
🍎 취지: 자바의 멀티 스레드를 공부하면서 스레드 및 자바의 스레드풀에 대해 공부한 것을 정리하고자 이 글을 쓰려고 한다.
🔍 스레드란?
- 한마디로 정의해보자면 운영체제 내에서 실행되는 프로세스의 하위 작업 단위라고 정의할 수 있을 것 같다.
그럼 먼저 Process에 대해 간단히 정의해보자
- 프로세스도 한 마디로 정의하자면 운영체제에서 실행될 수 있는 프로그램 즉 실행중인 상태를 말한다.
- 운영체제에 의해 관리되며, 독립적으로 실행될 수 있고 자원을 할당 받을 수 있다. 즉 메모리에 할당될 수 있는 데이터를 의미한다고 볼 수 있다.
그럼 멀티 프로세스라는 단어도 있는데 그건 뭐야?
- 운영체제는 효율적으로 그리고 다중 프로세스를 실행하기 위하여 context switching을 한다. 이 context switching 이란 번갈아가면서 프로세스를 실행하는 과정이라고 정의할 수 있다.
그러면 질문! 번갈아가면서 실행하려고 하면 내가 실행하고 있는 프로세스를 기억해서 어디까지 실행하고 있는지를 알아야되는 거 아냐??
- 이럴때 운영체제는 고유의 PCB(process control block)를 생성하여 프로세스의 상태 값을 저장한다.
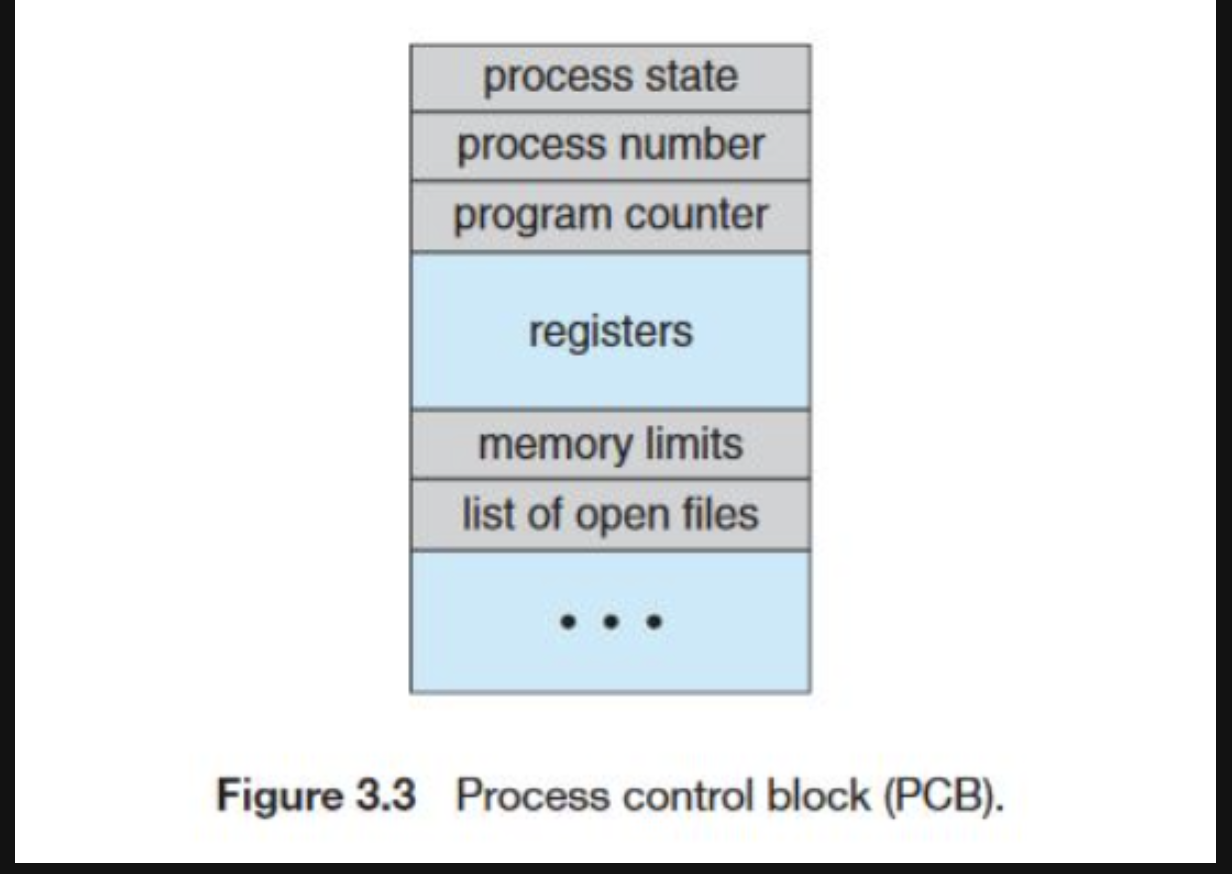
- 위의 사진과 같이 여러가지 정보를 저장하는데 설명은 아래와 같다.
