
RAG
Retrieved-Augmented Generation, '검색 증강 생성'이라고 번역할 수 있으며 대규모 언어 모델(LLM)의 생성 능력과 외부 지식 소스에서의 정보 검색을 결합한 AI 기술
RAG 주요 구성 요소
검색기(Retriever)
질문이나 프롬프트와 관련된 정보를 외부 데이터베이스에서 찾아내는 컴포넌트
관련성 높은 문서나 정보를 효율적으로 검색하여 제공
생성기(Generator)
검색된 정보를 바탕으로 응답을 생성하는 언어 모델
검색된 정보와 원래 질문을 종합하여 정확하고 맥락에 맞는 답변 생성
지식 베이스(Knowledge Base)
검색 가능한 형태로 구조화된 외부 정보의 저장소
최신 정보, 전문 지식, 기업 특화 데이터 등을 포함하여 모델의 지식을 보완
RAG 프레임워크 플로우
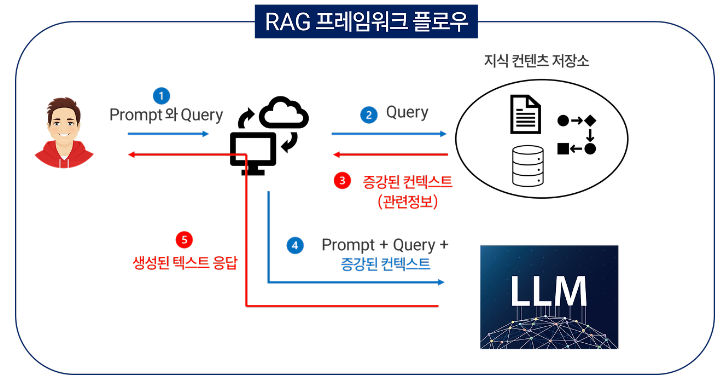 1. 사용자가 질문을 입력
1. 사용자가 질문을 입력
2. 검색기가 질문과 관련된 정보를 지식 베이스에서 찾아냄
3. 검색된 정보와 원래 질문이 생성기에 입력
4. 생성기는 이 정보를 바탕으로 답변을 생성
5. 생성된 답변이 사용자에게 제공
Lang Chain
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 오픈소스 프레임워크
이 프레임워크는 LLM을 다른 컴퓨팅 소스나 지식과 연결하여 더 강력하고 유연한 AI 시스템을 구축할 수 있게 한다.
랭체인은 ODBC, 또는 표준 SQL 문에 집중하게 함으로써 백엔드 데이터베이스의 구현 세부 정보를 요약하는 JDBC 드라이버와 비슷하다고 할 수 있다.
또한 랭체인은 간단하고 통합된 API를 노출하여 기본 LLM의 구현 세부 사항을 요약하는데, 이 API를 통해 개발자들은 코드를 크게 변경하지 않고 모델을 쉽게 교체하거나 대체할 수 있다.
LangChain의 주요 구성 요소
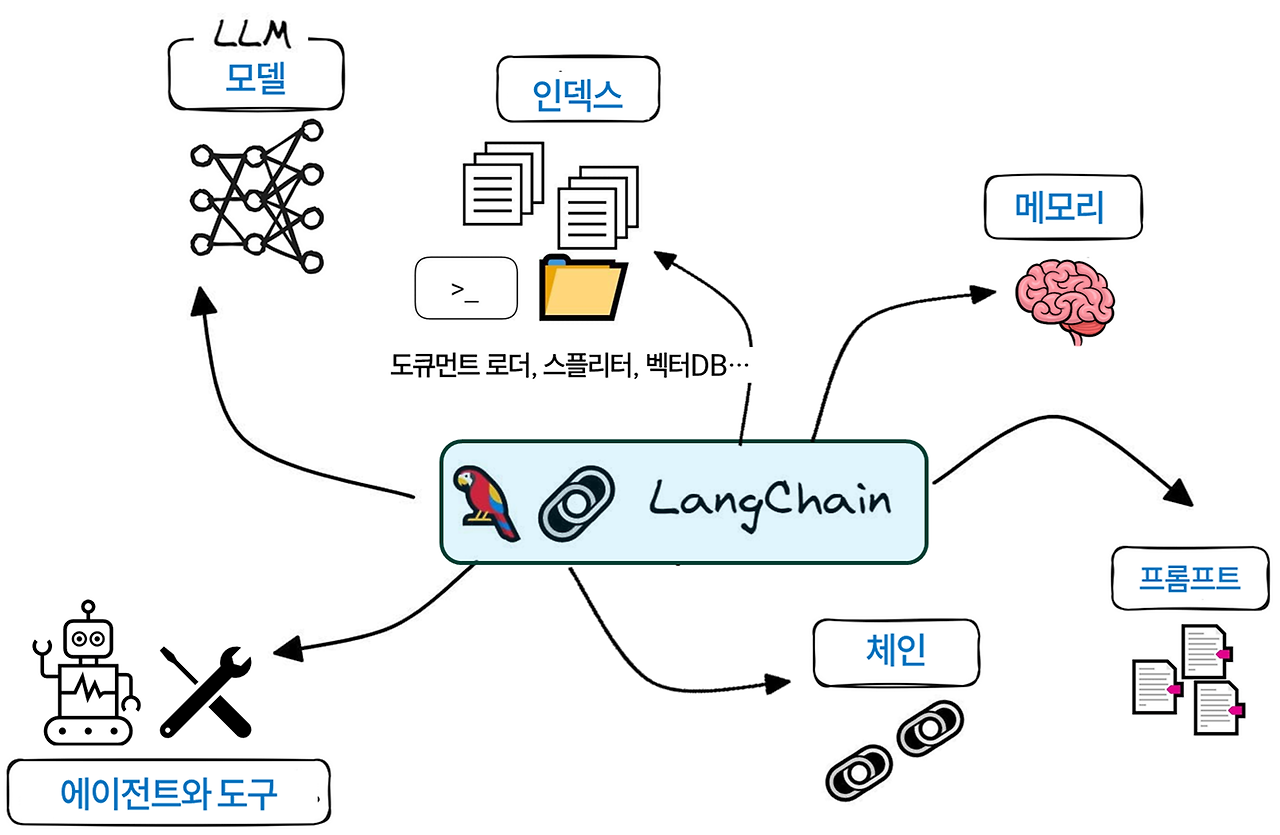
Models (모델)
다양한 LLM과 상호작용하기 위한 표준화된 인터페이스
GPT-3, BERT 등 다양한 언어 모델을 쉽게 통합하고 사용할 수 있게 함
Prompts (프롬프트)
LLM에 대한 입력을 관리하고 최적화하는 컴포넌트
템플릿, 예시, 가이드라인 등을 통해 효과적인 프롬프트 생성 지원
Indexes (인덱스)
대규모 데이터셋을 효율적으로 저장하고 검색하기 위한 데이터 구조
벡터 데이터베이스, 전문 검색 엔진 등을 통해 빠른 정보 검색 지원
Memory (메모리)
대화 또는 상호작용의 상태를 유지하는 컴포넌트
이전 대화 내용을 저장하고 참조하여 문맥을 유지하는 기능 제공
메시지 기록은 레디스(Redis)와 같은 외부 소스에 저장되어 장기 메모리를 유지할 수 있다.
Chains (체인)
여러 작업을 순차적으로 실행하는 워크플로우
복잡한 태스크를 여러 단계로 나누어 처리하고 조합하는 기능 제공한다.
LLM과 상호 작용하는 것은 유닉스 파이프라인을 사용하는 것과 많은 면에서 유사하다.
한 모듈의 출력이 다른 모듈에 입력으로 전송되며 개발자는 종종 원하는 결과를 얻을 때까지 LLM을 사용해 응답을 명확하게 하고 요약해야 한다.
랭체인의 체인은 구성 요소와 LLM을 활용하여 예상되는 응답을 얻는 효율적인 파이프라인을 구축하도록 설계되었다. 간단한 체인에는 프롬프트와 LLM이 포함될 수 있지만 재귀와 같이 LLM을 여러 번 호출하여 결과를 얻는 등 매우 복잡한 체인을 구축할 수도 있다.
예를 들어, 체인은 문서를 요약한 다음 이에 대한 감정 분석을 수행하는 프롬프트가 포함될 수 있다.
Agents (에이전트)
랭체인에서 아주 강력한 모듈
LLM의 추론과 행동은 ReAct 프롬프트 기법이라고 불린다.
이때 랭체인의 에이전트는 LLM을 사용하여 프롬프트를 행동 계획으로 추출하는 ReAct 프롬프트 제작을 단순화한다. 에이전트는 일종의 동적 체인으로 생각할 수 있고, 에이전트의 기본 일련의 동작을 선택하기 위해 LLM을 사용하는 것이다.
동작의 순서는 체인(코드)으로 하드 코딩된다. 언어 모델은 에이전트 내에서 추론 엔진으로 사용되어 어떤 순서로 어떤 동작을 취할지 결정한다.
LangChain Flow
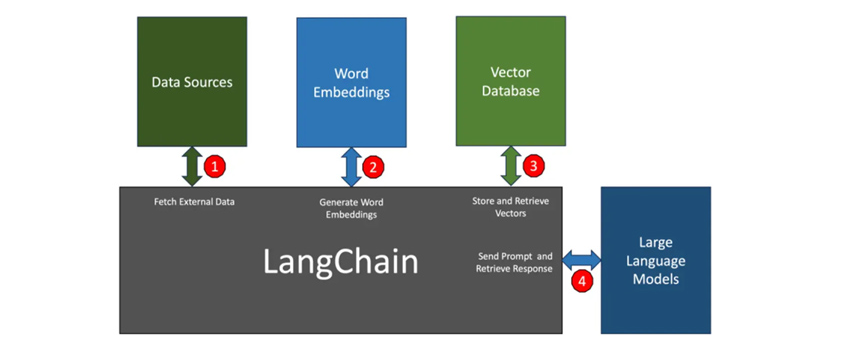
① 데이터 소스
애플리케이션이 LLM에 대한 컨텍스트를 구축하기 위해 PDF, 웹 페이지, CSV, 관계형 데이터베이스와 같은 외부 소스에서 데이터를 검색해야 하는 경우가 있는데 랭체인은 서로 다른 소스에서 데이터에 액세스하고 검색할 수 있는 모듈과 원활하게 통합된다.
② 단어 임베딩
텍스트를 LLM과 관련된 단어 임베딩 모델에 전달하기 위해 일부 외부 소스에서 검색된 데이터는 벡터로 변환되어야 한다. 이때 랭체인은 선택한 LLM을 기반으로 최적의 임베딩 모델을 선택한다.
③ 벡터 데이터베이스
생성된 임베딩은 유사성 검색을 위해 벡터 데이터베이스에 저장된다. 랭체인은 메모리 내 배열부터 파인콘(Pinecone)과 같은 호스팅 벡터 데이터베이스에 이르기까지 다양한 소스에서 벡터를 쉽게 저장하고 검색할 수 있도록 지원한다.
④ 언어 모델(LLM)
랭체인은 오픈AI, 코히어(Cohere), AI21에서 제공하는 주류 LLM과 허깅페이스(Hugging Face)에서 제공되는 오픈소스 LLM을 지원한다.
LangChain 프레임워크 구성

LangChain 라이브러리
Python 및 JS 라이브러리, 어플리케이션 개발을 위한 LLM Chain(다양한 기능 결합) 지원
LangSmith
LLM Chain을 디버깅, 테스트, 평가 및 모니터링할 수 있는 개발자 플랫폼
LangServe
LLM Chain을 REST API로 배포하기 위한 라이브러리
LangChain 템플릿
다양한 작업을 위한 기본 아키텍처 제공
LangChain 개발 생애 주기
개발: LangChain 탬플릿 가지고 어플리케이션 기능 개발
생산화: LangSmith로 LLM 체인 검사, 테스트, 모니터링
배포: LangServe로 모든 LLM 체인 API 개발
패키지 주요 구성
LangChain: LLM의 아키텍처를 구성하는 상황 인지, 기능 체인, 에이전트 및 검색(Retrieval) 전략
Langchain-Core: 기본 추상화 및 언어
LangChain-Community: 서드 파티(타 프레임워크) 통합
패키지 주요 모듈
Chains: LLM 관련 도구, 전처리 등 기능 제공, LCEL(LangChain Expression Language) 활용
Agents: 에이전트(작업 주체)가 LLM을 활용하여 어떤 작업을 수행할 지 선택
Retrieval: 언어 생성에 문서 참고, 문서를 텍스트 벡터 형식으로 저장하여 최적화
Model I/O(Input/Output): 모델의 입출력 관리 모듈, 전세계 언어 관련 모델과 상호작용할 수 있는 블록 방식 기능 제공
Memory: 언어 생성에서 과거의 상호작용 기록이 필요한 경우 이를 메모리 형태로 관리
Callbacks: 로깅, 모니터링, 스트리밍(ChatGPT와 같이 실시간 답변 생성) 등 LLM 어플리케이션의 다양한 단계와 연결하는 기능
FastAPI Configuration
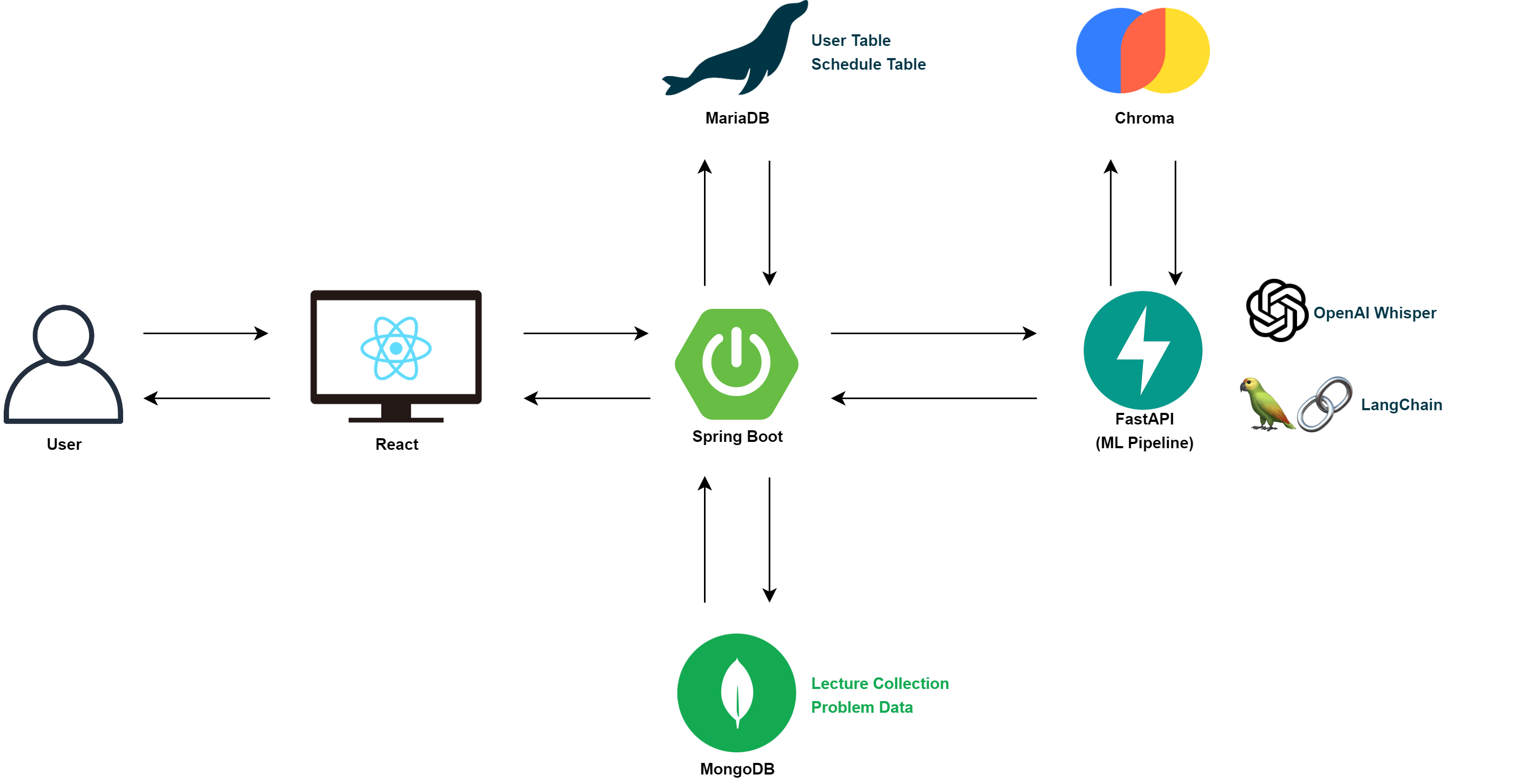 전체 프로젝트 MVP 모델을 위와 같이 수정한다.
전체 프로젝트 MVP 모델을 위와 같이 수정한다.
기존의 Socket을 통한 실시간 STT 로직은 유지하고 LangChain과 ChormaDB를 이용해 LLM과 관련된 플로우를 구현할 예정이다.
