목표
AI공동경진대회 준비 및 VIS(Video Instance Segmentation) 관련 논문을 읽어보자.
사용 언어
Python
일정
2회차: 7/15 13:00 ~ 16:00
목표 : DeeplabV3+ 논문 리뷰 및 코드 구현

모델 구조
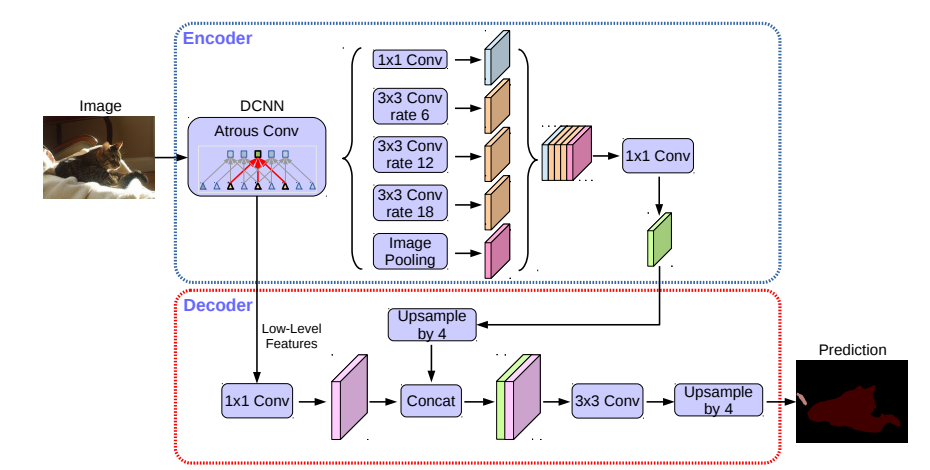
모델 특징
- Astrous convolution을 사용하여 receptive field를 효과적으로 키울 수 있었다.
여기서 Astrous convolution은 아래에 있는 그림처럼 특징 길이만큼 띄워서 convolution 연산을 수행하는 것이다.
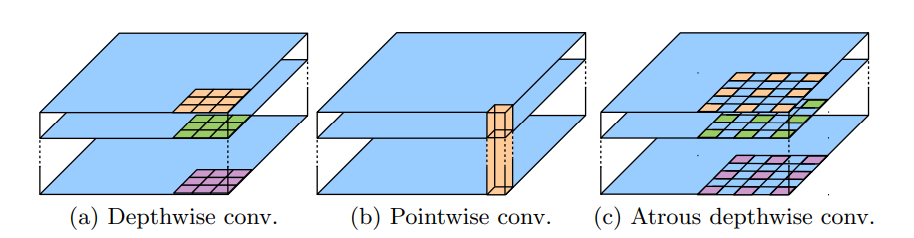
- Astrous separable depthwise convolution을 통해 기존의 연산량을 줄일 수 있었다.
해당 논문에서는 모델 구현을 위한 Backbone으로 Xception과 Resnet-101을 사용하였으며 코드 구조는 아래 그림과 같다.