- process state: 프로세스가 현재 실행 중인지, 대기 중인지, 준비 중인지 등 상태를 나타냅니다.- program counter: 다음에 실행될 명령어의 주소
- registers: CPU 에서 사용한 레지스터의 값
- cpu scheduling information: 프로세스의 우선순위, 최종 실행 시간, 스케쥴링 큐등의 정보
- Accounting informaion : CPU 사용 시간, 실제 사용된 시간, 시간 제한 등
- I/O status informaion : 프로세스에 할당된 I/O기기에 해당하는 정보
📖 프로세스의 상세정보 보는법
ps -p <PID> -o pid,ppid,state,etime,%cpu,%mem,command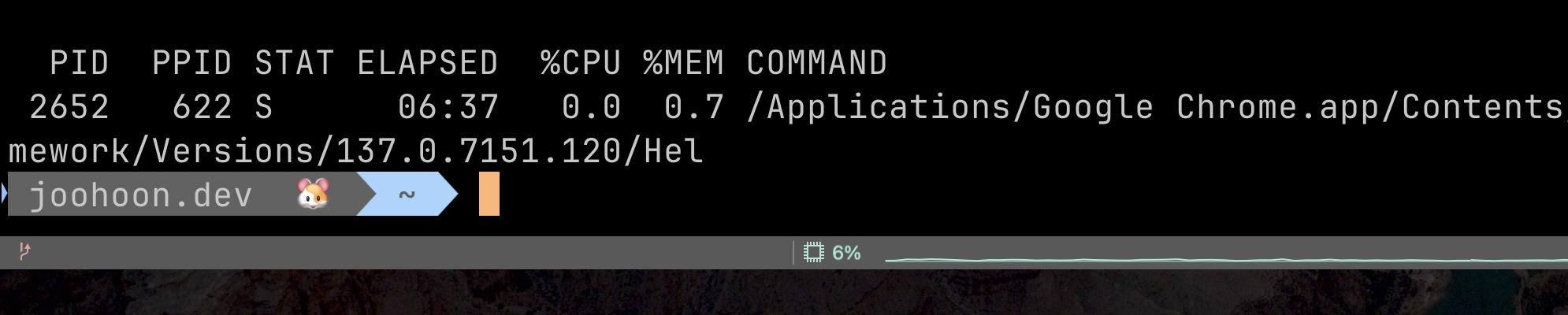
그럼 이제 본론으로 들어가보자
Java의 스레딩 모델은 어떤걸 사용해?
- Java의 스레드는 OS 즉 커널의 스레드에 1:1 매핑되는 구조이다.
- 스레드 하나를 생성하는 것은 1MB 의 비용이 발생한다고 한다.
- 우리가 흔히 아는 new Thread() 로 스레드를 생성하고 이를 .start() 하는 구조로 사용자는 OS의 스레드를 사용할 수 있다.
그럼 스레드를 얼마만큼 생성해야해?
- 물리 서버의 코어당 1~2개의 스레드를 사용할 수 있고 나머지는 대기 상태로 대기한다고 한다.
- Heap 영역을 제외한 사용가능한 메모리 / 스레드당 스택 크기가 평균적으로 생성할 수 있는 스레드 수라고 한다.
