📑 문제 주소
https://programmers.co.kr/learn/courses/30/lessons/42584
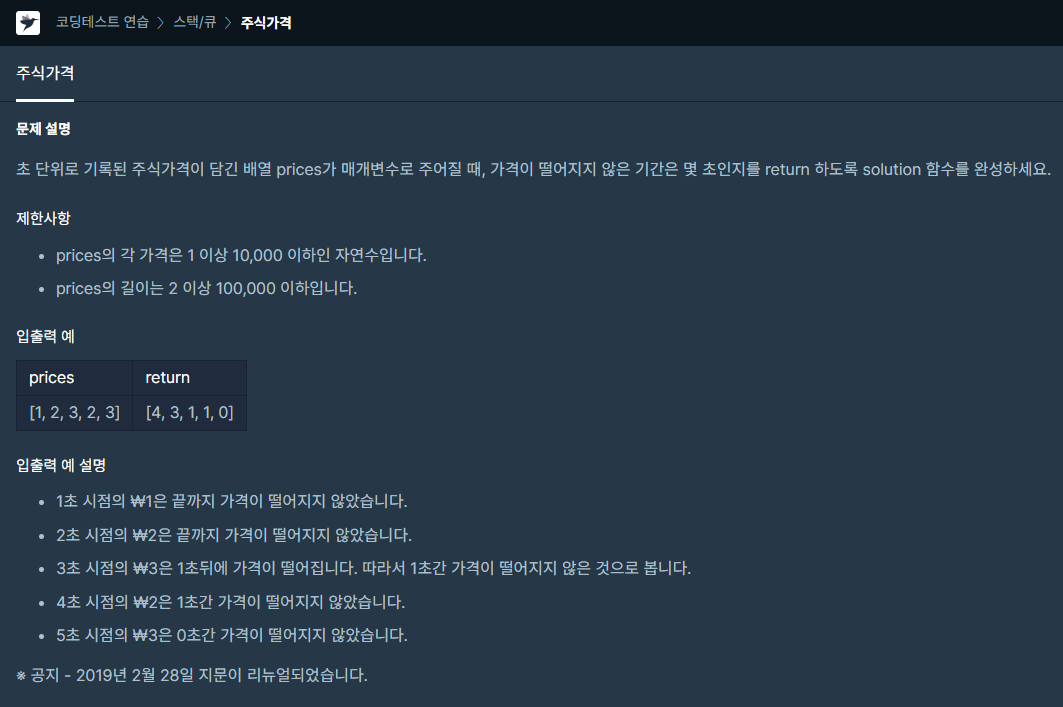
🔥 문제 설명
초단위의 주식 가격이 담긴 prices 배열이 주어진다. 이때, 주식 가격이 해당 시점 이후 떨어지지 않은 기간을 각각 구하여 해당 배열을 return 해야한다.
🔥 나의 풀이
stack이나 queue를 써야할 것같은 문제였다. (사실 stack/queue문제 중에서 고른 문제라서 그런것도 있다...) 하지만 아직까지 stack을 써야할지 queue를 써야할지 잘 모르겠어서 시간이 조금 오래걸렸다. stack을 쓰는줄 알고 헛고생 하다가 결국엔 queue를 사용하여 이중반복문을 통해 하나하나 비교하여 구하였다.(근데 stack을 사용해도 구현할 수 있을것같다..)
prices와 같은 queue를 deque를 사용하여 생성하였고, 앞에서부터 하나씩 pop하여(stack과 달리 queue는 FIFO방식 ➡ 먼저 넣은것 먼저 빼냄) 그 이후의 가격들과 비교하였다. 이때 주의할점은 바로 다음 초에 가격이 떨어지더라고 1초가 추가된다는 점이다. 즉, [1,2,3,2,3]의 배열에서 3 ➡ 2 로 가격이 떨어질때는 1초를 return하고 마지막 3으로 끝나는 경우에만 0을 return하게 된다. 이를 위해 break가 포함된 분기문을 앞에 작성하였다.
from collections import deque
def solution(prices):
queue = deque(prices)
length = len(prices)
answer = [0]*length
for i in range(length):
now_int = queue.popleft()
for j in range(i+1,length):
if now_int>prices[j]:
answer[i] += 1
break
else:
answer[i] +=1
return answer✅ 다른 사람의 풀이
이중 for문을 사용하여 당연히 효율성에서 걸릴 줄 알았는데 통과해서 조금 놀랐다. 그리고 다른사람들은 stack과 queue를 사용해서 O(n)의 시간복잡도를 가지게 짰을 줄 알았는데 좋아요를 가장 많이 받은 코드가 나와 비슷하여 또한번 놀랐다.
구글링을 하던 중 더 적은 반복을 돌 수 있는 코드를 찾았다.
def solution(prices):
length = len(prices)
stack = [0]
answer = [ i for i in range (length - 1, -1, -1)]
for i in range (1, length):
while stack and prices[stack[-1]] > prices[i]:
j = stack.pop()
answer[j] = i - j
stack.append(i)
return answer먼저 answer 배열을 할수 있는 가장 큰 값으로 초기화해놓는다. 그리고 stack에 index를 차례로 append하는데, 이때 만일 가격이 떨어졌다면 stack에서 해당 index를 pop하면서 최고 값으로 초기화 해놓은 answer배열을 수정한다.(=pop한 index 뒤로는 더이상 셀 수 없기 때문) 이렇게 하면 가격이 커지는 경우에만 두번째 반복문을 돌기 때문에 효율성을 크게 높일 수 있었다. (물론 난 혼자는 못 생각해 낼 것 같다~)
🏷️ 출처
다른사람 코드의 출처 : https://velog.io/@soo5717/%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%A8%B8%EC%8A%A4-%EC%A3%BC%EC%8B%9D%EA%B0%80%EA%B2%A9-Python