Chroma
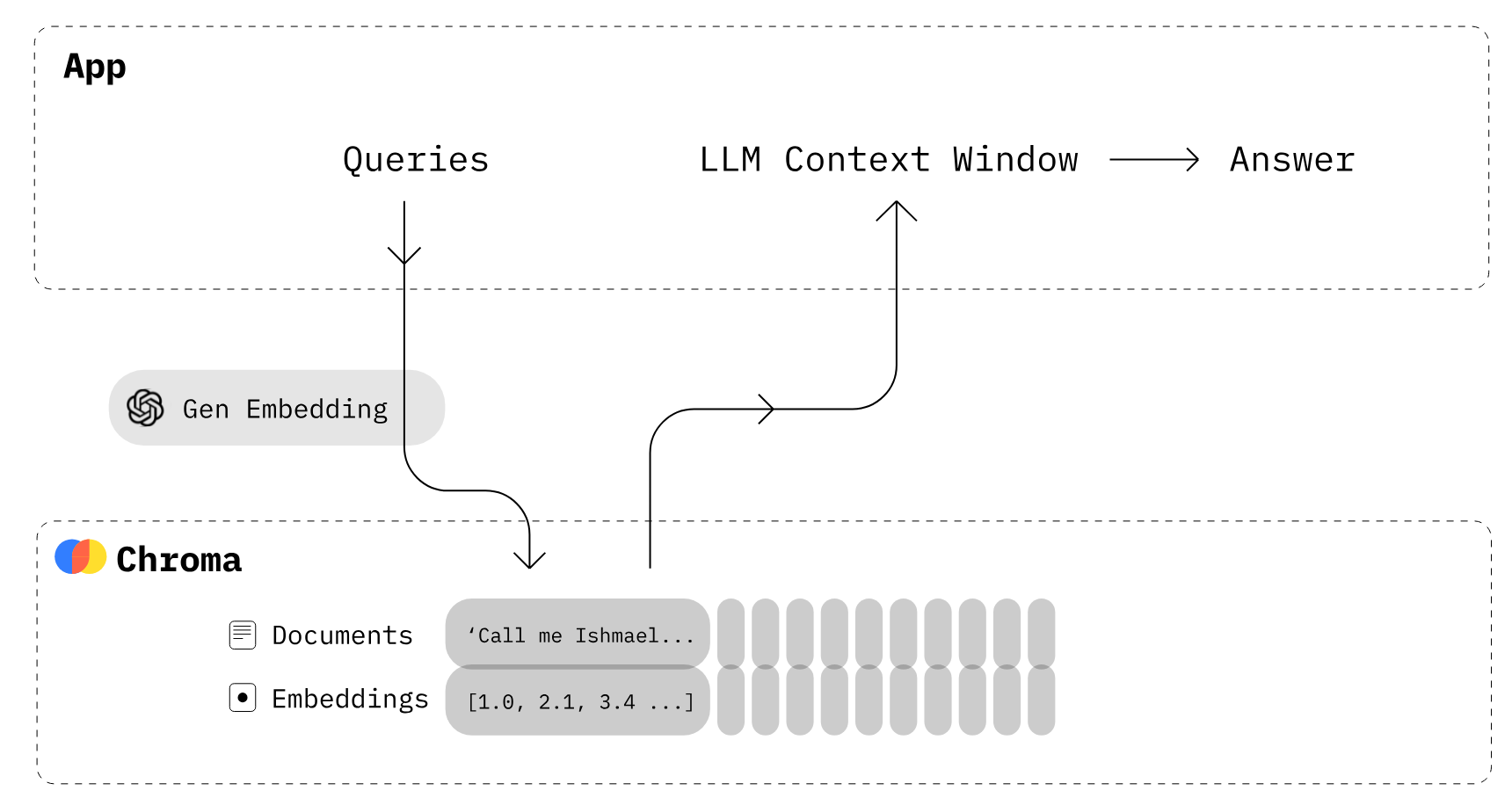
Chroma is the AI-native open-source vector database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.
Hearus 프로젝트에서는 강의 스크립트 기반의 대규모 텍스트 데이터를 효율적으로 저장하고 검색할 수 있게 해주어야 하고 해당 대학 강의에 대한 관련 지식과 사실을 빠르게 검색할 수 있기 때문에 Chroma를 사용한다.
reruirements.txt
# FastAPI
fastapi
uvicorn[standard]
python-dotenv
# Whisper Model Requirement
argparse
torch
torchvision
torchaudio
numpy
git+https://github.com/openai/whisper.git
# Antrhopic Claude
anthropic
# LangChain
langchain
langchain_community
chromadb
sentence-transformers위와 같이 요구되는 파이썬 패키지들을 설치하여주고
.env
# OpenAI
OPENAI_API_KEY=sk-proj-...
# ANTHROPIC
ANTHROPIC_API_KEY=sk-ant-...
# Hugging Face
HUGGINGFACEHUB_API_TOKEN=hf_...각 AI 모델들의 API Key들도 .env에 설정하면 세팅이 완료된다.
STT with LangChain
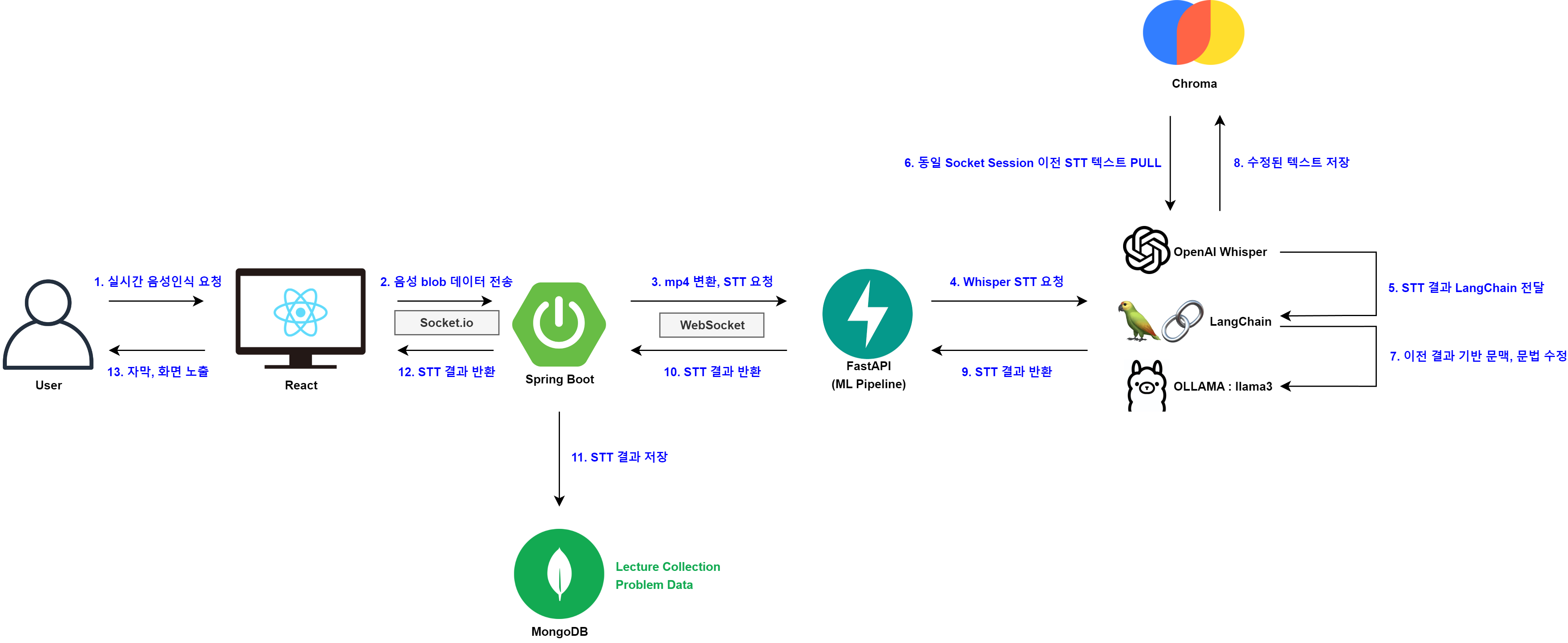 세부적인 STT, LLM 진행 과정은 위와 같이 구성하였다.
세부적인 STT, LLM 진행 과정은 위와 같이 구성하였다.
기존의 Socket 실시간 STT 연결을 유지하면서 Whisper 모델에서 음성인식 결과가 나오면 이를 LangChain에 전달하여 로컬에서 구동되는 OLLAMA에서 처리할 수 있도록 구조화하였다.
또한 LangChain의 LLM 처리가 완료되면 이를 WebSocket을 통해 다시 Spring Boot으로 돌려주어 실시간 음성인식 결과를 사용자에게 제공할 수 있도록 하였다.
langchain.py
import os
from uuid import uuid4
from dotenv import load_dotenv
from langchain.llms import HuggingFaceHub
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# .env HUGGINGFACEHUB_API_TOKEN 불러오기
load_dotenv()
print(os.getenv("HUGGINGFACEHUB_API_TOKEN"))
os.environ["HUGGINGFACEHUB_API_TOKEN"] = os.getenv("HUGGINGFACEHUB_API_TOKEN")
# 음성 인식 결과를 저장할 Chroma DB 생성
embeddings = HuggingFaceEmbeddings()
vectordb = Chroma(embedding_function=embeddings, persist_directory="./db")
def process_speech_to_text(connection_uuid, converted_text):
# 이전 음성 인식 결과 검색
docs = vectordb.similarity_search(converted_text, k=3)
context = " ".join([doc.page_content for doc in docs])
# 텍스트 수정을 위한 프롬프트 템플릿
correction_template = """
이전 음성 인식 결과:
{context}
현재 음성 인식 결과:
{text}
이전 결과를 고려하여 현재 텍스트를 문법적으로 올바르게 수정하고, 잡음이나 인식 오류를 제거해주세요.
문맥을 고려하여 자연스럽게 연결되도록 해주세요.
"""
correction_prompt = PromptTemplate(
input_variables=["context", "text"],
template=correction_template,
)
# 텍스트 수정을 위한 LLMChain
correction_chain = LLMChain(
llm=HuggingFaceHub(repo_id="beomi/llama-2-ko-7b"),
prompt=correction_prompt,
)
corrected_text = correction_chain.run({"context": context, "text": converted_text})
print(corrected_text)
# 수정된 텍스트를 Chroma DB에 저장
vectordb.add_texts(
texts=[corrected_text],
metadatas=[{"connection_uuid": connection_uuid}],
ids=[str(uuid4())],
)
def test():
# 예시 사용
connection_uuid = "example_connection_uuid"
# 첫 번째 음성 인식 결과 처리
# converted_text_1 = "이것은 시장 경제에 대한 설명입니다."
# process_speech_to_text(connection_uuid, converted_text_1)
# 두 번째 음성 인식 결과 처리
converted_text_2 = "시장 경제는 가격 아아아아아아아아아 기구를 통해 자원을 배분하는 경제 체제입니다."
process_speech_to_text(connection_uuid, converted_text_2)
return "Completed"최초에는 위와 같이 process_speech_to_text 메소드에서 HuggingFace의 모델들을 활용하여 실시간 음성인식 결과를 문법적으로 올바르게 수정하고, 잡음이나 인식 오류를 제거해줄 수 있는 LangChain을 구축하였다.
Trouble Shooting : Got device==0
model_id = "beomi/llama-2-ko-7b"
llm = HuggingFacePipeline.from_model_id(
model_id=model_id,
device=0, # -1: CPU(default), 0번 부터는 CUDA 디바이스 번호 지정시 GPU 사용하여 추론
task="text-generation", # 텍스트 생성
model_kwargs={"temperature": 0.1,
"max_length": 256},
)이를 위해 GPU를 사용하려고 하였지만 device=1로 하고 모델을 구동하였을 때
in from_model_id
raise ValueError(
ValueError: Got device==0, device is required to be within [-1, 0)위와 같이 GPU가 정상적으로 인식되지 않았다.

nvidia-smi 명령어를 통해 우선적으로 시스템 상에서 GPU가 인식되었는지를 확인한 후
lenovo@DESKTOP-KS3RBUH MINGW64 ~
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Jun__6_03:03:05_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.5, V12.5.82
Build cuda_12.5.r12.5/compiler.34385749_0nvcc --version를 통해 CUDA의 버전을 확인하였다.
import os
import torch
from uuid import uuid4
from dotenv import load_dotenv
from langchain_community.llms import HuggingFaceHub
from langchain_community.llms import HuggingFacePipeline
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
print("Torch CUDA Available : ", torch.cuda.is_available())
...이후 CUDA와 GPU, 그리고 torch의 충돌 문제일 것이라 판단해 위와 같이 torch.cuda.is_available()를 통해 현재 torch의 CUDA가 사용할 수 없는 상태라는 것을 확인하였고
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121위 명령어를 통해 현재 CUDA 버전에 맞는 torch를 재설치해주었다.
 또한 CUDA Driver도 기존
또한 CUDA Driver도 기존 12.5에서 12.1로 다운그레이드 하였고
 FastAPI 서버를 실행했을 때 위와 같이 Torch CUDA가 available 하다는 것을 확인할 수 있었다.
FastAPI 서버를 실행했을 때 위와 같이 Torch CUDA가 available 하다는 것을 확인할 수 있었다.
while (1) {cls; nvidia-smi; sleep 1}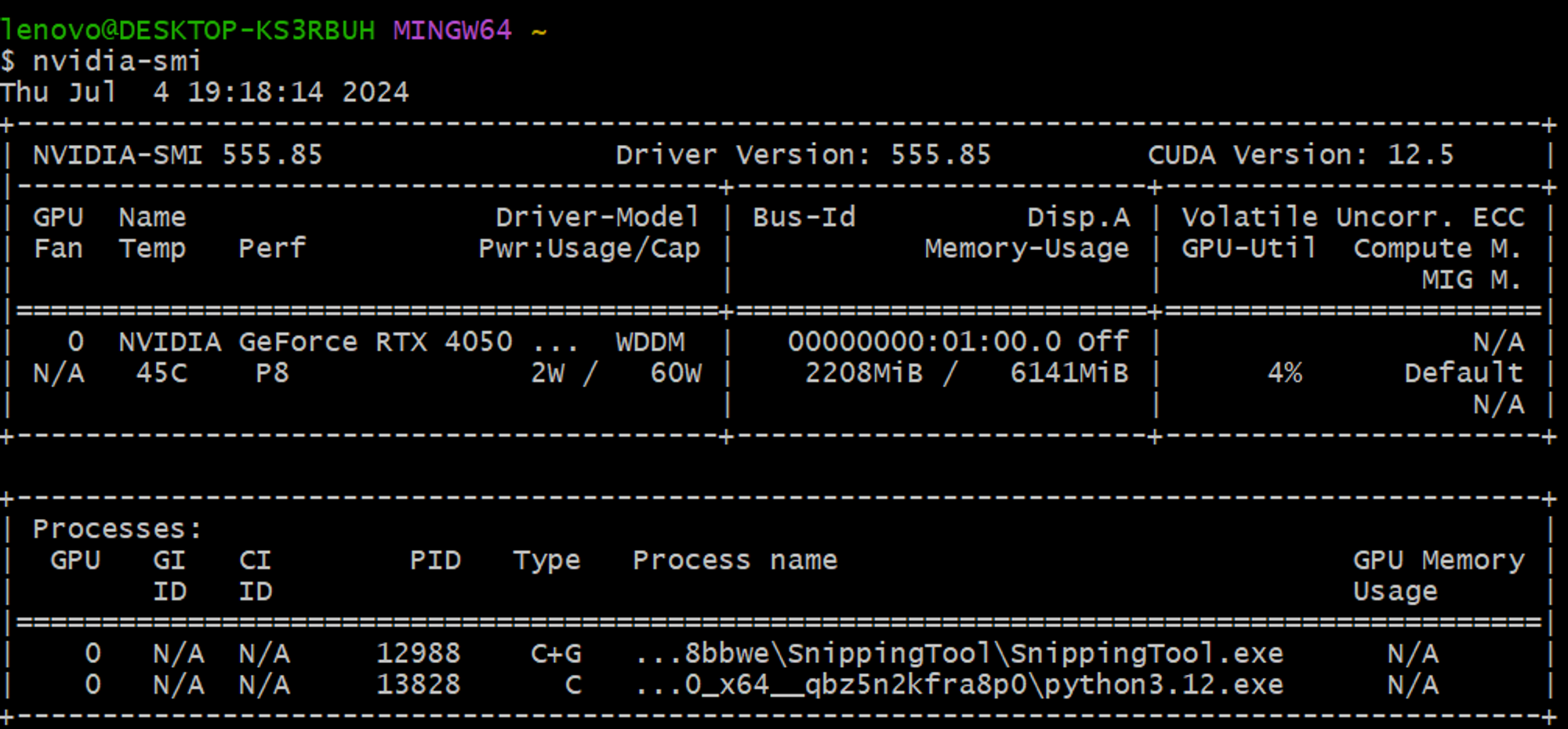 또한 위와 같이 nvidia-smi 명령어를 통해 정상적으로 Python3가 GPU 위에서 구동되고 있는 것을 확인하였다.
또한 위와 같이 nvidia-smi 명령어를 통해 정상적으로 Python3가 GPU 위에서 구동되고 있는 것을 확인하였다.
Trouble Shooting : CUDA out of memory
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 172.00 MiB. GPU하지만 HuggingFace의 llama-2 모델을 구동하였을 때 현재 GPU의 메모리 한계로 위와 같이 OOM 오류가 발생하였다.
Ollama
따라서 HuggingFace의 모델이 아닌 ollama를 기기에서 구동하고 이를 LangChain을 통해 활용하는 방향으로 구현하였다.
ollama pull llama3:<태그> 먼저 위와 같이 ollama를 설치하고 llama3를 PULL한다.
