안녕하세요! 기계번역 이야기하는 Judy 입니다 🙋🏻♀️
아쉽게도 이번에 마지막으로 기계번역 이야기를 들려드리게 되었어요 🥲
당초 시리즈에서 목표로 한 각각의 주제에 대해 제가 아는 지식을 대부분 풀어냈고
결정적으로 본의 아니게(?) 이제는 업무상 기계번역 이외의 도메인을 다룰 예정이고
당장 NLP 나 AI 보다도 백엔드 개발에 전념하게 되어서요... 😅
지난 시리즈에서 모델 학습까지 다루었으니 이번에는 학습 검증 방법 혹은 다양한 기계번역 품질 평가 지표를 다뤄볼까 생각했는데
사실 저도 연구나 현업에서 대부분 BLEU score 를 사용했기에 😂
마지막 글에서는 기계번역의 넓은 세계를 짧게 안내하고 🌌
NMT 다음으로 제가 많이 다뤘던 APE 에 대해 소개하며 시리즈를 끝맺으려 합니다.
기계번역은 1:1 번역만 한다?
정답은 NO!
사실 제가 대학원에서 실험을 하고 논문을 쓸 때까지만 해도
저는 기계번역이란 하나의 언어로 쓰여진 단어 또는 문장을 다른 언어로 번역해 주는 것,
즉 1:1 번역 작업인 줄로만 알았어요.
하지만 기계번역 서비스 회사에 취업하여 1:1 번역 이외의 서비스를 접하고,
또 관련된 논문을 찾아 읽다 보니 기계번역이라는 큰 주제 안에 다양한 task 가 있다는 사실을 알게 되었습니다.
WMT 를 예로 들어 볼까요?
WMT 는 EMNLP 학회의 워크샵으로, 'Workshop on Machine Translation' 의 약자입니다.
이름 그대로 기계번역에 해당하는 큰 task 들을 다루는 워크샵인데요,
각각의 task 는 매년 새로 생겨나는 것도, 유지되는 것도, 없어지는 것도 있습니다.
가장 최근인 2022년 12월에 열린 WMT 의 task 는 다음과 같습니다.

1:1 번역도 news, biomedical 등 특정 도메인에 특화된 번역으로 세분화되고
언어쌍(데이터셋) 이 적은 언어를 번역하는 Low resource,
품질을 평가하기 위한 Metrics, Quality estimation(QE),
번역문 사후 교정 작업인 Automatic post-editing (APE) 까지
번역 작업에는 다양한 task 가 있다는 점을 알 수 있지요.
이 글에서는 제가 직접 경험한 Automatic Post-Editing 에 대해 간략하게 소개하겠습니다.
Automatic Post-Editing (APE)
'기계번역에는 다양한 하위분야가 존재하며 APE(Automatic Post Editing)이란 기계번역 시스템의 결과물을 교정하여 더 나은 번역문을 만들어내는 기계번역의 하위분야이다. 즉 기계번역 시스템이 생성한 번역문에 포함되어 있는 오류를 수정하여 교정문을 만드는 과정을 의미한다. 기계번역 모델을 변경하는 것이 아닌 기계번역 시스템의 결과 문장을 교정하여 번역품질을 높이는 연구분야이다. 2015년부터 WMT 공동 캠페인 과제로 선정되었으며 성능 평가는 TER(Translation Error Rate)을 이용한다.'
APE 리뷰 논문의 초록에서 발췌한 APE 소개입니다.
조금만 더 자세하게 설명해 볼까요?
Automatic Post-Editing 은 한국어로 '사후 교정' 입니다.
간단한 예시를 들어 보겠습니다.
한국어로 '정의가 없다' 라는 문장을 Papago 를 이용해 영어로 번역하면
'Have no justice' 로 번역됩니다.
보편적으로는 맞는 번역이지만, 만약 주 사용자가 저와 같은 연구/기술직 종사자이거나
일반적인 또는 인문/사회적인 번역이 아니라 과학기술 분야에 특화된 도메인 전문 번역 모델을 만들어야 할 경우에는
문장이 'Have no definition' 으로 번역되어야겠지요?