- ex) 메모리 6GB / 스레드당 스택 크기 1MB- 6GB / 1MB = 약 6000개의 스레드 생성 가능
추천하는 방식은
- 보통 일반적으로 코어당 1~2개의 스레드를 생성하는 것이 일반적이라고 한다. 따라서 코어가 8코어라면 8~16개 정도의 스레드가 적당해 보인다.
- 혹여 I/O 작업이 많이 일어나는 경우라면 2배~10배 정도까지 생성하고 이를 성능 테스트를 통해 조절하는 것이 알맞아 보인다.
- 🐻 리틀의 법칙스레드 수 = 응답 시간 × 처리율
- 우리는 MVC 기반이라면 yml 파일 혹은 tomcat 설정에서 기본 스레드 수, max 스레드 수를 조절하여 사용중일 것이다. 아래는 springboot 기반의 tomcat 에서의 설정 방법이다.
-- yaml--
server:
tomcat:
threads:
max: 300
min-spare: 20-- 외장톰캣 --
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
maxThreads="200"
minSpareThreads="20"
acceptCount="100"
redirectPort="8443" />Java에서 그러면 스레드 풀을 사용해서 Task들을 실행하고 싶어 이럴땐?
- Java에서는 ExecutorService라는 인터페이스를 제공하여 스레드 풀을 사용할 수 있게 해준다.
- ❗️ 왜 이런 라이브러리가 나왔을까?
- 우리가 공부했던 Runnable, Thread 기반의 코드들은 문제점들이 있다. 하나하나 그 스레드의 작업을 waiting(join()) 한다던지 하는 번거러움이 동반될 수 있다.
- 이를 해결하기 위하여 ExectuorService(Executor의 자손) 같은 추상화된 인터페이스를 제공해주는 것 같다.
- Doug Lea님에게 감사의 인사 🙇🏻
🙌 사용 예시를 알아보자
고정 스레드풀
final ExecutorService es = Executors.newFixedThreadPool(2);- 고정 스레드풀은 newFixedThreadPool(int nThreads)를 통하여 생성 할 수 있다. 내부 코드를 보자
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}- ThreadPoolExecutor는 ExecutorService의 구현체라고 보면된다.
- 이 고정풀은 안정적으로 사용자의 요청을 받아들일 수 있는데 최소 n개의 스레드 수, 최대 n개의 스레드 수, 시간 단위, 그리고 대기 큐는 LinkedBlockingQueue로 되어있다.
- 단점으로는 요청이 갑자기 많이 들어오거나 사용자가 많아졌을 때 대기하는 스레드는 모두 blockingQueue에 대기하여 병목현상이 길어질 수 있다는 점이다.
캐시 스레드풀
- 캐시 스레드풀 사용 코드
final ExecutorService es = Executors.newCachedThreadPool();public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- 캐시 스레드풀은 사용자의 요청을 대기 큐에 넣지 않는다. 즉 사용자의 요청을 바로바로 수행한다. 그러기에 사용자의 요청이 급격하게 늘어날때 사용하면 좋을 것 같다. 하지만 OS의 스레드를 계속해서 생성하기에 서버 자원의 임계점을 초과하면 서버가 죽을 수 있는 side-effect가 존재한다.
사용자 정의 풀
final ExecutorService es = new ThreadPoolExecutor(100, 200,
60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000));
printState(es);- 사용자 정의 풀은 사용자가 직접 ThreadPoolExecutor로 스레드 풀을 생성하는 것을 의미한다. 여기서 주의할점은 두번째 인자로 들어가는 스레드 수는 대기 큐에 task가 초과될시 생성한다는 점이다.
- 여기서는 ArrayBlockingQueue를 사용하여 요청이 1000개가 초과될 시 200개까지 스레드를 초과 생성한다는 점이다
주의❗️
- 만약 수행해야할 작업이 대기 큐에도 꽉차고 사용가능한 스레드 수도 초과한다면 어떻게 될까?
- RejectedExecutionException이 발생한다. 이를 catch 구문으로 잡아서 로그를 찍거나 실패 시 작업을 등록하면 된다.
ex)
final long startMs = System.currentTimeMillis();
for (int i=1; i<=TASK_SIZE; ++i) {
String taskName = "task" + i;
try {
es.execute(new RunnableTask(taskName));
printState(es, taskName);
} catch (RejectedExecutionException e) {
log(taskName + " -> " + e);
}
}
es.close();🫸 거절 정책
- 마지막으로 봤던 사용자 정의 풀에서 RejectedExecutionException이 발생하는 이유는 뭘까?