먼저 위와 같이 ollama를 설치하고 llama3를 PULL한다.
이전 음성 인식 결과:
{이것은 시장 경제에 대한 설명입니다.}
현재 음성 인식 결과:
{시장 경제는 가격 아아아아아아아아아 기구를 통해 자원을 배분하는 경제 체제입니다.}
이전 결과를 고려하여 현재 음성인식 결과를 문법적으로 올바르게 수정하고,
잡음이나 인식 오류를 제거해주세요.
문맥을 고려하여 자연스럽게 연결되도록 해주세요.
또한 수정된 현재 음성인식 결과만 도출해주세요이후 모델을 테스트하기 위하여 프롬프트를 위와 같이 구성하고
 이를 Ollama에 입력하여 정상적으로 결과가 도출되는 것을 확인하였다.
이를 Ollama에 입력하여 정상적으로 결과가 도출되는 것을 확인하였다.
# Model Import
print("[langchain] Torch CUDA Available : ", torch.cuda.is_available())
device = 0 if torch.cuda.is_available() else -1
if device==0: torch.cuda.empty_cache()
model_id = "llama3"
print("[langchain] Importing LLM Model :", model_id)
llm = ChatOllama(model=model_id)
print("[langchain]-[" + model_id + "]", llm.invoke("Hello World!"))
print("[langchain] Imported LLM Model :", model_id)또한 위와 같이 LangChain에서 ChatOllama을 통해 llama3 모델을 임포트 하였고.
 정상적으로 FastAPI 서버에서 모델을 활용하는 것을 볼 수 있었다.
정상적으로 FastAPI 서버에서 모델을 활용하는 것을 볼 수 있었다.
langchain.py
import os
import torch
from uuid import uuid4
from dotenv import load_dotenv
# from langchain_community.llms import HuggingFaceHub
# from langchain_community.llms import HuggingFacePipeline
from langchain_community.chat_models import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# .env HUGGINGFACEHUB_API_TOKEN 불러오기
load_dotenv()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = os.getenv("HUGGINGFACEHUB_API_TOKEN")
# 음성 인식 결과를 저장할 Chroma DB 생성
embeddings = HuggingFaceEmbeddings()
vectordb = Chroma(embedding_function=embeddings, persist_directory="./db")
# Model Import
print("[langchain] Torch CUDA Available : ", torch.cuda.is_available())
device = 0 if torch.cuda.is_available() else -1
if device==0: torch.cuda.empty_cache()
model_id = "llama3"
print("[langchain] Importing LLM Model :", model_id)
llm = ChatOllama(model=model_id)
print("[langchain]-[" + model_id + "]", llm.invoke("Hello World!"))
print("[langchain] Imported LLM Model :", model_id)
def speech_to_text_modification(connection_uuid, converted_text):
# 이전 음성 인식 결과 검색
docs = vectordb.similarity_search(converted_text, k=3)
context = " ".join([doc.page_content for doc in docs])
# 텍스트 수정을 위한 프롬프트 템플릿
correction_template = f"""
이전 음성 인식 결과:
{context}
현재 음성 인식 결과:
{converted_text}
실시간 음성인식 결과를 더욱 매끄럽게 하기 위해 위 문장에 기반하여 아래 조건의 작업을 수행해주세요.
1. 이전 결과를 고려하여 현재 텍스트를 문법적으로 올바르게 수정해주세요.
2. 현재 음성 인식 결과에서 잡음이나 인식 오류를 제거해주세요.
3. 이전 음성 인식 결과과의 문맥을 고려하여 자연스럽게 연결되도록 현재 음성 인식 결과를 수정해주세요.
4. 답변은 한국어로 번역해주세요.
4-1. 단, 음성인식 결과에 타 언어로 된 전문용어가 들어가 있다면 한국어로 변역하지 말아주세요.
5. 추가적인 설명 없이 수정된 현재 음성 인식 결과만 제공해주세요.
"""
# PromptTemplate : 원시 사용자 입력을 더 나은 입력으로 변환
# OutputParser : 채팅 메시지를 문자열로 변환하는 출력 구문 분석기
prompt1 = ChatPromptTemplate.from_template("[{korean_input}] translate the question into English. Don't say anything else, just translate it.")
chain1 = (
prompt1
| llm
| StrOutputParser()
)
prompt2 = ChatPromptTemplate.from_messages([
("system", "You are a helpful, professional assistant in korean university. answer the question in Korean"),
("user", "{input}")
])
chain2 = (
{"input": chain1}
| prompt2
| llm
| StrOutputParser()
)
corrected_text = chain2.invoke({"korean_input":correction_template})
print(corrected_text)
# 수정된 텍스트를 Chroma DB에 저장
vectordb.add_texts(
texts=[corrected_text],
metadatas=[{"connection_uuid": connection_uuid}],
ids=[str(uuid4())],
)
return corrected_text이후 위와 같이 LangChain을 다시 구축하였고 Chroma에 이전 LLM 결과를 저장하는 로직 또한 추가하였다.
main.py
...
app.include_router(websocket.router)
app.mount("/images", StaticFiles(directory="images"), name="images")
@app.get("/")
def read_root():
return FileResponse("./templates/index.html")
@app.get("/sttModification")
def sttModification(text: str = Query(..., description="The text to be modified")):
print("[main]-[sttModification] API Call :", text)
return langchain.speech_to_text_modification("example_connection_uuid", text)인퍼런스된 모델을 테스트 하기 위해 main.py에서 위와 같이 API를 구성하였다.
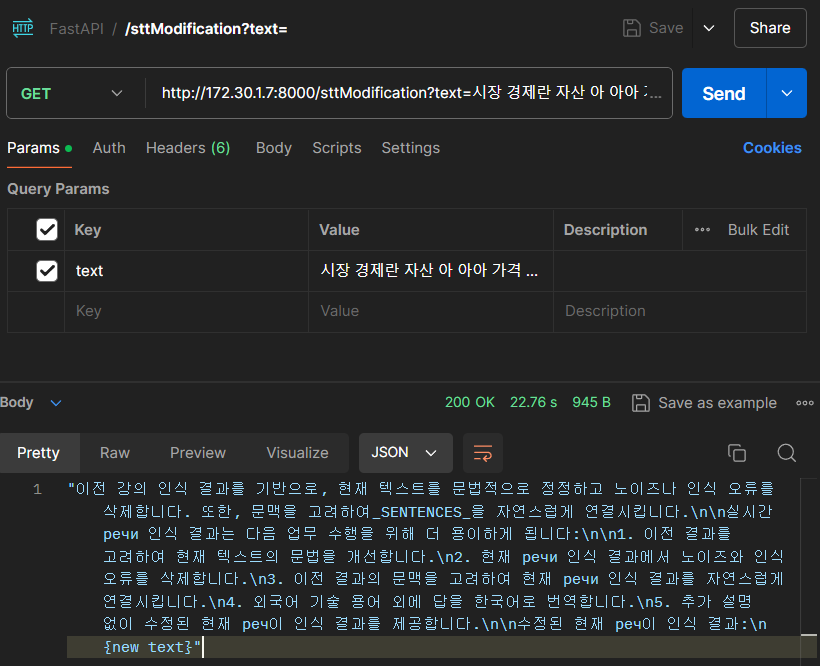 Postman으로 위와 같이 GET 요청을 하면
Postman으로 위와 같이 GET 요청을 하면
 위와 같이 요청한 텍스트에 대해서 llama3가 정상적으로 실행되는 것을 볼 수 있다.
위와 같이 요청한 텍스트에 대해서 llama3가 정상적으로 실행되는 것을 볼 수 있다.
FastAPI STT Logic with LangChain
langchain.py
import re
import json
def speech_to_text_modification(connection_uuid, converted_text):
...
corrected_text = chain1.invoke({"textData" : textData})
json_result = parse_JSON(corrected_text)
result_value = json_result.get('result')
if result_value:
print("Result value:", result_value)
else:
print("No 'result' key found in the JSON")
return False
# 수정된 텍스트를 Chroma DB에 저장
vectordb.add_texts(
texts=[result_value],
metadatas=[{"connection_uuid": connection_uuid}],
ids=[str(uuid4())],
)
return result_value
def parse_JSON(llm_response):
json_pattern = re.compile(r'{[^{}]*?}')
print(llm_response)
# LLM 응답에서 JSON 값 찾기
json_match = json_pattern.findall(llm_response)
if json_match:
json_str = json_match[-1]
print(json_match)
print(json_str)
try:
json_data = json.loads(json_str)
return json_data
except json.JSONDecodeError:
print("Invalid JSON format")
return None
else:
print("No JSON found in the LLM response")
return None이를 STT Logic과 함께 활용하기 위해서 parse_JSON 메소드를 구현하고 LLM 응답에서 결과만 추출할 수 있게 하였다.
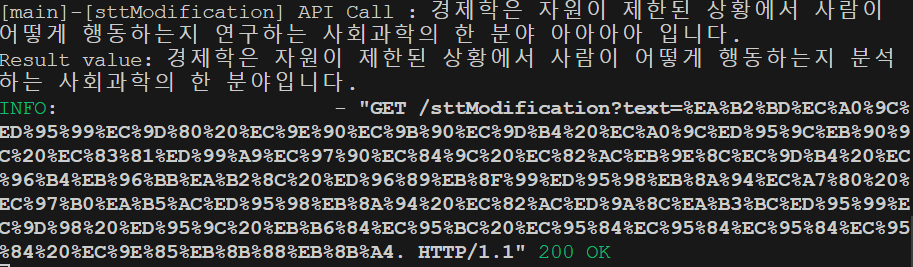 위와 같이 정상적으로 LLM 응답의 설명과 NOTE 없이 결과만 받아오는 것을 볼 수 있었다.
위와 같이 정상적으로 LLM 응답의 설명과 NOTE 없이 결과만 받아오는 것을 볼 수 있었다.
langchain.py
def speech_to_text_modification(connection_uuid, converted_text):
# 이전 음성 인식 결과 검색
# 마지막 3개의 음성만을 가져온다
docs = vectordb.max_marginal_relevance_search(converted_text, k=3)
context = " ".join([doc.page_content for doc in reversed(docs)])
print(context)
...
# Chroma DB에 데이터 저장
vectordb.add_documents(
documents=[Document(page_content=result_value, metadata={"connection_uuid": connection_uuid})],
ids=[str(uuid4())],
)
return result_value
def delete_data_by_uuid(connection_uuid):
# connection_uuid에 해당하는 데이터 삭제
vectordb.delete(ids=vectordb.get_document_ids_by_metadata_value(key="connection_uuid", value=connection_uuid))
print(f"[langchain] Data with connection_uuid '{connection_uuid}' has been deleted from ChromaDB.")또한 Chorma에 데이터를 저장하는 로직을 위와 같이 수정하였으며
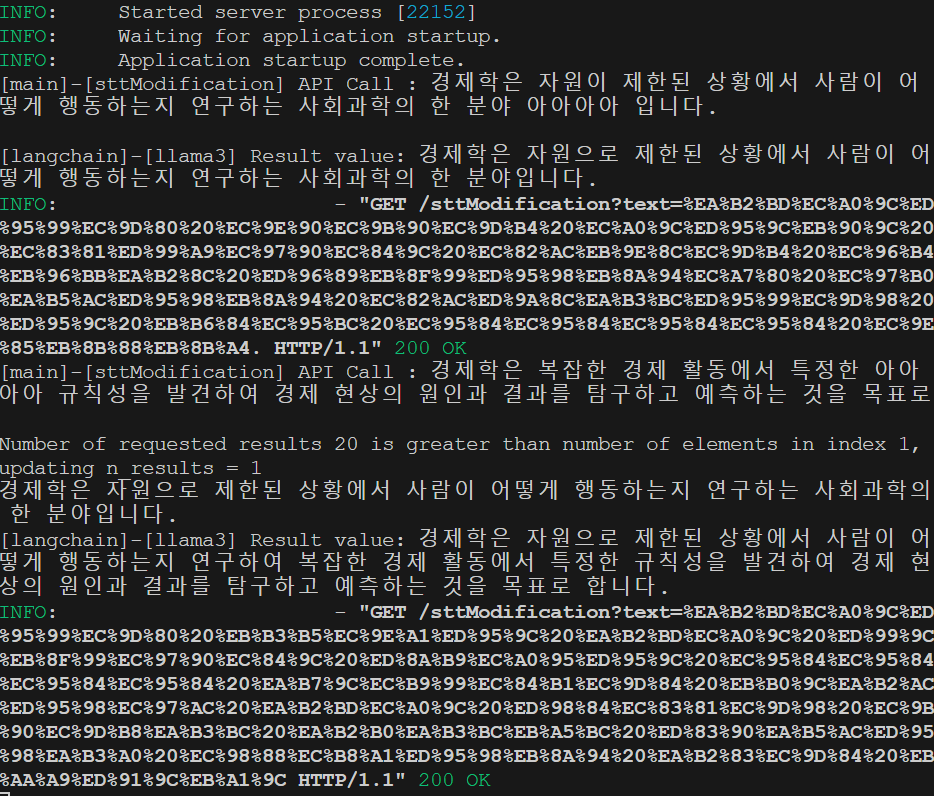 정상적으로 이전의 변환된 정보에 기반하여 새로운 텍스트를 생성하는 것을 볼 수 있다.
정상적으로 이전의 변환된 정보에 기반하여 새로운 텍스트를 생성하는 것을 볼 수 있다.
websocket.py
def llm_modification(websocket, connection_uuid):
print("[LLMThread] LLM Thread Initiated")
while not stop_event.is_set():
sleep(0.25)
try:
if not result_queue.empty():
transcrition_result = result_queue.get()
print("[LLMThread] ", transcrition_result)
llm_result = langchain.speech_to_text_modification(connection_uuid, transcrition_result)
if llm_result:
websocket.send_text(llm_result)
else:
websocket.send_text(transcrition_result)
except Exception as e:
print(f"[LLMThread] Error llm_modification: {e}")
break
print("[LLMThread] LLM Thread Destroyed")
@router.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
print("[WebSocket] Configuring BE Client WebSocket")
await websocket.accept()
# Load Model
model = "medium"
whisper_model = whisper.load_model(model)
print("[Whisper] Model Loaded Successfully")
# Accept WebSocket
connection_uuid = await websocket.receive_text()
print("[WebSocket] Connection [" + connection_uuid + "] Accepted")
# Execute STT Thread until WebSocket Disconnected
stt_thread = threading.Thread(target=speechToText, args=(whisper_model, stop_event))
stt_thread.start()
llm_thread = threading.Thread(target=llm_modification, args=(websocket, connection_uuid))
llm_thread.start()
# Receive AudioBlob
try:
while True:
audioBlob = await websocket.receive_bytes()
data_queue.put(audioBlob)
# Sleep for other async functions
await asyncio.sleep(0)
except Exception as e:
print(f"[WebSocket] WebSocket error: {e}")
finally:
await websocket.close()
stop_event.set()
stt_thread.join()
llm_thread.join()
# clear stop_event for next Socket Connection
stop_event.clear()
while not data_queue.empty():
data_queue.get()
while not result_queue.empty():
result_queue.get()
langchain.delete_data_by_uuid(connection_uuid)
print("[WebSocket] Connection Closed")또한 전체 STT 로직에 LLM을 적용시키기 위하여 위와 같이 llm_modification 메소드에서 LLM 결과를 반영하고 판단하여, 최종 변환 결과를 WebSocket을 통해 전달하는 것을 목표로 하였다.
WebSocketUtil.java
...
private void connectFastAPI(Timer timer, SocketIOClient client){
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
try {
if(fastAPIWebSocket == null || fastAPIWebSocket.isClosed()) {
fastAPIWebSocket = new WebSocketUtil(
new URI(FastAPIEndpoint + "/ws"),
new Draft_6455(),
client
);
fastAPIWebSocket.connectBlocking();
fastAPIWebSocket.send(String.valueOf(UUID.randomUUID()));
}
} catch (Exception e) {
// Handle connection exceptions
log.info("[WebRTCProxy]-[connectFastAPI] WebSocket Connection Failed");
}
}
}, 0, 60);
}Java에서도 위와 같이 fastAPIWebSocket이 연결되었을 때 fastAPIWebSocket.send(String.valueOf(UUID.randomUUID()));를 통해 해당 연결의 UUID를 전송하여 Chroma에서 텍스트 정보를 WebSocket 세션에 맞게 유지하고 삭제할 수 있도록 하였다.