이 때, '정의가 없다 : Have no definition' 과 같이
1:1 문장 쌍이 포함된 데이터셋을 이용해 새로 번역 모델을 학습시키는 방법도 있겠지만
새로 데이터셋을 구축하고 모델을 학습하는 데에는 많은 시간과 노력이 드는데다
이미 '정의가 없다 : Have no justice' 로 번역하는 모델이 있다면
이 모델을 그대로 이용하되, 번역 결과만 살짝 교정해 주면 더욱 효율적이겠죠?
Dataset & Model
지금까지 NMT 는 1:1 번역이므로 Source : Target 언어 문장 쌍을 이용하여 모델을 학습하였다면
APE 는 문장 쌍 한 종류를 추가로 이용합니다.
총 3개의 문장들이 하나의 쌍, 즉 triplet 을 이루지요.
- Source
- MT (Machine Translate 즉 Target 언어로 기계번역한 결과)
- Target
APE 모델을 가장 쉽게 만들기 위해서는 일반 NMT 모델을 만들 때와 같이 Encoder-Decoder 모델을 동일하게 이용할 수 있는데요,
Encoder 에는 Source 와 MT를, Decoder 에는 Target 을 넣어 주면 됩니다.
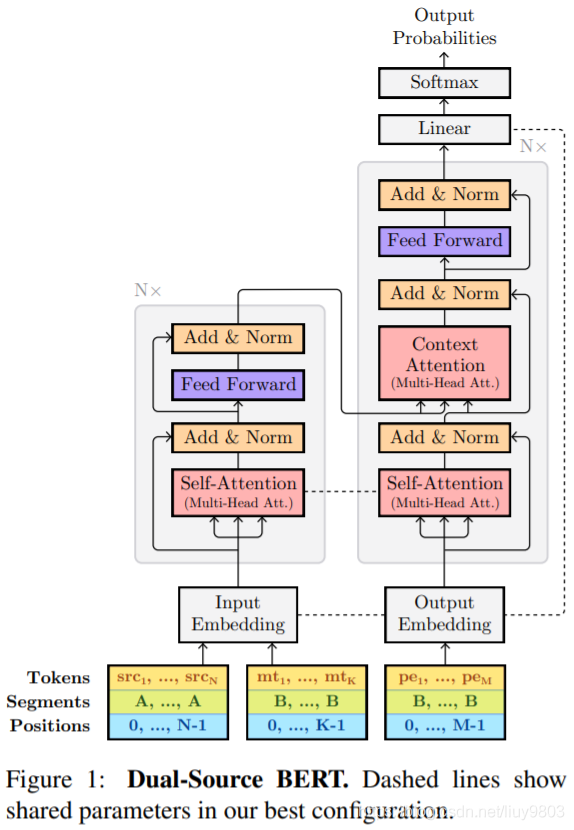
https://aclanthology.org/P19-1292/
Evaluation
마지막으로 APE 의 평가 지표로는 TER(Translation Error Rate) 를 이용합니다.
TER은 번역문 내의 오류를 수정하기 위해서 총 몇 번의 교정이 더 필요한지를 정량화한 값 (=최소 편집 횟수) 으로,
BLEU score 와 다르게 점수가 낮을수록 성능이 좋습니다.
TER 점수를 계산하기 위해서는 Tercom 에서 제공하는 TER측정 도구를 활용할 수 있습니다.
http://www.cs.umd.edu/~snover/tercom/
Reference
기계번역 사후교정(Automatic Post Editing) 연구
https://koreascience.kr/article/JAKO202015762900573.pdf
전이학습 기반 기계번역 사후교정 모델 검증
https://scienceon.kisti.re.kr/commons/util/originalView.do?cn=JAKO202131452857728&oCn=JAKO202131452857728&dbt=JAKO&journal=NJOU00558830