- 기본 정책으로 AbortPolicy() 라는 정책을 사용하고 있기 때문이다.
- 이 정책은 ThreadPoolExecutor의 마지막인자로 설정할 수 있다.
ex)
final ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1,
0, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.AbortPolicy()); // 기본 정책몇가지 정책에 대해서 더 살펴보자
DiscardPolicy()
final ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1,
0, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.DiscardPolicy()); - 이 정책은 task가 초과하면 그냥 버려버린다. 그래서 이름이 Discard이다. 참으로 재밌는 정책이다. 내부 코드를 열어보면 비어있다.
-- AbortPoicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}-- DiscardPolicy()
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}CallerRunsPolicy()
- 이 정책도 재밌다. 초과하는 task 발생 시 서비스(ExecutorService) 의 종료 여부를 물어보고 종료되지 않았다면 그 task를 호출하는 스레드가 실행시킨다.
- 즉 main thread가 실행하라고 요청하면 ExecutorService에서 생성한 스레드를 사용해서 그 작업을 처리하는 것이 아닌 main thread가 그 task를 실행해버린다.
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}사용자 정의 거절 정책
- 우리는 ThreadPoolExecutor의 마지막 인자로 RejectedExecutionHandler를 넣을 수 있다. 필요하다면 이 핸들러를 직접 구현해서 커스텀하게 우리가 정의한 클래스를 넣을 수 있다. 아래는 예시이다.

public static void main(String[] args) {
final ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1,
0, TimeUnit.SECONDS, new SynchronousQueue<>(), new MyRejectedExecutionHandler()); // 기본 정책
executor.submit(new RunnableTask("task1"));
executor.submit(new RunnableTask("task2"));
executor.submit(new RunnableTask("task3"));
executor.submit(new RunnableTask("task4"));
executor.close();
}
// 사용자 정의 거부 정책 예시
static class MyRejectedExecutionHandler implements RejectedExecutionHandler {