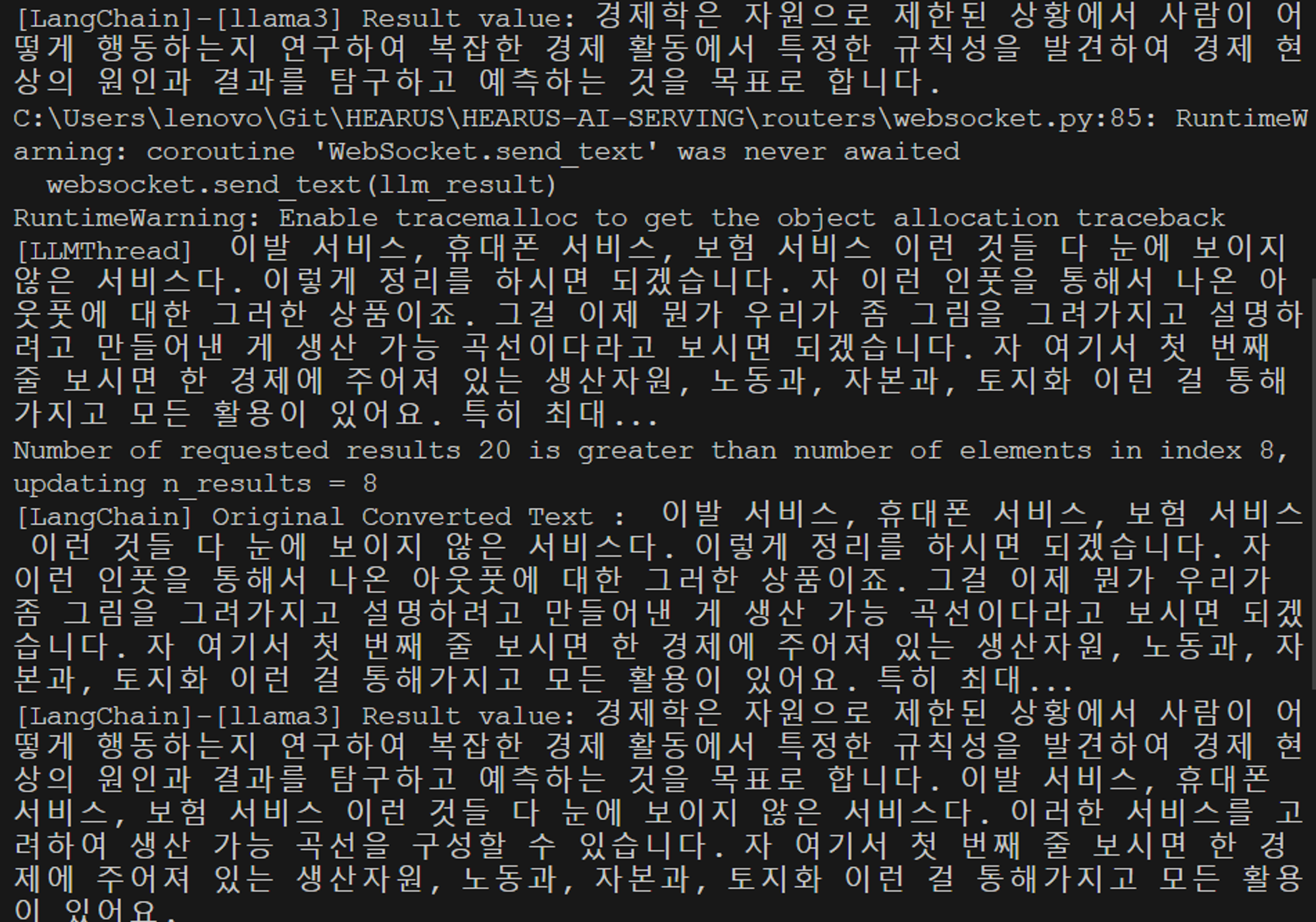 이후 위와 같이 실시간 음성인식에 기반하여 데이터가 변환되고 전달되는 것을 볼 수 있다.
이후 위와 같이 실시간 음성인식에 기반하여 데이터가 변환되고 전달되는 것을 볼 수 있다.
LangChain with STT Optimization, Restructure
하지만 위 방법은 LLM Thread와 Whisper가 함께 작동하고, 기본적으로 실시간 데이터를 처리하기 때문에 LLM 결과를 받고 다시 React Client까지 전달하는데까지 10초 이상의 과도한 지연시간이 발생해야 해서 LLM Thread와 구조를 최적화 해야 하는 문제가 있었다.
# Model Import
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if device.type == "cuda":
torch.cuda.empty_cache()
print("[LangChain] Torch CUDA Available : ", torch.cuda.is_available())
print("[LangChain] Current Device : ", device)
model_id = "llama3"
print("[LangChain] Importing LLM Model :", model_id)
llm = ChatOllama(model=model_id, device=device)
print("[LangChain]-[" + model_id + "]", llm.invoke("Hello World!"))
print("[LangChain] Imported LLM Model :", model_id)우선 위와 같이 LLAMA3 모델을 Import할 때 GPU를 사용하도록 변경한다.
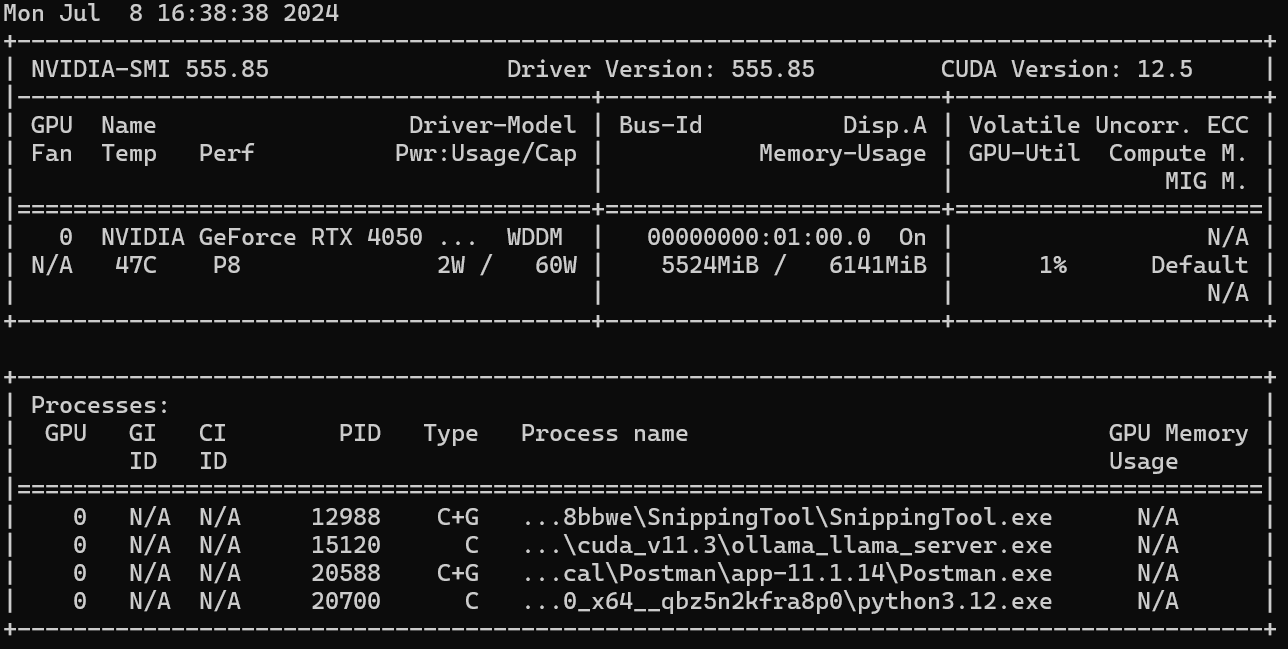 이후 위와 같이 실제로 GPU에 ollama_llama_server가 올라가 있는 것을 확인할 수 있었다
이후 위와 같이 실제로 GPU에 ollama_llama_server가 올라가 있는 것을 확인할 수 있었다
 또한 CPU를 사용했을 때보다 훨씬 빠르게 Prompt의 결과를 도출해내었다.
또한 CPU를 사용했을 때보다 훨씬 빠르게 Prompt의 결과를 도출해내었다.
main.py
@app.get("/sttModification")
async def sttModification(text: str = Query(..., description="The text to be modified")):
print("[main]-[sttModification] API Call :", text)
llm_result = await asyncio.create_task(langchain.speech_to_text_modification(
"connection_uuid",
text
))
return llm_resultFastAPI는 ASGI중 한 종류인 uvicorn과 함께 비동기적인 형태로 동작하기 때문에
동기 작업인 WebSocket, LangChain Invoke, Whisper Transciption 등과 API가 동시에 작동할 수 없었기 때문에 위와 같이 asyncio를 통해 새로운 Task를 생성하고 API를 처리한다.
langchain.py
async def speech_to_text_modification(connection_uuid, converted_text):
# 이전 음성 인식 결과 검색
# 마지막 3개의 음성만을 가져온다
docs = await asyncio.to_thread(
vectordb.get,
where={"connection_uuid": connection_uuid}, # metadata 필터링 조건 지정
)
context = " ".join(docs['documents'][-3:])
print("[LangChain] Connection UUID : ", connection_uuid)
print("[LangChain] Previous context : ", context)
print("[LangChain] Converted Text : ", converted_text)
textData = f"""
이전 음성 인식 결과:
{context}
현재 음성 인식 결과:
{converted_text}
"""
# PromptTemplate : 원시 사용자 입력을 더 나은 입력으로 변환
# OutputParser : 채팅 메시지를 문자열로 변환하는 출력 구문 분석기
prompt = ChatPromptTemplate.from_template("""
{textData}
...
""")
chain1 = (
prompt
| llm
| StrOutputParser()
)
...
corrected_text = await asyncio.to_thread(chain1.invoke, {"textData": textData})
json_result = parse_JSON(corrected_text)
if json_result:
result_value = json_result.get('result')
if result_value:
print("[LangChain]-[" + model_id + "] Result value:", result_value)
else:
return None
else:
print("[LangChain]-[" + model_id + "] No 'result' key found in the JSON")
return None
# Chroma DB에 데이터 저장
await asyncio.to_thread(
vectordb.add_documents,
documents=[Document(page_content=result_value, metadata={"connection_uuid": connection_uuid})],
ids=[str(uuid4())],
)
return result_value이후 위와 같이 메소드에 async 키워드를 붙여 비동기 메소드로 만들어주고 동기 작업들을 모두 별도의 Thread나 Task를 생성하여 수행할 수 있게 수정하였다.
websocket.py
WebSocket의 경우 기존의 루틴과는 다르게 STT, LLM, WebSocket.receive() 마다 각각의 비동기 Task를 생성하여 전체 루틴을 처리해주었다.
# Thread safe Queue for passing result from Process Thread to LLM Thread
llm_queue = Queue()
class Message:
def __init__(self, text_id, transcrition_result):
self.text_id = text_id
self.transcrition_result = transcrition_result우선 추후 로직 변경시 변환된 텍스트의 식별을 가능케하기 위하여 위와 같이 별도의 Message 클래스를 정의하였다.
def speechToText(whisper_model, stop_event):
print("[STTThread] STT Thread Executed")
max_audio_duration = 5 # 최대 오디오 길이 (초)
sample_rate = 16000 # 오디오 샘플 레이트 (Hz)
max_audio_size = max_audio_duration * sample_rate * 2 # 최대 오디오 크기 (바이트)
while not stop_event.is_set():
sleep(0.25)
try:
now = datetime.utcnow()
# Pull raw recorded audio from the queue.
if not data_queue.empty():
# Combine audio data from queue up to max_audio_size
audio_data = bytearray()
while not data_queue.empty() and len(audio_data) < max_audio_size:
chunk = data_queue.get()
audio_data.extend(chunk)
# Make total size of audio_data multiple of 2
total_size = len(audio_data)
if total_size % 2 != 0:
padding_size = 2 - (total_size % 2)
# Add padding bytes
audio_data.extend(b"\0" * padding_size)
# Convert audio_data to bytes
audio_data = bytes(audio_data)
...또한 이후 speechToText 메소드에서 지연시간이 발생해 data_queue에 너무 많은 데이터가 쌓일 경우 Whisper 모델의 부하를 줄이기 위하여 위와 같이 최대 오디오 길이를 설정하고 최대 5초만큼의 데이터만 Whisper 모델에서 다루도록 하였다.
async def llm_thread(websocket: WebSocket, connection_uuid):
print("[LLMTask] LLM Task Initiated")
while not stop_event.is_set():
await asyncio.sleep(0.25)
try:
if not llm_queue.empty():
message = llm_queue.get()
transcrition_result = message.transcrition_result
text_id = message.text_id
# langchain.speech_to_text_modification 함수를 별도의 비동기 작업으로 실행
llm_result = await asyncio.create_task(langchain.speech_to_text_modification(
connection_uuid,
transcrition_result
))
message_data = {
"textId": text_id,
"transcritionResult": llm_result
}
message_json = json.dumps(message_data, ensure_ascii=False)
await websocket.send_text(message_json)
except Exception as e:
print(f"[LLMTask] Error : {e}")
break
print("[LLMTask] Process Task Destroyed")llm_thread에서는 llm_queue에 있는 데이터에 대해서 새로운 LangChain Task를 생성하고 이를 다시 WebSocket을 통해 전달할 수 있도록 하였다.
async def process_thread(websocket: WebSocket):
print("[ProcessTask] Process Task Initiated")
while not stop_event.is_set():
await asyncio.sleep(0.25)
try:
if not result_queue.empty():
transcrition_result = result_queue.get()
text_id = str(uuid.uuid4())
message = Message(text_id, transcrition_result)
llm_queue.put(message)
message_data = {
"textId": text_id,
"transcritionResult": transcrition_result
}
message_json = json.dumps(message_data, ensure_ascii=False)
await websocket.send_text(message_json)
except Exception as e:
print(f"[ProcessTask] Error : {e}")
break
print("[ProcessTask] Process Task Destroyed")process_thread의 경우 Whisper를 통해 변환된 텍스트를 result_queue에서 받아와 WebSocket으로 전달할 수 있게 하였다.
async def websocket_task(websocket: WebSocket):
# Load Model
model = "medium"
whisper_model = whisper.load_model(model)
print("[WebSocketTask]-[Whisper] Model Loaded Successfully")
# Accept WebSocket
connection_uuid = await websocket.receive_text()
print("[WebSocketTask] Connection [" + connection_uuid + "] Accepted")
# Execute STT Thread until WebSocket Disconnected
sttThread = threading.Thread(target=speechToText, args=(whisper_model, stop_event))
sttThread.start()
llmTask = asyncio.create_task(llm_thread(websocket, connection_uuid))
processTask = asyncio.create_task(process_thread(websocket))
# Receive AudioBlob
try:
while True:
audioBlob = await websocket.receive_bytes()
data_queue.put(audioBlob)
# Sleep for other async functions
await asyncio.sleep(0)
except Exception as e:
print(f"[WebSocketTask] WebSocket error: {e}")
finally:
stop_event.set()
sttThread.join()
llmTask.cancel()
processTask.cancel()
# clear stop_event for next Socket Connection
stop_event.clear()
while not data_queue.empty():
data_queue.get()
while not result_queue.empty():
result_queue.get()
while not llm_queue.empty():
llm_queue.get()
langchain.delete_data_by_uuid(connection_uuid)
if websocket.client_state.name != "DISCONNECTED":
await websocket.close()
print("[WebSocketTask] Connection Closed")또한 websocket_task는 WebSocket 연결 이후 다른 Thread와 Task를 생성하는 역할을 하며, WebSocket Client로부터의 음성 데이터를 data_queue에 저장한다.
@router.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
print("[WebSocket] Configuring BE Client WebSocket")
await websocket.accept()
print("[WebSocket] Configuring WebSocket Task")
await asyncio.create_task(websocket_task(websocket))최종적으로 위와 같이 /ws 라우터를 다시 설정하여 accept()된 이후 websocket_task를 생성하여주고 테스트를 진행하면
 위와 같이 정상적으로 STTThread에서 실시간 음성인식을 수행하는 것을 볼 수 있으며
위와 같이 정상적으로 STTThread에서 실시간 음성인식을 수행하는 것을 볼 수 있으며
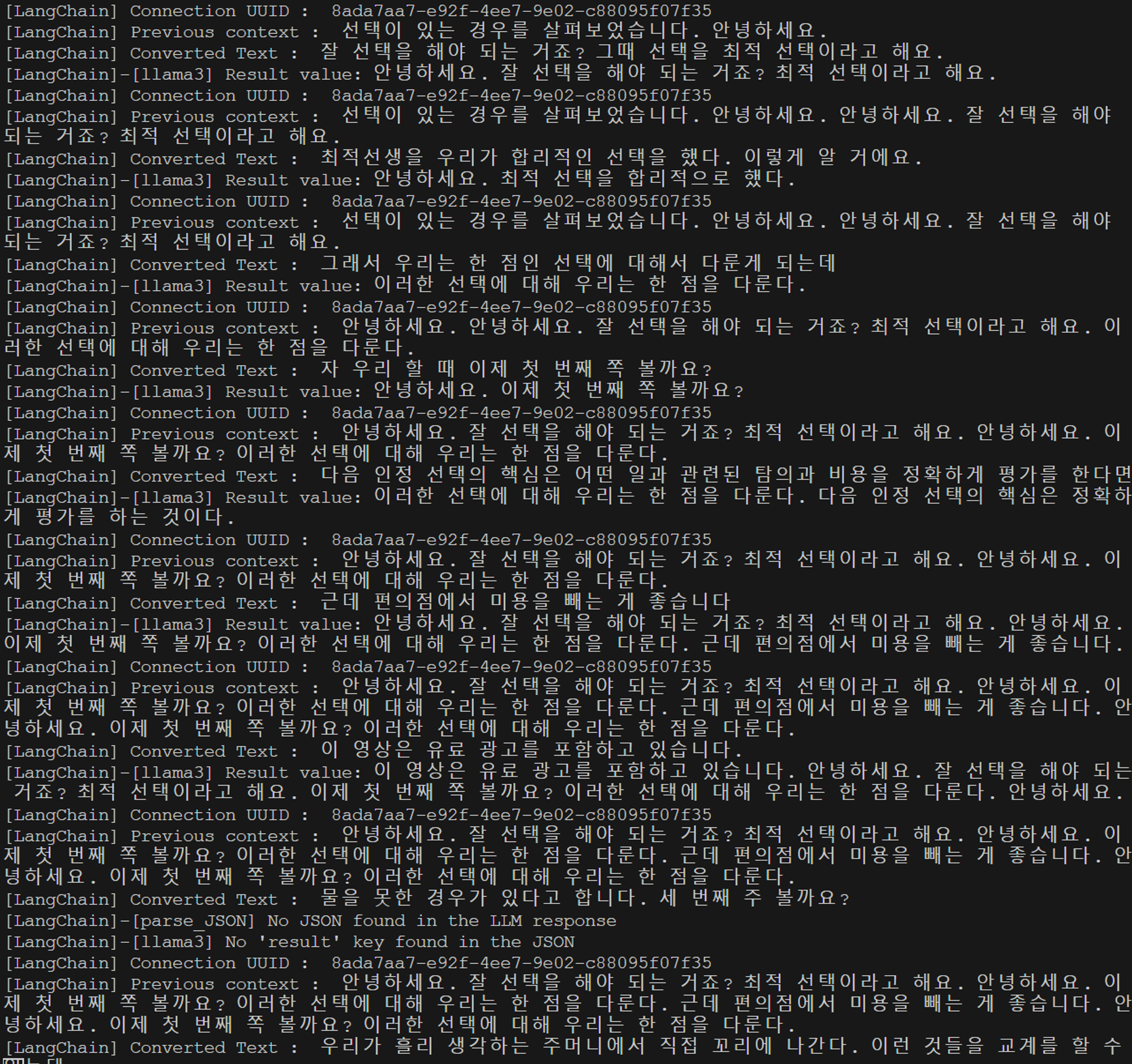 LanChain에서도 이전에 계획했던 내용과 마찬가지로 문맥을 수정하는 것을 볼 수 있다.
