Abstract
DRT: 문학 번역을 위한 긴 사고 과정 기반 기계 번역 모델
- 추론 태스크의 긴 사고 과정(Long CoT)을 기계 번역에 적용한 DRT 모델 소개
- 직역이 어려운 문학 작품의 비유/은유 번역에 특화
- 3개 에이전트(번역가-조언자-평가자) 프레임워크로 반복 정제하여 Long CoT 번역 데이터 합성
- 합성된 수만 건 데이터로 Qwen2.5, Llama-3.1 기반 DRT 모델 훈련
- 기존 LLM 대비 우수한 번역 성능 달성
1 Introduction
- O1 등 LLM의 Long thought 성공을 MT에 적용하려는 DRT를 제안합니다.
- 문학 번역처럼 직역이 어려운 경우에 Long thought가 필요하다고 봅니다.
- 이를 위해 비유/은유 문장을 LLM으로 발굴합니다.
- Long thought 데이터 합성을 위해 Multi-Agent Framework를 개발했습니다.
- Multi-Agent는 Translator, Advisor, Evaluator가 반복적으로 번역을 개선합니다.
- 합성 데이터를 바탕으로 DRT를 학습시켰고, 바닐라/SFT 모델보다 우수함을 보였습니다.
- DRT는 LLM이 번역 중 '생각'하도록 학습됩니다.
2 DRT Data
이 섹션에서는 논문에서 제안하는 DRT(Deep Reasoning Translation) 모델 학습을 위한 데이터를 어떻게 수집하고 만들었는지 자세히 설명합니다.
2.1 Literature Book Mining
- Long thought가 필요한 문장을 찾기 위해 Project Gutenberg의 영문 문학 서적 약 400권을 사용했습니다.
- 길이 기준(10~100 단어)으로 577.6K 문장을 추출했습니다.
- Qwen2.5-72B를 사용하여 각 문장에 비유/은유가 있는지 (Q1) 판단했습니다.
- 비유/은유가 있다면, Qwen2.5-72B로 리터럴 번역 후 중국어 원어민이 이해하기 쉬운지 (Q2) 판단했습니다.
- Q1="yes" & Q2="no"인 문장만 Long thought에 적합한 것으로 선별했습니다.
- 이 과정을 통해 63K개의 예비 문장을 수집했습니다.
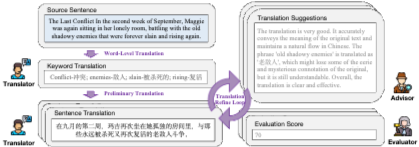
2.2 Multi-Agent Framework
- 각 선별된 문장(s)에 대해 Long thought 번역을 합성하기 위해 Multi-Agent Framework를 설계했습니다.
- 이 프레임워크는 Translator, Advisor, Evaluator 세 Agent (모두 Qwen2.5-72B 기반)로 구성됩니다.
- 합성 과정은 세 단계입니다:
- (1) Word-level Translation: Translator가 문장 내 키워드 를 식별하고 문맥 고려하여 번역 을 제공합니다.
- (2) Preliminary Translation: Translator가 소스 문장 s와 키워드 쌍 을 바탕으로 예비 문장 번역 을 생성합니다.
- (3) Translation Refine Loop: 반복 단계 k에서 Agent들이 협력하여 번역을 정제합니다.
- Advisor가 이전 번역 을 평가하고 피드백 을 제공합니다.
- Evaluator가 에 대해 점수 을 부여합니다.
- Translator가 , , 을 고려하여 새 번역 를 생성합니다.
- 루프는 점수 이 임계값에 도달하거나 최대 반복 횟수에 이르면 중단됩니다.
2.3 Long Thought Reformulation
- Multi-agent 협업 후, 원시 Long thought 과정 를 얻습니다.
- (수식 1)
- 점수 변화가 없는 단계()는 제거합니다.
- 유효한 단계만 남은 과정 를 얻습니다.
- (수식 2), 여기서 입니다.
- 남은 단계가 3개 미만()인 샘플은 폐기합니다.
- GPT-4o를 사용하여 를 자기 성찰(self-reflection) 형태로 재구성합니다.
- 최종 번역은 가장 높은 점수 를 받은 번역이며, 마지막 번역()이 아닐 수 있습니다.
- 최종적으로 총 22,264개의 Long thought MT 샘플을 얻었습니다.

2.4 Data Statistics and Data Analyses
- 총 22,264개의 합성된 Long thought MT 샘플을 수집했습니다.
- 데이터를 학습(19,264), 검증(1,000), 테스트(2,000) 세트로 분할했습니다.
- 데이터의 평균 thought 토큰 길이는 500+ 토큰으로, 긴 사고 과정을 보여줍니다.
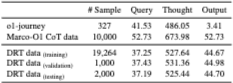
- Refinement Loop 단계는 3단계에서 8단계까지 분포하며, 3단계가 가장 많습니다 (73.22%).
-
Refinement가 진행될수록 수정량(Edit Distance)이 점진적으로 감소합니다.
-
Refinement 단계가 증가할수록 평균 평가 점수가 일반적으로 상승하며, 개선 효과를 보여줍니다.