static AtomicInteger count = new AtomicInteger(0);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
int i = count.incrementAndGet();
log("[경고] 거절된 누적 작업 수 " + i);
}
}
Java의 스레딩 모델의 미래
- 사실 미래도 아니다. 이제 점점 다가오고 있는 현재라고 볼 수 있다.
- Java 21부터 Virtual Thread 라는 것이 등장하였다.
기존의 자바 스레드 모델 vs Virtual Thread
- 기존의 자바 스레드(Platform Thread) 는 OS의 스레드와 1:1 로 매핑되는 구조여서 생성 비용이 높은 편이였다.
- 하지만 Virtual Thread는 구조가 좀 다르다.
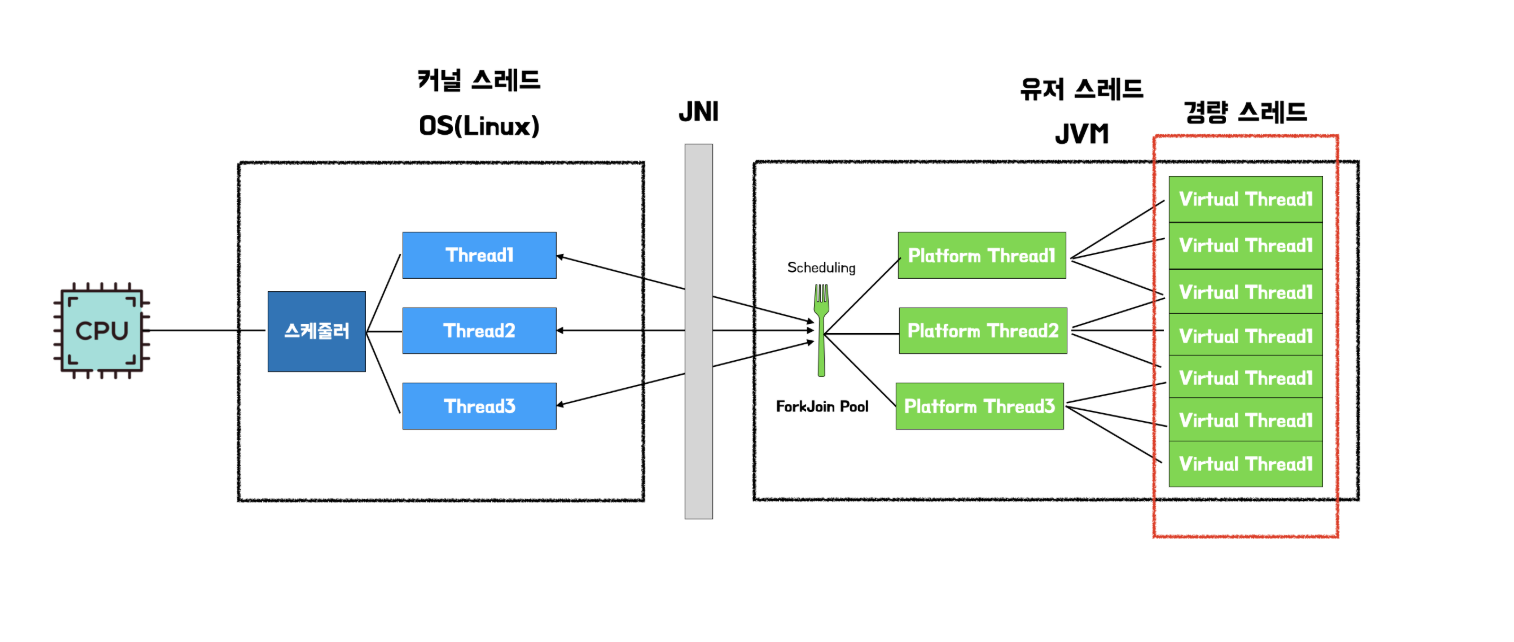
출처: 우아한 기술블로그
- 기존에 1:1로 매핑되던 Platform Thread와는 달리 ForkJoinPool이 PlatForm Thread를 스케쥴링한다. 그리고 이 Platform Thread과 1:N 관계로 연결되어 있는 경량 스레드들이 JVM 내부에서 존재한다고 한다. 이 스레드들은 기존 스레드가 blocking되는 것과는 달리 async-nonblocking 과 유사한 구조로 동작한다.
- 내가 이해한 것을 예로 들자면(틀리면 댓글 부탁드립니다) 1번 PlatFormThread가 A,B,C Virtual Thread와 매핑되어 있다라고 가정해보자
- A에서 I/O 작업이 이루어져 blocking 되어있다면 PlatFormThread는 A를 스케쥴링에서 제외한다(park). 1번 스레드는 B,C 작업을 수행하다 A의 요청이 왔을 시 (unpark) JVM은 이 I/O 작업을 다시 스케쥴링 큐에 넣게 된다.
Kotlin의 코루틴?
- 아직 코틀린은 익숙치 않지만 코틀린의 꽃은 코루틴이라는 말을 어디선가 들었다.
- 코루틴은 메소드 단위로 실행할 수 있고 원래의 메소드라면 처음부터 끝까지 계속해서 실행하는데 (countDownLatch쓰면 예외인 경우같음) 코루틴을 사용하면 메소드 중간에 실행을 멈추고 스레드가 반환된다고 한다. 그리고 이 메소드를 재개할 시점에 다시 중단된 부분부터 실행(callback이 오면)을 가능하게 만드는 구조라고 한다. 그러면 얼마전에 사용했던 webflux의 async-nonBlocking 방식이랑 같은데 뭐가 다를까 찾아보았더니
코틀린의 코루틴은 동기 방식의 코드로 async-nonBlocking이 가능해서 오버헤드가 좀 적다고 한다.(webflux는 사용해본 결과 코드 작성 방식이 오버헤드가 매우 큰 것 같다.)
결론: virtual thread가 상용화 된다면 이를 좀더 공부해보자 혹은 코틀린의 코루틴 Go의 고루틴등을 공부해도록 하자. 또한 여러 태스크들(Callable, Runnable) 을 실행할때는 ExecutorService를 적극 활용해보도록 하자.

Dont regret it will be your future