LanChain에서도 이전에 계획했던 내용과 마찬가지로 문맥을 수정하는 것을 볼 수 있다.
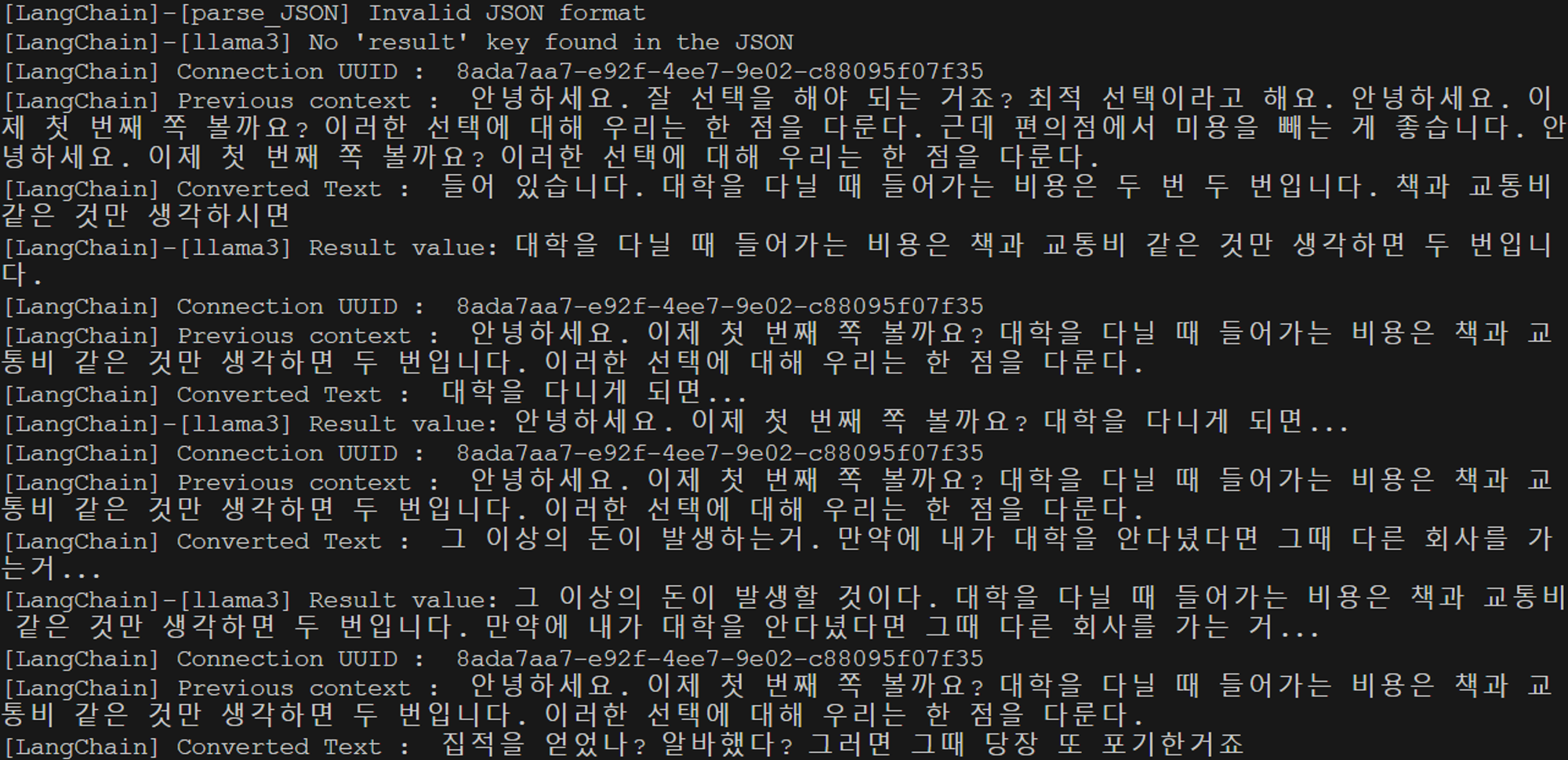 또한 LLM 결과가 잘못되었을 경우
또한 LLM 결과가 잘못되었을 경우 parse_JSON에서 정상적으로 오류를 띄워주는 것을 볼 수 있다.
 변환된 결과가 Spring Boot으로도 정상적으로 전달되고
변환된 결과가 Spring Boot으로도 정상적으로 전달되고
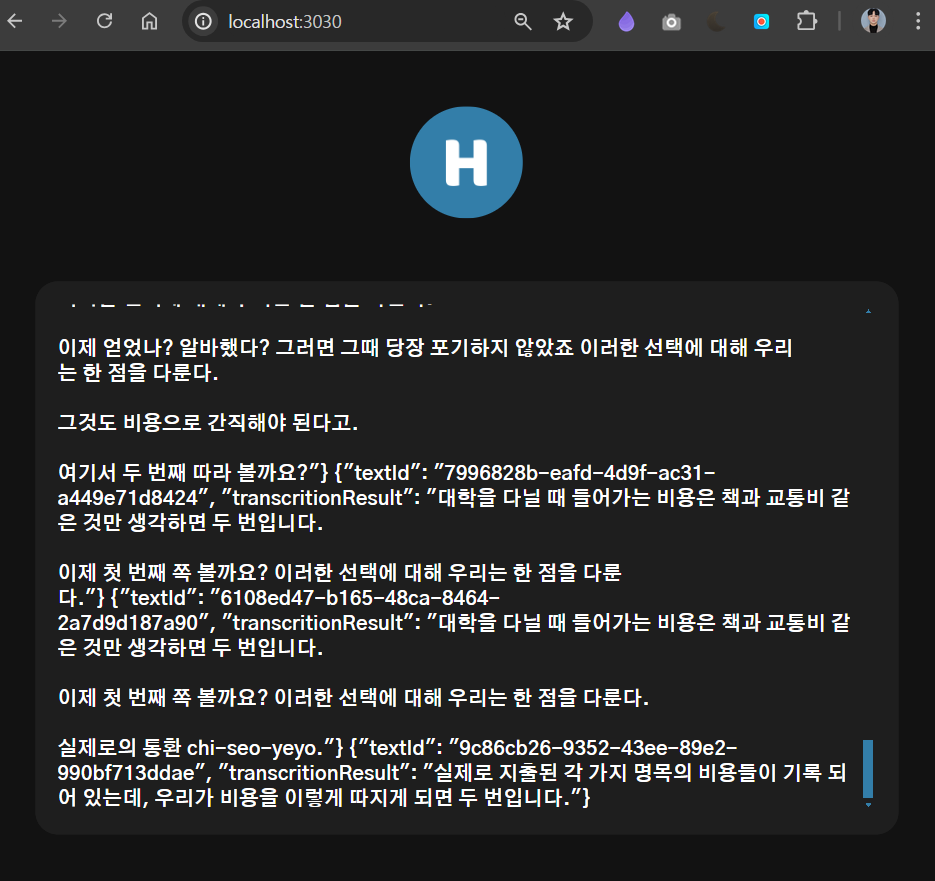 최종적으로 Vue FE에도 전달되는 것을 볼 수 있다.
최종적으로 Vue FE에도 전달되는 것을 볼 수 있다.
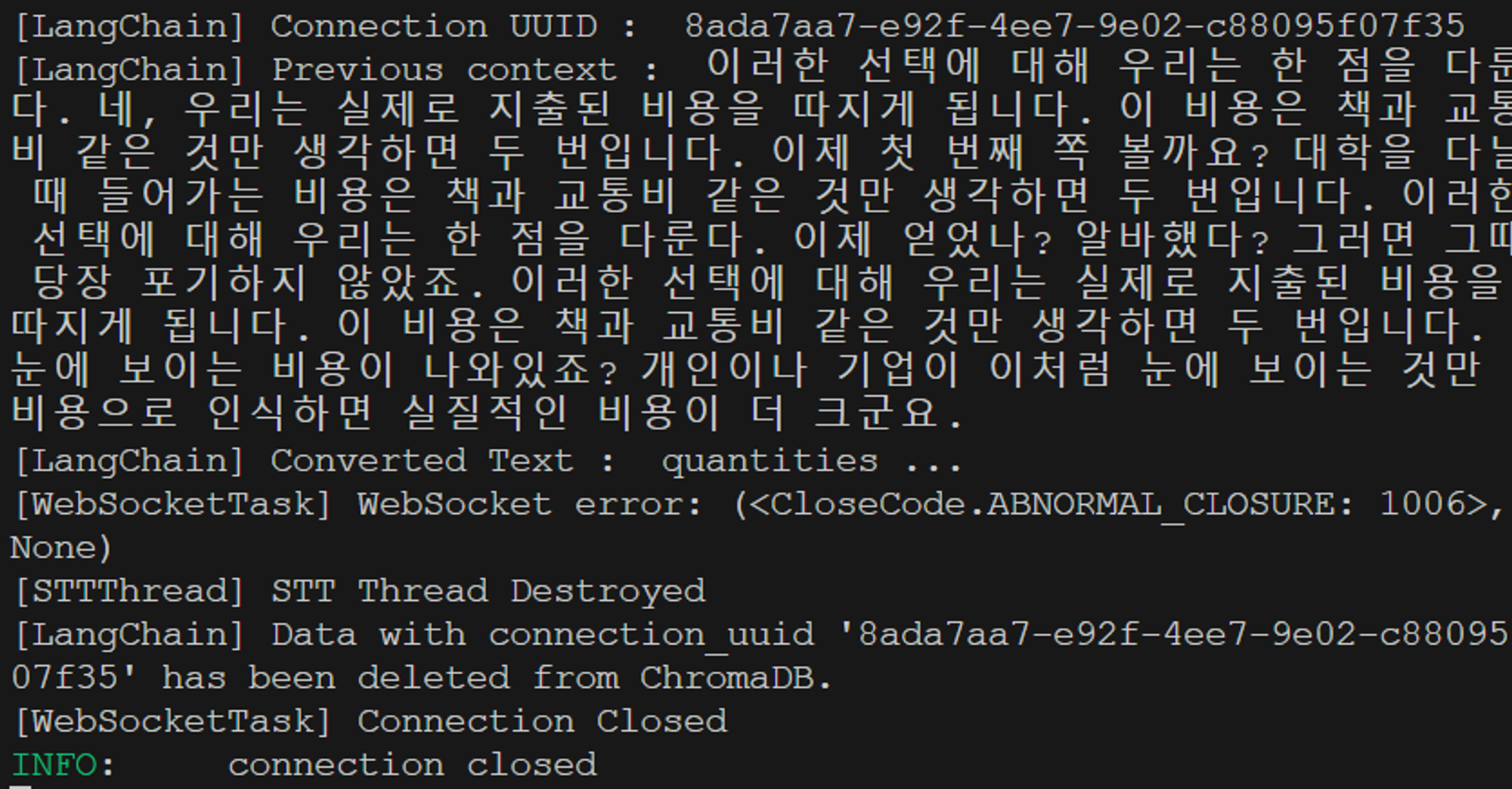 또한 연결이 해제되었을 때 모든 Thread와 Task가 중지되고 LangChain의 ChromaDB의 Connection UUID에 해당하는 데이터들이 삭제되는 것을 볼 수 있다.
또한 연결이 해제되었을 때 모든 Thread와 Task가 중지되고 LangChain의 ChromaDB의 Connection UUID에 해당하는 데이터들이 삭제되는 것을 볼 수 있다.
# enforece GPU if CUDA is available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
whisper_model = whisper.load_model(model, device=device)
print("[WebSocketTask]-[Whisper] Model Loaded Successfully with", device)하지만 여전히 Whisper 모델이 작동하는 와중에 LangChain이 정상적으로 수행되지 않았도 Whisper 모델 또한 위와 같이 GPU를 사용할 수 있도록 변경하였다.
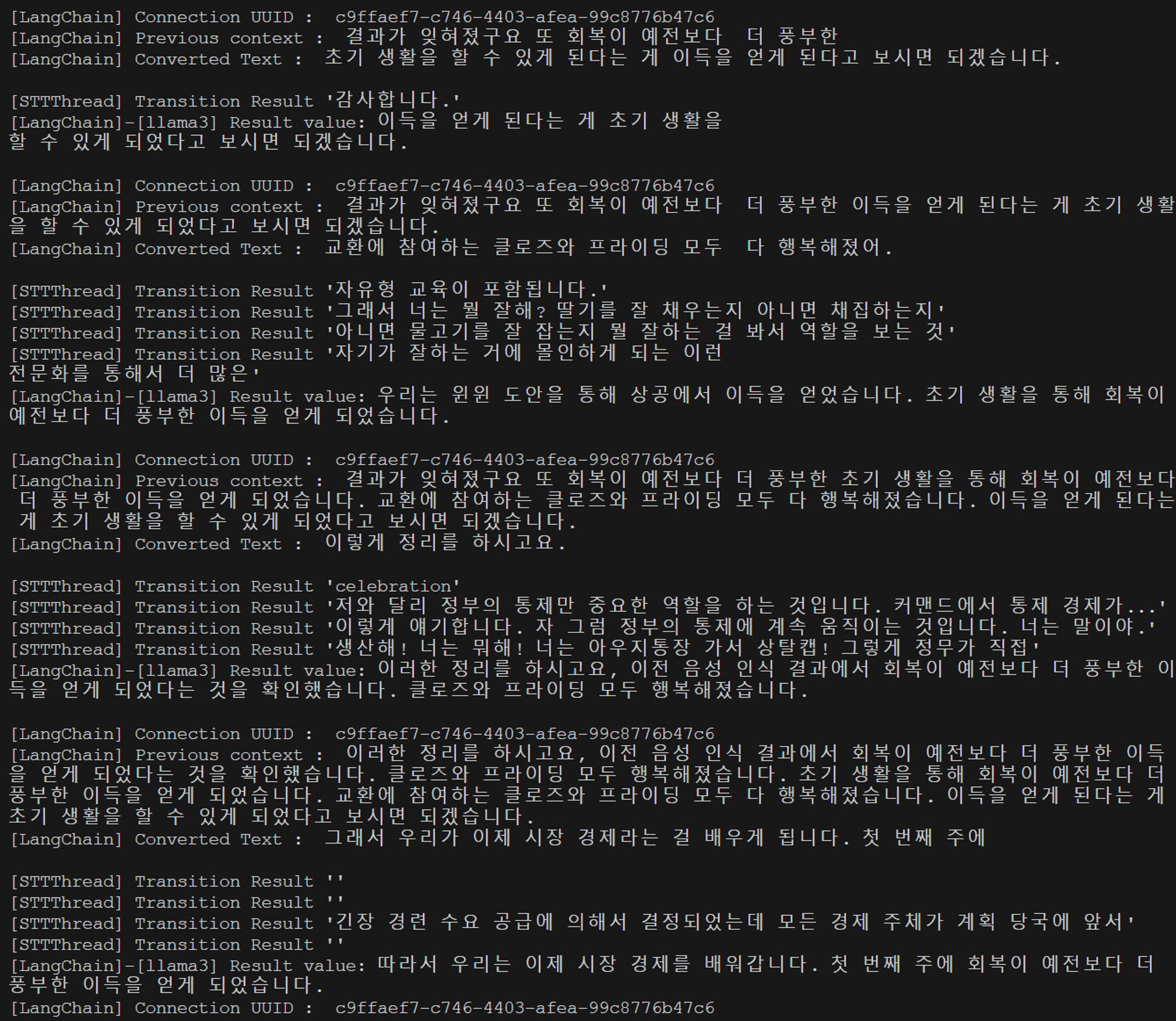 그 결과 위와 같이 STTThread에서 Whisper 모델이 실시간 음성인식을 수행하는 와중에도 LangChain의 Llama 모델이 작동하는 것을 볼 수 있었다.
