이번 학기 프로젝트는 백엔드에서 사용자의 트래픽을 처리하는 데 정성을 들일 것이기 때문에 ES를 써야할지 고민중이다.
오늘 교수님께서 '설치하는데만 3주 걸릴수도 있다'고 언급하셨는데 그정도로 ES...악명높은건가 혹시..?
목표는 우선 ES에 대해 이해하고, 설치하기까지인 것으로 !
Elasticsearch(ES)
1. WHAT?
ES란 무엇인가?
elasticsearch는 분산 검색엔진이다. 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진이고, 분산형 및 개방형을 특징으로 한다.
분산 시스템이기 때문에 검색 대상의 용량이 증가했을 때 대처하기가 매우 쉽다.
2. WHERE?
ES는 어디에 사용되는가?
ES의 속도와 확장성, 수많은 종류의 콘텐츠를 인덱싱(색인)할 수 있다는 것은 다양한 사례에 적용하여 사용가능하다는 뜻이다.
- 애플리케이션 검색
- 웹사이트 검색
- 엔터프라이즈 검색
- 로깅과 로그 분석
- 인프라 메트릭과 컨테이너 모니터링
- 애플리케이션 성능 모니터링
- 위치 기반 정보 데이터 분석 및 시각화
- 보안 분석
- 비즈니스 분석
3. HOW?
그렇다면 ES는 어떻게 작동하는가?
위에서 언급했던 로그, 시스템 메트릭, 웹 애플리케이션 등 다양한 소스로부터 원시 데이터가 ES로 들어간다.
데이터를 수집하는 프로세스에서는 ES에서 인덱싱되기 전에 구문 분석, 정규화, 강화된다.
인덱싱된 후에, 사용자는 이 데이터에 대한 복잡한 쿼리를 실행하고 집계를 사용해 데이터의 복잡한 요약을 검색할 수 있다.
사용자는 Kibana에서 데이터를 시각화하고, 대시보드를 공유하며, Elastic Stack을 관리할 수 있다.
- Kibana : ES를 위한 시각화 및 관리 도구이다. 실시간 히스토그램, 선 그래프, 파이 차트, 지도 등을 제공한다. Kibana에는 사용자가 자신의 데이터를 기반으로 사용자가 정의한 동적 인포그래픽을 만들 수 있는 캔버스, 위치 기반 정보 데이터를 시각화하기 위한 Elastic Maps같은 고급 애플리케이션도 포함된다.
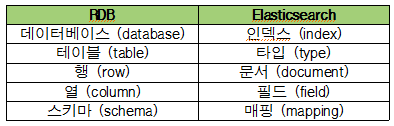
4. DIFFERENCE with RDB
ES는 관계형 데이터베이스와 어떤 차이가 있을까?
-
관계형 데이터베이스 (RDB)

-
Elasticsearch (ES)
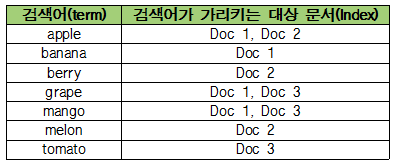
ES에 나타낸 표와 같이 인덱싱한것을 역색인(Inverted Index)이라 한다.
역색인을 하게 되면 DB에 데이터가 많이 들어가있는 경우에도 검색 시 빠른 처리를 도울 수 있다.왜 그런가 이해하기 위해 예시를 들어보자.
가령 사용자가 'apple'이 들어가는 '문서(Doc)'를 찾고싶을 경우 'apple'이라는 키워드로 검색을 할 것이다.기존 RDB에서는 Doc 1, Doc 2, Doc 3 전체 문서의 전체 text필드에서 'apple'을 찾고난 후 그 결과를 돌려준다.
그에 비해 ES에서는 'apple'이라는 키워드가 어느 문서에 있는지 이미 인덱싱되어있기 때문에, 바로 문서 'Doc 1'과 'Doc 2'를 결과로 돌려준다.
따라서 ES는 Full text search에 강점을 가질 수 밖에 없게 된다.
다만, ES에서는 메모리에 데이터를 들고 있기 때문에, 데이터의 규모나 형태에 따라 하드웨어 스펙을 잘 결정해야 한다(CPU, 메모리 등).
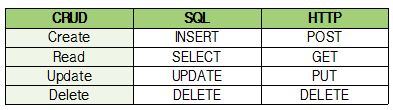
-
CRUD명령어 비교
-
개념