2.5 Quality Analyses
- Evaluator Agent의 효과:
- 합성 과정에 사용된 Evaluator Agent(Qwen2.5-72B)의 신뢰성을 검증했습니다.
- 인간 평가와 비교하여 Evaluator Agent의 평가 정확도가 92.5%로 높았습니다.
- CometKiwi(56.0%)보다 훨씬 정확하며, GPT-4o Evaluator(93.5%)와 유사했습니다.
- 비용 효율성을 고려하여 Qwen2.5-72B를 Evaluator로 사용했습니다.
- 번역 품질:
- Evaluator Agent의 효과성과 최종 번역의 높은 평균 점수(약 90점)를 바탕으로 합성된 데이터의 번역 품질이 높다고 판단했습니다.
- Evaluator 기준에서 90점은 'Excellent translations'에 해당합니다.

3 Experiments
3.1 Experimental Setups
- 평가 지표:
- 전통적 지표: BLEU, CometKiwi, CometScore를 사용했습니다.
- LLM 기반 지표: GPT-4o를 사용한 Reference-Based (GRB) 및 Reference-Free (GRF) 평가를 도입했습니다.
- Evaluator Agent 점수(GEA)도 평가에 활용했습니다 (GPT-4o Evaluator 정확도 검증 기반).
- GRB, GRF, GEA는 비용 문제로 400개 샘플에 대해 평가했습니다.
- Backbone 모델:
- DRT의 백본으로 Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct를 사용했습니다.
- 구현 상세:
- Llama-Factory 툴킷으로 Instruct-tuning 했습니다.
- 8x NVIDIA A100 GPU (40G) 사용, DeepSpeed ZeRO-3 최적화를 적용했습니다.
- 추론 시 vLLM 툴킷으로 가속화했습니다.
- 결과는 3회 실행의 평균입니다.
3.2 Comparison Models
- Vanilla LLMs:
- DRT의 백본으로 사용된 기본 Instruct 모델들 (Llama-3.1, Qwen2.5)을 포함합니다.
- Marco-o1, QwQ, DeepSeek-R1 Distill 시리즈 등 다른 O1-like LLM들도 비교 대상으로 포함했습니다.
- SFT LLMs (w/o CoT):
- 저희 DRT 데이터의 소스 문장과 최종 번역 결과 쌍만 사용하여 Fine-tuning한 모델들입니다.
- Long thought 과정 없이 단순 SFT만 수행한 모델들로, DRT의 Long thought 학습 효과를 비교하기 위한 핵심 Baseline입니다.
- Llama-3.1-8B-SFT, Qwen2.5-7B-SFT, Qwen2.5-14B-SFT 모델이 해당됩니다.
네, 논문 3.3절 Main Results 부분을 최대한 간결하게 하이픈(-)으로 구분하여 요약해 드리겠습니다. 이 절은 모델들의 실제 실험 성능을 비교한 결과입니다.
3.3 Main Results
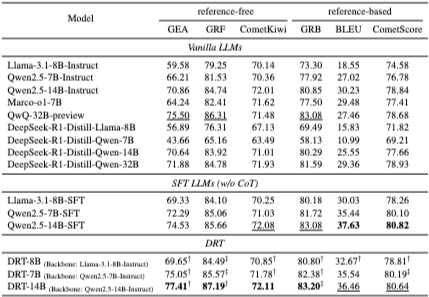
- SFT (w/o CoT) vs. Vanilla LLMs: 저희 합성 데이터의 소스-타겟 쌍으로만 학습한 SFT 모델이 Vanilla LLMs보다 모든 지표에서 유의미하게 우수했습니다. (합성 데이터 품질 우수성 입증)
- DRT vs. Vanilla LLMs: Long thought 데이터로 학습한 DRT 모델들도 해당 백본의 Vanilla LLMs보다 모든 지표에서 유의미하게 우수했습니다. (DRT 학습 효과 입증)
- DRT vs. SFT (w/o CoT): Llama-8B 및 Qwen-7B 백본에서는 DRT 모델이 해당 SFT 모델보다 모든 지표에서 더 나은 성능을 보였습니다. (Long CoT 학습의 명확한 기여)
- DRT-14B vs. Qwen2.5-14B-SFT: DRT-14B는 LLM 기반/Reference-free 지표 (GEA, GRF, CometKiwi, GRB)에서 우수했으나, BLEU 및 CometScore에서는 약간 낮은 성능을 보였습니다. (CoT 학습이 deeper quality에 집중함을 시사)
- DRT-14B는 QwQ-32B-preview 및 DeepSeek-R1-Distill-Qwen-32B 등 다른 대형 O1-like 모델들보다도 우수했습니다.
- DRT 모델은 상용 LLM (GPT-4o, o1-preview)과 비교해도 경쟁력 있는 성능을 보였습니다 (Appendix E).
3.4 Human Evaluation
- DRT-14B와 주요 Baseline 모델(Qwen2.5-14B-Instruct, QwQ-32B-Preview, Qwen2.5-14B-SFT)에 대해 인간 평가를 수행했습니다.
- 200개 샘플에 대해 세 명의 숙련된 평가자가 평가했습니다.
- 평가 기준은 Fluency (유창성), Semantic Accuracy (의미 정확성), Literary Quality (문학적 품질) 세 가지입니다.
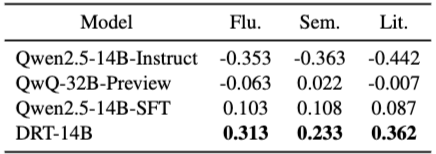
- Best-Worst Scaling 방법으로 평가 점수(-1 ~ 1)를 산출했습니다.
- DRT-14B는 모든 측면에서 다른 Baseline들보다 유의미하게 우수했습니다.
- 특히 Literary Quality 측면에서 가장 큰 우위를 보였습니다. (DRT가 문학적 뉘앙스를 잘 살림)
- 평가자 간 일치도(Fleiss’ Kappa)는 0.69 ~ 0.85로 Good agreement 수준이었습니다.
3.5 Inference Time Analysis
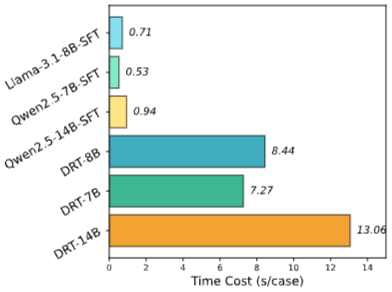
- vLLM을 사용하여 Test set에 대한 모델별 추론 시간을 측정했습니다.
- DRT 모델들의 평균 추론 시간은 SFT (w/o CoT) 모델들보다 현저히 높았습니다.
- DRT 모델들은 SFT 모델보다 약 11.9~13.9배 더 많은 시간이 소요되었습니다.
- 이는 DRT 모델이 최종 번역 외에 Long thought 과정을 추가로 생성해야 하기 때문입니다.
- 이 결과는 DRT 모델이 높은 실시간 응답성이 요구되는 시나리오에는 적합하지 않을 수 있음을 시사합니다.
3.6 Case Study
- Qwen2.5-14B-Instruct, QwQ-32B-Preview, Qwen2.5-14B-SFT, DRT-14B 모델들의 실제 문학 번역 사례를 제시하고 비교했습니다.