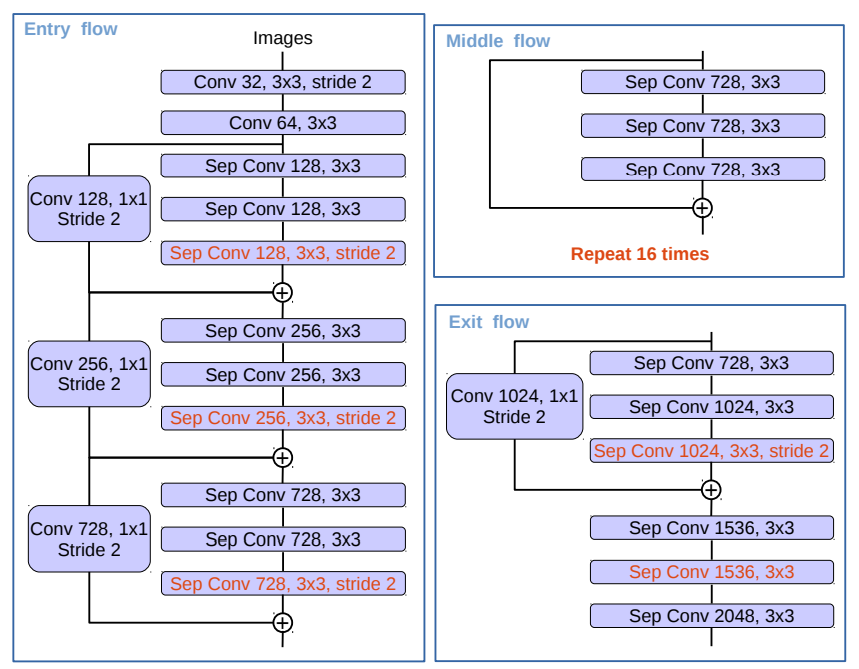
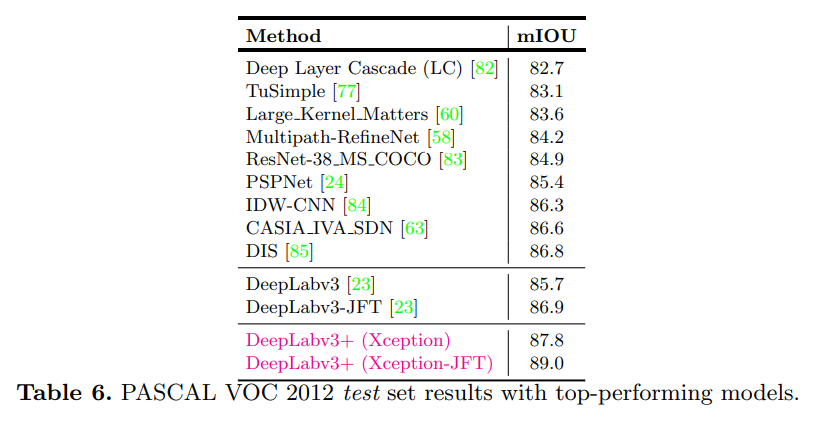
그 결과 기존의 존재하는 모델의 성능을 뛰어넘은 SOTA(state-of-the-art)를 달성하였다.
코드구현
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, rate=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
dilation=rate, padding=rate, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.rate = rate
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, nInputChannels, block, layers, os=16, pretrained=False):
self.inplanes = 64
super(ResNet, self).__init__()
if os == 16:
strides = [1, 2, 2, 1]
rates = [1, 1, 1, 2]
blocks = [1, 2, 4]
elif os == 8:
strides = [1, 2, 1, 1]
rates = [1, 1, 2, 2]
blocks = [1, 2, 1]
else:
raise NotImplementedError
# Modules
self.conv1 = nn.Conv2d(nInputChannels, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], rate=rates[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], rate=rates[1])
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], rate=rates[2])
self.layer4 = self._make_MG_unit(block, 512, blocks=blocks, stride=strides[3], rate=rates[3])
self._init_weight()
if pretrained:
self._load_pretrained_model()
def _make_layer(self, block, planes, blocks, stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def _make_MG_unit(self, block, planes, blocks=[1,2,4], stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate=blocks[0]*rate, downsample=downsample))
self.inplanes = planes * block.expansion
for i in range(1, len(blocks)):
layers.append(block(self.inplanes, planes, stride=1, rate=blocks[i]*rate))
return nn.Sequential(*layers)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
low_level_feat = x
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x, low_level_feat
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _load_pretrained_model(self):
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/resnet101-5d3b4d8f.pth')
model_dict = {}
state_dict = self.state_dict()
for k, v in pretrain_dict.items():
if k in state_dict:
model_dict[k] = v
state_dict.update(model_dict)
self.load_state_dict(state_dict)
def ResNet101(nInputChannels=3, os=16, pretrained=False):
model = ResNet(nInputChannels, Bottleneck, [3, 4, 23, 3], os, pretrained=pretrained)
return model
class ASPP_module(nn.Module):
def __init__(self, inplanes, planes, rate):
super(ASPP_module, self).__init__()
if rate == 1:
kernel_size = 1
padding = 0
else:
kernel_size = 3
padding = rate
self.atrous_convolution = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,
stride=1, padding=padding, dilation=rate, bias=False)
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.3)
self._init_weight()
def forward(self, x):
x = self.atrous_convolution(x)
x = self.bn(x)
x = self.relu(x)
# x = self.dropout(x)
return x
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class DeepLabv3_plus(nn.Module):
def __init__(self, nInputChannels=3, n_classes=2, os=16, pretrained=False, _print=True):
if _print:
print("Constructing DeepLabv3+ model...")