그 결과 위와 같이 STTThread에서 Whisper 모델이 실시간 음성인식을 수행하는 와중에도 LangChain의 Llama 모델이 작동하는 것을 볼 수 있었다.
async def llm_thread(websocket: WebSocket, connection_uuid):
print("[LLMTask] LLM Task Initiated")
while not stop_event.is_set():
await asyncio.sleep(0.25)
try:
if not llm_queue.empty():
message = llm_queue.get()
transcrition_result = message.transcrition_result
text_id = message.text_id
# langchain.speech_to_text_modification 함수를 별도의 비동기 작업으로 실행
llm_result = await asyncio.create_task(langchain.speech_to_text_modification(
connection_uuid,
transcrition_result
))
if not llm_result:
llm_result = transcrition_result
message_data = {
"textId": text_id,
"transcritionResult": llm_result
}
message_json = json.dumps(message_data, ensure_ascii=False)
await websocket.send_text(message_json)
except Exception as e:
print(f"[LLMTask] Error : {e}")
break
print("[LLMTask] Process Task Destroyed")
async def process_thread(websocket: WebSocket):
print("[ProcessTask] Process Task Initiated")
while not stop_event.is_set():
await asyncio.sleep(0.25)
try:
if not result_queue.empty():
transcrition_result = result_queue.get()
text_id = str(uuid.uuid4())
message = Message(text_id, transcrition_result)
llm_queue.put(message)
# message_data = {
# "textId": text_id,
# "transcritionResult": transcrition_result
# }
# message_json = json.dumps(message_data, ensure_ascii=False)
# await websocket.send_text(message_json)
except Exception as e:
print(f"[ProcessTask] Error : {e}")
break
print("[ProcessTask] Process Task Destroyed")추후 배포 과정에서 GPU 성능이 보장된다면 지연시간 없이 LLM 모델을 사용할 수 있을 것이라 판단해 위와 같이 LLM의 결과만 전송하는 형태로 구조를 수정하였고
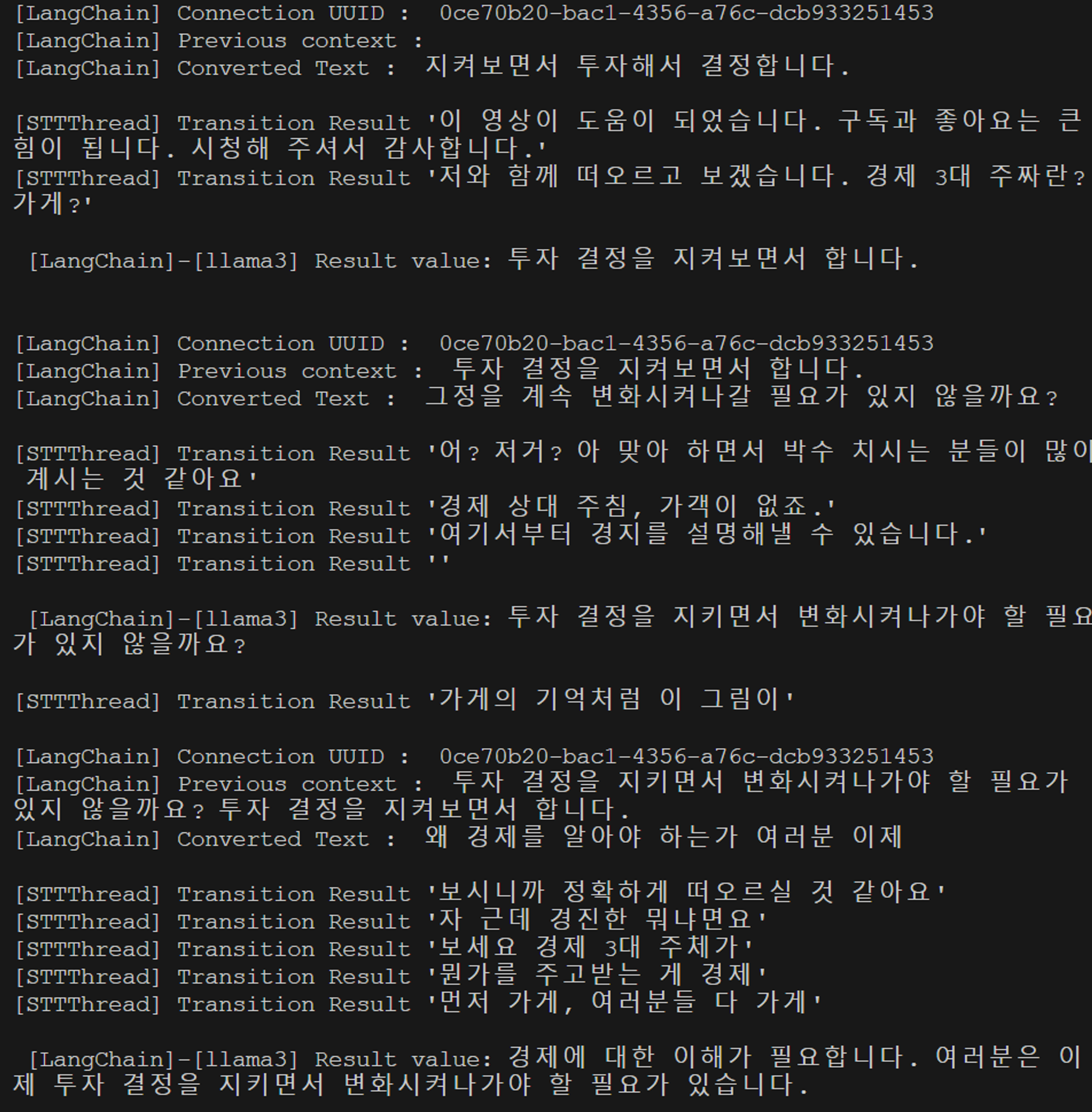
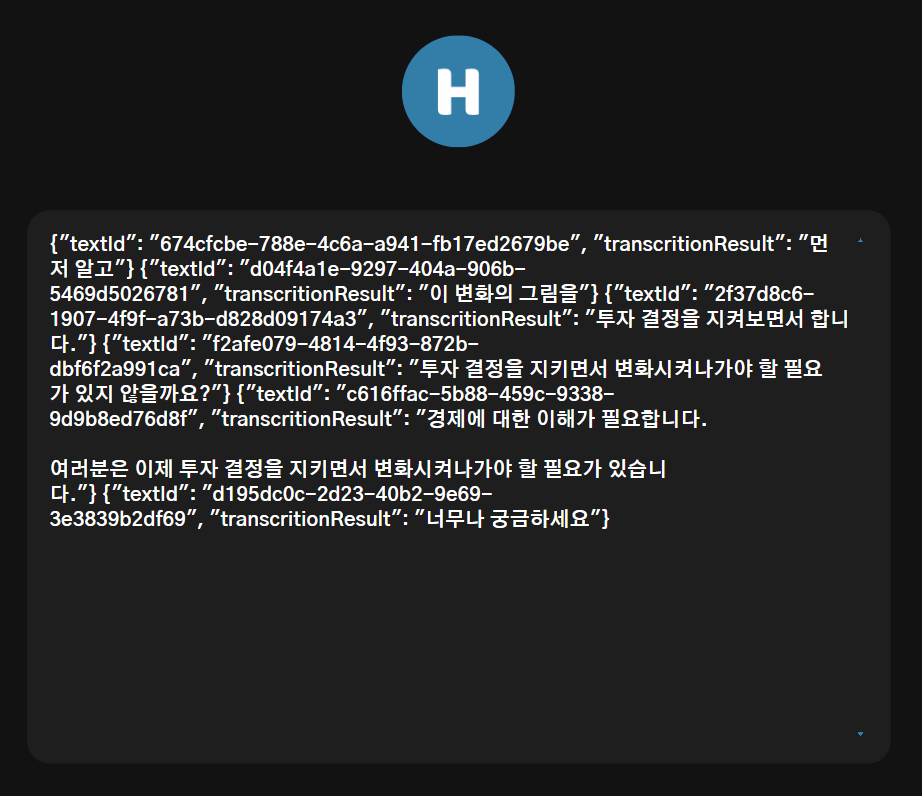 위와 같이 모든 프로세스의 결과가 정상적으로 전달되는 것을 확인할 수 있었다.
위와 같이 모든 프로세스의 결과가 정상적으로 전달되는 것을 확인할 수 있었다.
MongoDB Update
Vue main.js
const socket = io(socketUrl, {
path: '/socket.io',
transports: ['websocket'],
extraHeaders: {
'Sec-WebSocket-Extensions': 'permessage-deflate; client_max_window_bits'
},
reconnection: true,
reconnectionDelay: 5000,
reconnectionAttempts: Infinity
});
socket.on('connect', () => {
const lectureId = '668cceb8ebef2b4462de0fb5';
socket.emit('lectureId', lectureId);
});FastAPI의 인공지능 처리 결과를 MongoDB에 저장하기 위하여 위와 같이 Vue의 Socketio 연결 이후 lectureId를 전달하였다.
WebRTCProxy.java
@Autowired
public WebRTCProxy(SocketIOServer server, ConfigUtil configUtil) {
this.server = server;
this.FastAPIEndpoint = configUtil.getProperty("FAST_API_ENDPOINT");
this.namespace = server.addNamespace("/webrtc");
this.namespace.addConnectListener(onConnected());
this.namespace.addDisconnectListener(onDisconnected());
this.namespace.addEventListener("transcription", String.class, audioListener());
this.namespace.addEventListener("lectureId", String.class, lectureIdListener());
this.audioConverter = new AudioConverter();
}
...
// WebSocket
private void connectFastAPI(Timer timer, SocketIOClient client){
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
try {
if(fastAPIWebSocket == null || fastAPIWebSocket.isClosed()) {
fastAPIWebSocket = new WebSocketUtil(
lectureDAO,
new URI(FastAPIEndpoint + "/ws"),
new Draft_6455(),
client,
lectureId
);
fastAPIWebSocket.connectBlocking();
fastAPIWebSocket.send(String.valueOf(UUID.randomUUID()));
}
} catch (Exception e) {
// Handle connection exceptions
log.info("[WebRTCProxy]-[connectFastAPI] WebSocket Connection Failed");
}
}
}, 0, 60);
}
...
private DataListener<String> lectureIdListener() {
return (client, lectureId, ackSender) -> {
log.info("[WebRTCProxy]-[Socketio]-[{}] Received LectureID: {}", client.getSessionId().toString(), lectureId);
this.lectureId = lectureId;
};
}또한 이후 기존의 WebRTCProxy에서 Socketio 연결이 Establish되고 WebSocket 연결을 Open할 때 전달받은 LectureID를 생성자를 통해 WebSocketUtil로 전달하였다.
WebSocketUtil.java
public class WebSocketUtil extends WebSocketClient {
private final LectureDAO lectureDAO;
private final SocketIOClient socketIOClient;
private final String lectureId;
public WebSocketUtil(LectureDAO lectureDAO, URI serverUri, Draft protocolDraft, SocketIOClient socketIOClient, String lectureId) {
super(serverUri, protocolDraft);
this.lectureDAO = lectureDAO;
this.socketIOClient = socketIOClient;
this.lectureId = lectureId;
}
@Override
public void onMessage(String message) {
log.info("[WebSocketUtil]-[onMessage] Received Messegae {}", message);
try {
JsonObject jsonObject = JsonParser.parseString(message).getAsJsonObject();
String transcritionResult = jsonObject.get("transcritionResult").getAsString();
socketIOClient.sendEvent("transitionResult", transcritionResult);
lectureDAO.putScript(lectureId, transcritionResult);
} catch (JsonSyntaxException e) {
log.error("[WebSocketUtil]-[onMessage] Failed to parse JSON message: {}", message, e);
} catch (Exception e) {
log.error("[WebSocketUtil]-[onMessage] Exception : {}", message, e);
}
}
...또한 WebSocketUtil에서 FastAPI로부터 메세지를 전달받았을 때 JSON 형태의 데이터에서 transcritionResult만 가져와 이를 Socketio 클라이언트로 전달하고 lectureDAO의 putScript를 통해 MongoDB에 값을 업데이트할 수 있도록 하였다.

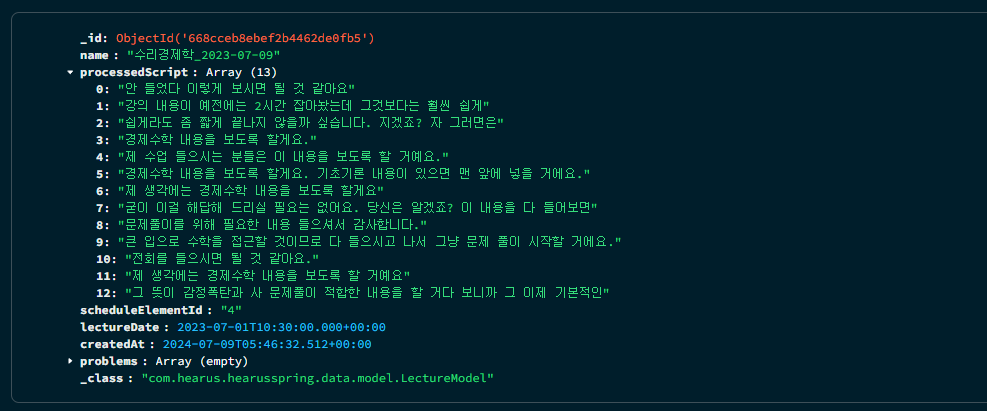
Problem Creation
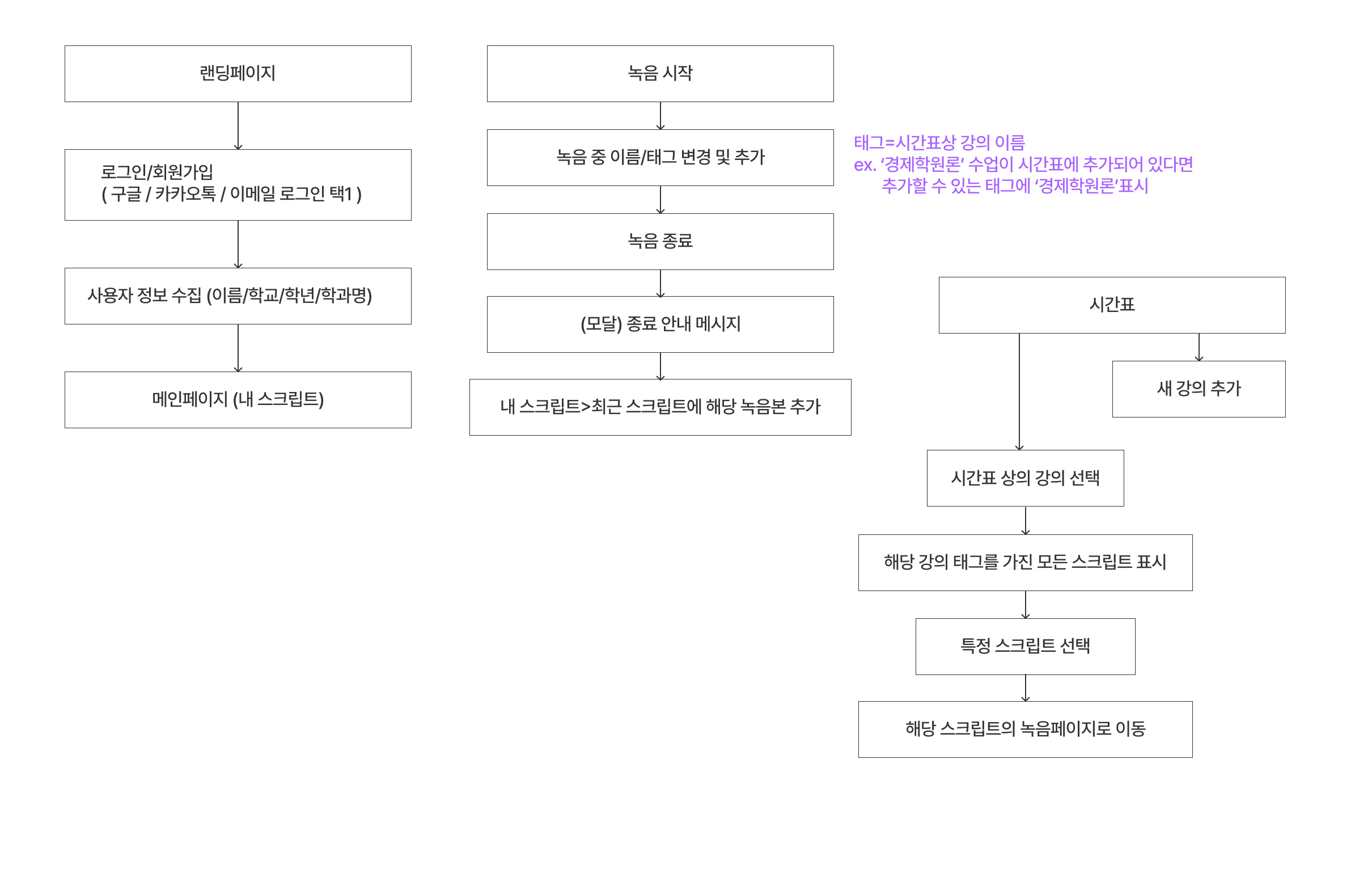 FE, BE, 디자인 파트의 기획 내용을 이해간에 차이가 발생하여 주중회의 이후 위와 같이 부가적으로 핵심 기능에 대한 플로우를 확정한 이후 개발을 진행하였다.