- DRT-14B의 번역이 Long thought 덕분에 중국어 관습에 더 잘 맞고 문학적 품질이 뛰어남을 보여줍니다.
- 다른 LLM들도 일부 좋은 번역을 보여주었지만, DRT-14B의 전반적인 품질이 우수했습니다.
- 사례 연구는 DRT가 Long thought를 통해 바닐라 LLM의 잠재된 문학 번역 능력을 활성화시킬 수 있음을 시사합니다.
4 Related Work
- O1-like LLMs:
- 최근 LLM들이 Long thought를 활용하여 수학, 코딩 등 추론 태스크에서 뛰어난 성능을 보였습니다.
- OpenAI O1 이후 journey learning, 데이터 증류, MCTS 등의 기법으로 O1을 재현하려는 노력이 있었습니다 (예: Marco-o1, DeepSeek-R1, Kimi K1.5).
- DRT는 이러한 O1-like 모델의 Long thought 개념을 MT에 적용합니다.
- Literature Translation:
- 표준 MT(뉴스 등)와 달리, 문학 번역은 문화적 요소, 비유/은유 포함으로 인해 어렵고 단어 수준 이상의 등가성이 필요합니다.
- 자동 평가 지표(BLEU, COMET 등)로는 평가가 어렵고 신뢰할 수 없어서, 주로 인간 평가에 의존합니다.
- 이전 연구는 소규모 시도가 많았으며, 최근 LLM을 활용하거나 문서 수준 문맥을 고려하는 연구가 진행되었습니다 (예: Par3 벤치마크).
- DRT는 이 어려운 문학 번역 도메인에 Long thought 방식을 도입합니다.
5 Conclusion
- 이 논문은 LLM의 Long thought를 기계 번역에 적용한 DRT를 제안합니다.
- DRT 데이터는 Multi-Agent Framework와 GPT-4o Reformulation을 통해 합성되었습니다.
- Multi-Agent Framework는 번역가, 조언자, 평가자가 반복적으로 협력하여 Long thought 과정을 만듭니다.
- 적합한 소스 문장은 문학 작품에서 비유/은유 문장을 마이닝하여 수집했습니다.
- 합성 데이터로 DRT 모델을 훈련시켰습니다.
- 자동 평가 및 인간 평가, 사례 연구를 통해 DRT 모델의 우수성을 입증했습니다.
- DRT는 LLM이 기계 번역 과정에서 '생각하는 방법'을 학습하게 함을 보여줍니다.

AI Researcher