목표
AI공동경진대회 준비 및 VIS(Video Instance Segmentation) 관련 논문을 읽어보자.
사용 언어
Python
일정
4회차: 7/29 13:00 ~ 16:00
4회차 목표 : VITA 논문 리뷰

-
등장 배경
앞선 선행 연구들은 Online, Offline 다양한 방식으로 VIS Task를 수행해왔다.
Online : Offline 모델에 비해 성능이 떨어짐, frame 혹은 clip 간 matching association method가 필요
Offline : 모델에 적용할 수 있는 Video 크기가 제한적임.
따라서 본 논문에서는 일반적인 환경에서 Video input의 크기 제한을 덜 받는 모델을 제안한다. -
핵심 기술
- dense feature map 대신 Object token(query) 사용
- frame level detector인 mask2former 사용
- Similarity loss 사용

-
모델 구조
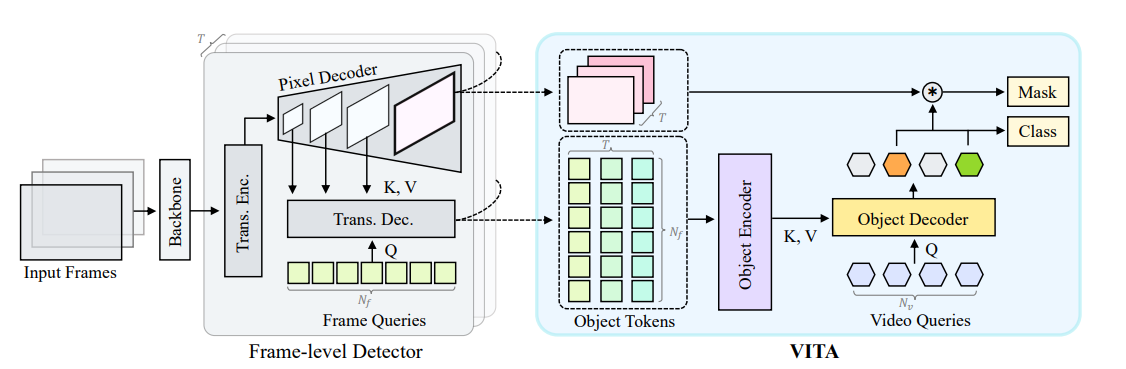
-
결과
- Datasets : YouTube-VIS 2019, 2021 OVIS![]

- Datasets : YouTube-VIS 2019, 2021 OVIS![]
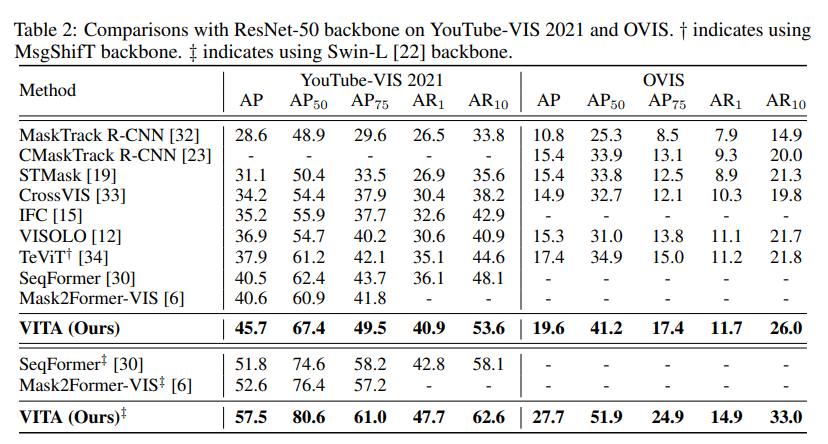
- 한계점
-
무한한 수의 frame 처리가 안된다.
-
객체 토큰은 시간정보를 명시적으로 활용하지 못한다. 따라서 매우 긴 sequence에서 어려운 케이스의 경우 이를 처리하기 어렵다.
-

Object Detection, Segmentation, Multi-Object Tracking
잘 봤습니다. 좋은 글 감사합니다.