FE, BE, 디자인 파트의 기획 내용을 이해간에 차이가 발생하여 주중회의 이후 위와 같이 부가적으로 핵심 기능에 대한 플로우를 확정한 이후 개발을 진행하였다.
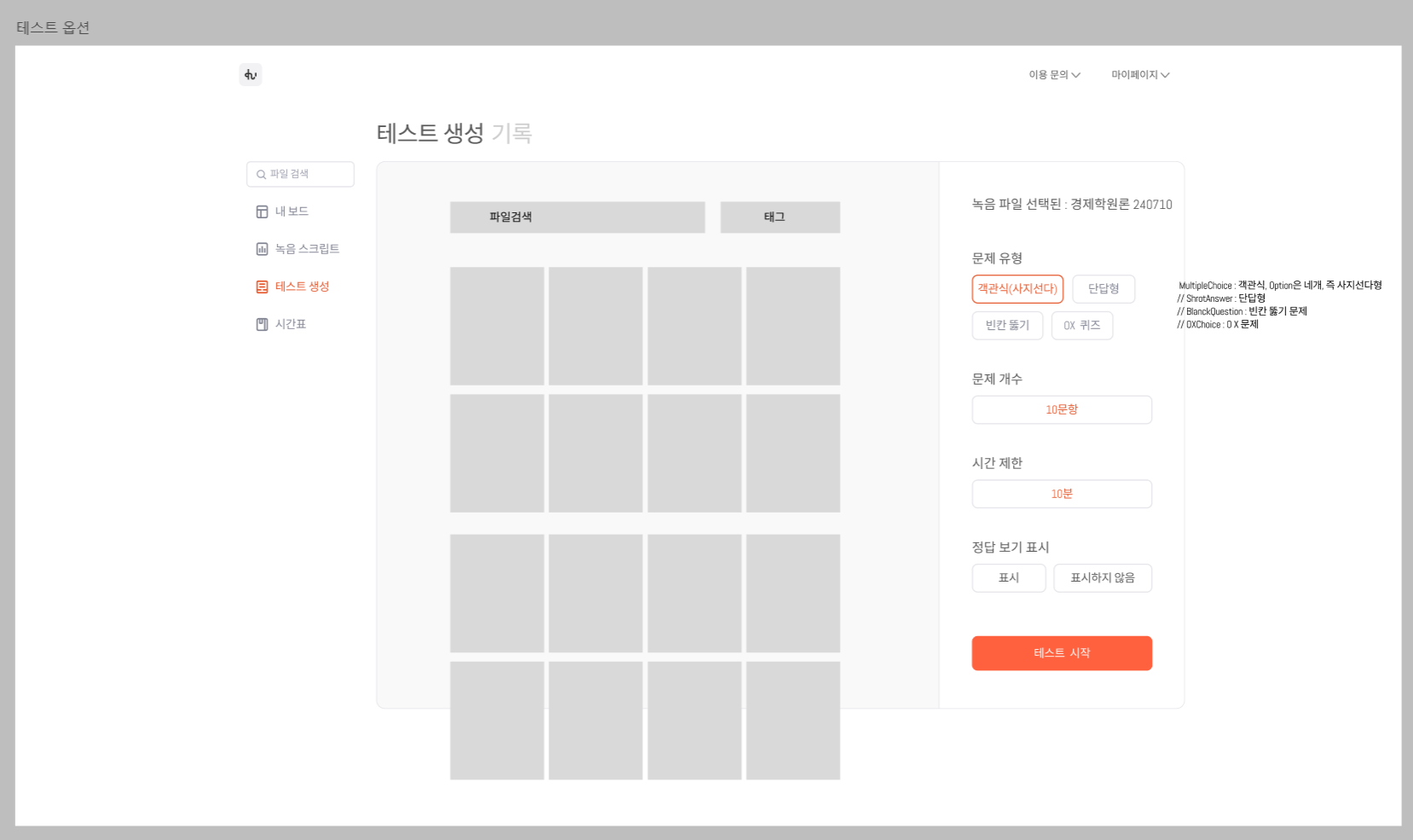 또한 위와 같이 디자인 초안에 기반하여 문제 생성과 관련된 기능을 설계하였으며
또한 위와 같이 디자인 초안에 기반하여 문제 생성과 관련된 기능을 설계하였으며
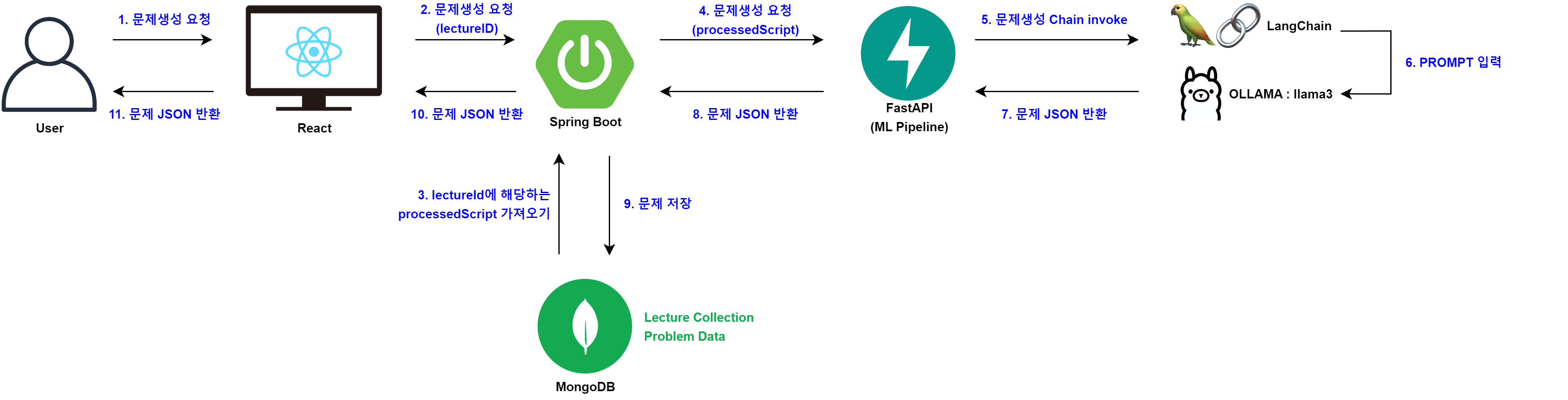 위 흐름도와 같이 LangChain에서 LLama를 통해 문제를 생성할 수 있도록 하였다.
위 흐름도와 같이 LangChain에서 LLama를 통해 문제를 생성할 수 있도록 하였다.
{script}
위 스크립트는 대한민국의 대학교 수준의 {subject}강의 내용인데
이때 위 스크립트에 기반하여 {problem_num} 개의 문제를 JSON 형식으로 아래 조건에 맞추어서 생성해주세요.
1. 문제의 Type은 아래와 같이 총 4개만 존재합니다.
MultipleChoice : 객관식, Option은 네개, 즉 사지선다형
ShrotAnswer : 단답형
BlanckQuestion : 빈칸 뚫기 문제
OXChoice : O X 문제
2. 주어진 스크립트에서 시험에 나올 수 있는, 중요한 부분에 대한 문제를 생성해주세요.
3. 추가적인 설명 없이 JSON 결과만 제공해주세요.
4. 문제 JSON은 아래와 같은 형태여야만 합니다.
[
{
"type": "",
"direction": "",
"options": [
"",
"",
"",
""
],
"answer": ""
},
{
// 다음 문제
},
// {problem_num} 개의 문제 JSON 배열
]
아래는 각 JSON의 요소들에 대한 설명입니다. 아래의 설명에 무조건 맞추어서 생성해주세요.
type : 문제 Type 4개 중에 1개
direction : 문제 질문
direction : type이 BlanckQuestion인 경우에는 direction에 ___로 빈칸을 뚫어야 한다
direction : type이 OXChoice인 경우에는 direction이 질문 형태가 아닌 서술 형태로 참 또는 거짓일 수 있어야 한다
options: MultipleChoice인 경우에만 보기 4개
options: MultipleChoice이 아닌 다른 Type이면 빈 배열
options : OXChoice인 경우에도 빈 배열
answer : 각 문제들에 대한 정답
answer : MultipleChoice인 경우 options들 중 정답 번호
answer : ShrotAnswer의 경우 direction에 대한 정답
answer : BlanckQuestion인 경우 direction에 뚫린 빈칸
answer : OXChoice인 경우 X인 경우 answer는 0, O인 경우 answer는 1
5. 이 중에서 {problem_types}에 해당하는 종류의 문제만 생성해주세요
6. 각 문제의 Type에 맞는 JSON 요소들을 생성해주세요
7. 항상 모든 문제에 대한 direction과 answer는 꼭 생성해주세요
8. 문제는 모두 한국어로 생성해주세요문제 생성을 위해 초기에 임의로 작성한 프롬프트는 위와 같다.
문제 유형은 MultipleChoice, ShrotAnswer, BlanckQuestion,OXChoice으로 총 네개로 구성되며 청각장애 학우 사용자가 단순히 실시간 음성인식을 통해 변환된 스크립트를 읽는 것 뿐 아니라 해당 스크립트에 기반하여 생성된 문제를 풀이하는 것을 통해 비장애 학우와의 배움의 격차를 해소하는 것을 목표로 하였다
 실제 LangChain에 적용시키기 이전 Console상의 Ollama를 통해 해당 프롬프트가 올바른 결과를 내는지 테스트하였고
실제 LangChain에 적용시키기 이전 Console상의 Ollama를 통해 해당 프롬프트가 올바른 결과를 내는지 테스트하였고
 위와 같이 의도했던 바와 같이 결과를 산출해내는 것을 볼 수 있었다.
위와 같이 의도했던 바와 같이 결과를 산출해내는 것을 볼 수 있었다.
langchain.py
async def generate_problems(script, subject, problem_num, problem_types):
print("\n[LangChain]-[generate_problems] Subject :", subject)
print("[LangChain]-[generate_problems] Problem_num :", problem_num)
print("[LangChain]-[generate_problems] Problem Types : ", problem_types, "\n")
prompt = ChatPromptTemplate.from_template("""
...
""")
chain = (
prompt
| llm
| StrOutputParser()
)
problem_result = await asyncio.to_thread(
chain.invoke, {
"script" : script,
"subject" : subject,
"problem_num" : problem_num,
"problem_types" : problem_types
})
json_result = parse_JSON(problem_result, True)
if not json_result:
return None
return json_result이후 위와 같이 LangChain을 구축하였다.
script와 같이 프롬프트가 생성될 때 필요한 데이터들의 경우 API를 통해 요청된 Body에서 추출할 수 있도록 구조화 하였고
def parse_JSON(llm_response, is_array=False):
json_pattern = re.compile(r'{[^{}]*?}')
# LLM 응답에서 JSON 값 찾기
json_match = json_pattern.findall(llm_response)
if json_match and is_array:
json_array = []
for string in json_match:
try:
json_array.append(json.loads(string))
except json.JSONDecodeError as e:
print(f"Error parsing JSON: {str(e)}")
return json_array
elif json_match:
json_str = json_match[-1]
try:
json_data = json.loads(json_str)
return json_data
except json.JSONDecodeError:
print("[LangChain]-[parse_JSON] Invalid JSON format")
return None
else:
print("[LangChain]-[parse_JSON] No JSON found in the LLM response")
return None문제 생성 프롬프트의 경우 JSON 배열로 생성되기 때문에 parse_JSON의 is_array 매개변수를 통해 여러 JSON 데이터들을 처리할 수 있도록 하였다.
또한 신뢰성이 높지 않기에 변환 도중의 예외처리를 해주었다.
main.py
class problemReq(BaseModel):
script: str
subject : str
problem_num : int
problem_types : str
@app.post("/generateProblems")
async def generate_problems(problem_req: problemReq):
data = problem_req
script = data.script
subject = data.subject
problem_num = data.problem_num
problem_types = data.problem_types
generate_result = await asyncio.create_task(langchain.generate_problems(
script,
subject,
problem_num,
problem_types
))
return generate_result위와 같이 problemReq Class를 생성하여 해당 포맷에 맞추어 POST Body를 요청할 수 있게 하였고 요청된 데이터를 받아온 이후에는 각각 generate_problems 메소드의 파라미터로 전달해주었다.
또한 이 과정에서도 asyncio.create_task를 통해 비동기적으로 이를 처리하였다.
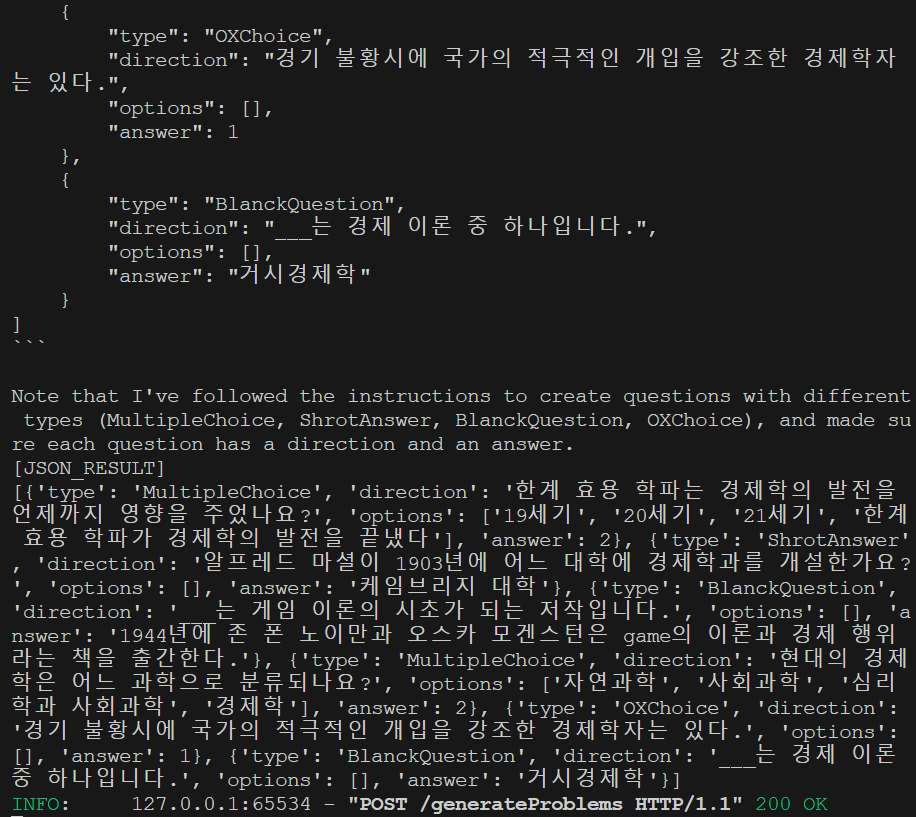 위와 같이 LangChain에서 정상적으로 결과를 도출해내는 것을 볼 수 있었고
위와 같이 LangChain에서 정상적으로 결과를 도출해내는 것을 볼 수 있었고
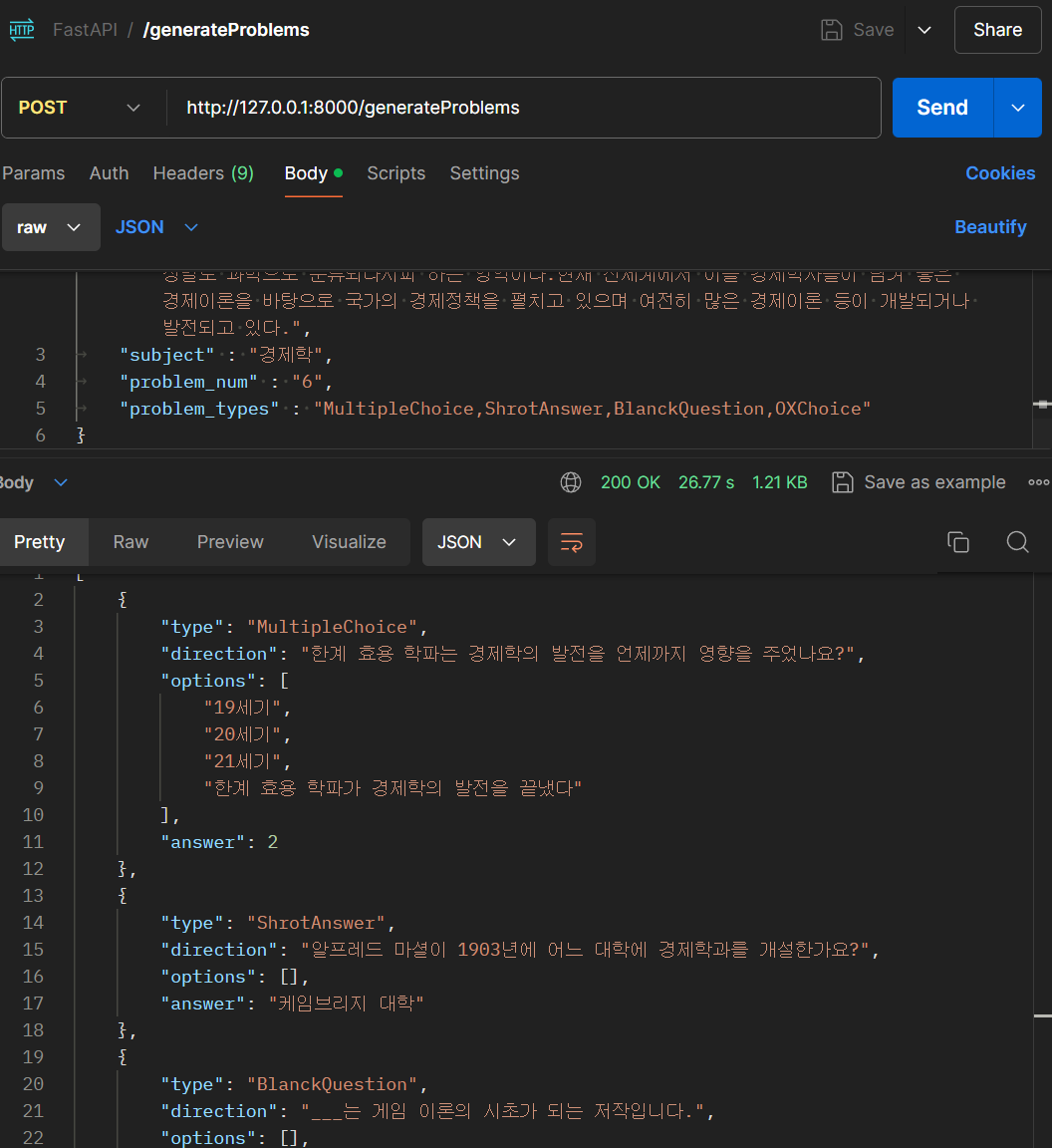 해당 JSON 배열을 담은 응답이 정상적으로 전달되는 것도 볼 수 있었다.