print("Number of classes: {}".format(n_classes))
print("Output stride: {}".format(os))
print("Number of Input Channels: {}".format(nInputChannels))
super(DeepLabv3_plus, self).__init__()
# Atrous Conv
self.resnet_features = ResNet101(nInputChannels, os, pretrained=pretrained)
# ASPP
if os == 16:
rates = [1, 6, 12, 18]
elif os == 8:
rates = [1, 12, 24, 36]
else:
raise NotImplementedError
self.aspp1 = ASPP_module(2048, 256, rate=rates[0])
self.aspp2 = ASPP_module(2048, 256, rate=rates[1])
self.aspp3 = ASPP_module(2048, 256, rate=rates[2])
self.aspp4 = ASPP_module(2048, 256, rate=rates[3])
self.relu = nn.ReLU()
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(2048, 256, 1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
self.dropout = nn.Dropout(p=0.3) # define dropout layer
self.conv1 = nn.Conv2d(1280, 256, 1, bias=False)
self.bn1 = nn.BatchNorm2d(256)
# adopt [1x1, 48] for channel reduction.
self.conv2 = nn.Conv2d(256, 48, 1, bias=False)
self.bn2 = nn.BatchNorm2d(48)
self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Conv2d(256, n_classes, kernel_size=1, stride=1))
def forward(self, input):
x, low_level_features = self.resnet_features(input)
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
x5 = F.upsample(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout(x) # add dropout layer
x = F.upsample(x, size=(int(math.ceil(input.size()[-2]/4)),
int(math.ceil(input.size()[-1]/4))), mode='bilinear', align_corners=True)
low_level_features = self.conv2(low_level_features)
low_level_features = self.bn2(low_level_features)
low_level_features = self.relu(low_level_features)
low_level_features = self.dropout(low_level_features) # add dropout layer
x = torch.cat((x, low_level_features), dim=1)
x = self.last_conv(x)
x = F.upsample(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x
def freeze_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def __init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def get_1x_lr_params(model):
"""
This generator returns all the parameters of the net except for
the last classification layer. Note that for each batchnorm layer,
requires_grad is set to False in deeplab_resnet.py, therefore this function does not return
any batchnorm parameter
"""
b = [model.resnet_features]
for i in range(len(b)):
for k in b[i].parameters():
if k.requires_grad:
yield k
def get_10x_lr_params(model):
"""
This generator returns all the parameters for the last layer of the net,
which does the classification of pixel into classes
"""
b = [model.aspp1, model.aspp2, model.aspp3, model.aspp4, model.conv1, model.conv2, model.last_conv]
for j in range(len(b)):
for k in b[j].parameters():
if k.requires_grad:
yield k
if __name__ == "__main__":
model = DeepLabv3_plus(nInputChannels=3, n_classes=1, os=16, pretrained=True, _print=True)
model.eval()
image = torch.randn(1, 3, 512, 512)
with torch.no_grad():
output = model.forward(image)
print(output.size())

Object Detection, Segmentation, Multi-Object Tracking