모델 소개
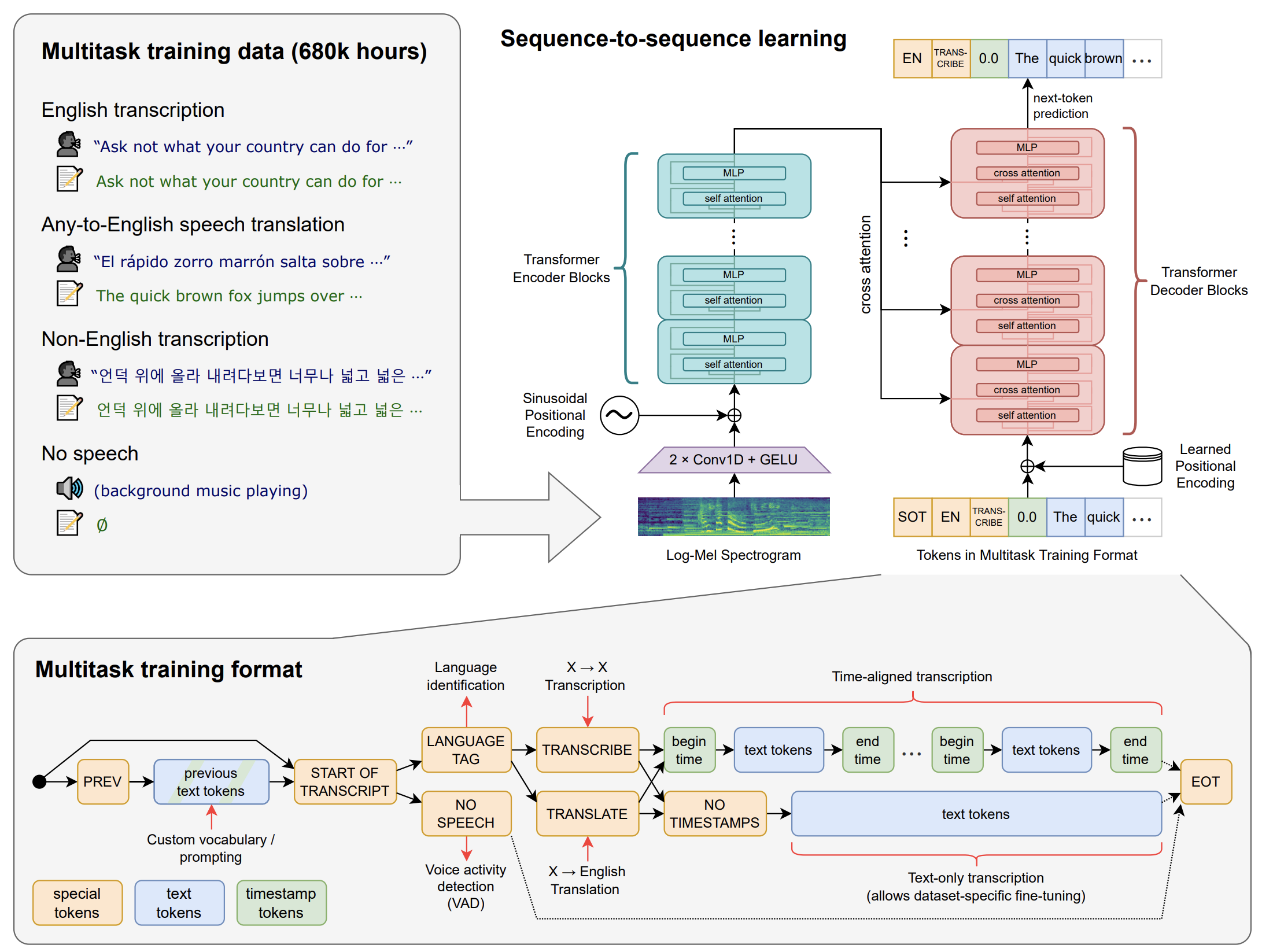
- 모델 아키텍쳐는 encoder-decdoer 변환기로 구현되는 간단한 end-to-end 접근 방식
- 입력 오디오는 30초 단위로 분할되어 log-Mel 스펙트로그램으로 변환된 다음 encoder로 전달됨
- decoder는 단일 모델이 언어 식별, 구문 단위의 타임스탬프, 다국어 음성 전사 및 영어 음성 번역과 같은 작업을 수행하도록 지시하는 특수 토큰과 혼합된 해당 텍스트 캡션을 예측하도록 훈련됨.
- 대규모 노이즈 데이터를 사용해 weakly supervised 방식으로 훈련되기 때문에, 입력된 오디오에서 실제로 말하지 않은 텍스트가 포함될 수도 있음
Set up
최신 whisper 레포 설치하기
pip install git+https://github.com/openai/whisper.gitpackage update
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.gitos 환경에 맞게 ffmpeg 설치
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpegtokenizer 가 필요하다면 설치하기
pip install setuptools-rust설치하는 동안 이 링크를 참고해서 Rust 개발 환경 셋팅하기
Usage
사용 가능한 모델 및 언어
영어만 필요할 경우, .en 모델의 성능이 더 좋다
CLI usage
medium 모델을 사용해서 audio file 한국어로 STT 수행하기
whisper audio.wav --model medium --language Korean더 많은 옵션 확인하기
whisper --helpPython usage
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])transcribe()메서드는 전체 파일을 읽고 30초 단위로 슬라이딩하여 오디오를 처리하고, 각 슬라이딩 윈도우마다 sequence-to-sequence 예측을 수행함
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)- 해당 코드는 모델에 대한 lower-level 수준의 액세스를 제공하는
wisper.detect_language()와wisper.decode()의 사용 예이다
Review
코랩을 사용하여 실제 코드를 돌려본 결과 한국어 전화 음성에 대한 STT 결과가 꽤 좋았다. 노이즈 데이터에 대한 영향 때문에 실제로 말하지 않은 텍스트나 잘못 검출된 단어들이 종종 보였지만, 구문 단위로 텍스트를 잘 분리하고, 여러명의 화자가 대화를 나눌 때 중간에 끼어든 말 또한 다른 구문으로 잘 분리하였다.