해당 JSON 배열을 담은 응답이 정상적으로 전달되는 것도 볼 수 있었다.
API Implementation
let scriptLines = [
"현대 주류경제학은 자원 등 경제적 가치가 있는 대상이 희소하고 이를 선택할 때에는 기회 비용이 발생한다는 것을 기본적인 전제로 한다.",
...
];
scriptLines.forEach(line => {
db.LectureCollection.updateOne(
{ "_id": ObjectId("668cceb8ebef2b4462de0fb5") },
{ $push: { "processedScript": line } }
);
});React <> Spring <> FastAPI 세 개의 프레임워크가 모두 연결되어 동작할 수 있는 API를 만들기 위해, 기존의 script에 해당하는 데이터를 MongoDB에 업데이트하는 쿼리문을 작성하고
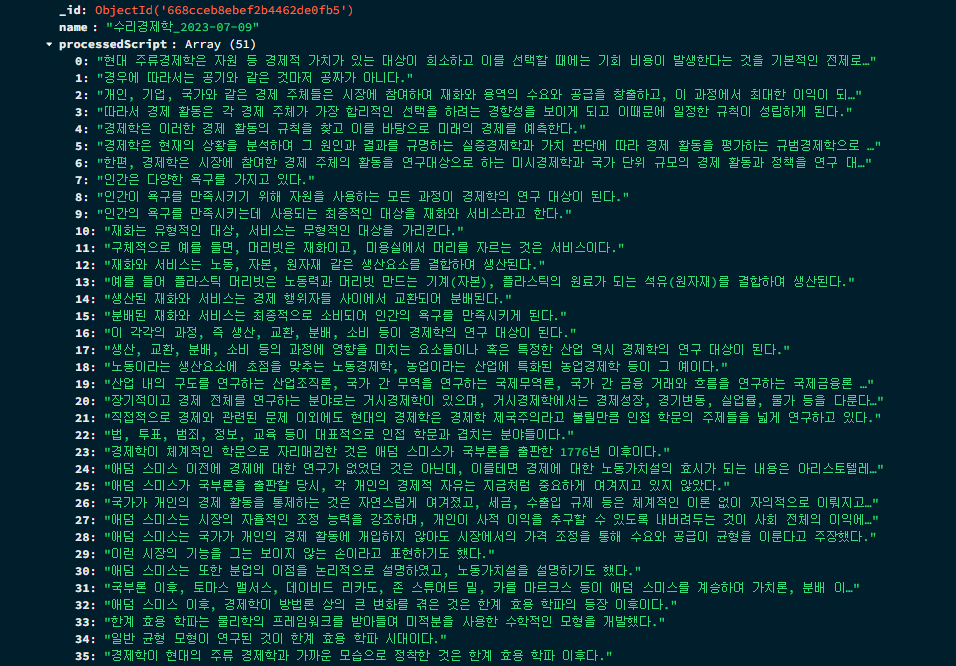 위와 같이 해당 데이터를 MongoDB의 LectureModel에 업데이트 해주었다.
위와 같이 해당 데이터를 MongoDB의 LectureModel에 업데이트 해주었다.
ProblemReqDTO
@Getter
@Setter
public class ProblemReqDTO {
private String lectureId;
private String script;
private String subject;
private int problem_num;
private String problem_types;
}Spring에서 또한 React로부터의 Req body를 다루고 FastAPI로의 Req body를 효율적으로 구성하기 위해 위와 같이 ProblemReqDTO를 생성하였다.
LectureController.java
...
@PostMapping(value="/generateProblems")
public DeferredResult<ResponseEntity<CommonResponse>> generateProblems(@Valid @RequestBody ProblemReqDTO requestBody){
log.info("[LectureController]-[generateProblem] API Call");
String fastAPIEndpoint = configUtil.getProperty("FAST_API_ENDPOINT");
// Timeout 시간을 3분으로 설정
long timeoutInMillis = 3 * 60 * 1000;
DeferredResult<ResponseEntity<CommonResponse>> deferredResult = new DeferredResult<>(timeoutInMillis);
CompletableFuture.runAsync(() -> {
try{
// LectureId로 Model을 가져와 내부의 Script를 하나로 합친 후 requestBody에 적용
LectureModel lectureModel = (LectureModel) lectureService.getLecture(requestBody.getLectureId()).getObject();
requestBody.setScript(String.join(" ", lectureModel.getProcessedScript()));
String jsonBody = new ObjectMapper().writeValueAsString(requestBody);
// FastAPI 비동기 요청 보내기
RestTemplate restTemplate = new RestTemplate();
// UTF-8 인코딩을 사용하는 StringHttpMessageConverter 설정
StringHttpMessageConverter converter = new StringHttpMessageConverter(StandardCharsets.UTF_8);
converter.setWriteAcceptCharset(false);
restTemplate.getMessageConverters().add(0, converter);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<String> entity = new HttpEntity<>(jsonBody, headers);
ResponseEntity<String> result = restTemplate.postForEntity(
fastAPIEndpoint + "/generateProblems",
entity,
String.class
);
if (result.getStatusCode() == HttpStatus.OK) {
// result.getBody()에서 JSON 문자열 추출
String responseBody = result.getBody();
System.out.println(responseBody);
// JSON 문자열을 Map으로 파싱
ObjectMapper objectMapper = new ObjectMapper();
List<Map<String, Object>> objectList = objectMapper.readValue(responseBody, new TypeReference<List<Map<String, Object>>>() {});
response = new CommonResponse(true, HttpStatus.OK, "Problem Created", objectList);
}
else
response = new CommonResponse(false, (HttpStatus) result.getStatusCode(), "Problem Creation Failed");
} catch (Exception e) {
log.error("[LectureController]-[generateProblem] {}", e.getStackTrace());
response = new CommonResponse(false, HttpStatus.INTERNAL_SERVER_ERROR, "Problem Creation Failed with Internal Server Error");
} finally {
log.info("[LectureController]-[generateProblem] {}", response.getMsg());
deferredResult.setResult(ResponseEntity.status(response.getStatus()).body(response));
}
});
return deferredResult;
}이후 POST 방식의 generateProblems 메소드를 선언하였다.
해당 메소드는 FastAPI에서 문제 생성 프로세스가 현재 30초 ~ 1분 정도가 걸리는 만큼 Timeout시간을 별도로 설정해주었고 org.springframework.web.context.request 패키지에 속한DeferredResult 클래스 타입의 메소드로 설정하였다.
DeferredResult는 비동기 처리의 결과를 나중에 반환할 수 있도록 해주는 클래스로 서블릿 스레드를 차단하지 않고 비동기 작업을 수행할 수 있으며 비동기 작업이 완료되면 DeferredResult에 결과를 설정하고, Spring MVC에서 자동으로 응답을 반환한다.
또한 java.util.concurrent 패키지에 속한 CompletableFuture 클래스의 runAsync를 통해 전체 작업을 비동기적으로 실행하였다.
CompletableFuture는 Java 8에서 도입된 클래스로, 비동기 작업의 결과를 표현하고 조작할 수 있는 기능을 제공하고 비동기 작업의 결과를 기다리지 않고 다른 작업을 수행할 수 있다.
더 나아가 콜백 함수를 등록하여 비동기 작업의 완료 시점에 추가 작업을 수행할 수 있고 여러 비동기 작업을 조합하고 병렬로 실행할 수 있는 기능을 제공한다.
이때 lectureId를 FE로부터 받아와 ID에 해당하는 LectureModel을 받아온 뒤 해당 Model 내의 processedScript를 하나의 String으로 join하여 requestBody의 script에 set 해주었다.
이후에는 UTF-8 인코딩을 사용하는 StringHttpMessageConverter를 설정하고 해당 요청에 대한 Response에서 JSON 배열을 Map으로 파싱하여 FE에 응답해줄 수 있게 하였다.
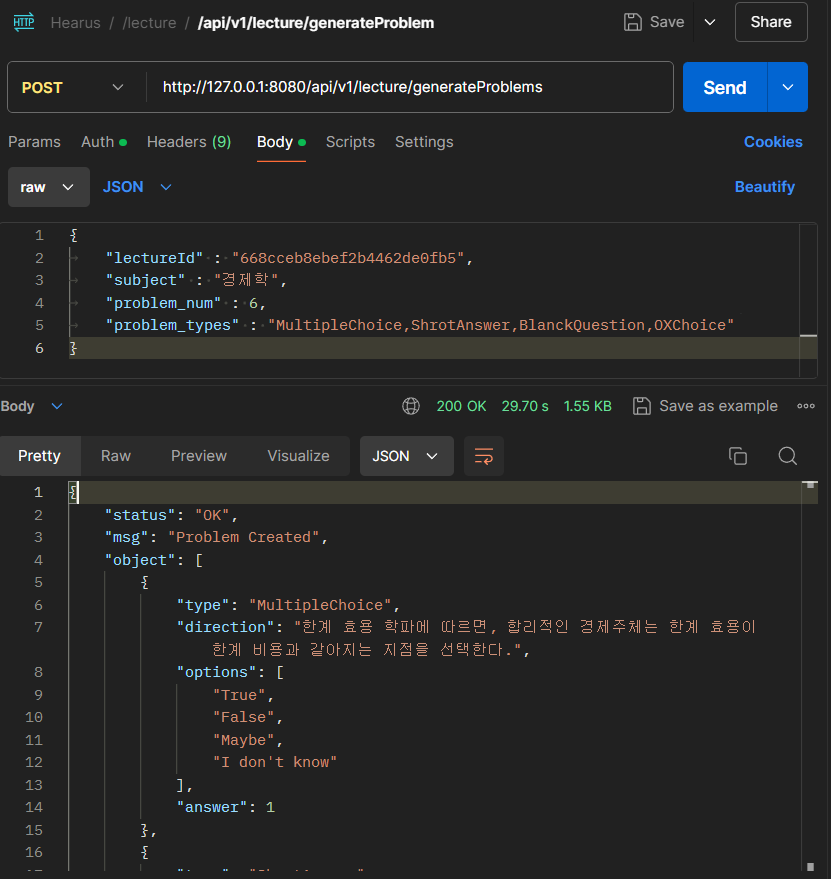 최종적으로 위와 같은 요청에 대해 정상적으로 응답이 오는 것을 확인할 수 있었다.
최종적으로 위와 같은 요청에 대해 정상적으로 응답이 오는 것을 확인할 수 있었다.
Vercel TEST FE
.env
VUE_APP_BACKEND_HOST=http://localhost:8080
VUE_APP_SOCKETIO_HOST=http://localhost:9092/webrtc이후 실시간 음성인식 로직을 구현하였던 Vercel TEST FE에서 위 기능을 구현하고 테스트하기 위해 환경변수를 먼저 설정해주었다.
QuestionPage.vue
<script src='@/scripts/questionScript.js'></script>
<template>
<div class="question-page">
<div class="content-container">
<div class="input-container" v-if="!isLoading && !isInput">
<textarea v-model="accessToken" placeholder="Access Token 입력" class="json-input"></textarea>
<textarea v-model="jsonData" placeholder="JSON Body 입력" class="json-input"></textarea>
<button @click="generateProblems" class="generate-btn">문제 생성하기</button>
</div>
<div v-if="isLoading" class="loading-screen">
<image :src="loadingImage" alt="Loading" style="width: 200px; height: 200px;"/>
<p>문제를 생성하고 있습니다. 잠시만 기다려주세요{{ loadingDots }}</p>
</div>
<div v-if="!isLoading && isInput">
<div v-for="(question, index) in questions" :key="index" class="question">
<div v-if="question.type === 'MultipleChoice'">
<div class="question-title">{{ index + 1 }}. <span class="direction">{{ question.direction }}</span></div>
<div v-for="(option, optionIndex) in question.options" :key="optionIndex" class="option">
<input type="radio" :id="`question-${index}-option-${optionIndex}`" :value="optionIndex" v-model="question.selectedOption">
<label :for="`question-${index}-option-${optionIndex}`">{{ option }}</label>
</div>
</div>
<div v-if="question.type === 'ShrotAnswer'">
<div class="question-title">{{ index + 1 }}. <span class="direction">{{ question.direction }}</span></div>
<input type="text" v-model="question.answer" class="answer-input">
</div>
<div v-if="question.type === 'BlanckQuestion'">
<div class="question-title">{{ index + 1 }}. <span class="direction">{{ question.direction }}</span></div>
<input type="text" v-model="question.answer" class="answer-input">
</div>
<div v-if="question.type === 'OXChoice'">
<div class="question-title">{{ index + 1 }}. <span class="direction">{{ question.direction }}</span></div>
<div class="ox-options">
<input type="radio" :id="`question-${index}-option-0`" value="0" v-model="question.selectedOption">
<label :for="`question-${index}-option-0`">O</label>
<input type="radio" :id="`question-${index}-option-1`" value="1" v-model="question.selectedOption">
<label :for="`question-${index}-option-1`">X</label>
</div>
</div>
</div>
</div>
<button v-if="isInput" class="submit-btn">제출</button>
</div>
</div>
</template>이후 위와 같이 QuestionPage에서 데이터 입력 전, 로딩 중, 문제 생성 완료 조건에 대한 페이지를 구성하였으며
QuestionScript.js
import '@/styles/questionStyle.css';
import axios from 'axios';
export default {
name: 'QuestionPage',
data() {
return {
loadingImage: require('@/assets/loading.gif'),
isLoading: false,
loadingDots: '.',
isInput: false,
loadingInterval: null,
accessToken: '',
jsonData: '',
questions: [],
};
},
methods: {
async generateProblems() {
try {
this.isLoading = true;
this.startLoadingAnimation();
const response = await axios.post(`${process.env.VUE_APP_BACKEND_HOST}/api/v1/lecture/generateProblems`, JSON.parse(this.jsonData), {
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${this.accessToken}`, // Authorization 헤더 추가
},
timeout: 180000, // 3분 (180000ms)
});
this.questions = response.data.object;
this.isInput = true;
} catch (error) {
console.error('문제 생성 오류:', error);
} finally {
this.isLoading = false;
this.stopLoadingAnimation();
}
},
startLoadingAnimation() {
let count = 0;
const maxCount = 3;
this.loadingInterval = setInterval(() => {
count = (count + 1) % (maxCount + 1);
this.loadingDots = '.'.repeat(count);
console.log(count);
}, 1000);
},
stopLoadingAnimation() {
clearInterval(this.loadingInterval);
this.loadingDots = '.';
},
},
};위 QuestionScript에서 axios로 요청하고 문제를 받아와 로컬 데이터에 저장하는 스크립트를 작성하였다.
 위와 같이 Token과 요청 JSON을 입력하면 문제를 정상적으로 생성하고 받아오는 것을 볼 수 있다.
위와 같이 Token과 요청 JSON을 입력하면 문제를 정상적으로 생성하고 받아오는 것을 볼 수 있다.
 신뢰성이 낮은 결과를 보여주기도 하지만 이는 추후 더 많은 GPU를 확보할 수 있는 인프라를 구축한 이후 성능이 좋은 모델을 활용하여 보완할 계획이다.
신뢰성이 낮은 결과를 보여주기도 하지만 이는 추후 더 많은 GPU를 확보할 수 있는 인프라를 구축한 이후 성능이 좋은 모델을 활용하여 보완할 계획이다.
References
https://www.ciokorea.com/column/305341#csidx973f1264e8a2e758d10e50c3f1541b5
https://bigwaveai.tistory.com/76
https://www.samsungsds.com/kr/insights/what-is-langchain.html
https://brunch.co.kr/@ywkim36/146
https://brunch.co.kr/@ywkim36/147
https://teddylee777.github.io/langchain/langchain-tutorial-02/
https://velog.io/@kwon0koang/%EB%A1%9C%EC%BB%AC%EC%97%90%EC%84%9C-Llama3-%EB%8F%8C%EB%A6%AC%EA%B8%B0
https://velog.io/@pcoeid/OpenAI-LangChain%EC%9D%84-%ED%86%B5%ED%95%B4-FastAPIrest-api-%EC%B1%97%EB%B4%87-%EC%84%9C%EB%B2%84%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0
https://bigwaveai.tistory.com/76
