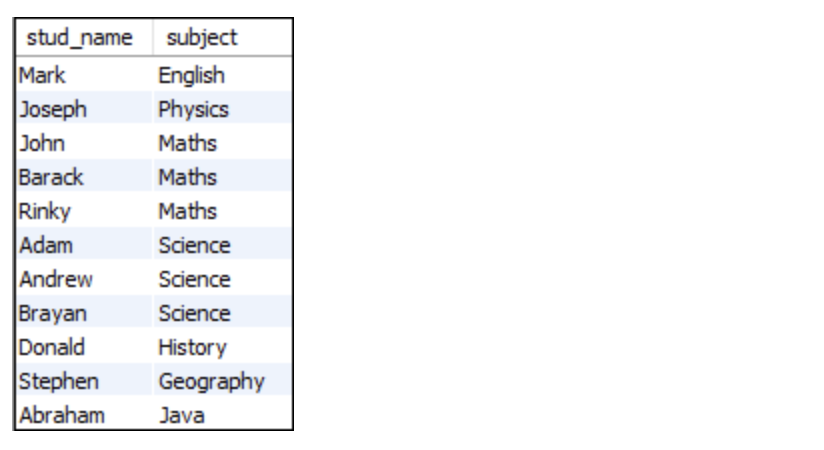
처리 과정
- 최종 UNION 결과에 적합한 임시 테이블을 메모리 테이블로 생성한다.
- UNION 또는 UNION DISTINCT의 경우, 임시 테이블의 모든 컬럼으로 Unique Hash 인덱스 생성한다.
- 서브쿼리 실행 후 결과를 임시 테이블에 복사한다.
- 임시 테이블이 특정 사이즈 이상으로 커지면 임시 테이블을 Disk 임시 테이블로 변경한다.
- 임시 테이블을 읽어서 Client에 결과를 전송한다.
- 임시 테이블을 삭제한다.
UNION ALL
(SELECT stud_name, subject, marks FROM students)
UNION ALL
(SELECT stud_name, subject, marks FROM student2)
ORDER BY marks; 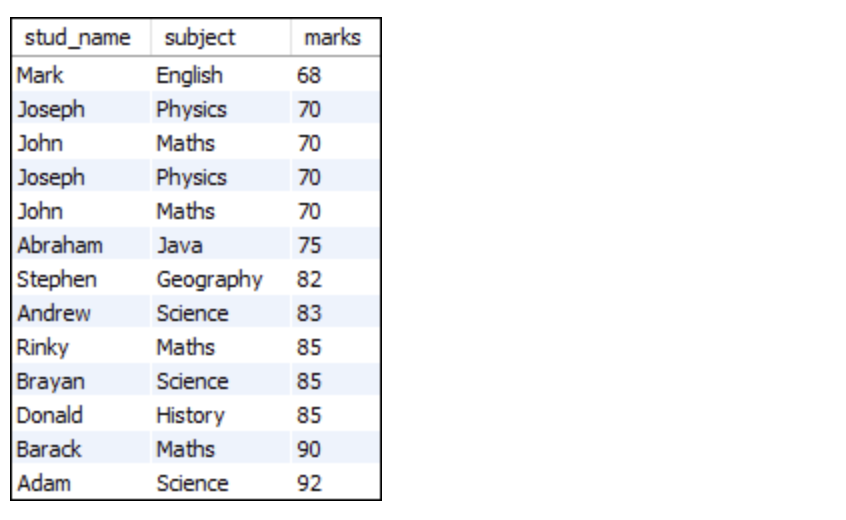
UNION/UNION ALL 제약 조건
상위 SQL문과 하위 SQL문의 컬럼 개수가 동일해야 한다.
상위 SQL문과 하위 SQL문의 컬럼 위치가 동일한 컬럼들이 결합 된다.
컬럼명은 최상위 SQL문의 명칭을 따르게 된다.
❗️UNION [DISTINCT] 유의 점
내부적으로 중복을 체크하는 로직이 작동되는데 데이터가 적으면 차이가 미비하지만 데이터가 매우 많을 경우 중복 체크를 하는 과정에서 부하가 많이 발생하게 됩니다.

기록